-
自学设计模式
设计模式
v1.0 摘抄来源书籍:设计模式 Java版本
源码:quanke/design-pattern-java-source-code (github.com)
面向对象的七个设计原则
设计原则名称 定 义 使用频率 单一职责原则 (Single Responsibility Principle, SRP) 一个类只负责一个功能领域中的相应职责 ★★★★☆ 开闭原则 (Open-Closed Principle, OCP) 软件实体应对扩展开放,而对修改关闭 ★★★★★ 里氏代换原则 (Liskov Substitution Principle, LSP) 所有引用基类对象的地方能够透明地使用其子类的对象 ★★★★★ 依赖倒转原则 (Dependence Inversion Principle, DIP) 抽象不应该依赖于细节,细节应该依赖于抽象 ★★★★★ 接口隔离原则 (Interface Segregation Principle, ISP) 使用多个专门的接口,而不使用单一的总接口 ★★☆☆☆ 合成复用原则 (Composite Reuse Principle, CRP) 尽量使用对象组合,而不是继承来达到复用的目的 ★★★★☆ 迪米特法则 (Law of Demeter, LoD) 一个软件实体应当尽可能少地与其他实体发生相互作用 ★★★☆☆ 单一原则
理解为:一个类只负责自己领域的功能责任,多余的功能分解成其他类。
eg:

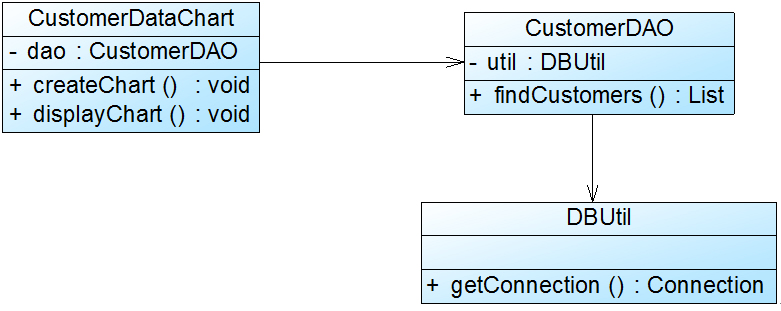
在图1中,CustomerDataChart类中的方法说明如下:getConnection()方法用于连接数据库,findCustomers()用于查询所有的客户信息,createChart()用于创建图表,displayChart()用于显示图表。
现使用单一职责原则对其进行重构。
在图1中,CustomerDataChart类承担了太多的职责,既包含与数据库相关的方法,又包含与图表生成和显示相关的方法。如果在其他类中也需要连接数据库或者使用findCustomers()方法查询客户信息,则难以实现代码的重用。无论是修改数据库连接方式还是修改图表显示方式都需要修改该类,它不止一个引起它变化的原因,违背了单一职责原则。因此需要对该类进行拆分,使其满足单一职责原则,类CustomerDataChart可拆分为如下三个类:
(1) DBUtil:负责连接数据库,包含数据库连接方法getConnection();
(2) CustomerDAO:负责操作数据库中的Customer表,包含对Customer表的增删改查等方法,如findCustomers();
(3) CustomerDataChart:负责图表的生成和显示,包含方法createChart()和displayChart()。
使用单一职责原则重构后的结构如图2所示:
开闭原则
理解为:在不修改原有代码的基础上,新增功能。
抽象化是开闭原则的关键
Sunny软件公司开发的CRM系统可以显示各种类型的图表,如饼状图和柱状图等,为了支持多种图表显示方式,原始设计方案如图1所示:
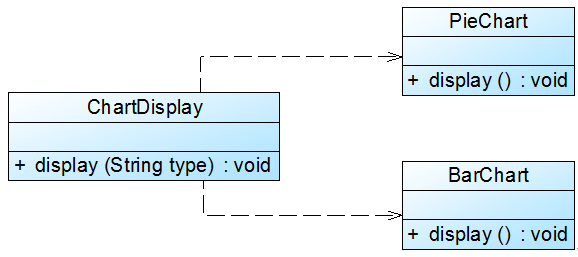
图1 初始设计方案结构图
在ChartDisplay类的display()方法中存在如下代码片段:
...... if (type.equals("pie")) { PieChart chart = new PieChart(); chart.display(); } else if (type.equals("bar")) { BarChart chart = new BarChart(); chart.display(); } ......- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
在该代码中,如果需要增加一个新的图表类,如折线图LineChart,则需要修改ChartDisplay类的display()方法的源代码,增加新的判断逻辑,违反了开闭原则。
现对该系统进行重构,使之符合开闭原则。
在本实例中,由于在ChartDisplay类的display()方法中针对每一个图表类编程,因此增加新的图表类不得不修改源代码。可以通过抽象化的方式对系统进行重构,使之增加新的图表类时无须修改源代码,满足开闭原则。
具体做法如下:
