-
ServiceWorker 介绍
引言
我们经常可以听到 Worker 这个名词,比如本文要介绍的 ServiceWorker 后面就带着一个 Worker 的单词,那么 Worker 实际上指的是什么呢?
在介绍 Worker 的定义之前,先来回忆一下浏览器的渲染原理。
在一个 tab 打开的时候,浏览器会给这个 tab 创建一个新的渲染进程(renderer process),如下图:
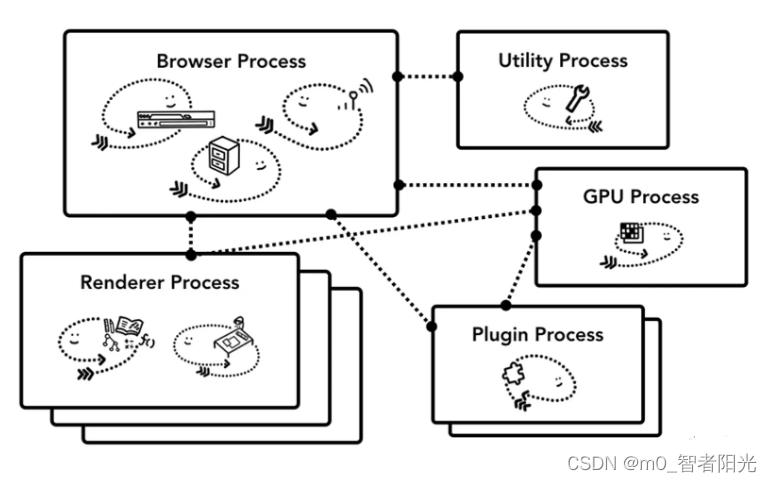
在每一个渲染进程中,都会有一个主线程(Main Thread),负责 JavaScript 的执行以及浏览器的渲染(JavaScript 的执行与 UI 渲染是一个互相阻塞的流程)。
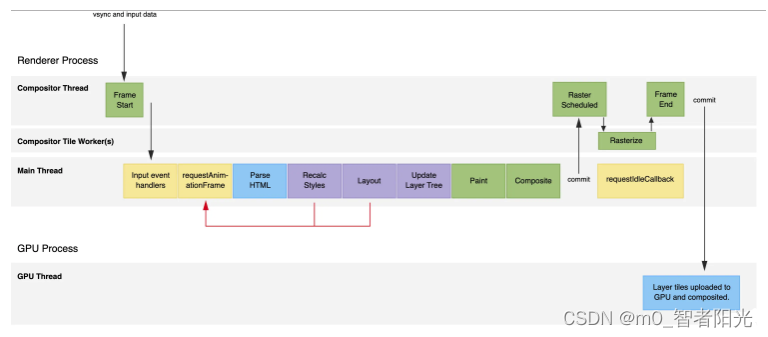
如果 JavaScript 执行时间过久(比如超过 33.33 ms),那么一帧内留给 UI 渲染的时间不多,如果这时候网页有正在执行的动画,那么用户就会感受到卡顿。
10 FPS:能够达成基本的视觉残留(参考:定格动画至少需要 12 帧每秒以上)
30 FPS以下:让人感觉到明显的卡顿和不适感
30-50 FPS:因人而异
50-60 FPS:流畅
一个 Worker,指的是一个可以在后台独立执行 JavaScript 脚本。它存在于一个单独的 worker 线程,即使执行一些长任务也不会阻塞主线程响应用户操作(如鼠标点击、动画等)。
另外 Worker 也指使用
new Worker()构造函数创建的一个对象,可以用在主线程与 worker 线程的通信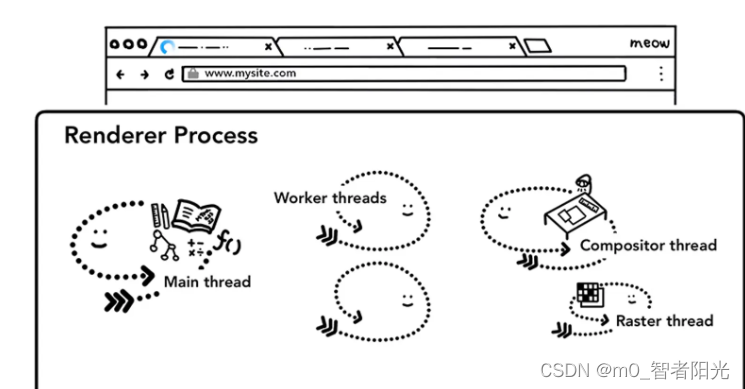
Worker 与 主线程之间可以通过
postMessage进行通信: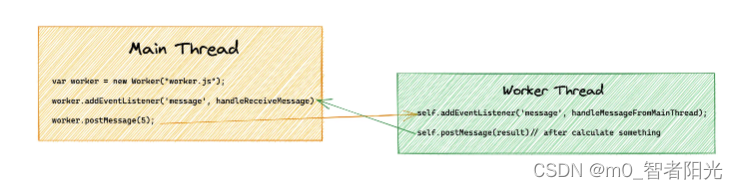
worker 线程与主线程通信方式
Worker 一般有其独立的上下文:WorkerGlobalScope,其全局变量一般用 self 来表示,如果使用 window 则会报错
ServiceWorker 介绍
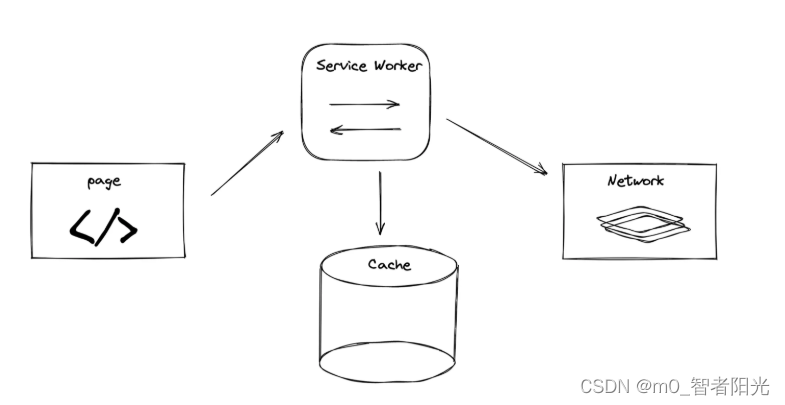
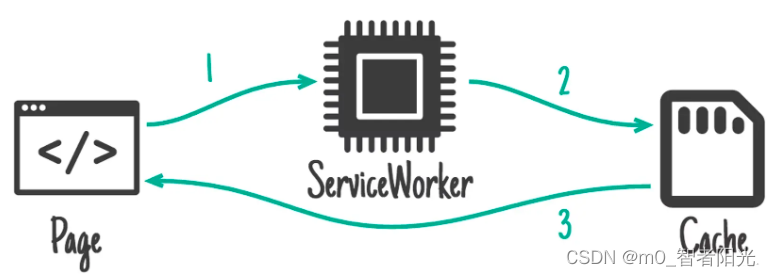
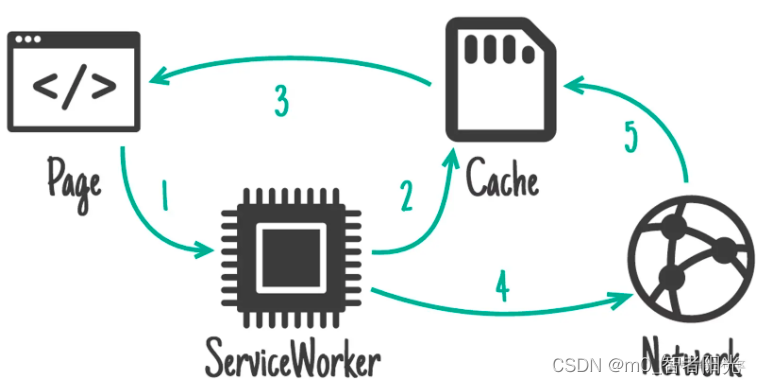
本文要介绍的 ServiceWorker 是一种特化的 Worker,专门来处理跟网页有关的资源(assets),在浏览器和真正的服务端之间扮演一个代理(Proxy)的角色。ServiceWorker 同时引入了缓存(Cache),可以用来存储一个网络响应。
下文会继续介绍 Cache 相关的知识。
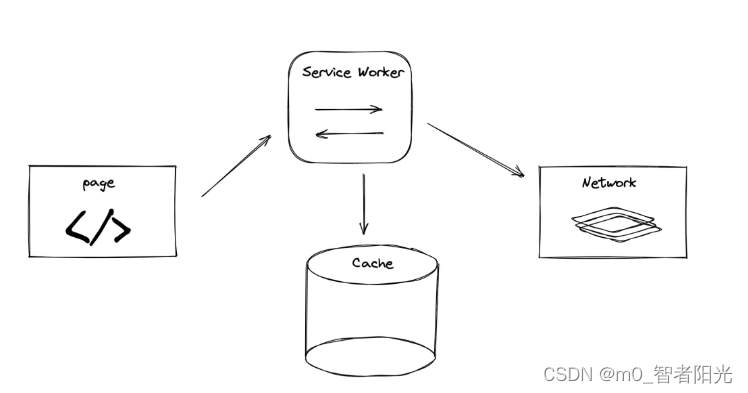
图:ServiceWorker 中重要的几个角色
