-
【无标题】
第 7 章 DQN 算法


7.3 DQN

函数拟合得到动作价值函数


经验回放
DQN 算法采用了经验回放(experience replay)方法,具体做法为维护一个回放缓冲区,将每次从环境中采样得到的四元组数据(状态、动作、奖励、下一状态)存储到回放缓冲区中,训练 Q 网络的时候再从回放缓冲区中随机采样若干数据来进行训练。
目标网络

第 8 章 DQN 改进算法
介绍其中两个非常著名的算法:Double DQN 和 Dueling DQN,这两个算法的实现非常简单,只需要在 DQN 的基础上稍加修改,它们能在一定程度上改善 DQN 的效果
第 9 章 策略梯度算法
9.1 简介
本书之前介绍的 Q-learning、DQN 及 DQN 改进算法都是基于价值(value-based)的方法,其中 Q-learning 是处理有限状态的算法,而 DQN 可以用来解决连续状态的问题。在强化学习中,除了基于值函数的方法,还有一支非常经典的方法,那就是基于策略(policy-based)的方法。对比两者,基于值函数的方法主要是学习值函数,然后根据值函数导出一个策略,学习过程中并不存在一个显式的策略;而基于策略的方法则是直接显式地学习一个目标策略。策略梯度是基于策略的方法的基础,本章从策略梯度算法说起。
9.2 策略梯度


REINFORCE 算法理论上是能保证局部最优的,它实际上是借助蒙特卡洛方法采样轨迹来估计动作价值,这种做法的一大优点是可以得到无偏的梯度。但是,正是因为使用了蒙特卡洛方法,REINFORCE 算法的梯度估计的方差很大,可能会造成一定程度上的不稳定 Actor-Critic 算法要解决的问题
第 10 章 Actor-Critic 算法
本书之前的章节讲解了基于值函数的方法(DQN)和基于策略的方法(REINFORCE),其中基于值函数的方法只学习一个价值函数,而基于策略的方法只学习一个策略函数。那么,一个很自然的问题是,有没有什么方法既学习价值函数,又学习策略函数呢?答案就是 Actor-Critic。
需要明确的是,Actor-Critic 算法本质上是基于策略的算法,因为这一系列算法的目标都是优化一个带参数的策略,只是会额外学习价值函数,从而帮助策略函数更好地学习。
10.2 Actor-Critic

第 11 章 TRPO 算法


针对以上问题,我们考虑在更新时找到一块信任区域(trust region),在这个区域上更新策略时能够得到某种策略性能的安全性保证,这就是信任区域策略优化(trust region policy optimization,TRPO)算法的主要思想


第 12 章 PPO 算法(跳过)
TRPO 算法在很多场景上的应用都很成功,但是我们也发现它的计算过程非常复杂,每一步更新的运算量非常大。于是,TRPO 算法的改进版——PPO 算法在 2017 年被提出,PPO 基于 TRPO 的思想,但是其算法实现更加简单。
第 13 章 DDPG 算法



第 14 章 SAC 算法 (跳过)
虽然 DDPG 是离线策略算法,但是它的训练非常不稳定,收敛性较差,对超参数比较敏感,也难以适应不同的复杂环境。一个更加稳定的离线策略算法 Soft Actor-Critic(SAC)被提出。SAC 的前身是 Soft Q-learning,它们都属于最大熵强化学习的范畴。

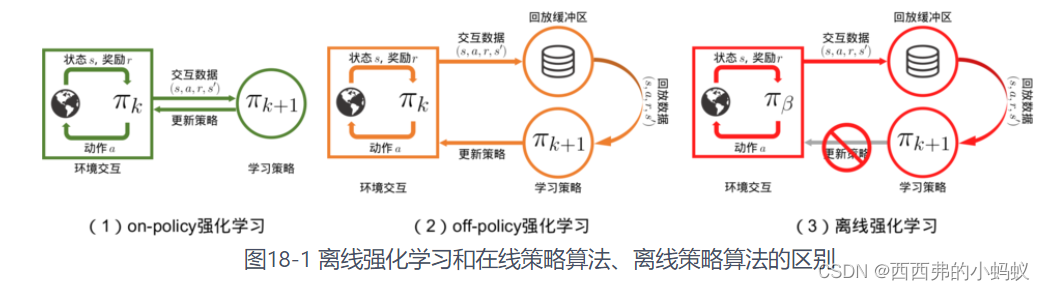
第 18 章 离线强化学习
无论是在线策略(on-policy)算法还是离线策略(off-policy)算法,都有一个共同点:智能体在训练过程中可以不断和环境交互,得到新的反馈数据。二者的区别主要在于在线策略算法会直接使用这些反馈数据,而离线策略算法会先将数据存入经验回放池中,需要时再采样。
离线强化学习(offline reinforcement learning)的目标是,在智能体不和环境交互的情况下,仅从已经收集好的确定的数据集中,通过强化学习算法得到比较好的策略。离线强化学习和在线策略算法、离线策略算法的区别如
第 20 章 多智能体强化学习入门
多智能体的情形相比于单智能体更加复杂,因为每个智能体在和环境交互的同时也在和其他智能体进行直接或者间接的交互。


20.3 多智能体强化学习的基本求解范式
完全中心化(fully centralized)方法:将多个智能体进行决策当作一个超级智能体在进行决策,即把所有智能体的状态聚合在一起当作一个全局的超级状态,把所有智能体的动作连起来作为一个联合动作
完全去中心化(fully decentralized)方法:与完全中心化方法相反的范式便是假设每个智能体都在自身的环境中独立地进行学习,不考虑其他智能体的改变。完全去中心化方法直接对每个智能体用一个单智能体强化学习算法来学习。这样做的缺点是环境是非稳态的,训练的收敛性不能得到保证,但是这种方法的好处在于随着智能体数量的增加有比较好的扩展性,不会遇到维度灾难而导致训练不能进行下去。

第 21 章 多智能体强化学习进阶
本章来介绍一种比较经典且效果不错的进阶范式:中心化训练去中心化执行(centralized training with decentralized execution,CTDE)。所谓中心化训练去中心化执行是指在训练的时候使用一些单个智能体看不到的全局信息而以达到更好的训练效果,而在执行时不使用这些信息,每个智能体完全根据自己的策略直接动作以达到去中心化执行的效果。中心化训练去中心化执行的算法能够在训练时有效地利用全局信息以达到更好且更稳定的训练效果,同时在进行策略模型推断时可以仅利用局部信息,使得算法具有一定的扩展性

-
相关阅读:
2.11 教你一套怎么建立自己的选题素材库的方法【玩赚小红书】
C语言-流程控制
第1关:会话创建与关闭
【ROS】节点&话题
【计算机基础】数据结构一览
看云笔记 | 适合大学生的云笔记软件
Sklearn基本算法
[青少年CTF训练平台]web部分题解(已完结!)
Android笔记--WebSocket
头歌:第1关:有序单链表的插入操作
- 原文地址:https://blog.csdn.net/zj_18706809267/article/details/126335929