-
java虚拟机字符串常量池
String的基本特征
创建字符串的方式:
- new String(“”); 在堆中
- =“”; 直接写 ,在常量池中
String 是final的,jdk1.8的时候,底层是一个char[ ] , jdk1.9的时候用的是 byte[ ],原因是堆空间中有大量的字符串,实际使用时发现大部分字符串都是拉丁文,1个字节就可以存放,而char 需要2个字节,所以为了节约空间,和减少GC的次数,就把char[ ] 改成了 byte[ ] ,在我们创建字符串的时候,会尝试压缩字符串,
- 能压缩,就使用1个字节去存储,把标识值coder设为0
- 如果不能压缩,就采用2个字节去存储,把标识值coder设为1
也不光是String做了修改,StringBuilder,StringBuffer都做了相应的修改
String是不可变的:任何对原有的字符串进行的修改操作,其实都是创建了新的字符串
字符串常量池不会存储相同内容的字符串
- String 的 String Pool (字符串常量池) 本质上是一个固定大小的 hashtable,默认大小长度是1009,且不会扩容,如果放进String Pool 的String 非常多,就会造成哈希冲突,导致链表会很长,访问效率就会很低
- jdk6中StringTable是固定的,就是1009的长度,jdk1.7中默认长度是60013
- 可以通过-XX:StringTableSize来设置StringTable的长度,1.6、1.7时设置的大小没有限制,1.8时1009是能被设置的最小值
String的内存分配
因为8种基本数据类型和String都非常常用,为了提高使用效率,都有常量池的概念,类似于一个java系统级别的缓存,8种基本数据类型的常量池是系统来协调的,String类型的比较特殊,有两种主要的使用方法:
- 直接用""声明的对象都会存储在常量池中
- 不是直接使用双引号声明的String对象,可以使用String提供的intern()方法
1.6时,字符串常量池在永久代,1.7就到了堆中,1.8去除了永久代,但是字符串常量池依然保留在了堆中,
调整字符串常量池的原因:
-
所有的字符串都放在了堆中,如果空间不足,可以直接调整堆的大小就好,而永久代的空间较小,不方便优化
-
永久代的垃圾回收频率很低
字符串的拼接操作
- 常量与常量的拼接结果在常量池,原理是编译期优化(在编译期就优化掉了,例如 “a”+“b”,编译后的结果就是"ab",是不需要去运算的)
- 常量池不会存在相同内容的常量
- 只要其中有一个是变量,结果就在堆中(常量池也在堆中,这里是和new 对象一样,在常量池以外),拼接的原理是StringBuilder
- 两个字符串拼接,只要有一个是变量,就会先new 一个StringBuilder ,然后依次调用 append() ,最后调用tiString()
- 在 5.0之后是 StringBuilder ,5.0之前是 StringBuffer
- 如果拼接的结果调用intern() 方法,判断常量池中有没有该字符串,存在就返回常量池中的地址,不存在就把对象放入池中,并返回对象的地址
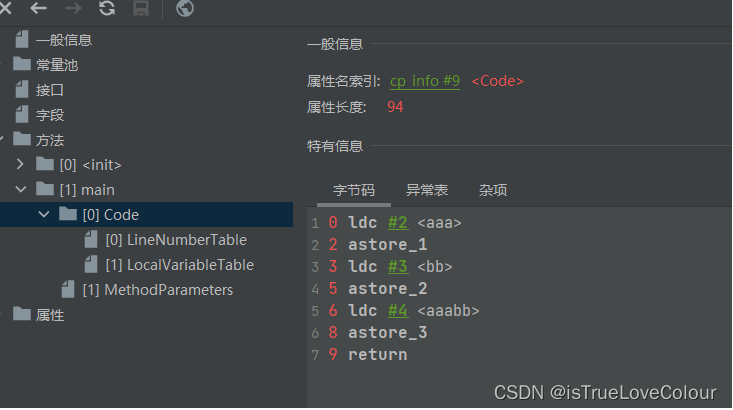
该代码对应的字节码文件如下
public static void main(String[] args) { String aa = "aaa"; String bb = "bb"; String cc = aa + bb; }- 1
- 2
- 3
- 4
- 5
- 6

但是如果,两个字符串都是常量,在编译期就被优化掉了,就不会使用 StringBuilder 拼接了,所以实际工作中,对于可以使用final修饰的,尽量使用final修饰
public static void main(String[] args) { final String aa = "aaa"; final String bb = "bb"; String cc = aa + bb; }- 1
- 2
- 3
- 4
- 5
- 6
通过StringBuilder 的append() 来拼接字符串的效率要远远高于 字符串的直接拼接
- 因为,用StringBuilder 的append 方法,自始至终只创建了一个StringBuilder ,而用户字符串的拼接,每一次拼接都会创建一个StringBuilder ,还要在调用一次 toString(),创建新的字符串对象 ,拼接的次数越多,创建的对象越多,效率差距越大
- 又因为字符串直接拼接会创建大量的 StringBuilder 和 String 对象,内存占用会很大,而且有可能会加速GC的到来,严重影响效率
- 另外如果能够确定拼接后的字符串的大概长度,可以在创建StringBuilder 时,直接指定长度,减少扩容的次数
