-
【torchserve使用最终篇】修改handler文件来实现自己的推理流程|部署onnx模型|部署tensorrt模型
目录
前言
在之前我们提到如何去配置torchserve,这使得我们对其有了初步的了解和认识:【torchserve安装和使用】torchserve部署方法|常见问题汇总|mmdetection使用torchserve部署|不使用docker_活成自己的样子啊的博客-CSDN博客_torchserve部署
 https://blog.csdn.net/m0_61139217/article/details/125014279?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_61139217/article/details/125014279?spm=1001.2014.3001.5501本篇旨在研究handler文件的写法,来自定义属于自己的模型推理流程。
QQ:1757093754 欢迎交流、学习!
先给出官网,万物官网可解决~~~:(官网还有)1. TorchServe — PyTorch/Serve master documentation
https://pytorch.org/serve/注:本篇博文旨在研究handler文件的编写方式,故所有代码均以图片的形式给出, 自己动手实现一遍更有意义!!!
handler文件的构造说明
要想自定义handler文件的推理代码,首先需要了解handler文件他的构造原理,以及类方法的调用过程,方便之后我们部署tensorrt模型、onnx模型。
类别继承关系
所有的handler类均继承自basehandler类,它提供了最原始的initialize(模型的初始化)、_load_torchscript_model(模型加载)、_load_pickled_model(模型加载)、preprocess(前处理)、inference(推理)、postprocess(后处理)主要方法。(我们只需重写这几个方法即可。其他方法均是内置推理过程,无需修改!)
注:torchserve在默认情况下只支持部署pytorch和torchscript这两种模型文件。
basehandler类initialize方法:(截取了加载模型的代码部分)

(load_pickled_model 是加载pytorch模型;load_torchscript_model 是加载torchscript模型)