一般来说,ServiceWorker 处理的就是页面与缓存、服务器之间的关系(下文有详细介绍)。
ServiceWorker 的出现是为了解决下面的两个问题:
- 离线请求(提供类似于 App 的用户体验,类 App 的生命周期)
- 性能优化
Cache
由于 ServiceWorker 是一种特化型 Worker,它专门处理资源相关的逻辑,简单来说就是做一些缓存(但不止与此),下面先介绍一下 ServiceWorker 做缓存用到的一个底层 API:Cache
Cache 提供一个
Request -> Response的持久缓存,除非显式删除,存储在 Cache 里面的数据不会主动过期,同时也不会主动去更新,需要手动维护其更新。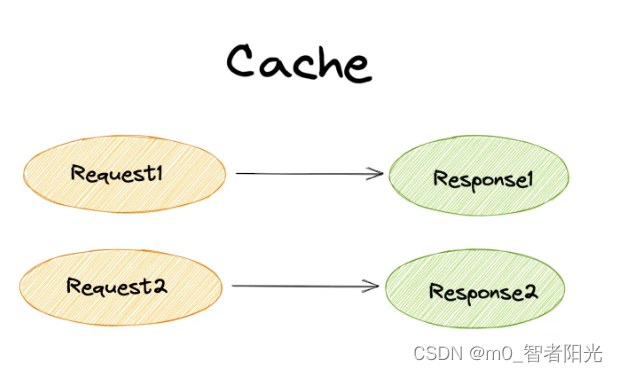
图:Cache 存储的是 Request -> Response 的键值对
Cache 基础用法
一个域之内可以存在多个 Cache,可以通过一个名字来标识对应的 Cache:
可以通过 CacheStorage 来获取对应 Cache 对象,有同源策略
- // caches extends CacheStorage,是 window / self 上面的一个全局变量
- // 下面是通过一个 cacheName 来获取对应的缓存对象
- const cache = await caches.open('hello-cache-v1');
然后可以通过
Cache.put方法将缓存设置进去- const request = new Request('/samples/service-worker/basic/', { method: 'GET' })
- const response = await fetch(request)
- const cache = await caches.open('hello-cache-v1');
- cache.put(request, response)
结果如下:
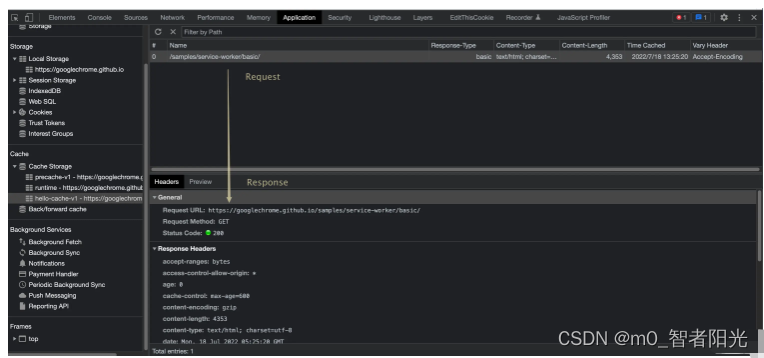
下一次获取的时候可以:
- const request = new Request('/samples/service-worker/basic/', { method: 'GET' })
- const cache = await caches.open('hello-cache-v1');
- const matchResponse = await cache.match(request) // 此处可以获取上次存储的 Response
- // 如果是带上路由 query 参数的形式
- const request2 = new Request('/samples/service-worker/basic/?a=1', { method: 'GET' })
