-
完整大数据集群配置(从配置虚拟机到实操)
一、虚拟机配置
网络配置
记录一下三个信息,用作配置IPADDR(ip地址)、NETMASK(子网掩码)、GATEWAY(网关)
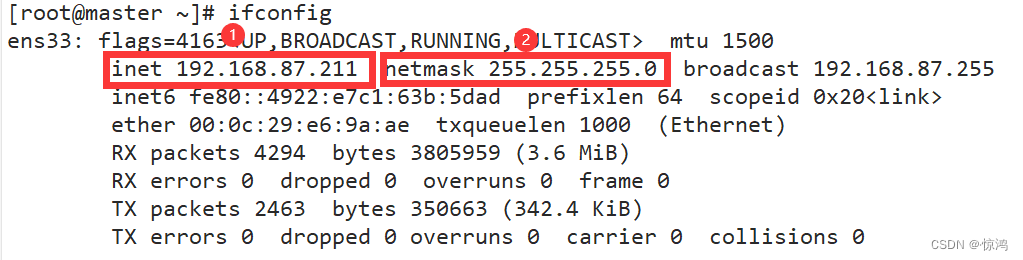
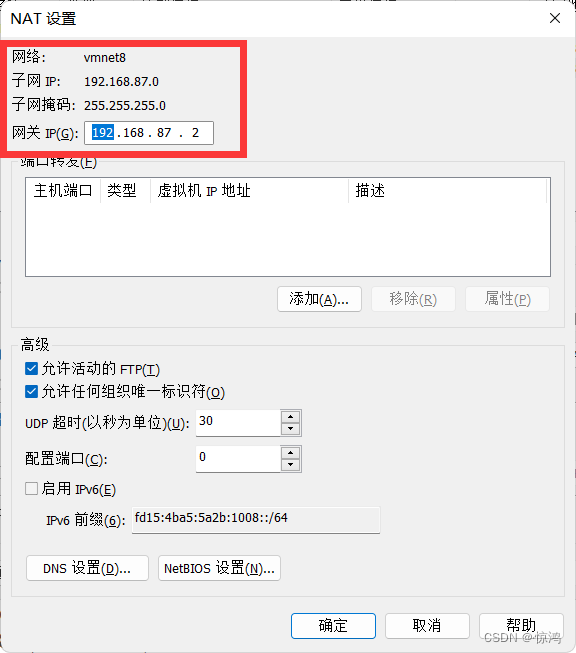
上面是ip和掩码,在网络编辑器里面的net模式查看自己的网关:
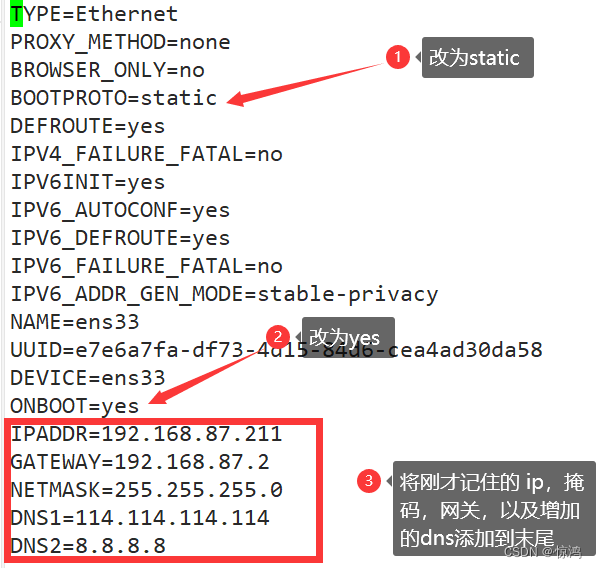
输入vi /etc/sysconfig/network-scripts/ifcfg-ens33- 1
做如下修改
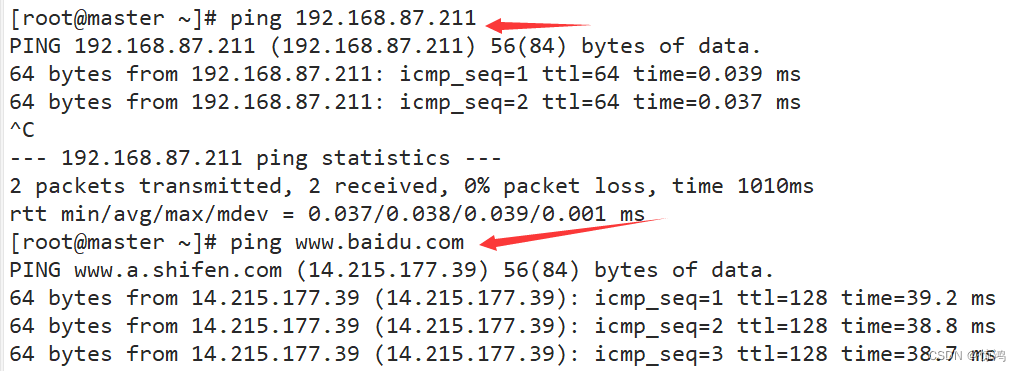
修改完成以后,重启网卡service network restart- 1
