-
【时间序列】流式多变量异常检测数据集NAB详细介绍
一、前言
前段时间整理了一下 多变量时间序列异常检测的数据集,以及对应数据集统一格式处理代码的文章。
文章在这:https://zhuanlan.zhihu.com/p/544335741
今天介绍的也是多变量时间序列异常检测的数据集。但这个数据集和之前那篇文章的数据集是两种,虽然都可以这么称呼,但形势和背景目的截然不同,但也存在关联。
对于多个时间序列,这里我们简称为线,多个线,每个线有单独的异常的区间(单个异常检测模型判定的异常区间),如果这些线独立,并且不代表一个载体上,则就是每个线的异常,如果这些线都存在一个载体上,比如机器上,那某条线单独的异常区间可能并不能代表机器的异常,或者多条线的异常(一种pattern)也不代表机器的异常,多条线的异常组合可能是机器一种健康状态下的pattern。
1.1 区别
1.1.1 异常维度
前者 是 线的维度异常,但有多条线,并非一条线。数据集格式
后者 是 entity维度异常,一个entity有多条线。
1.1.2 数据格式
前者 是 多个时间序列, 每个时间序列都有对应的异常区间的label
后者 是 每个实体有多个时间序列,每个实体在某一个时间点是否存在异常,这里可以查看之前写的那篇文章数据集的格式
1.1.3 场景
前者 是 流式异常检测场景,追求实时。
后者 多用于机器异常检测,或某个传感器装置异常检测故障诊断场景。
二、NAB数据集
2.1 简介