我们自定义的handler类可以直接继承其继承好的类,例如继承自basehandler的testhandler、visionhandler类。这里我们直接继承basehandler类即可。
initialize方法模块:模型的初始化
initialize方法主要负责模型的初始化,在basehandler里面其具有以下功能:
1.设置运行环境(GPU or CPU)

2.加载模型权重

注:
1.这里加载模型权重的方法是根据 model_file 这一变量区分的。其为包含模型类的model.py,且这个文件里面有且仅有一个类来表示模型类。(因为torchscript的权重不仅保存了模型训练出来的参数,也保存了模型的原始信息,故torchscript权重在加载的时候无需指定该模型类了)
2.默认的初始化方法只会加载pytorch、torchscript权重。
3.加载类别对应名称的json

其他类在继承basehandler类的时候会调用父类的 initialize 方法:
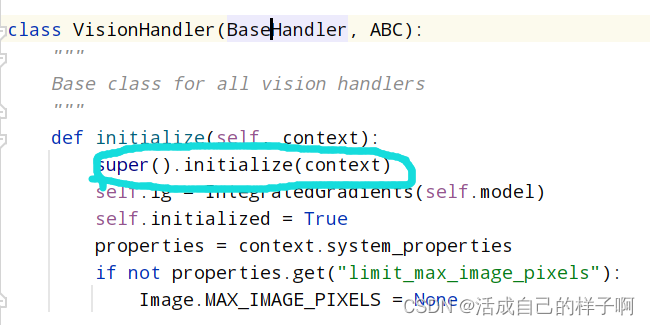
这里以visionhandler为例。
load_model:模型加载模块