- const matchResponse = await cache.match(request2, { ignoreSearch: false }) // 如果ignoreSearch=false(默认) 的情况下,此时匹配不上
上述即为 Cache 最基础的用法,另外 Cache 还提供了一些更加简便的方法,比如直接写入 url 即可自动请求缓存的
Cache.addAll方法等Cache 匹配逻辑
其中 match 方法的 options 中,
ignoreMethod,ignoreSearch,ignoreVary选项可能会影响最后匹配的结果- 判断 Method 是否匹配,是则继续下一步
- 判断 url 是否匹配,是则继续下一步
- 如果 Response 的 header 不包含
Vary,则匹配该 Response,否则下一步 - 匹配 Vary 对应的各种 header 字段
其实在实际操作中,一般很少将实际发出的 Request 和 Response 直接缓存在 Cache 中,一般都会经过一层复制,以获得更自由的控制:
可以参考 workbox 源码:copyResponse.ts,将 Response 进行一层 clone
- const request = new Request('/?a=1', { method: 'GET' })
- const response = await fetch(request)
- const url = new URL(request.url);
- url.search = ''
- const requestWillCache = new Request(url, {...request})
- const clonedResponse = response.clone();
- const responseInit = {
- headers: new Headers({...clonedResponse.headers, 'vary': 'Content-Type'}),
- status: clonedResponse.status,
- statusText: clonedResponse.statusText,
- };
- const body = clonedResponse.body
- const responseWillCache = new Response(body, responseInit);
- cache.put(requestWillCache, responseWillCache)
Cache 容量
每一个域名可用的空间不一样,可以通过下面的代码获取:
- const estimate = await navigator.storage.estimate();
- const usage = estimate.usage / estimate.quota * 100).toFixed(2);
作用范围与客户端