(1) 增加一个抽象图表类AbstractChart,将各种具体图表类作为其子类;
(2) ChartDisplay类针对抽象图表类进行编程,由客户端来决定使用哪种具体图表。
重构后结构如图2所示:
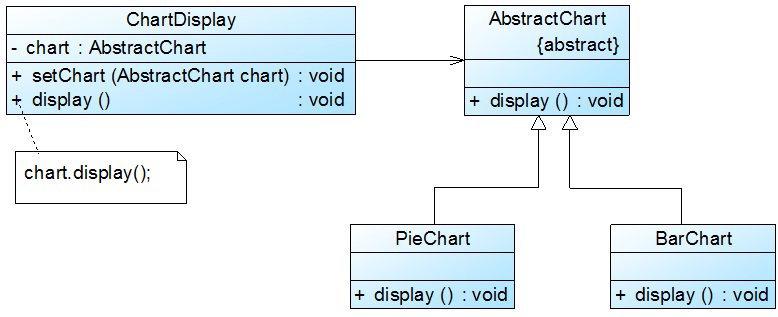
图2 重构后的结构图
在图2中,我们引入了抽象图表类AbstractChart,且ChartDisplay针对抽象图表类进行编程,并通过setChart()方法由客户端来设置实例化的具体图表对象,在ChartDisplay的display()方法中调用chart对象的display()方法显示图表。如果需要增加一种新的图表,如折线图LineChart,只需要将LineChart也作为AbstractChart的子类,在客户端向ChartDisplay中注入一个LineChart对象即可,无须修改现有类库的源代码
里氏代换原则
理解为:所有引用基类(父类)的地方必须能透明地使用其子类的对象。
其严格表述如下:如果对每一个类型为S的对象o1,都有类型为T的对象o2,使得以T定义的所有程序P在所有的对象o1代换o2时,程序P的行为没有变化,那么类型S是类型T的子类型。这个定义比较拗口且难以理解,因此我们一般使用它的另一个通俗版定义: 里氏代换原则(Liskov Substitution Principle, LSP):所有引用基类(父类)的地方必须能透明地使用其子类的对象。
里氏代换原则告诉我们,在软件中将一个基类对象替换成它的子类对象,程序将不会产生任何错误和异常,反过来则不成立,如果一个软件实体使用的是一个子类对象的话,那么它不一定能够使用基类对象。例如:我喜欢动物,那我一定喜欢狗,因为狗是动物的子类;但是我喜欢狗,不能据此断定我喜欢动物,因为我并不喜欢老鼠,虽然它也是动物。
里氏代换原则是实现开闭原则的重要方式之一,由于使用基类对象的地方都可以使用子类对象,因此在程序中尽量使用基类类型来对对象进行定义,而在运行时再确定其子类类型,用子类对象来替换父类对象。
在使用里氏代换原则时需要注意如下几个问题:
(1)子类的所有方法必须在父类中声明,或子类必须实现父类中声明的所有方法。根据里氏代换原则,为了保证系统的扩展性,在程序中通常使用父类来进行定义,如果一个方法只存在子类中,在父类中不提供相应的声明,则无法在以父类定义的对象中使用该方法。
(2) 我们在运用里氏代换原则时,尽量把父类设计为抽象类或者接口,让子类继承父类或实现父接口,并实现在父类中声明的方法,运行时,子类实例替换父类实例,我们可以很方便地扩展系统的功能,同时无须修改原有子类的代码,增加新的功能可以通过增加一个新的子类来实现。里氏代换原则是开闭原则的具体实现手段之一。
(3) Java语言中,在编译阶段,Java编译器会检查一个程序是否符合里氏代换原则,这是一个与实现无关的、纯语法意义上的检查,但Java编译器的检查是有局限的。
在Sunny软件公司开发的CRM系统中,客户(Customer)可以分为VIP客户(VIPCustomer)和普通客户(CommonCustomer)两类,系统需要提供一个发送Email的功能,原始设计方案如图1所示:
图1原始结构图
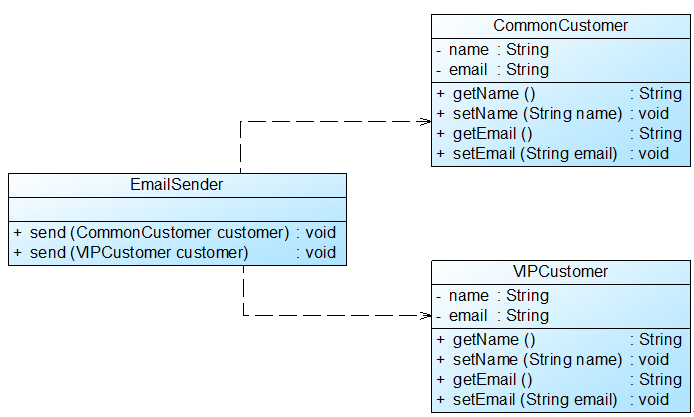
在对系统进行进一步分析后发现,无论是普通客户还是VIP客户,发送邮件的过程都是相同的,也就是说两个send()方法中的代码重复,而且在本系统中还将增加新类型的客户。为了让系统具有更好的扩展性,同时减少代码重复,使用里氏代换原则对其进行重构。
在本实例中,可以考虑增加一个新的抽象客户类Customer,而将CommonCustomer和VIPCustomer类作为其子类,邮件发送类EmailSender类针对抽象客户类Customer编程,根据里氏代换原则,能够接受基类对象的地方必然能够接受子类对象,因此将EmailSender中的send()方法的参数类型改为Customer,如果需要增加新类型的客户,只需将其作为Customer类的子类即可。重构后的结构如图2所示:
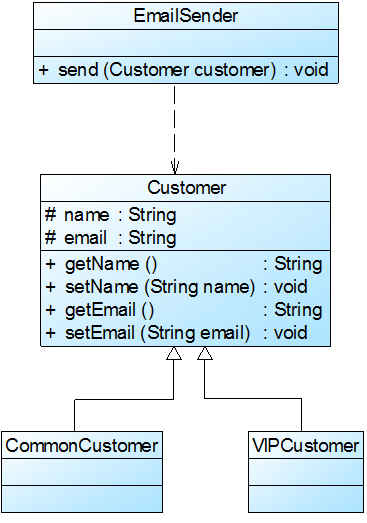
图2 重构后的结构图
里氏代换原则是实现开闭原则的重要方式之一。在本实例中,在传递参数时使用基类对象,除此以外,在定义成员变量、定义局部变量、确定方法返回类型时都可使用里氏代换原则。针对基类编程,在程序运行时再确定具体子类。
依赖倒转原则