此时,无论是ping本地,还是ping百度,都可以连上网
设置中文输入法
在设置里面的
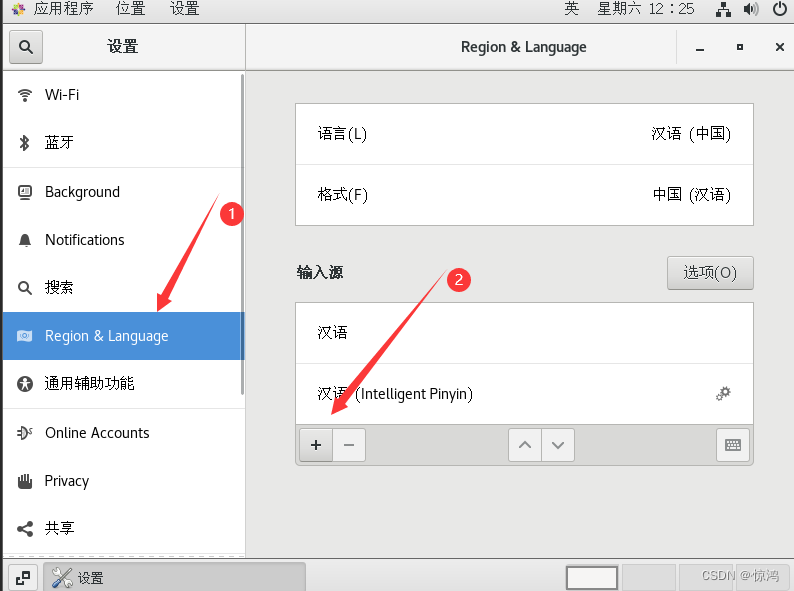
找到汉语(中国),并添加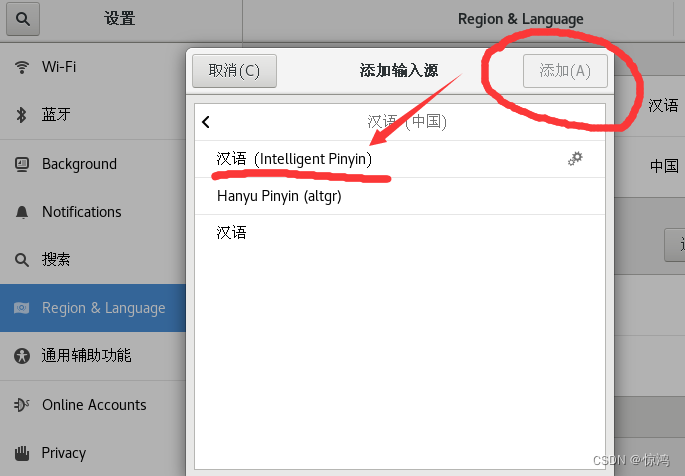
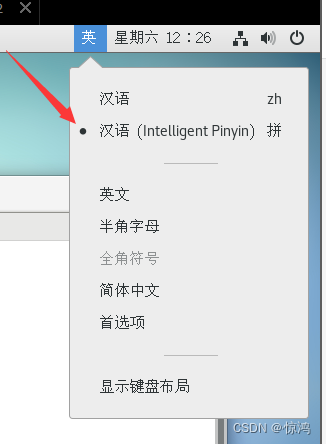
在桌面右上角切换
关闭防火墙和selinux
关闭防火墙
systemctl stop firewalld- 1
关闭开机自启动
systemctl disable firewalld.service- 1
关闭selinux
1、临时关闭
先查看状态:getenforce- 1
出现
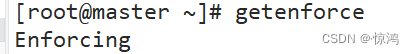
关闭setenforce 0- 1
此时在查看