上文提到,初始化方法只会加载pytorch、torchscript权重:
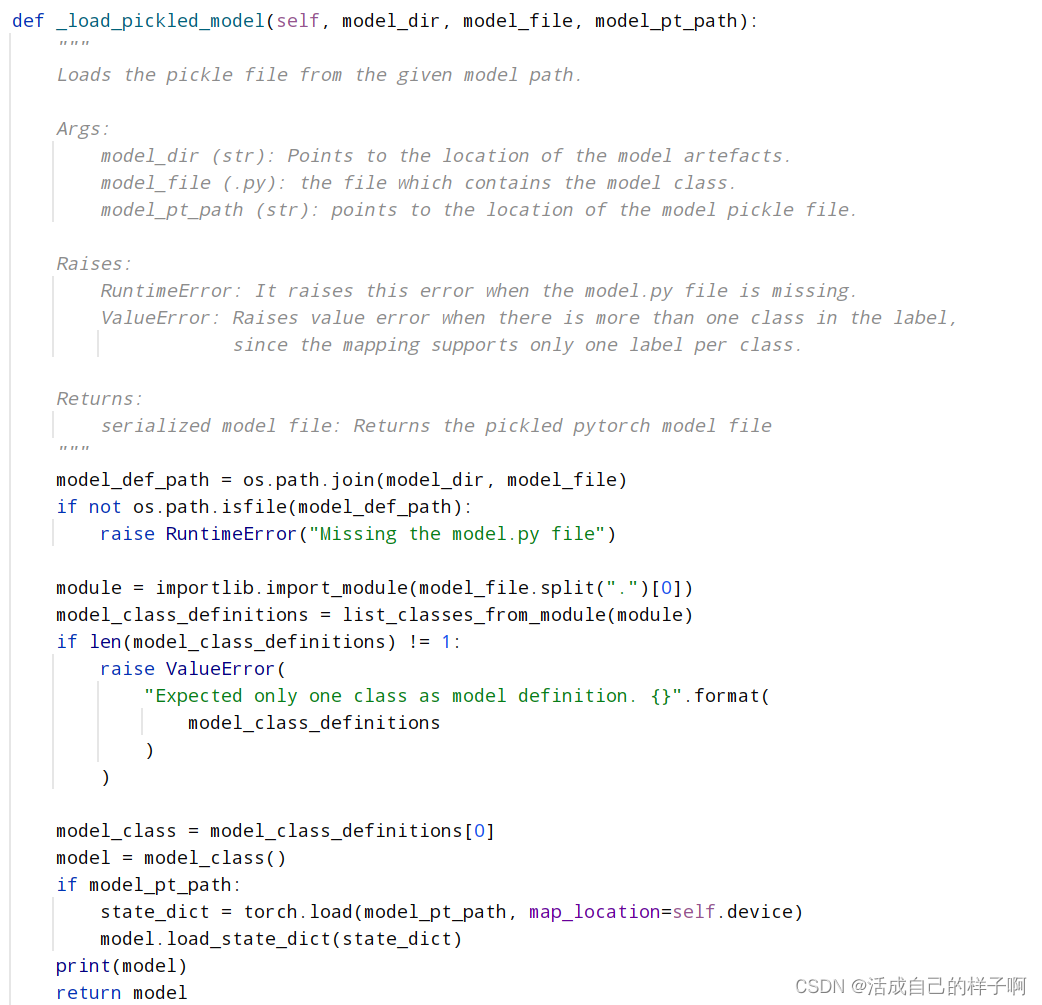
 我们可以通过以下方法来在自定义的类里面加载模型:
我们可以通过以下方法来在自定义的类里面加载模型:- 重写 _load_torchscript_model、_load_pickled_model 方法来加载模型权重。
- 自定义一个权重加载方法来专门加载模型权重,并且重写initialize方法来调用自定义方法。
preprocess:前处理过程
该模块方法主要功能是处理post请求发来的数据(也可以是其他请求,这里以post请求为例):
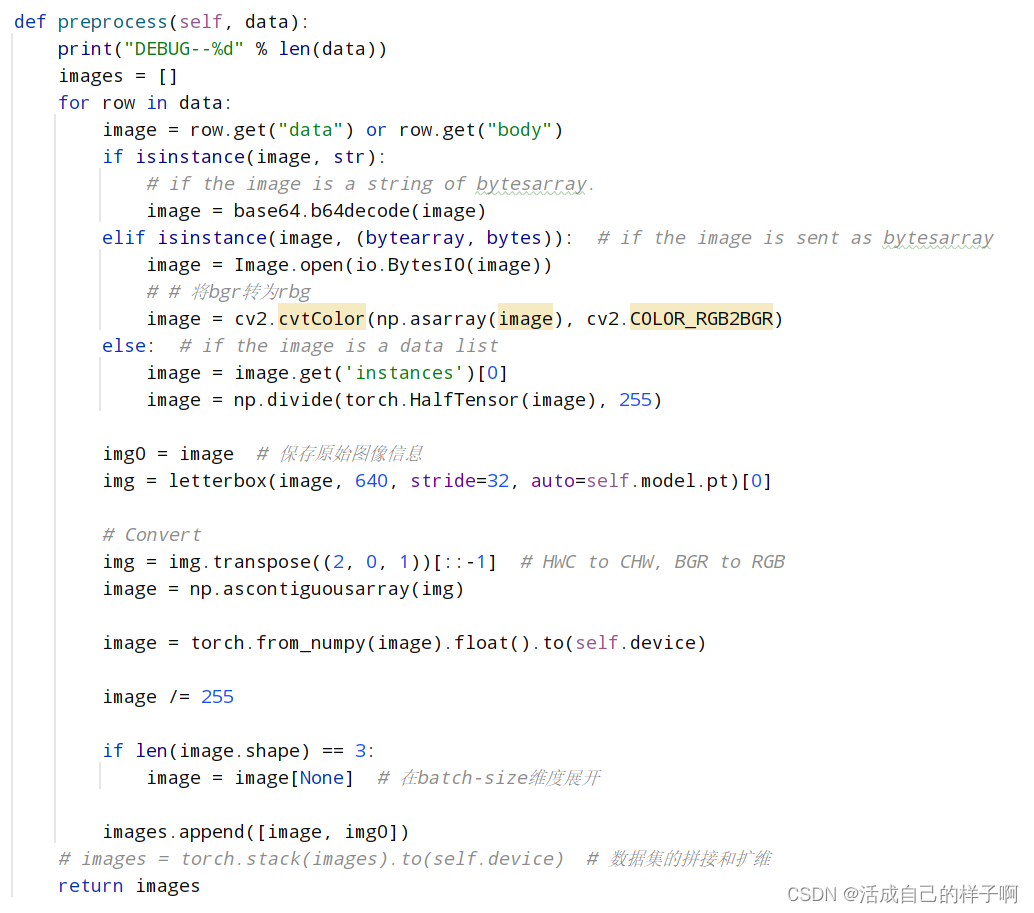
注:该方法有一个返回值【images】,该参数会成为inference方法的参数。
inference:推理过程
该方法主要负责模型的前向传播,即将preprocess函数返回的images传入模型进行预测。也可以自己编写代码实现其方法。
这里插上我的代码:
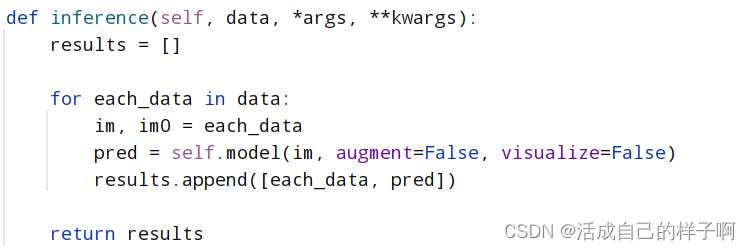
注:
