-
五、配置文件的解析
一、一个小例子
package com.example.demo; import ch.qos.logback.classic.Logger; import ch.qos.logback.classic.LoggerContext; import ch.qos.logback.classic.joran.JoranConfigurator; import java.net.URL; import org.slf4j.ILoggerFactory; import org.slf4j.LoggerFactory; import org.slf4j.Marker; import org.slf4j.MarkerFactory; import org.slf4j.impl.StaticLoggerBinder; import org.springframework.core.io.ClassPathResource; /** * @author zhen_hong * @date 2022/8/9 11:21 */ public class LogbackDemo2Test { public static void main(String[] args) throws Exception { // 绑定日志实现,这里使用的是logback实现并解析配置,如果存在logback.xml,logback.groovy and so on 或者系统属性中有指定对应的路径 // ILoggerFactory loggerContext = StaticLoggerBinder.getSingleton().getLoggerFactory(); ILoggerFactory loggerContext = LoggerFactory.getILoggerFactory(); // 获取根logger ch.qos.logback.classic.Logger rootLogger = (ch.qos.logback.classic.Logger)loggerContext.getLogger(Logger.ROOT_LOGGER_NAME); // 清除默认的基本 appender 配置 rootLogger.detachAndStopAllAppenders(); // 解析配置文件 JoranConfigurator configurator = new JoranConfigurator(); configurator.setContext((LoggerContext)loggerContext); URL url = Thread.currentThread().getContextClassLoader().getResource("logback-custom.xml"); configurator.doConfigure(url); org.slf4j.Logger logger = loggerContext.getLogger(LogbackParseTest.class.getName()); logger.info("这个是一个测试方法"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
上面通过 JoranConfigurator 解析配置,将我们在配置文件中定义的 Appender 加载到了LoggerContext中,那么接下来我们将分析它是
如何解析并加载配置的,在分析之前,我们先来看看 JoranConfigurator 的继承结构。1.1 类图
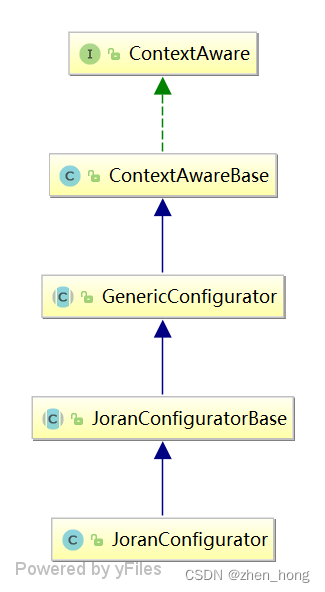
我们对这个类图做简单的介绍
- ContextAware:日志上下文aware,类似spring中的各种aware,比如ApplicationContextAware,继承该接口的类,会在使用前
注入日志上下文对象,除此之外还有一些addInfo,addWarn等添加状态的接口,在具体的实现中会记录到一个集合中,超过大小之后会
缓存在环形缓存中,另外还会除非状态监听器 - ContextAwareBase:ContextAware的基本实现
- GenericConfigurator:模板类,定义基本的解析逻辑,提供添加规则的模板方法
- JoranConfiguratorBase:添加了基本的标签解析规则
- JoranConfigurator:添加了扩展的标签解析规则
我们先来分析下 GenericConfigurator 做了什么
public final void doConfigure(final InputSource inputSource) throws JoranException { long threshold = System.currentTimeMillis(); // 使用 xml sax 驱动方式解析xml,将解析的动作按照 // start,body,end 分别封装成 StartEvent,BodyEvent,EndEvent SaxEventRecorder recorder = new SaxEventRecorder(context); recorder.recordEvents(inputSource); // doConfigure(recorder.saxEventList); // no exceptions a this level StatusUtil statusUtil = new StatusUtil(context); if (statusUtil.noXMLParsingErrorsOccurred(threshold)) { addInfo("Registering current configuration as safe fallback point"); registerSafeConfiguration(recorder.saxEventList); } } public void doConfigure(final List<SaxEvent> eventList) throws JoranException { buildInterpreter(); // disallow simultaneous configurations of the same context synchronized (context.getConfigurationLock()) { // 开始驱动解析 interpreter.getEventPlayer().play(eventList); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
logback使用sax解析xml,将解析时的开始标签,标签体内容,结束标签解析成StartEvent,BodyEvent,EndEvent,比如有如下标签
<a> <b> <c> hello logback c> b> a>- 1
- 2
- 3
- 4
- 5
- 6
- 7
sax解析方式是从第一个标签a开始 -》b-》c-》body-》/c-》/b-》/a,那么对应event集合为 a的StartEvent,b的StartEvent,c的StartEvent
,c的BodyEvent,c的EndEvent,b的EndEvent,a的EndEvent所有的event准备就绪之后就可以驱动解析了
public void play(List<SaxEvent> aSaxEventList) { eventList = aSaxEventList; SaxEvent se; // 从第一个StartEvent开始 for (currentIndex = 0; currentIndex < eventList.size(); currentIndex++) { se = eventList.get(currentIndex); if (se instanceof StartEvent) { interpreter.startElement((StartEvent) se); // invoke fireInPlay after startElement processing // 触发event监听器 interpreter.getInterpretationContext().fireInPlay(se); } if (se instanceof BodyEvent) { // invoke fireInPlay before characters processing // 触发event监听器 interpreter.getInterpretationContext().fireInPlay(se); interpreter.characters((BodyEvent) se); } if (se instanceof EndEvent) { // invoke fireInPlay before endElement processing // 触发event监听器 interpreter.getInterpretationContext().fireInPlay(se); interpreter.endElement((EndEvent) se); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