NAB 是一种新的基准,用于评估流式实时应用程序中的异常检测算法。它由超过 50 个标记的真实世界和人工时间序列数据文件 NAB数据集是Numenta公司开源的用于评估流式时序异常检测算法的公开数据集。它由超过50个带label的真实世界和人工时间序列数据文件组成。
链接:https://github.com/numenta/NAB
数据链接:https://github.com/numenta/NAB/tree/master/data
2.2 数据详情
包括真实数据集和人生生成的数据集
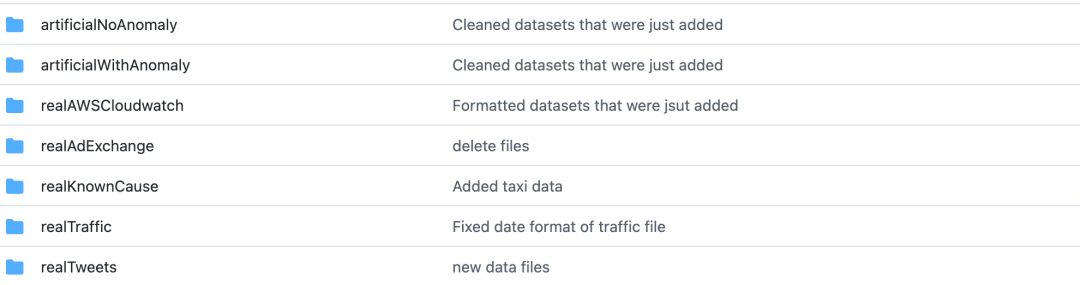
详情 请看:https://github.com/numenta/NAB/blob/master/data/README.md
主要包含交通,广告点击率,机器等数据
label数据在:https://github.com/numenta/NAB/tree/master/labels/raw

2.3 数据格式
2.3.1 时间序列文件
打开一个数据的格式。
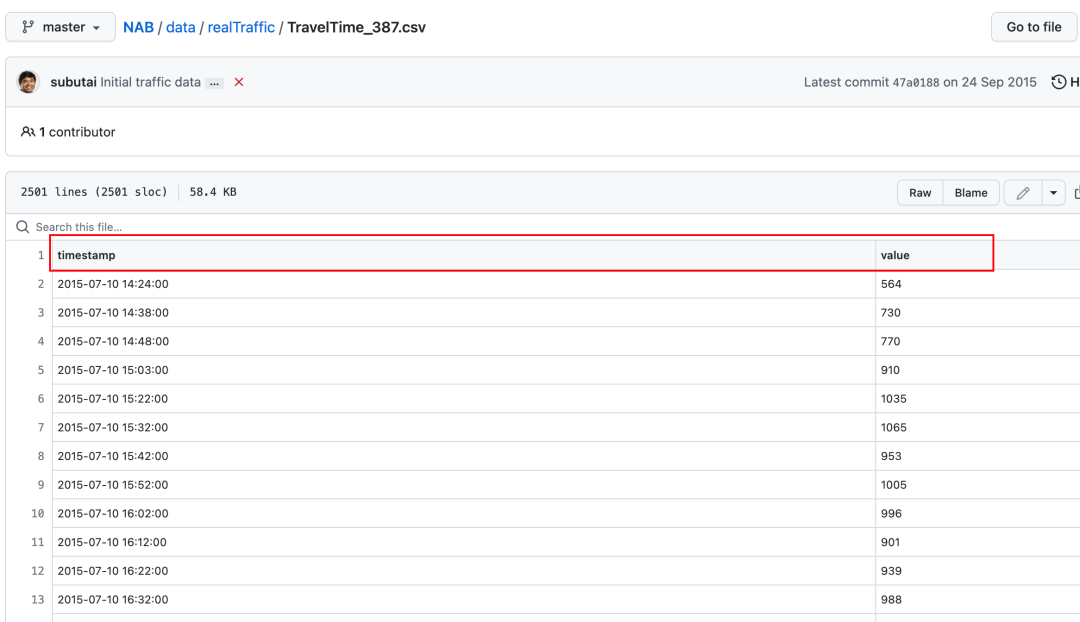
所有的数据已经标准化,都是两列,一列是timestamp,另外一列是value值。
2.3.2 label文件
格式如下,保存格式是json

key是文件名
value是一个list,里面包含异常的点的timestamp
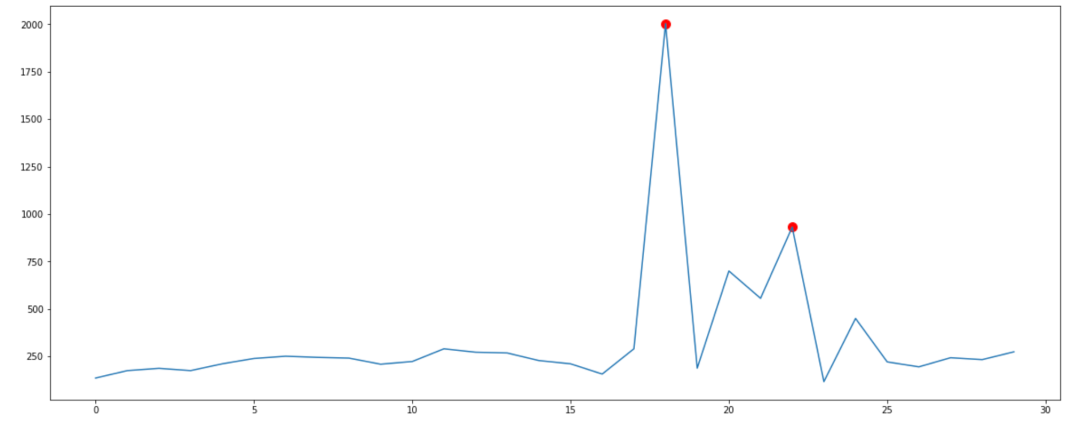
2.4 可视化
