-
查阅trt engine
(1)终于把TensorRT的engine模型的结构图画出来了! - 知乎
这个需要build时候记录的log以及profile文件
其实我觉得很鸡肋。我们往往需要拿到一个已经生成好的别人的计划文件,因此不可能知道log和profile
(2)第二种方案是利用trt sdk库自带的tools下的polygraphy。
安装方法:
- conda activate xxx(你的带有trt的虚拟环境)
- cd xxx(你的trt sdk下面的目录与setup.py文件同级目录路径下)
- python setup.py install
然后可以基于以下参考:
极智AI | 教你使用深度学习模型调试器 polygraphy - 掘金
TensorRT debug及FP16浮点数溢出问题分析_TracelessLe的专栏-程序员秘密 - 程序员秘密
链接:https://pan.baidu.com/s/1sMum2N8N2rU0WqTM3t4w6Q
提取码:1314

实际我发现需要使用命令:
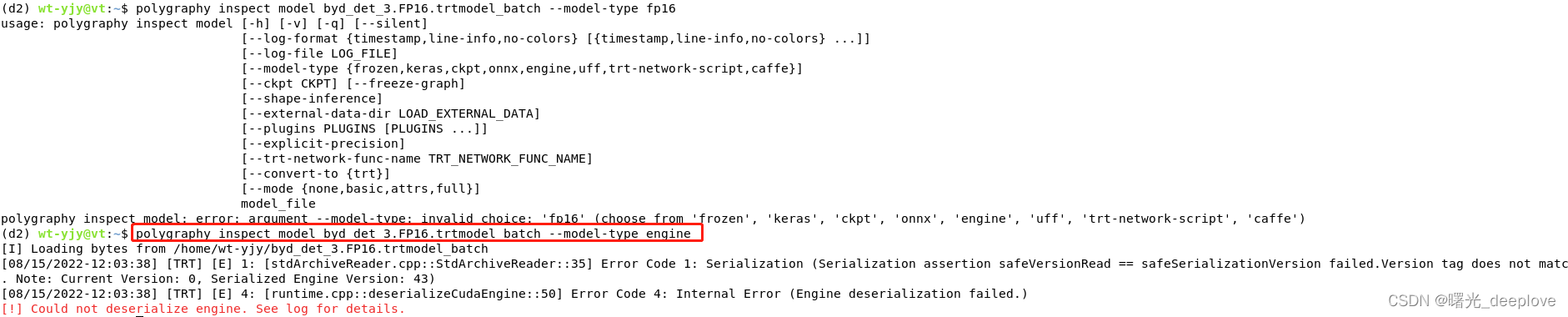
明显报出错误了最后,这错误是由于我生成的trt文件是trt8.2的,而现在我这个虚拟环境下的trt是8.4的,自然trt库的版本出现不一致,就出现了以上错误!
我后面没有继续更换虚拟环境下的trt版本了。
我的目的是想获得trt文件的输入输出名、shape,因此通过:strings xxx.engine | grep xxx(你想搜索的)


这个trt的engine文件我是没有加密的,因此可以看到上面显示的,都很正常。接下来使用同样方法查询一个加密后的trt engine文件:

这很明显是这个trt engine文件被加密了成了二进制文件,且是混乱无序,乱七八糟,各种符号!!!
(3)第三种方法就是使用trt的 runtime直接反序列化trt的engine(当然如果上面一样,如果这个engine文件被加密了,那么也就歇菜了!!!),engine 对象可以遍历 names。
这样就可以输入输出的名字,通过名字判断是检测还是分类。
-
相关阅读:
吐血整理超全 Java 进阶教程:基础 + 容器 + 并发 + 虚拟机 +IO
Camunda 7.x 系列【48】候选用户和用户组
1.11 小红书起号必看,如何找到适合自己的对标账号?【玩赚小红书】
AI语音克隆
Linux内核基础 - list_move_tail函数详解
SpringMVC前后端分离交互传参详细教程
后勤事务繁杂低效?三步骤解决企业行政管理难题
c# 容器变换
Oracle19c安装图文教程
使用Python的Turtle库绘制一棵随风飘落叶子的树
- 原文地址:https://blog.csdn.net/yangjinyi1314/article/details/126345134