永久关闭
修改此文件vi /etc/sysconfig/selinux- 1
如图

这里需要重启一下,在查看一下状态克隆
事先说明,需要修改的几个东西
1.修改mac地址
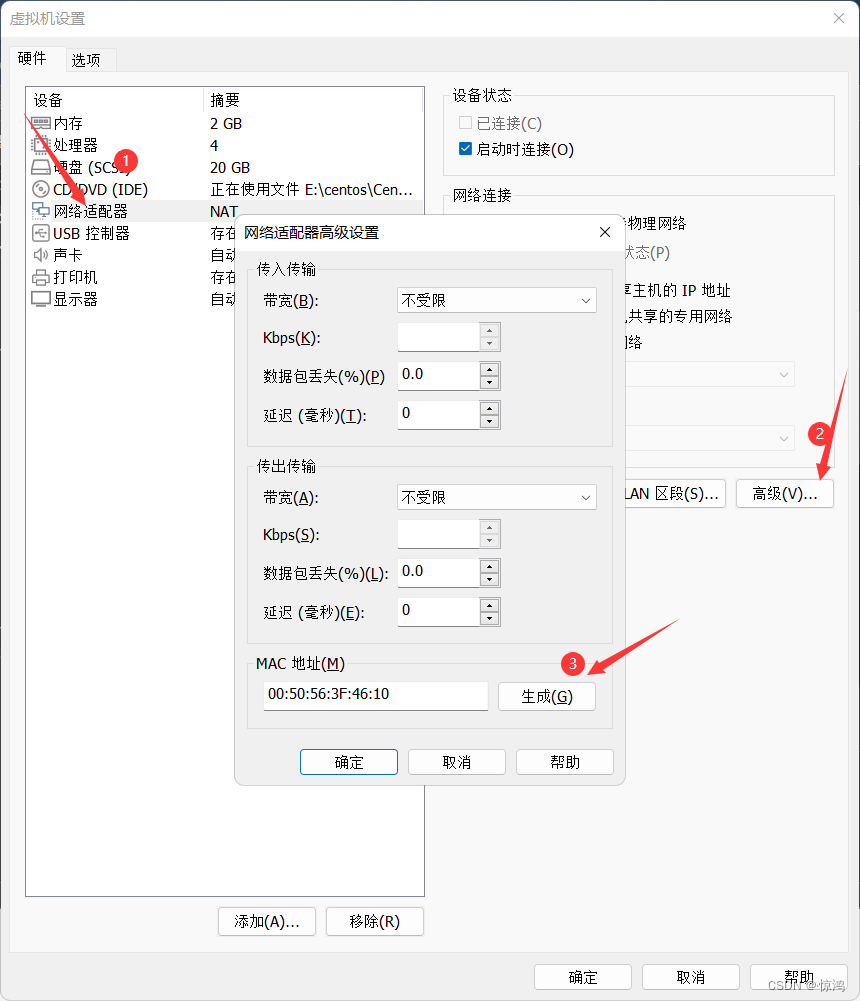
2.更改UUID地址和IP地址
使用命令生成新的UUIDuuidgen- 1