这里我挑选 './data/realTraffic/TravelTime_387.csv'进行了可视化
只展示了前两个异常点:
三、总结
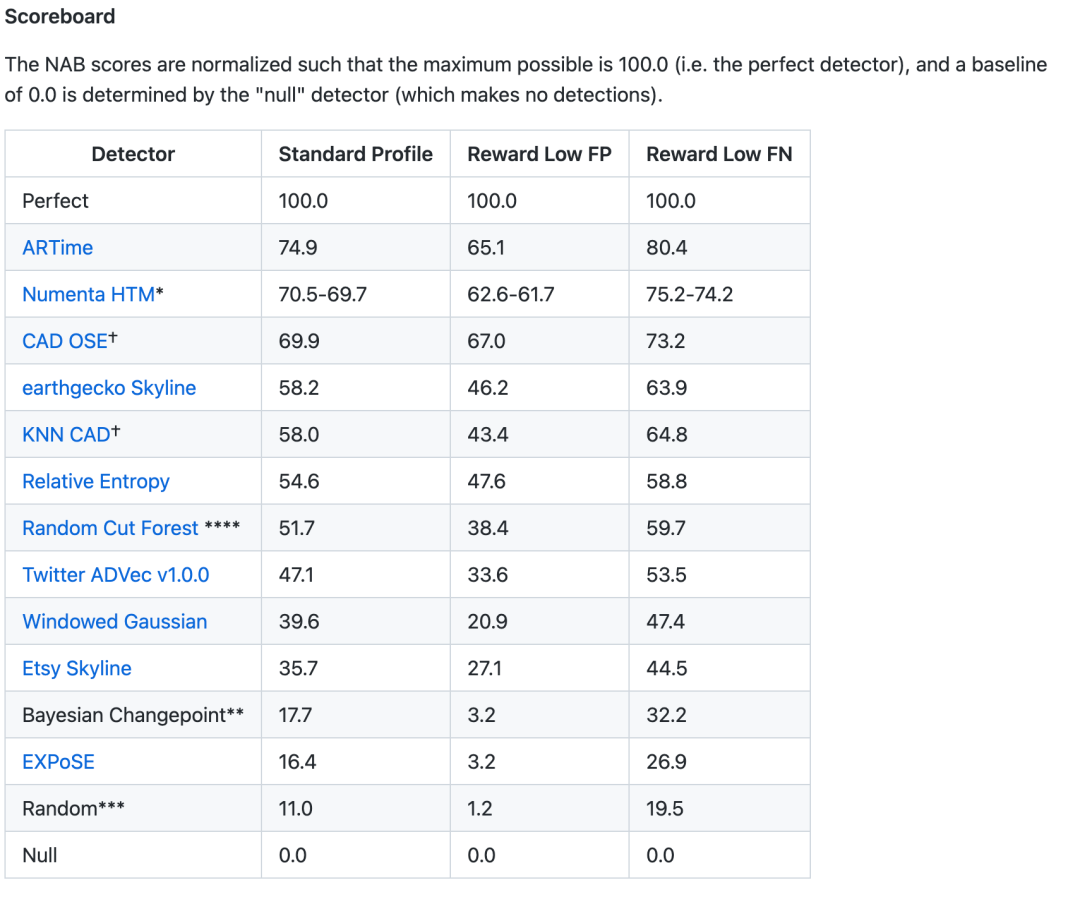
该仓库还整理了若干近年来许多流式异常检测算法包以及评价函数,具体看仓库吧内容很多~
推荐阅读:
- 我的2022届互联网校招分享
- 我的2021总结
- 浅谈算法岗和开发岗的区别
- 互联网校招研发薪资汇总
- 2022届互联网求职现状,金9银10快变成铜9铁10!!
- 公众号:AI蜗牛车
- 保持谦逊、保持自律、保持进步
- 发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
- 发送【1222】获取一份不错的leetcode刷题笔记
- 发送【AI四大名著】获取四本经典AI电子书
-
相关阅读:
B+ 树的简单认识
redis初级介绍
冰蝎默认加密的流量解密
3.前端调式
Linux网络技术学习(四)—— 用户空间与内核的接口
Deforum提示词---『阿里云』万物皆可AIGC,爱视频就来AI视频!
vue使用qrcodejs2生成二维码
【Java Web】使用ajax在论坛中发布帖子
F - Thanos Sort
Flink系列文档-(YY05)-Flink编程API-多流算子
- 原文地址:https://blog.csdn.net/qq_33431368/article/details/126338845