从上面的代码我们可以看到,根据不同的event类型调用不同的处理方法,在处理不同的方法前后都会触发事件监听,前面我们提到过
在解析配置文件的过程中会需要配置规则,解析某个标签时,就需要匹配到对应的规则才能进行处理,默认的规则在 JoranConfigurator
中的 addInstanceRules 添加@Override public void addInstanceRules(RuleStore rs) { // parent rules already added super.addInstanceRules(rs); //......省略部分规则代码 rs.addRule(new ElementSelector("configuration/logger"), new LoggerAction()); rs.addRule(new ElementSelector("configuration/logger/level"), new LevelAction()); rs.addRule(new ElementSelector("configuration/root"), new RootLoggerAction()); rs.addRule(new ElementSelector("configuration/root/level"), new LevelAction()); rs.addRule(new ElementSelector("configuration/logger/appender-ref"), new AppenderRefAction<ILoggingEvent>()); rs.addRule(new ElementSelector("configuration/root/appender-ref"), new AppenderRefAction<ILoggingEvent>()); // add if-then-else support rs.addRule(new ElementSelector("*/if"), new IfAction()); rs.addRule(new ElementSelector("*/if/then"), new ThenAction()); rs.addRule(new ElementSelector("*/if/then/*"), new NOPAction()); rs.addRule(new ElementSelector("*/if/else"), new ElseAction()); rs.addRule(new ElementSelector("*/if/else/*"), new NOPAction()); // ......省略部分规则代码 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
看到上面添加规则的代码,很容易想到它就是通过标签路径进行匹配的,比如我现在解析的标签是if,那么它会把IfAction匹配出来
根据事件的类型调用它的begin,body,end方法,这里不会去分析所有的action的实现方式,只会取其中一两个去分析。首先我们来看下
Appender的begin方法(它不需要body方法,所以是空实现)public void begin(InterpretationContext ec, String localName, Attributes attributes) throws ActionException { // We are just beginning, reset variables appender = null; inError = false; // 获取 class 属性的值 String className = attributes.getValue(CLASS_ATTRIBUTE); if (OptionHelper.isEmpty(className)) { addError("Missing class name for appender. Near [" + localName + "] line " + getLineNumber(ec)); inError = true; return; } try { addInfo("About to instantiate appender of type [" + className + "]"); // 实例化Appender appender = (Appender<E>) OptionHelper.instantiateByClassName(className, ch.qos.logback.core.Appender.class, context); appender.setContext(context); // Appender的名字 String appenderName = ec.subst(attributes.getValue(NAME_ATTRIBUTE)); if (OptionHelper.isEmpty(appenderName)) { addWarn("No appender name given for appender of type " + className + "]."); } else { appender.setName(appenderName); addInfo("Naming appender as [" + appenderName + "]"); } // The execution context contains a bag which contains the appenders // created thus far. // 将创建的Appender保存到解析上下文中 HashMap<String, Appender<E>> appenderBag = (HashMap<String, Appender<E>>) ec.getObjectMap().get(ActionConst.APPENDER_BAG); // add the appender just created to the appender bag. appenderBag.put(appenderName, appender); // 入栈,用于内嵌标签可能需要设置 encoder ec.pushObject(appender); } catch (Exception oops) { inError = true; addError("Could not create an Appender of type [" + className + "].", oops); throw new ActionException(oops); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
解析Append标签很简单,将Appender实例化之后根据名字保存到解析上下文中,在后边解析logger标签的时候如果这个logger内部写了
appender-ref标签,那么就会从这里取出来set到对应Logger对象里,AppenderAction的end方法没有什么特别的逻辑,只是将当前Appender
对象从栈中pop出去,下边我们来分析一个比较复杂的action -》NestedComplexPropertyIA,这个action没有对应的标签路径匹配,
在logback没有通过标签匹配到任何的action的时候,它会根据标签的名字去反射获取属性类型,比如我的标签是这样的<apender> <encoder> encoder> apender>- 1
- 2
- 3
- 4
我解析到encoder标签的时候发现没有通过标签路径解析到具体的action,那么我就会通过标签的名字 encoder,去上一个解析出来的
Appender对象里找 encoder 属性,判断它的属性是什么类型,最后会通过反射的方式将这个encoder注入进去,判断是否能够使用