再在网卡配置文件里面替换原来的UUIDvi /etc/sysconfig/network-scripts/ifcfg-ens33- 1
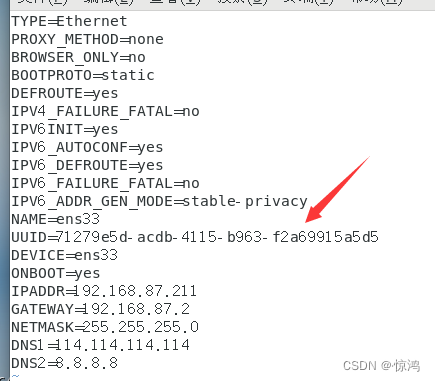
还要修改ip地址,这里我第一台是192.168.87.211,为了记忆,IP地址就顺次下移吧,也就是212和213
其他地方不变,修改之后,wq! 保存退出
3.修改主机名称
查看当前主机名hostname- 1
修改主机名
hostnamectl set-hostname 主机名- 1
4.修改hosts文件
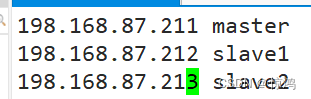
也就是把你几台的ip地址加主机名加入进来192.168.87.211 master 192.168.87.212 slave1 192.168.87.213 slave2- 1
- 2
- 3
免密登录
查看是否安装SSH命令,其实看不看无所谓,我直接下也行,大不了更新一下(网络不至于这么慢吧?)
ps -e|grep sshd- 1
下载服务
yum install openssh-server- 1
首先,在三台机器上都各自产生一下自己的公钥,产生的公钥和密钥在 /root/.ssh/id_rsa
ssh-keygen -t rsa- 1
下图所示操作
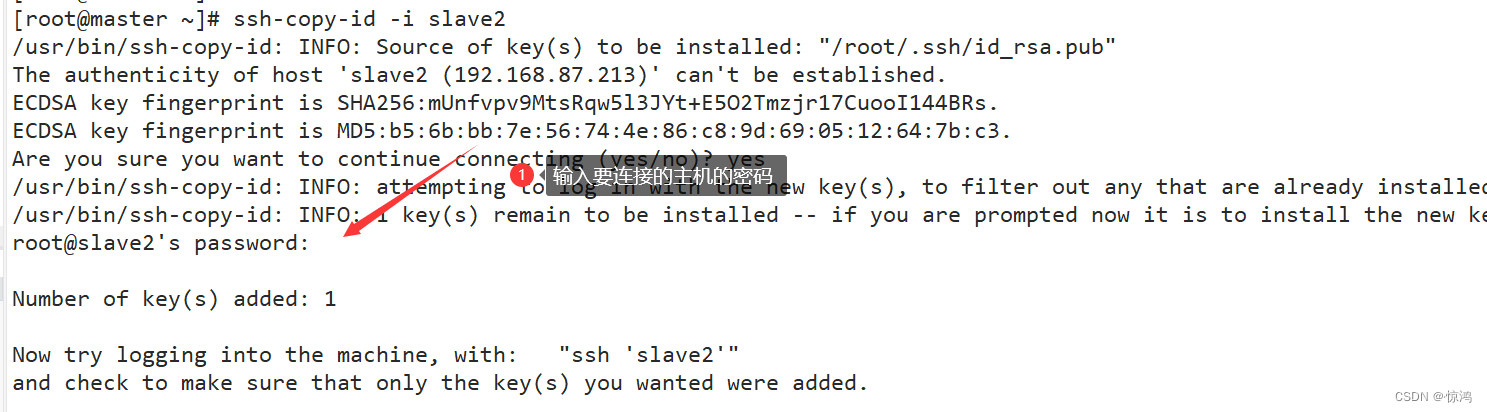
使用命令拷贝,自己也要copy自己一次,三台各一次,那就是九次ssh-copy-id -i 主机名 or ip地址- 1
输入命令,登录要连接的主机,这时候不需要密码就可以直接登陆上!ssh 主机名 or ip地址- 1
二、配置hadoop完全分布式环境
事先声明目录和文件修改位置
- 这里我就自定义目录了,分开放,你们随意,但是要记住后面要配置!
- 可以先配置一台,剩下两台我们把第一台配置好了直接copy过去!
- 文件修改位置除了javahome,其他都是在文件的