理解为:高层模块不应该依赖低层模块,二者都应该依赖其抽象高层模块不应该依赖低层模块,二者都应该依赖其抽象
抽象不应该依赖细节,细节应该依赖抽象抽象不应该依赖细节,细节应该依赖抽象
中心思想:面向接口编程依赖倒转(倒置)的中心思想是面向接口编程使用接口或抽象类的目的是制定好规范,而不涉及任何具体的操作,把展现细节的任务交给他们的实现类去完成使用接口或抽象类的目的是制定好规范,而不涉及任何具体的操作,把展现细节的任务交给他们的实现类去完成。
接口隔离原则
理解为:复杂的接口要拆分成多个小接口,类似单一原则。
合成复用原则
理解为:复用时要尽量使用组合/聚合关系(关联关系),少用继承。
迪米特法则
理解为:一个软件实体应当尽可能少地与其他实体发生相互作用。
六个创建型模式
简单工厂模式-Simple Factory Pattern
定义:定义一个工厂类,它可以根据参数的不同返回不同类的实例,被创建的实例通常都具有共同的父类。因为在简单工厂模式中用于创建实例的方法是静态(static)方法,因此简单工厂模式又被称为静态工厂方法(Static Factory Method)模式,它属于类创建型模式。
简单工厂模式的要点在于:当你需要什么,只需要传入一个正确的参数,就可以获取你所需要的对象,而无须知道其创建细节。简单工厂模式结构比较简单,其核心是工厂类的设计。
1、核心设计一
class Factory { //静态工厂方法 public static Product getProduct(String arg) { Product product = null; if (arg.equalsIgnoreCase("A")) { product = new ConcreteProductA(); //初始化设置product } else if (arg.equalsIgnoreCase("B")) { product = new ConcreteProductB(); //初始化设置product } return product; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
简单工厂模式总结
简单工厂模式提供了专门的工厂类用于创建对象,将对象的创建和对象的使用分离开,它作为一种最简单的工厂模式在软件开发中得到了较为广泛的应用。
- 主要优点
简单工厂模式的主要优点如下:
(1) 工厂类包含必要的判断逻辑,可以决定在什么时候创建哪一个产品类的实例,客户端可以免除直接创建产品对象的职责,而仅仅“消费”产品,简单工厂模式实现了对象创建和使用的分离。
(2) 客户端无须知道所创建的具体产品类的类名,只需要知道具体产品类所对应的参数即可,对于一些复杂的类名,通过简单工厂模式可以在一定程度减少使用者的记忆量。
(3) 通过引入配置文件,可以在不修改任何客户端代码的情况下更换和增加新的具体产品类,在一定程度上提高了系统的灵活性。
- 主要缺点
简单工厂模式的主要缺点如下:
(1) 由于工厂类集中了所有产品的创建逻辑,职责过重,一旦不能正常工作,整个系统都要受到影响。
(2) 使用简单工厂模式势必会增加系统中类的个数(引入了新的工厂类),增加了系统的复杂度和理解难度。
(3) 系统扩展困难,一旦添加新产品就不得不修改工厂逻辑,在产品类型较多时,有可能造成工厂逻辑过于复杂,不利于系统的扩展和维护。
(4) 简单工厂模式由于使用了静态工厂方法,造成工厂角色无法形成基于继承的等级结构。
- 适用场景
在以下情况下可以考虑使用简单工厂模式:
(1) 工厂类负责创建的对象比较少,由于创建的对象较少,不会造成工厂方法中的业务逻辑太过复杂。
(2) 客户端只知道传入工厂类的参数,对于如何创建对象并不关心。
工厂方法模式-Factory Method Pattern
理解为:充分利用,继承,接口,抽象,降低耦合。不用修改源码等。每一个具体工厂对应一种具体产品
抽象工厂模式-Abstract Factory Pattern
理解为:一个产品有多个品牌,所有品牌都是由工厂生产。
单例模式-Singleton Pattern
适用场景:
(1) 系统只需要一个实例对象,如系统要求提供一个唯一的序列号生成器或资源管理器,或者需要考虑资源消耗太大而只允许创建一个对象。(2) 客户调用类的单个实例只允许使用一个公共访问点,除了该公共访问点,不能通过其他途径访问该实例。
可以理解为:为了节约系统资源,有时需要确保系统中某个类只有唯一一个实例,当这个唯一实例创建成功之后,我们无法再创建一个同类型的其他对象,所有的操作都只能基于这个唯一实例。