介绍完 Cache 之后,我们将重新聚焦回本文的主角 ServiceWorker
作用范围 Scope
一个 ServiceWorker 可以被多个页面注册,但是一个页面只允许注册一个 ServiceWorker
一个 ServiceWorker 会有一个作用范围(Scope),表示在这个范围内的页面才可以注册该 ServiceWorker,默认的作用范围是 ServiceWorker 所在路径的上一级。
如:路径是
/subdir/sw.js的 ServiceWorker,其作用范围默认是/subdir/**,因此/subdir/**下面的页面(如/subdir/a.html)可以正常注册该 ServiceWorker。如果有一个超出作用范围的页面(如
/subdir2/b.html)想要注册该 ServiceWorker,浏览器就会报错。要解决这种报错,可以通过下面的方式来设置:- 在注册 ServiceWorker 的时候,显示指定一个作用范围
- navigator.serviceWorker.register("/subdir/sw.js", { scope: "/" })
- .then(() => {
- console.log("安装成功,scope 被调整为 '/'");
- });
- 同时在 ServiceWorker js 文件的请求上加上 HTTP 相应头
Service-Worker-Allowed : /
只有当响应头和注册时候显示指定作用范围,才能够注册成功
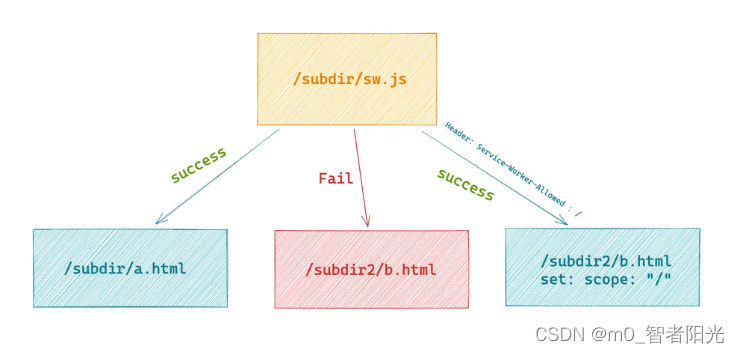
图:ServiceWorker 的作用范围
客户端 Client
对于 ServiceWorker 来说,一个页面是其控制的一个客户端
ServiceWorker 也可以作用于其他 Worker
可以通过 Worker 中的
Clients来获取当前 ServiceWorker 控制客户端的实例
- const allClients = await clients.matchAll({
- includeUncontrolled: true, // 更新 serviceWorker 的时候可能有一些还没生效
- type: "window", "worker", "sharedworker" or "all", // 默认是 “window”
- });
生命周期
ServiceWorker 设置生命周期的目的是:
- 使得离线使用成为可能(APP式的体验)
- 允许一个新版本的 ServiceWorker 准备好,而不影响当前正在发挥作用的 ServiceWorker
- 可以确保一个页面在其生命周期内始终被同一个 ServiceWorker 控制或者不被 ServiceWorker 控制
- 可以确保一个时刻只有一个版本的 ServiceWorker 正在运行
为什么要强调一个时刻内只有一个版本的 ServiceWorker 正在运行呢?