cofiguration标签中
放置软件压缩包
mkdir /opt/software- 1
放置大数据相关文件
mkdir /usr/app- 1
安装jdk和hadoop
首先解压jdk安装包命令
tar -zxvf /opt/software/解压文件名 -C /usr/app/(解压到位置)- 1
tar命令详解
那这时候虽然解压过去了,但是这个文件名也太长了是吧?so,使用mv命令修改文件名字
修改为了jdk1.8 和 hadoop2.7,当然后面的版本号我们可能不一样,都随你们比如我把 hadoop的名字修改成了这样 mv /usr/app/hadoop-2.7.7/ /usr/app/hadoop2.7- 1
- 2
添加环境变量
vi /etc/profile# JAVAHOME是你自己jdk的解压目录 export JAVA_HOME=/usr/app/jdk1.8 export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export PATH=$PATH:$JAVA_HOME/bin #HADOOP_HOME export HADOOP_HOME=/usr/app/hadoop2.7 export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
wq! 保存退出,在刷新一下环境变量,使其生效
source /etc/profile- 1
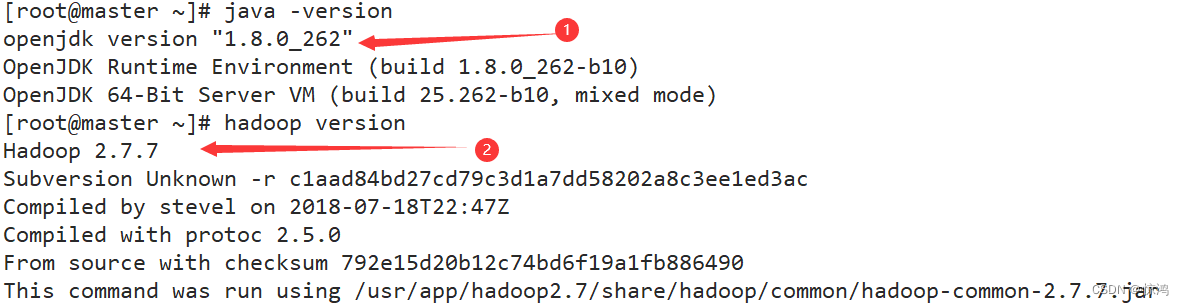
这时候可以查看一下各自的版本,检查一下
java -version # 有横杠 与 hadoop version # 没有横杠- 1
- 2
- 3
出现这个就是ok!
配置hadoop文件
配置文件路径,都在解压包下面的etc/hadoop下
/usr/app/hadoop2.7.3/etc/hadoop/- 1
如图