- 饿汉式单例类
无须考虑多线程访问问题
class EagerSingleton { private static final EagerSingleton instance = new EagerSingleton(); private EagerSingleton() { } public static EagerSingleton getInstance() { return instance; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 懒汉式单例类与线程锁定
class LazySingleton { private static LazySingleton instance = null; private LazySingleton() { } //有线程安全问题,加上线程关键字synchronized进行线程锁 synchronized public static LazySingleton getInstance() { if (instance == null) { instance = new LazySingleton(); } return instance; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
上述代码性能不好,有了一下改进,但还是不完美。
class LazySingleton { //被volatile修饰的成员变量可以确保多个线程都能够正确处理 private volatile static LazySingleton instance = null; private LazySingleton() { } public static LazySingleton getInstance() { //第一重判断 if (instance == null) { //锁定代码块 synchronized (LazySingleton.class) { //第二重判断 if (instance == null) { instance = new LazySingleton(); //创建单例实例 } } } return instance; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
———————————————————————————————
饿汉式单例类不能实现延迟加载,不管将来用不用始终占据内存;懒汉式单例类线程安全控制烦琐,而且性能受影响。可见,无论是饿汉式单例还是懒汉式单例都存在这样那样的问题,有没有一种方法,能够将两种单例的缺点都克服,而将两者的优点合二为一呢?答案是:Yes!下面我们来学习这种更好的被称之为Initialization Demand Holder (IoDH)的技术。
//Initialization on Demand Holder class Singleton { private Singleton() { } private static class HolderClass { //初始化的时候不会加载内部类 private final static Singleton instance = new Singleton(); } public static Singleton getInstance() { return HolderClass.instance; } public static void main(String args[]) { Singleton s1, s2; s1 = Singleton.getInstance(); s2 = Singleton.getInstance(); System.out.println(s1==s2); //true } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
此外还可以改写为多例类。
原型模式-Prototype Pattern
- 对象的克隆——原型模式
包含角色:
- Prototype(抽象原型类):它是声明克隆方法的接口,是所有具体原型类的公共父类,可以是抽象类也可以是接口,甚至还可以是具体实现类。
- ConcretePrototype(具体原型类):它实现在抽象原型类中声明的克隆方法,在克隆方法中返回自己的一个克隆对象。