想象一下这个场景:当你打开一个页面被 ServiceWorkerV1 控制了,然后打开一个相同路径的 tab,然后这个 tab 被一个另一个 ServiceWorkerV2 控制,但是他们的缓存逻辑可能不一样,比如 V2 版本可能会清空一些它用不到的缓存,而这个缓存可能恰好是 V1 版本必须的时候,就有可能会导致一些错误、数据丢失的问题。
另外,必要的时候,其实可以通过一些操作来覆盖这种默认行为
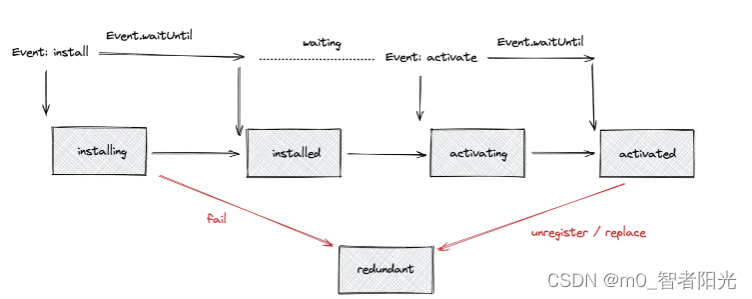
图:ServiceWorker 生命周期
Install
注册之后会先触发
install事件,如果event.waitUntil有传入 promise,当 promise 为resolved状态的时候,该事件才算完成,然后到下一个状态。如果 promise 被rejected,那么 ServiceWorker 注册失败。如果 ServiceWorker 代码中存在语法等错误,那么注册也会失败,并且不会生效
Install 事件在 ServiceWorker 更新前只会运行一次
- // entry.html
- // sw.js
- self.addEventListener('install', event => {
- console.log('V1 installing…');
- // 可以在这个时机进行一些后续处理必须的前置缓存处理(Precaching)
- event.waitUntil(
- caches.open('static-v1').then(cache => cache.add('/cat.svg'))
- );
- });
Activate
当 ServiceWorker 准备好控制客户端,并且可以处理类似
sync、push事件的时候,就会触发activate事件进入 activating 状态。一般情况下,在 ServiceWorker 更新的时候,才会有较长的 installed -> activating 中间的 waiting 状态,因为其需要等旧的 ServiceWorker 卸载才能控制新的页面。
首次则是直接到达 installed 状态之后直接会触发
activate事件进入 activating 状态需要注意的是:首次注册 ServiceWorker 之后页面并不会马上被 ServiceWorker 控制,一般情况下,页面需要通过 ServiceWorker 请求之后,后面才会被 ServiceWorker 控制。
如果想要不重新加载页面来激活 ServiceWorker,可以使用
clients.claim()覆盖默认行为,该方法可以让 ServiceWorker 跳过等待状态,直接控制页面。一般可以在 Activate 这个阶段处理上一个 ServiceWorker 相关的动作,如:
- 清除、迁移上一个版本 ServiceWorker Cache 数据
另外,ServiceWorker 安装的时候,activate 事件返回一个 reject promise 暂时是一个未定义的行为,所以需要额外关注,详情看下面两个 Issue
一般而言,这个步骤不应该存在“失败”的状态
#659 There should be no such thing as "fail to activate"
#1372 Clarification on what happens during a terminated activation
更新
一般 ServiceWorker 更新是在下面的时机上触发的:
- 用户访问到 ServiceWorker 控制范围下的页面
- 浏览器触发给 ServiceWorker 的
push或者sync事件(过去 24h 内触发过的可能会不再检查更新) - 当页面通过
register执行 ServiceWorker 注册,并且 url 跟上一次注册 url 不相同或者控制范围 Scope 的时候 - 页面可以手动执行 ServiceWorker 的
update方法来触发更新
很多浏览器在检查 ServiceWorker 更新的时候,都会忽略请求 header 上 cache 相关的字段
这个行为可以通过
updateViaCache来覆盖一般注册之后需要通过 unregister 来卸载,否则即使回退到没有 ServiceWorker 的版本,其也会继续生效。
ServiceWorker 更新是通过浏览器通过逐字节对比来确定的,如果 ServiceWorker 文件的字节发生了改变,那么会执行 ServiceWorker 更新操作,否则依旧使用旧的 ServiceWorker。
Worker 内部如果要加载其他脚本,有一个专门的方法
importScripts(),通过importScripts()方法加载的脚本也会进行逐字节对比使用该方法可以同时加载多个脚本。
新的 ServiceWorker 会有自己另外一个实例来执行其初始化操作,而不会影响当前正在运行的实例。
如果新的 ServiceWorker install 失败了,那么这个 ServiceWorker 将会被丢弃,旧的 ServiceWorker 会依旧生效
当 install 成功了之后,会进入 waiting 状态,知道旧的 ServiceWorker 实例不控制任何客户端(相关 tab 都关闭的情况下)
使用
self.skipWaiting()可以跳过这个 waiting 状态,直接使得新的实例生效,但是这时候要考虑新旧的无缝衔接注意一个特殊 case:当刷新页面的时候,当前页面不会卸载直到收到新的页面请求,这意味着刷新或者一些跳转操作不会使得新的 ServiceWorker 正常工作,而是使用旧的 ServiceWorker 实例
ServiceWorker 的更新其实有点类似于 Chrome 的更新,新版本安装了之后,需要点击一个按钮才生效