1.我的images是一个二维列表,每一个元素是 数据增强后的图像(im) + 原始图像(im0)。(例如目标检测类问题,在模型输出预测框的时候需要对预测框进行等比例缩放)
2.该方法有一个返回值【results】, 该参数会成为postprocess方法的参数。
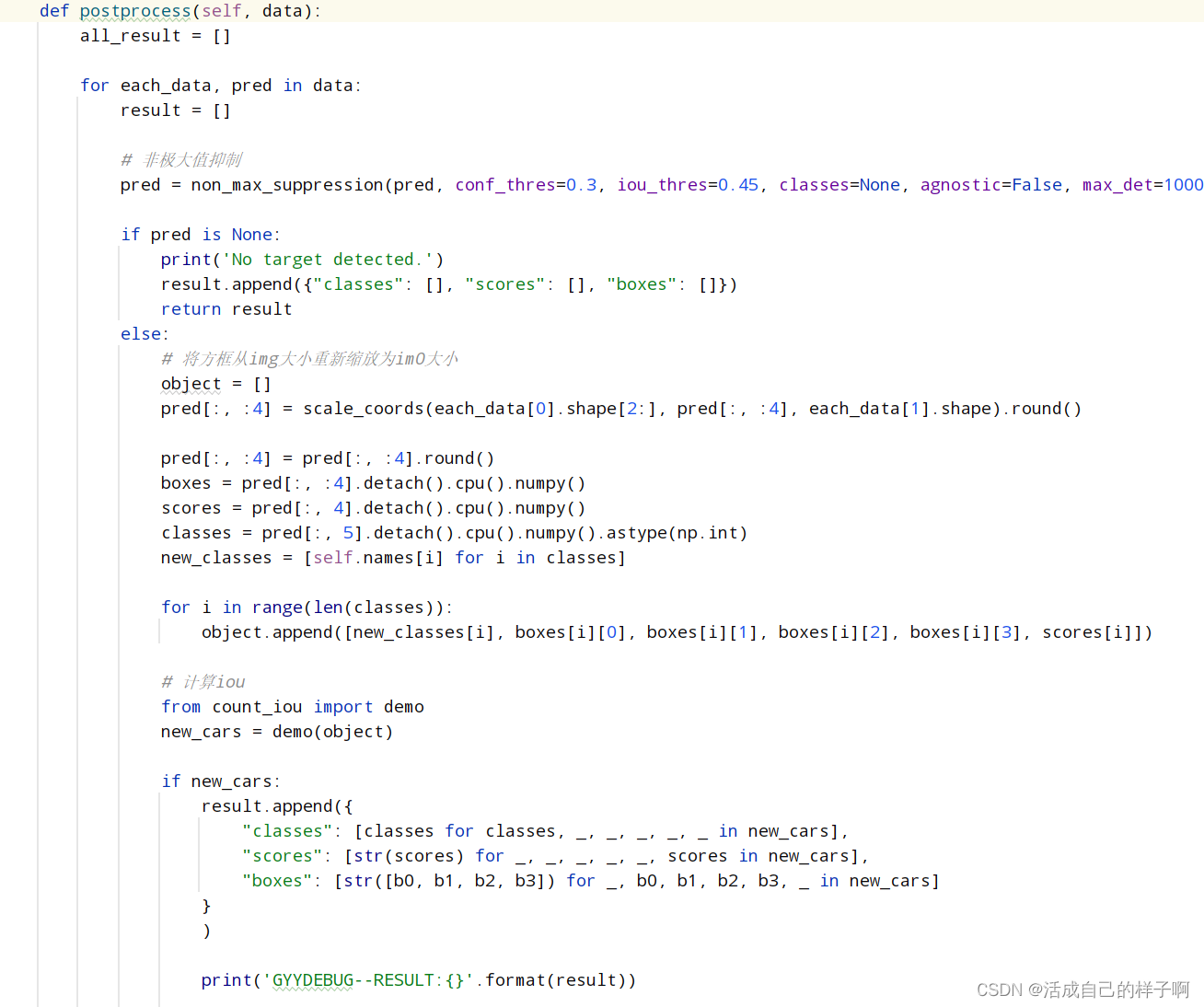
postprocess:后处理过程
该部分代码负责对模型输出结果的一些其他处理,例如计算非极大值抑制等等。最终得到的结果以json格式的字典(在一个列表里面)返回。

需要注意的几点:
- 1.返回值是一个列表,里面有键值对。
- 2.键、值均为字符串才行。
- 3.返回字典的键值对里面不能有汉字。

依赖文件打包方法
在编写handler文件的时候,难免会有一些其他依赖脚本需要一并使用。在启动torchserve服务之前,我们需要对这些文件进行打包(打包成mar文件包的形式)。
步骤:
1.将所有文件放到一个文件夹里面。
例如:我把通过yolov5的训练出来的两个模型(一个torchscript,一个tensorrt)分别编写对应的handler,并分别打包所有的依赖文件。
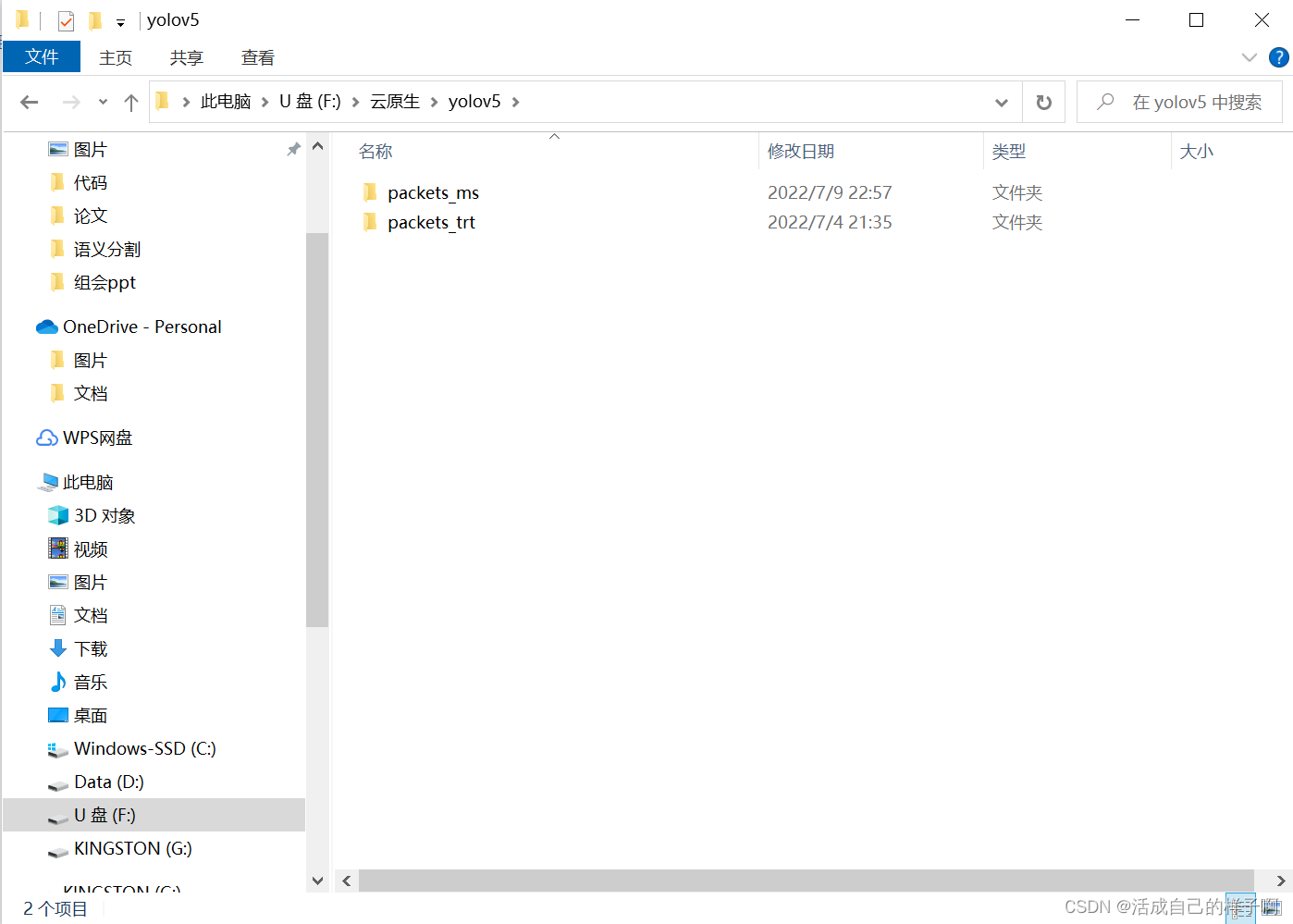