- Client(客户类):让一个原型对象克隆自身从而创建一个新的对象,在客户类中只需要直接实例化或通过工厂方法等方式创建一个原型对象,再通过调用该对象的克隆方法即可得到多个相同的对象。由于客户类针对抽象原型类Prototype编程,因此用户可以根据需要选择具体原型类,系统具有较好的可扩展性,增加或更换具体原型类都很方便。
示意代码如下所示:
class ConcretePrototype implements Prototype { private String attr; //成员属性 public void setAttr(String attr) { this.attr = attr; } public String getAttr() { return this.attr; } public Prototype clone() //克隆方法 { Prototype prototype = new ConcretePrototype(); //创建新对象 prototype.setAttr(this.attr); return prototype; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
客户端代码:
Prototype obj1 = new ConcretePrototype(); obj1.setAttr("Sunny"); Prototype obj2 = obj1.clone();- 1
- 2
- 3
Java源码分析,以ArrayList为例:
//这两行为克隆list ArrayList list = new ArrayList(); ArrayList clone = (ArrayList) list.clone(); //ArrayList中的源码 public Object clone() { try { ArrayList<?> v = (ArrayList<?>) super.clone(); v.elementData = Arrays.copyOf(elementData, size); v.modCount = 0;//盲猜修改次数更新为0 return v; } catch (CloneNotSupportedException e) { // this shouldn't happen, since we are Cloneable throw new InternalError(e); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
一般而言,Java语言中的clone()方法满足:
(1) 对任何对象x,都有x.clone() != x,即克隆对象与原型对象不是同一个对象;
(2) 对任何对象x,都有x.clone().getClass() == x.getClass(),即克隆对象与原型对象的类型一样;
(3) 如果对象x的equals()方法定义恰当,那么x.clone().equals(x)应该成立。
为了获取对象的一份拷贝,我们可以直接利用Object类的clone()方法,具体步骤如下:
(1) 在派生类中覆盖基类的clone()方法,并声明为public;
(2) 在派生类的clone()方法中,调用super.clone();
(3)派生类需实现Cloneable接口。
此时,Object类相当于抽象原型类,所有实现了Cloneable接口的类相当于具体原型类
1.2 浅克隆和深克隆
浅克隆和深克隆的主要区别在于是否支持引用类型的成员变量的复制。以下是浅拷贝,无法拷贝引用类型成员变量。
@Data public class Blog implements Cloneable{ // 实现这个接口才可以浅拷贝 private Integer status; Files files;//随便一个类都可以 public Blog clone() { Object object = null; try { object = super.clone(); } catch (CloneNotSupportedException exception) { System.err.println("Not support cloneable"); } return (Blog) object; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