一个简单的使用例子
- const expectedCaches = ['static-v2'];
- self.addEventListener('install', event => {
- console.log('V2 installing…');
- // 下面的 svg 图片是执行后续操作的前提条件,所以放在 install 事件执行
- // 如果缓存失败了,意味着后续 ServiceWorker 逻辑不能正常运行
- // 而 install 事件失败的情况下,整个 ServiceWorker 会被丢弃,不会影响页面功能
- event.waitUntil(
- caches.open('static-v2').then(cache => cache.add('/horse.svg'))
- );
- });
- self.addEventListener('activate', event => {
- // 此处是旧的 ServiceWorker 不再控制客户端,新 ServiceWorker 准备接管的时机
- // 这个时候可以清理旧 ServiceWorker 的一些缓存,做一些数据迁移等操作
- event.waitUntil(
- caches.keys().then(keys => Promise.all(
- keys.map(key => {
- if (!expectedCaches.includes(key)) {
- return caches.delete(key);
- }
- })
- )).then(() => {
- console.log('V2 now ready to handle fetches!');
- })
- );
- });
- // 当客户端发起请求,会触发 fetch 事件
- // 这里的逻辑就是客户端与真正服务端之间的 proxy 角色
- // 可以通过 fetch 转发客户端请求,也可以返回客户端在 cache 中请求
- self.addEventListener('fetch', event => {
- const url = new URL(event.request.url);
- // serve the horse SVG from the cache if the request is
- // same-origin and the path is '/dog.svg'
- if (url.origin == location.origin && url.pathname == '/dog.svg') {
- event.respondWith(caches.match('/horse.svg'));
- }
- });
请求只走缓存,如果缓存不存在,则需要处理(如返回 404 页面)
缓存更新需要借助 ServiceWorker 主动更新(比如浏览器在空闲时候触发的 xx 事件)
Network only
请求只走网络,就像没有 ServiceWorker 一样
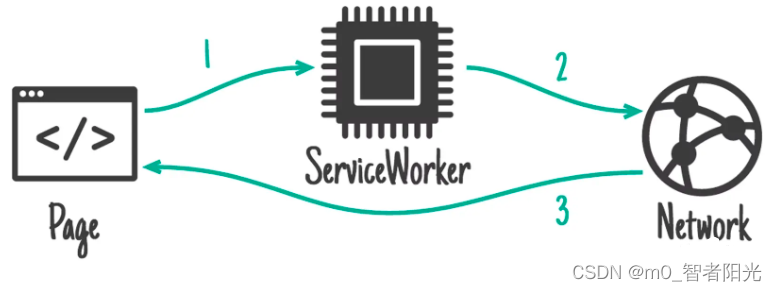
Cache first, falling back to network
如果缓存存在的话,先走缓存,否则兜底走网络
这种策略更像是原生 App 的更新策略
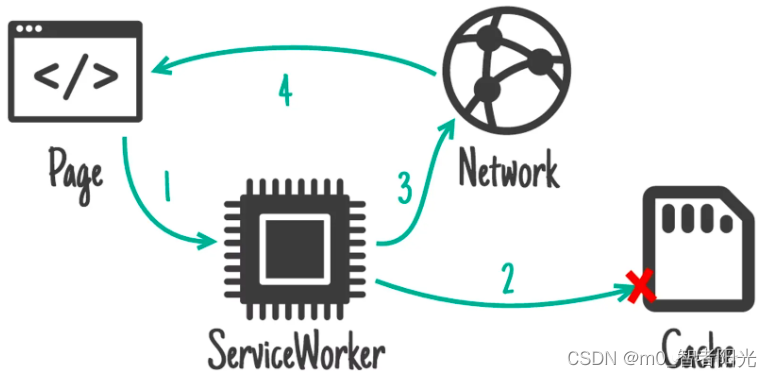
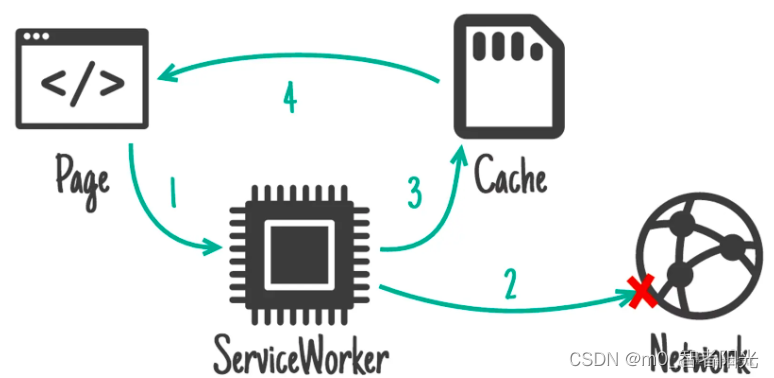
Network first, falling back to cache
如果网络请求正常的话,先走网络请求,否则兜底走缓存
这种策略是为了能够让用户在离线情况下也有一个好的体验,比如 Chrome 在断网情况下的小恐龙游戏
Stale-while-revalidate 异步缓存更新
这一种比较常见,如果当前有命中缓存,那么先给客户端返回一个缓存的响应,同时再发送一个请求去服务端,更新最新结果到缓存中。
这种策略一般常见于一些不经常变的数据,如用户信息数据、权限数据等,这种场景下如果数据变更之后,客户端还是读取旧的缓存不会引起致命的逻辑错误。
Workbox 介绍
Workbox 是什么
上面介绍了这么多种常见缓存策略,如果都用原生的 ServiceWorker 来实现,那么将会非常繁琐,同时 ServiceWorker 上手门槛比较高
而 google 开源的 Workbox 就是 ServiceWorker 的框架,主要目的是来简化 ServiceWorker 的使用,提供更加简单的方式来使用构建一个 ServiceWorker
WorkBox 是一个完整的 ServiceWorker 解决方案,其涵盖了一系列工具,包括构建、运行时等,这里只单独介绍使用频率更高的一些策略及其插件内容
Workbox 的策略
主要封装了上述介绍的一些策略,可以像下面一样简单地使用
- import {registerRoute} from 'workbox-routing';
- import {StaleWhileRevalidate} from 'workbox-strategies';
- registerRoute(
- // 标识命中怎么样的路由
- ({url}) => url.pathname.startsWith('/images/avatars/'),
- // 走 StaleWhileRevalidate 异步缓存策略
- new StaleWhileRevalidate()
- );
使用一种缓存策略就是上面几行代码,没了,就这么简单
Workbox 的策略描述的是下面三者的关系:
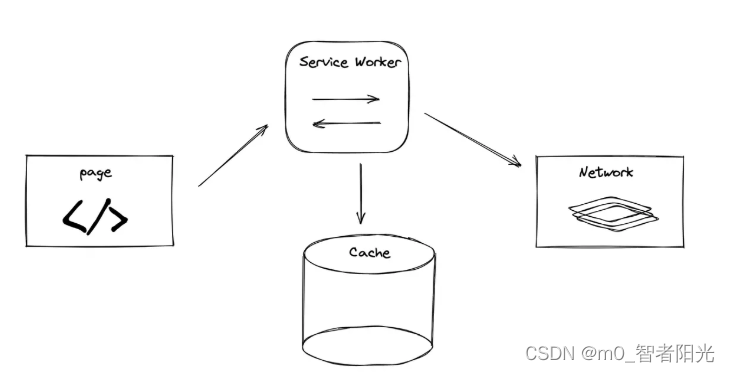
如果你需要这三者的关系跟上述的策略都不同,那么可以实现一个自定义的策略:
- import {Strategy} from 'workbox-strategies';
- // 自定义策略
- class NewStrategy extends Strategy {
- _handle(request, handler) {
- // handler 有 Workbox 封装好的各种工具函数,比如添加缓存:handler.cachePut(xxx)
- // 见:https://developer.chrome.com/docs/workbox/modules/workbox-strategies/#creating-a-new-strategy
- // Define handling logic here
- }
- }
实现自定义策略只需要把
_handle函数定义好上面三者的关系即可,指的注意的是,由于策略可以使用各种插件,所以需要在适当的时机给插件触发下面定义好的钩子。Workbox 策略插件
上面提到了策略是描述的是 客户端、Network 和 Cache 三者的关系,而当三者关系相同,但是一些细节不同的时候,我们可以考虑使用插件来丰富这些细节。
比如我需要设置一下缓存的过期时间,那么我可以:
- import {registerRoute} from 'workbox-routing';
- import {CacheFirst} from 'workbox-strategies';
- import {ExpirationPlugin} from 'workbox-expiration';
- registerRoute(
- ({request}) => request.destination === 'image',
- new CacheFirst({ // 主要策略
- cacheName: 'images',
- plugins: [
- new ExpirationPlugin({ // 策略插件
- maxEntries: 60,
- maxAgeSeconds: 30 * 24 * 60 * 60, // 设置一个 30 Days 的过期时间
- }),
- ],
- })
- );
可以自定义自己的策略插件,如下:
强烈推荐看这篇文档的视频介绍:developer.chrome.com/docs/workbo…
- // 这个插件即后面提到的 ServiceWorker 入口文件缓存方案部分实现细节
- class StaleNotificationPlugin implements WorkboxPlugin {
- // ...
- fetchDidSucceed(params: FetchDidSucceedParam) {
- // 在 Network 请求回来的时候,对比缓存版本和新回来的版本
- // 检查版本差异
- this.handleDiffVersion(params);
- return Promise.resolve(params.response.clone());
- }
- async handlerDidError(params: HandlerDidErrorParam) {
- // 当发生异常的时候,给客户端响应 network 请求
- // 保证可用性
- const { state, request, error } = params;
- setTimeout(() => {
- this.cleanUp(state);
- this.onError(error);
- });
- // 直接走网络请求
- return fetch(request);
- }
- }
- // 使用的时候:
- registerRoute(
- ({ url }) => url.pathname.endsWith('/detail'),
- new StaleWhileRevalidate({ // 策略
- cacheName: 'xxx',
- plugins: [
- new StaleNotificationPlugin() // 自定义插件
- ]
- }),
- 'GET',
- );
Workbok 的路由
Workbox 的路由在上面也有接触过,主要是匹配客户端发起的不同请求来走不同的处理逻辑
- import {registerRoute} from 'workbox-routing';
- registerRoute(matchCb, handlerCb);
ServiceWorker 很危险
- Cache 可以缓存任何请求,比如 404、503 等状态的请求,如果没有加以控制便将其缓存,那么用户在 Cache First 等策略中将会一直请求到这种错误状态的请求,直到用户清除缓存
- 在处理用户请求过程中,如果处理代码报错,那么可能会导致客户端一直接收不到请求,导致无限 loading,造成用户体验问题
- 降级问题
- 如果报错,可能会导致无限 pending,用户的请求将会一直挂着直到 timeout
紧急移除 ServiceWorker
如果不小心发布了一个含有严重错误逻辑的 ServiceWorker,可以发布下面代码的 ServiceWorker 来紧急移除
- // sw.js
- self.addEventListener('install', () => {
- // Skip over the "waiting" lifecycle state, to ensure that our
- // new service worker is activated immediately, even if there's
- // another tab open controlled by our older service worker code.
