-
STL中sort 用的是快排吗? - 快排、堆排(heap sort)、插入排序
插入排序优势
插入排序复杂度虽然是O(n^2);
但是其时间复杂度中常数项小,并在优化情况下,小数据量时,有更快的优势;
其他复杂排序,有递归等操作带来的额外的负荷;
我这版STL中,判断用快排还是用插入排序的阈值选用的时32 ;
STL 对快排和插入排序的抉择
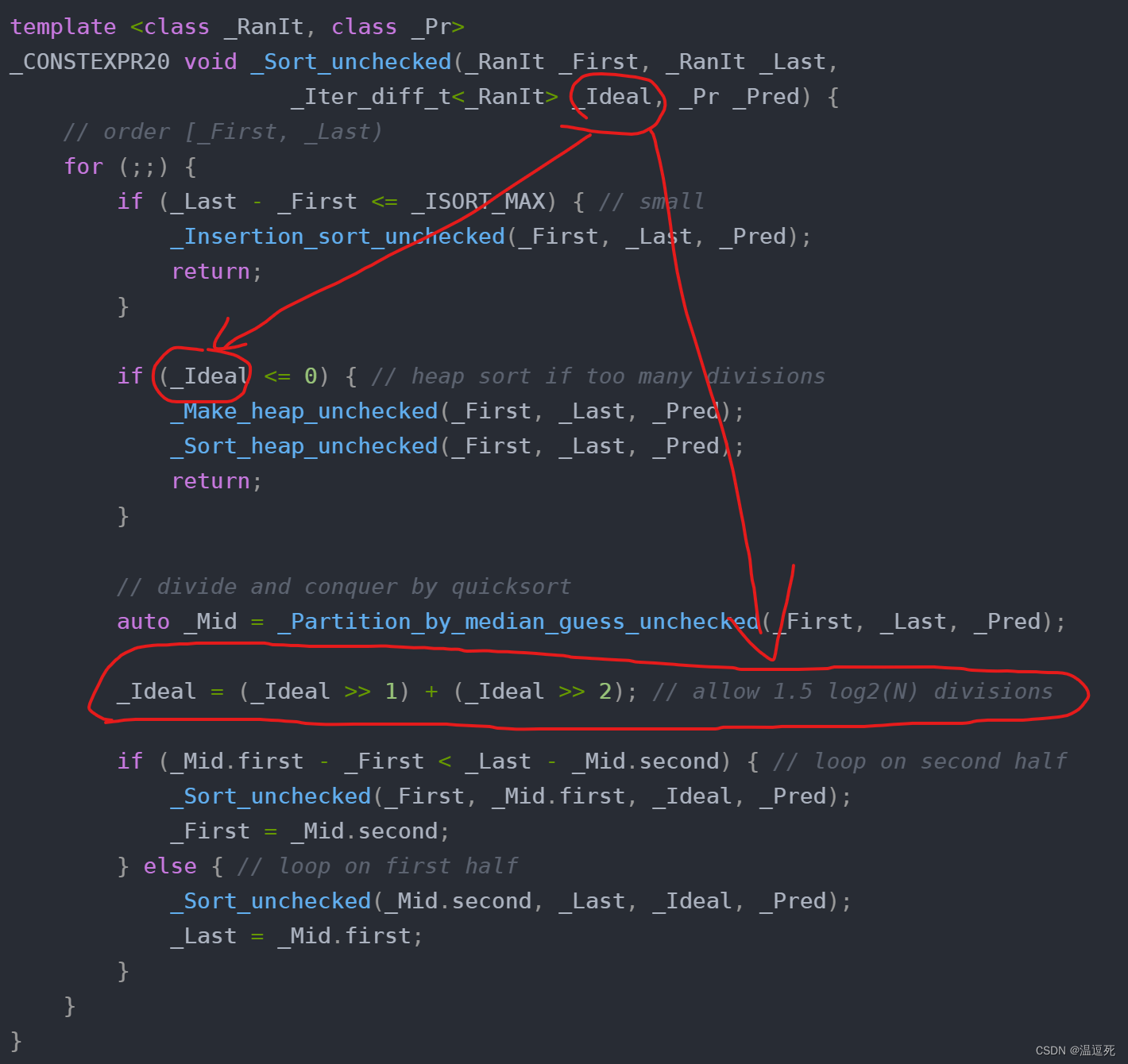
这里在for的时候,计算了数据量,根据数据量大于32、小于32 来判断:用快排 or 用插入排序;
每次递归进去,都需要判断,递归到一定的数据量还是改为插入;所以这样的sort 是快排中混着插入来做的;template <class _RanIt, class _Pr> _CONSTEXPR20 void _Sort_unchecked(_RanIt _First, _RanIt _Last, _Iter_diff_t<_RanIt> _Ideal, _Pr _Pred) { // order [_First, _Last) for (;;) { if (_Last - _First <= _ISORT_MAX) { // small _Insertion_sort_unchecked(_First, _Last, _Pred); return; } if (_Ideal <= 0) { // heap sort if too many divisions _Make_heap_unchecked(_First, _Last, _Pred); _Sort_heap_unchecked(_First, _Last, _Pred); return; } // divide and conquer by quicksort auto _Mid = _Partition_by_median_guess_unchecked(_First, _Last, _Pred); _Ideal = (_Ideal >> 1) + (_Ideal >> 2); // allow 1.5 log2(N) divisions if (_Mid.first - _First < _Last - _Mid.second) { // loop on second half _Sort_unchecked(_First, _Mid.first, _Ideal, _Pred); _First = _Mid.second; } else { // loop on first half _Sort_unchecked(_Mid.second, _Last, _Ideal, _Pred); _Last = _Mid.first; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
什么时间用堆排;
看源码时候发现:在一定情况下用到了堆排;好奇心驱使,看了一下;
其实就是每次递归计算递归深度,根据深度来决策继续快排还是堆排;
其实很正常,快排有可能退化,而堆排时间复杂度稳定,为了减少退化,肯定要优化;这个_Ideal的初始值就是数据量长度;每递归一层,都会减少,减少到0就不再快排了;每次递归进行计算;到一定的递归深度;数据量还大于32,就改用堆排;其实就是为了避免递归深度太深;
总结
STL中,大数据排序时候,首选了快排;
递归深度到达一定程度的时候,选择了堆排;(允许1.5 log2(N) 的递归深度)
数据量小到一定程度的时候,选择插入排序;(小于32个数据时候) -
相关阅读:
学信息系统项目管理师第4版系列20_风险管理
kerberos 客户端windows系统版本
Linux——03(Shell命令介绍、帮助命令、常用命令(文件目录类、echo > head tailf ln history))
如何修改springboot项目启动时的默认图标?
ubuntu18.04虚拟机ros1乐动激光雷达LD06/LD19/LD300的使用
HBase,JavaAPI操作 HBase,220827,
C++ 随机数、srand((unsigned)time(NULL)) 详解
C++内存分区概念
【教程】视频汇聚/视频监控管理平台EasyCVR录像存储功能如何优化?具体步骤是什么?
鸿蒙应用开发之三方库使用
- 原文地址:https://blog.csdn.net/qq_43142509/article/details/126315295