intern
如果不是使用双引号声明的字符串,可以使用intern() 方法,该方法会使用equals()判断常量池中有没有该字符串,存在就返回常量池中的地址,不存在就把对象放入池中,并返回对象的地址
想要保证字符串在字符串常量池中:
- 使用字面量的方式声明,也就是使用""声明
- 调用intern()
关于intern的使用:
- intern会尝试将这个字符串放入字符串常量池中,如果字符串常量池中有,会返回字符串常量池中的地址
- 如果没有,在1.6中会把对象复制一份,放入字符串常量池中,并返回字符串常量池的地址,而在1.7以后,会把对象的地址复制一份,放入字符串常量池,并返回字符串常量池中的引用地址
创建字符串时产生了几个对象
//这个操作会创建两个对象,一个是在字符串常量池中创建的,另一个是堆中用new创建的 new String("ab") ;- 1
- 2
- 3
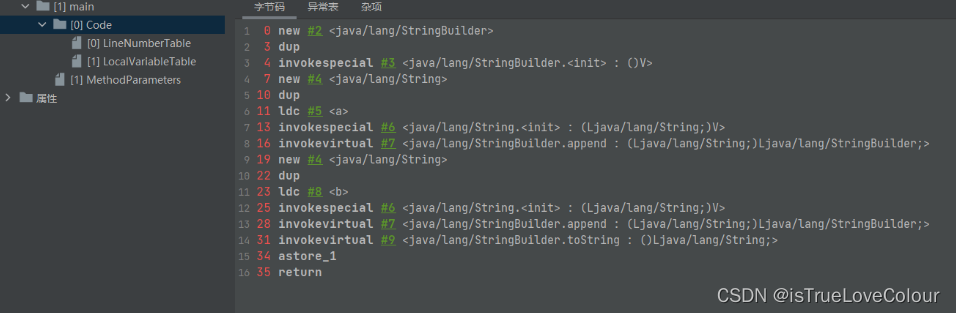
下面的代码有六个对象:
- 首先是拼接字符串产生的StringBuilder,
- 然后new了一个 String(“a”),
- 字符串常量池中有“a”,
- 接着是new String(“b”) ,
- 字符串常量池中的"b",
- 最后是StringBuilder 的 toString()
public static void main(String[] args) { String ss = new String("a") + new String("b"); }- 1
- 2
- 3
StringBuilder 的 toString() ,StringBuilder 中的数据不为空,就 new 一个新的 字符串,上面就是new String(“ab”),但是这里的“ab” 并不在字符串常量池中
private transient char[] toStringCache; public synchronized String toString() { if (toStringCache == null) { toStringCache = Arrays.copyOfRange(value, 0, count); } return new String(toStringCache, true); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
intern面试难点
下面代码在jdk1.6和jdk1.7以后的执行结果不一样,因为1.7的字符串常量池从1.6的元空间移到了堆中
public static void main(String[] args) { String s1 = new String("1"); s1.intern(); String s2 = "1"; System.out.println(s1 == s2); //false //这里最终结果相当于 new String("11"),但是字符串常量池并没有“11” String s3 = new String("1") + new String("1"); s3.intern(); //在字符串常量池中生成“11” ,在jdk1.6中是创建了一个新的对象,所以结果为false, //而1.7以后,字符串常量池在堆中,为了节省空间,调用intern方法,需要向字符串常量池中存在字符串时,如果发现 //堆中已经有了该字符串,就不会在字符串常量池中创建新的字符串了,而是直接引用堆中的字符串 String s4 = "11"; //这里使用的是上一行代码生成的“11” 的地址 System.out.println(s3==s4); //1.6 false , 1.7以后 true //所以在1.7以后,常量池中的地址和s3相等 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
字符串常量池中既有字符串对象,又有引用
如果有大量的重复字符串,使用intern 可以节约内存空间,(虽然也会创建很多对象,但是会及时回收掉,直接从常量池中使用,而不是直接使用堆中的对象)
-
相关阅读:
快来了解一下程序员的前世今生
GenICam标准(二)
从零开始—【Mac系统】MacOS配置Java环境变量
Clickhouse 用户自定义外部函数
wpf使用CefSharp.OffScreen模拟网页登录,并获取身份cookie
黑马学Docker(一)
贪心,队列,运算符重载,牛客:连环爆炸
SQL 教程之为什么 SQL 正在击败 NoSQL,以及这对数据的未来意味着什么
http协议(序列化与反序列化)
SpringBoot中常用注解的含义
- 原文地址:https://blog.csdn.net/persistence_PSH/article/details/126320808