- // 不需要等待旧的 ServiceWorker
- self.skipWaiting();
- });
- self.addEventListener('activate', () => {
- // Optional: Get a list of all the current open windows/tabs under
- // our service worker's control, and force them to reload.
- // This can "unbreak" any open windows/tabs as soon as the new
- // service worker activates, rather than users having to manually reload.
- // 强制所有的客户端进行重定向
- self.clients.matchAll({
- type: 'window'
- }).then(windowClients => {
- windowClients.forEach((windowClient) => {
- windowClient.navigate(windowClient.url);
- });
- });
- });
手动取消注册 ServiceWorker
应用:ServiceWorker 入口文件缓存方案
通常我们的 SPA 的 HTML 入口文件是无缓存的,每一次都会到 CDN 请求最新的入口文件(即使是协商缓存,也至少需要经历一次请求服务器的链路)。在网络情况不佳时,会比较明显地影响页面加载速度,可以通过 ServiceWorker 来缓存入口文件。
具体策略是:
当用户访问入口文件的时候,首先返回本地的缓存,让浏览器开始解析,然后后台发起另一个请求去获取当前最新的入口文件。当新的入口文件返回来的时候,检测二者的版本是否一致(可以通过比较注入到入口文件的版本、文本全量对比等方式来判断)。
如果判断二者版本一致,那么不做处理,这种情况相当于节省了一个网络链路;
如果判断二者版本不一致,那么可以马上通知客户端(此处指的是当前浏览器 tab)进行 reload,而此时由于最新的文件已经拿到了,所以 reload 请求到的也是缓存,整体时间消耗约等于直接请求服务端获取最新入口文件的时间。
通过上述这种策略,可以在大多数场景下减少入口文件请求的时间,达到优化的效果。
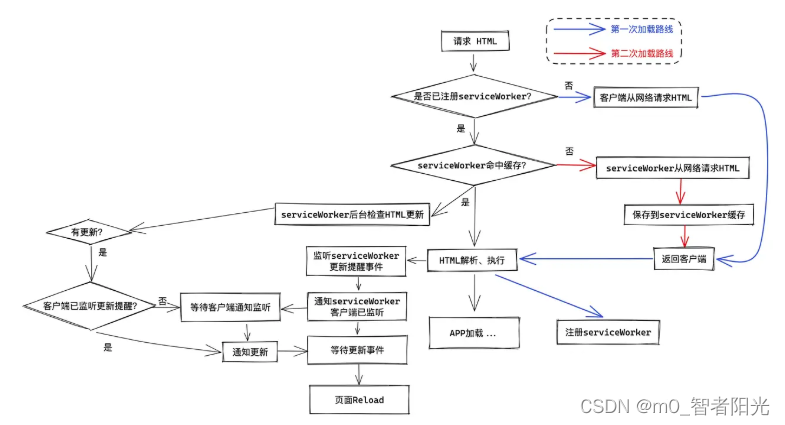
具体做法是在 Workbox 的异步缓存更新策略(stale while revalidate strategy)的基础上,增加一个 HTML 入口文件的 diff 过程,如果检查到 HTML 发生了改变,那么可以通过
postMessage来通知客户端进行重载操作。如果 diff 发生错误便容易造成无限刷新,所以这种情况下可以再加上一个保险机制,在特定时间内不能够多次重载
-
相关阅读:
坚信人类记忆是以大分子物质存储的朋友们请看过来
SpringBoot - Swagger2的集成与使用(二)
【selenium】使用 cookies
Linux | 文件描述符理解 | 系统级别的文件操作讲解 | 一切皆文件的由来 | 重定向dup2函数讲解
vue多张图片实现TV端长图浏览组件
无胁科技-TVD每日漏洞情报-2022-9-9
Java学习复杂的对象数组操作
如何在 Windows 10 中安装 WSL2 的 Linux 子系统
Simfatic Forms 是一个网络表单构建工具
前端面试题总结(一)
- 原文地址:https://blog.csdn.net/m0_73088370/article/details/126335813