Blog blog = new Blog(); Blog blogClone = blog.clone(); System.out.println(blog.getFiles() == blogClone.getFiles());//true- 1
- 2
- 3
以下是深拷贝
首先要被拷贝的实体都需要实现 Serializable 接口,保证能被序列化。
让后自己写拷贝函数,这样就可以将被拷贝的对象全部拷贝。public Blog deepClone() throws IOException, ClassNotFoundException, OptionalDataException { //将对象写入流中 ByteArrayOutputStream bao=new ByteArrayOutputStream(); ObjectOutputStream oos=new ObjectOutputStream(bao); oos.writeObject(this); //将对象从流中取出 ByteArrayInputStream bis=new ByteArrayInputStream(bao.toByteArray()); ObjectInputStream ois=new ObjectInputStream(bis); return (Blog) ois.readObject(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
建造者模式-Builder Pattern
在以下情况下可以考虑使用建造者模式:
(1) 需要生成的产品对象有复杂的内部结构,这些产品对象通常包含多个成员属性。
(2) 需要生成的产品对象的属性相互依赖,需要指定其生成顺序。
(3) 对象的创建过程独立于创建该对象的类。在建造者模式中通过引入了指挥者类,将创建过程封装在指挥者类中,而不在建造者类和客户类中。
(4) 隔离复杂对象的创建和使用,并使得相同的创建过程可以创建不同的产品。
链接:https://blog.csdn.net/SEU_Calvin/article/details/52249885
七个结构型模式
适配器模式-Adapter Pattern
链接:https://blog.csdn.net/sunqiang4/article/details/119878377
桥接模式-Bridge Pattern
在正式介绍桥接模式之前,我先跟大家谈谈两种常见文具的区别,它们是毛笔和蜡笔。假如我们需要大中小3种型号的画笔,能够绘制12种不同的颜色,如果使用蜡笔,需要准备3×12 = 36支,但如果使用毛笔的话,只需要提供3种型号的毛笔,外加12个颜料盒即可,涉及到的对象个数仅为 3 + 12 = 15,远小于36,却能实现与36支蜡笔同样的功能。如果增加一种新型号的画笔,并且也需要具有12种颜色,对应的蜡笔需增加12支,而毛笔只需增加一支。为什么会这样呢?通过分析我们可以得知:在蜡笔中,颜色和型号两个不同的变化维度(即两个不同的变化原因)融合在一起,无论是对颜色进行扩展还是对型号进行扩展都势必会影响另一个维度;但在毛笔中,颜色和型号实现了分离,增加新的颜色或者型号对另一方都没有任何影响。如果使用软件工程中的术语,我们可以认为在蜡笔中颜色和型号之间存在较强的耦合性,而毛笔很好地将二者解耦,使用起来非常灵活,扩展也更为方便。在软件开发中,我们也提供了一种设计模式来处理与画笔类似的具有多变化维度的情况,即本章将要介绍的桥接模式。
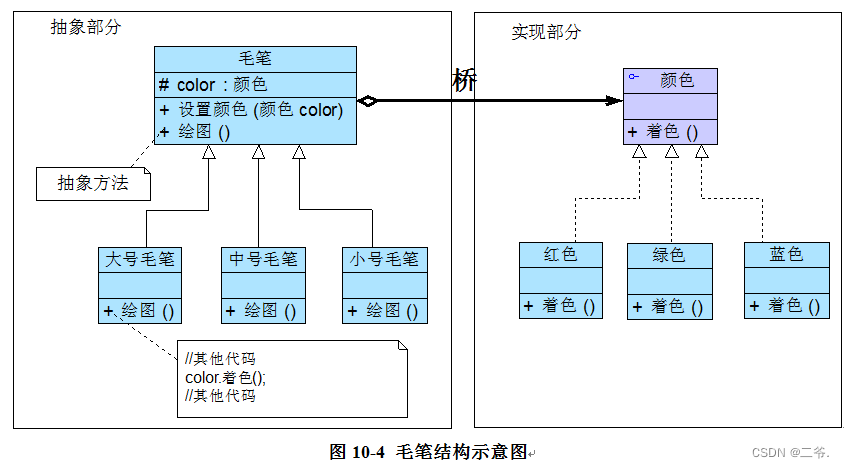
链接:https://blog.csdn.net/weixin_39296283/article/details/104953668组合模式-Composite Pattern
-
相关阅读:
【Cherno的C++视频】Writing iterators in C++
题目新颖,内容全面!阿里巴巴又一 Java 面试神册开源!
RabbitMQ坑大全
安卓文件权限总结
Android 面经总结分享(相当走心)
【英语:语法基础】B2.核心语法-动词
readhat8搭建SFTP双机高可用并配置Rsync数据实时同步
Leetcode 53. 最大子数组和
MySQL 及 jdbc 问题汇总
MySQL阅读网上MySQL文章有感的杂记
- 原文地址:https://blog.csdn.net/qq_43773170/article/details/126345270