hadoop-env.sh 与 yarn-env.sh
配置Yarn运行所需的环境变量 指定
JAVA_HOME路径
配置Hadoop运行所需要的环境变量 指定JAVA_HOME路径- 开启行号 输入 set number
- 关闭就是 set nonumber

在她两里找到javahome,把自己的jdk路径加在后面,两个都要加啊!
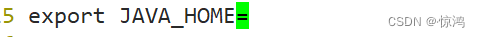
core-site.xml
Hadoop核心全局配置文件,可在其他配置文件中引出
在cofiguration标签中,加入<!-- 配置hadoop文件系统--> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <!-- 配置hadoop临时目录--> <property> <name>hadoop.tmp.dir</name> <value>/usr/app/hadoop2.7/tmp</value> </property>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这里的tmp没有的话,需要自己创建一下
hdfs-site.xml
HDFS配置文件,继承core-site.xml配置文件
在cofiguration标签中写入<!-- 配置文件副本数--> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- 配置SecondaryNameNode服务器的主机ip和端口--> <property> <name>dfs.namenode.secondary.http-address</name> <value>slave1:50090</value> </property>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
mapred-site.xml
MapReduce配置文件,继承core-site.xml配置文件
- 首先 cp mapred-site.xml.template mapred-site.xml,复制一个文件出来,编辑这个文件
<!-- 配置mapreduce计算框架--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>- 1
- 2
- 3
- 4
- 5
- 6
yarn-site.xml
Yarn配置文件,继承core-site.xml配置文件
在cofiguration标签中<!-- 指定Reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>slave1</value> </property> <!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true --> <!--(注意最后两个是横杠不是点)--> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认 是 true --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
slaves 配置集群主机名单
vi /usr/app/hadoop2.7/etc/hadoop/slaves 将localhost删除 加上我们三台的ip地址和主机名 如- 1
- 2
- 3
- 4
远程拷贝
我们配置完了一台机子过后,其他两台也是要配置的,但是在一台一台的去配置难免麻烦,我们就拷贝过去!
将- jdk
- hadoop
- 环境变量
都拷贝过去!
# 将 jdk 和 hadoop 一起拷贝过去 scp -r /usr/app/ slave1:/usr/ 别忘了还有第三台,slave1 是主机名,后面跟地址,第三台也就是 scp -r /usr/app/ slave2:/usr/ 环境变量,也是两台 scp -r /etc/profile slave1:/etc/ scp -r /etc/profile slave2:/etc/- 1
- 2
- 3
- 4
- 5
- 6
- 7
** jdk和hadoop拷贝过来不用修改,
但是环境变量修改了是要刷新的!**
刷新环境变量source /etc/profile- 1
启动和关闭集群
- 启动之前先在主节点上(master),格式化一下 集群
hadoop namenode -format- 1
下面的启动都在这个目录下
/usr/app/hadoop2.7/sbin- 1
这个目录下都是
可执行脚本,.sh是linux系统下的,.cmd是Windows系统下的

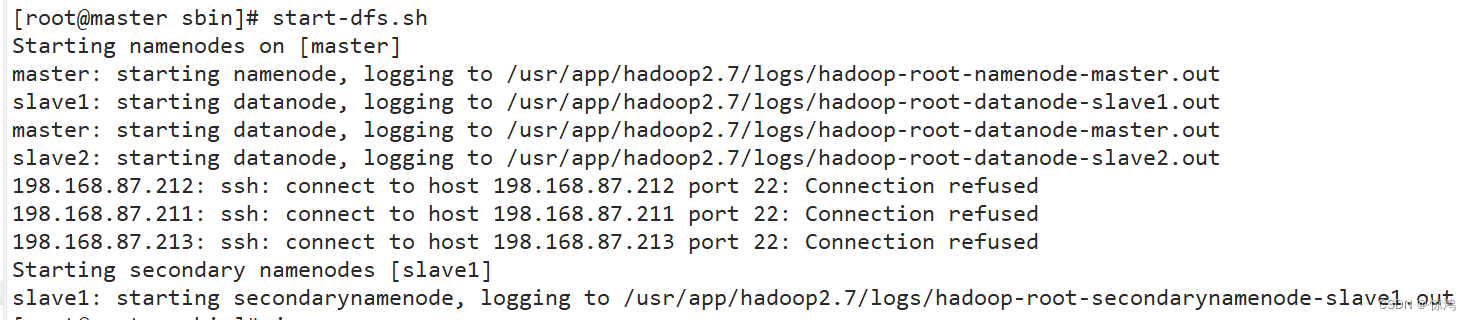
- 在主节点上启动,输入
start-dfs.sh
关闭就是将start 改为 stop,也在这个位置 - 在slave1上启动,输入
start-yarn.sh
关闭就是将start 改为 stop,也在这个位置
如图
master
slave1

jps查看进程
master
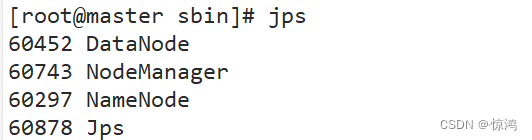
slave1
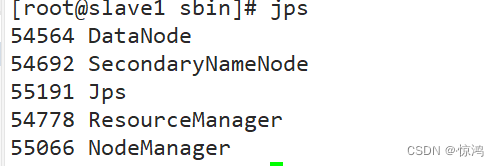
slave2
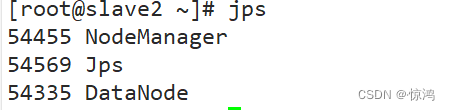
访问web页面端口
用我们主节点的ip加上50070端口,即可访问
如图192.168.87.211:50070- 1