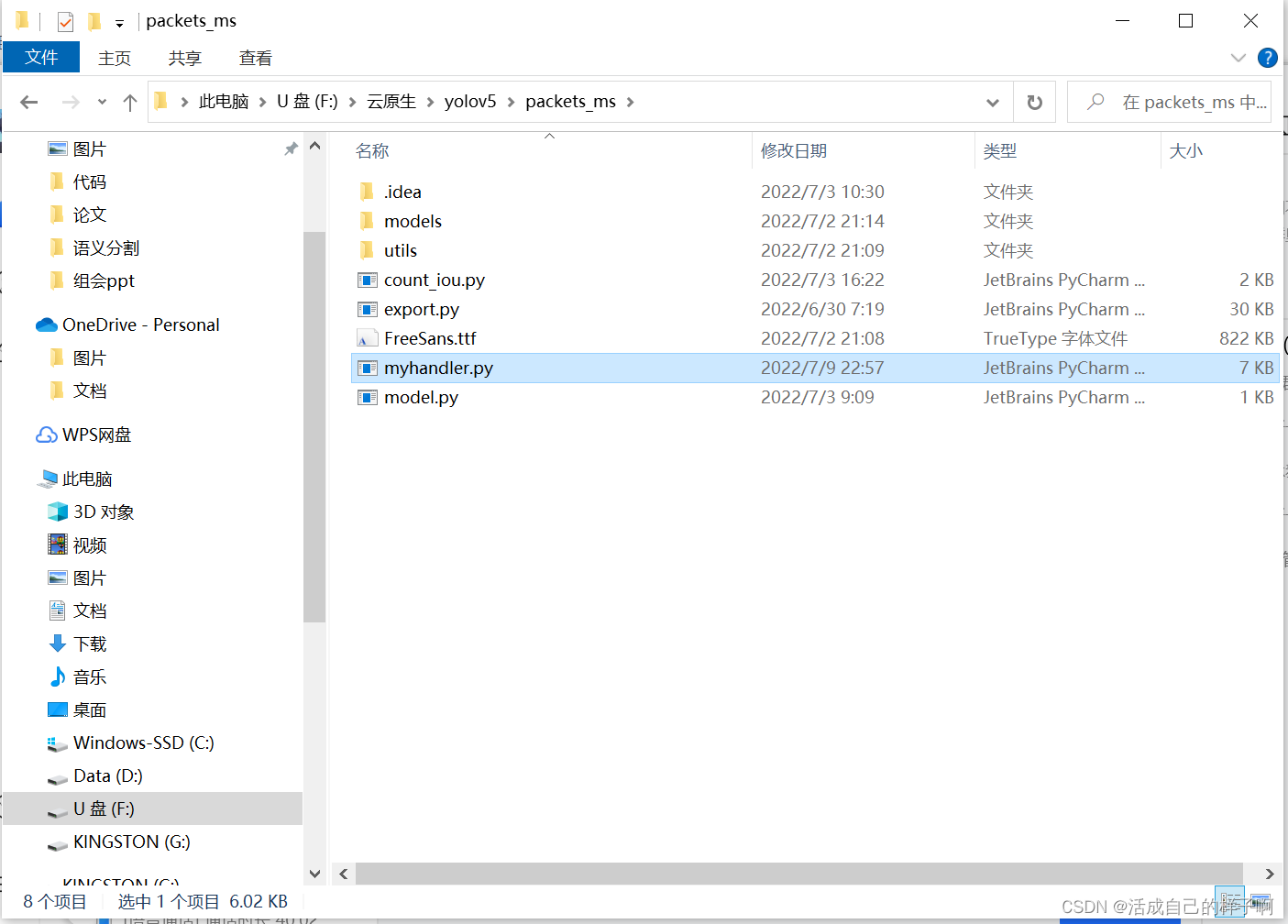
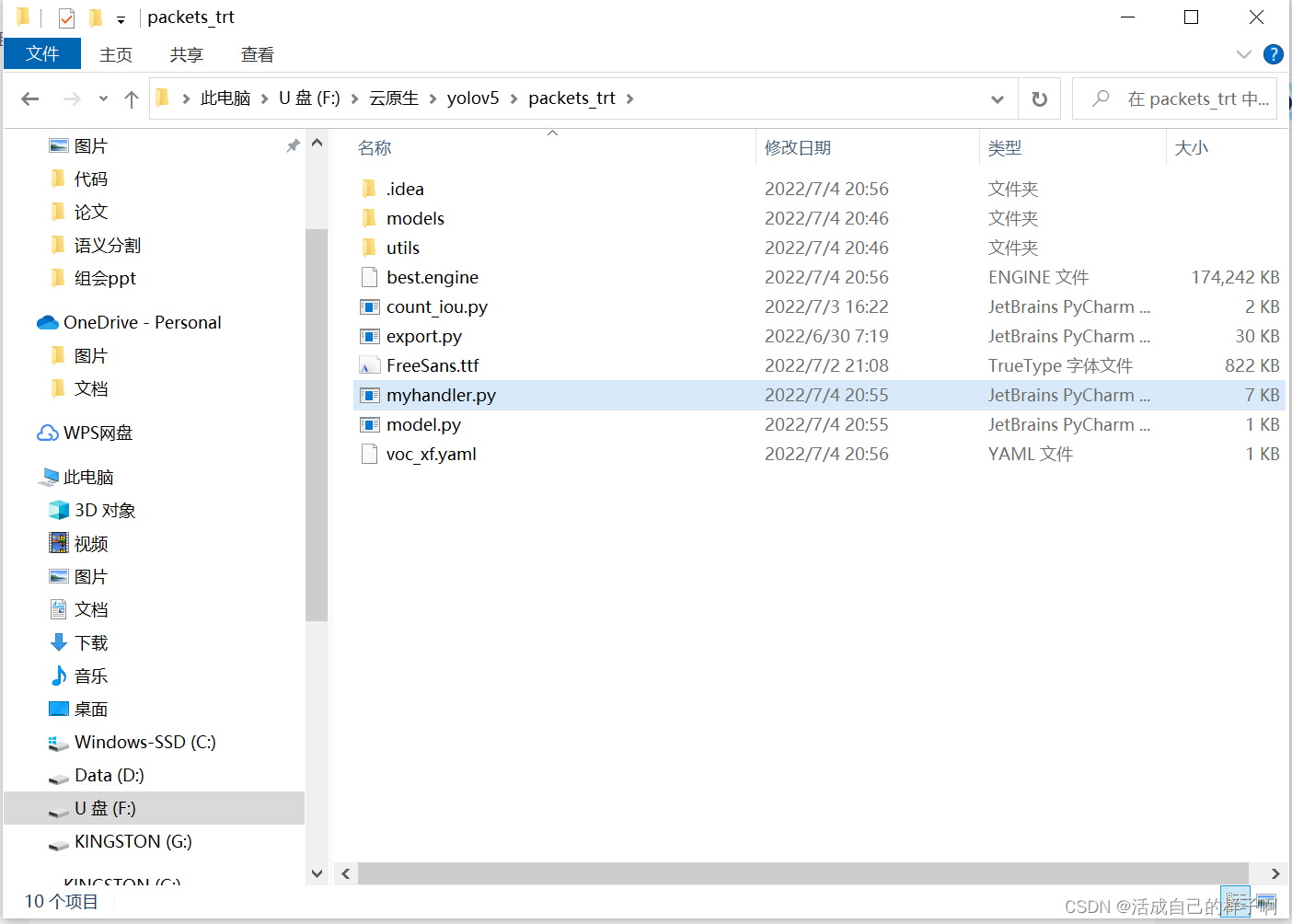
注:handler在命名的时候建议不要使用 handler.py 这个名字。我这里使用的是 myhandler.py (我记得有个报错和这个有关,,但是我记不太清了,,也可能不要紧,,为了以防万一还是自定义一个名字吧)
2.使用torch-model-archiver进行打包指定所有依赖所在的文件夹。
torch-model-archiver --model-name xxx --version 1.0 --model-file packets_ms/model.py --serialized-file xxx.pth --handler packets_ms/myhandler.py --extra-files packets_ms,index_to_name.json
其他问题
- 如果出现自己的模型一直没有被注册,或者注册出现重命名,或者是注册没成功,但是自己的操作并没有问题,请先把torchserve生成的logs日志文件夹删掉(里面保存了模型的注册信息),并重新注册模型到torchserve里面。
- 在部署tensorrt模型到torchserve的时候,要注意engine模型支持的tensorrt版本要和部署的服务器保持一致(建议直接在要部署的服务器进行tensorrt转换,防止出现tensorrt版本不兼容的问题)
欢迎一起交流、学习,如有博客问题,也欢迎大神指正!!!
QQ:1757093754
-
相关阅读:
Leetcode 第1342题:将数字变成 0 的操作次数 (位运算解题法详解)
交换机的工作原理
ftp文件传输协议
32 Feign性能优化
gpt扣款失败,openai扣款失败无法使用-如何解决gpt扣款失败的问题?
FITC荧光标记果聚糖Fructan/阿拉伯聚糖Fructan/脂多糖LPS定制合成
养猫后家里有异味?哪款宠物空气净化器可以去除猫皮屑过敏源?
Python实现求解上个工作日逻辑
计算机毕业设计Java大数据在线考试系统在线阅卷系统及大数据统计分析(源码+系统+mysql数据库+lw文档)
VS2019自动闪退问题
- 原文地址:https://blog.csdn.net/m0_61139217/article/details/126328027