要查看文件系统的目录和文件,在这个标签

当然现在肯定啥都没,我们可以在我们的hdfs文件系统上创建一个文件夹,这里我比较忙就不介绍命令,基础差的可以去网上学习
我在slave2上创建了一个文件夹,三台机器共享此hdfs空间,so,任意一台都可以进行操作# 命令 hadoop fs -mkdir /test1- 1
- 2
如图

最后当然还要关闭啦,不然集群有时候会出问题的
还是在sbin目录下,相同两台上,执行stop-dfs.sh 和 stop-yarn.sh- 1
- 2
- 3
Hadoop完全分布式部署到此结束!
三、ZooKeeper集群式 部署
步骤
解压安装包
tar -zxvf zookeeper-3.4.5.tar.gz -C /usr/app/- 1
改名,这里都随你们改,只是方便看
mv /usr/app/zookeeper-3.4.5/ /usr/app/zookeeper3.4- 1
配置环境变量
vi /etc/profile #zookeeper export ZK_HOME=/usr/app/zookeeper3.4 export PATH=$PATH:$ZK_HOME/bin # 使其环境变量生效 source /etc/profile- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在此目录下
/usr/app/zookeeper3.4/conf- 1
将此文件,复制并重命名为
zoo_sample.cfg >> zoo.cfg- 1
在这个文件里面添加
- dataDir这个在文件的前几行有,你要么就修改前几行的,要么把它删了,我是为了和下面配置的写在一起,都是可以的
#修改数据存储路径配置 dataDir=/usr/app/zookeeper3.4/zkData #增加如下配置 server.1=master:2888:3888 server.2=slave1:2888:3888 server.3=slave2:2888:3888- 1
- 2
- 3
- 4
- 5
- 6
- 7
注
2888为组成zookeeper服务器之间的通信端口,3888为用来选举leader的端口- 1
在我们解压的目录下,创建zkData目录
mkdir zkData # 为了怕没有权限,给一个777,这里貌似不给也行 chmod 777 zkData/- 1
- 2
- 3
再在zkData目录下创建
myid文件,并在其中添加与server对应的编号
(注意:上下不要有空行,左右不要有空格)touch myid #这里不给权限也行,777 的权限尽量别给,我是为了测试 chmod 777 zkData/myid- 1
- 2
- 3
第一台就把myid文件的值改为1
第n台就写n
以此类推
我们可以直接scp 过去,但是别忘了修改各自myid对应的值哦!
注意:添加 myid 文件,一定要在 Linux 里面创建,在 notepad++里面很可能乱码scp -r /usr/app/zookeeper3.4/ slave1:/usr/app/- 1
启动集群
在我们的bin目录下执行
/usr/app/zookeeper3.4/bin/zkServer.sh start- 1
记住,你有多少台,都要在不同机器自己相应的目录下启动,这个不像Haoop一样!so,我这里就在要三台上各自启动一次!
都启动完成过后,使用命令查看状态
/usr/app/zookeeper3.4/bin/zkServer.sh status- 1
如图
master

slave1

slave2

这里的follower和leader就是Zookeeper的选举机制
文章: 【分布式】Zookeeper的Leader选举集群同步脚本
兄弟们,是不是觉得scp虽然很好,但是如果我有不止三台呢?就算只有10台也难得一个一个scp吧?
so,解决问题的方法就来了,那就是xsync filename- 1
我也是才看见的,后续在补充
-
相关阅读:
超实用的JS常用算法详解(推荐)
SciencePub学术 | Elsevier出版社SCIE&EI征稿中
Shell脚本编程实战
Java运行时jar时终端输出的中文日志是乱码
简易基本MyBatis语句书写模板-续更中
支持笔记本电脑直插直充,TOWE 65W智能快充PDU超级插座
RabbitMQ如何保证消息的顺序性【重点】
layui 树状控件tree优化
【Leetcode刷题Python】生词本单词整理
【zeriotier】win10安装zeriotier的辛酸泪
- 原文地址:https://blog.csdn.net/qq_40608132/article/details/126317565