NestedComplexPropertyIA 处理的方法如下:public boolean isApplicable(ElementPath elementPath, Attributes attributes, InterpretationContext ic) { // 获取标签名字 String nestedElementTagName = elementPath.peekLast(); // calling ic.peekObject with an empty stack will throw an exception if (ic.isEmpty()) { return false; } // 从栈中弹出Appender对象(不一定是appender,但是我们这里只分析Appender的情况) Object o = ic.peekObject(); // 用反射描述解析的工具类 PropertySetter parentBean = new PropertySetter(beanDescriptionCache, o); parentBean.setContext(context); // 通过标签名检查该标签对应的属性是什么类型,如果是枚举,String,int之类的都会被标记 // 为基础类型,如果是Encoder这样的对象,那么就是复杂类型 AggregationType aggregationType = parentBean.computeAggregationType(nestedElementTagName); // 当前这个action只处理复杂的类型,基本的类型由 NestedBasicPropertyIA 处理 switch (aggregationType) { case NOT_FOUND: case AS_BASIC_PROPERTY: case AS_BASIC_PROPERTY_COLLECTION: return false; // we only push action data if NestComponentIA is applicable case AS_COMPLEX_PROPERTY_COLLECTION: case AS_COMPLEX_PROPERTY: // 如果符合复杂类型,那么入栈保存 IADataForComplexProperty ad = new IADataForComplexProperty(parentBean, aggregationType, nestedElementTagName); actionDataStack.push(ad); return true; default: addError("PropertySetter.computeAggregationType returned " + aggregationType); return false; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
在没有通过标签路径匹配到action的情况下,会调用 NestedComplexPropertyIA 与 NestedBasicPropertyIA 的 isApplicable 方法去
检查是否可以应用,像我们在Appender标签里的Encoder标签就会使用到 NestedComplexPropertyIA 这个action,它首先通过标签的名字
反射出它所在对象里的类型,如果是复杂类型的就会返回true,下面我们来看看它的begin和end方法public void begin(InterpretationContext ec, String localName, Attributes attributes) { // 在调用 isApplicable 方法的时候如果符合复杂类型的条件那么会入栈,此处将 // 在 isApplicable 反射的结果取出来 IADataForComplexProperty actionData = (IADataForComplexProperty) actionDataStack.peek(); // 读取 class 属性 String className = attributes.getValue(CLASS_ATTRIBUTE); // perform variable name substitution // 替换 ${} 占位符 className = ec.subst(className); Class<?> componentClass = null; try { if (!OptionHelper.isEmpty(className)) { componentClass = Loader.loadClass(className, context); } else { // guess class name via implicit rules PropertySetter parentBean = actionData.parentBean; // 获取该属性类型 componentClass = parentBean.getClassNameViaImplicitRules(actionData.getComplexPropertyName(), actionData.getAggregationType(), ec.getDefaultNestedComponentRegistry()); } if (componentClass == null) { actionData.inError = true; String errMsg = "Could not find an appropriate class for property [" + localName + "]"; addError(errMsg); return; } if (OptionHelper.isEmpty(className)) { addInfo("Assuming default type [" + componentClass.getName() + "] for [" + localName + "] property"); } // 构建对象 actionData.setNestedComplexProperty(componentClass.newInstance()); // pass along the repository // 如果该类型是实现了 ContextAware 接口的,那么需要注入日志上下文 if (actionData.getNestedComplexProperty() instanceof ContextAware) { ((ContextAware) actionData.getNestedComplexProperty()).setContext(this.context); } // addInfo("Pushing component [" + localName // + "] on top of the object stack."); // 将该属性入解析上下文栈,因为后边这个属性内部可能还有其他的内嵌属性 // 内嵌属性同样的会调用 isApplicable 方法去判断使用什么 action ec.pushObject(actionData.getNestedComplexProperty()); } catch (Exception oops) { actionData.inError = true; String msg = "Could not create component [" + localName + "] of type [" + className + "]"; addError(msg, oops); } } public void end(InterpretationContext ec, String tagName) { // 弹出之前反射好的属性缓存 IADataForComplexProperty actionData = (IADataForComplexProperty) actionDataStack.pop(); if (actionData.inError) { return; } // 反射描述工具,描述嵌入对象,后边用于检查是否具有 parent 属性 PropertySetter nestedBean = new PropertySetter(beanDescriptionCache, actionData.getNestedComplexProperty()); nestedBean.setContext(context); // 这个嵌入对象存在 parent 属性,将父对象注入 if (nestedBean.computeAggregationType("parent") == AggregationType.AS_COMPLEX_PROPERTY) { nestedBean.setComplexProperty("parent", actionData.parentBean.getObj()); } // 如果嵌入对象实现了LifeCycle接口,这里会调用start方法,确保在使用的时候不会抛出错误 Object nestedComplexProperty = actionData.getNestedComplexProperty(); if (nestedComplexProperty instanceof LifeCycle && NoAutoStartUtil.notMarkedWithNoAutoStart(nestedComplexProperty)) { ((LifeCycle) nestedComplexProperty).start(); } // 从解析上下文弹出该嵌入对象,后边通过放射将嵌入对象注入到父对象中 Object o = ec.peekObject(); if (o != actionData.getNestedComplexProperty()) { addError("The object on the top the of the stack is not the component pushed earlier."); } else { ec.popObject(); // Now let us attach the component switch (actionData.aggregationType) { case AS_COMPLEX_PROPERTY: actionData.parentBean.setComplexProperty(tagName, actionData.getNestedComplexProperty()); break; case AS_COMPLEX_PROPERTY_COLLECTION: actionData.parentBean.addComplexProperty(tagName, actionData.getNestedComplexProperty()); break; default: addError("Unexpected aggregationType " + actionData.aggregationType); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
首先在begin方法中将嵌入对象实例化并入栈,等所有的内嵌标签解析完成之后,那么这个嵌入对象基本已经初始化完成,那么在end方法
中就可以将该对象注入到父对象当中了,所以,logback给我我们自定义Appender添加额外的属性的机会,如果我们自定义了一个Appender,
我们的Appender可能需要注入其他的什么属性,那么我们就可以将标签名设置得和属性一样的名字即可。如果你是从第一篇文章读到这的
读者,那么你已经拥有定制自己的Appender的能力了。但是我们在开发的时候,需要根据环境进行不同的配置,那么像if…then…else
这样的动态标签就少不了,下面我们就来看看IfActionpublic void begin(InterpretationContext ic, String name, Attributes attributes) throws ActionException { // IfState 封装了条件判断结果和if标签内部嵌入标签的event IfState state = new IfState(); boolean emptyStack = stack.isEmpty(); stack.push(state); if (!emptyStack) { return; } // 压栈 ic.pushObject(this); if (!EnvUtil.isJaninoAvailable()) { addError(MISSING_JANINO_MSG); addError(MISSING_JANINO_SEE); return; } state.active = true; Condition condition = null; String conditionAttribute = attributes.getValue(CONDITION_ATTR); // 执行表达式,得到结果 if (!OptionHelper.isEmpty(conditionAttribute)) { conditionAttribute = OptionHelper.substVars(conditionAttribute, ic, context); PropertyEvalScriptBuilder pesb = new PropertyEvalScriptBuilder(ic); pesb.setContext(context); try { condition = pesb.build(conditionAttribute); } catch (Exception e) { addError("Failed to parse condition [" + conditionAttribute + "]", e); } if (condition != null) { state.boolResult = condition.evaluate(); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
上面这个begin方法操作的逻辑比较简单,只是执行下条件,缓存下执行条件的结果,那么接下来就是执行then或者else标签了,ThenAction
和ElseAction都继承了 ThenOrElseActionBase,下面是它的begin方法public void begin(InterpretationContext ic, String name, Attributes attributes) throws ActionException { if (!weAreActive(ic)) return; // ThenActionState 是一个实现了 InPlayListener 接口的监听器 // 它会监听每个事件的begin,body,end操作 // ThenActionState 的实现很简单,就是用一个集合保存 then或者else 标签内的其他标签event ThenActionState state = new ThenActionState(); if (ic.isListenerListEmpty()) { // 注册监听器 ic.addInPlayListener(state); state.isRegistered = true; } stateStack.push(state); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
从上面的代码可以看到不管是ThenAction还是ElseAction,它都是通过向解析上下文注册一个监听器去收集自身标签内的其他的event,
收集完成之后他们会在IfAction中做以下操作public void end(InterpretationContext ic, String name) throws ActionException { // 。。。。。。省略部分代码 // 根据条件表达式的结果,获取在then或者else中收集的event, // 然后动态的插入到解析集合中 Interpreter interpreter = ic.getJoranInterpreter(); List<SaxEvent> listToPlay = state.thenSaxEventList; if (!state.boolResult) { listToPlay = state.elseSaxEventList; } // if boolResult==false & missing else, listToPlay may be null if (listToPlay != null) { // insert past this event interpreter.getEventPlayer().addEventsDynamically(listToPlay, 1); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
根据条件表达式的结果,获取在then或者else中收集的event,然后动态的插入到正在处理的List集合中,代码如下:
public void addEventsDynamically(List<SaxEvent> eventList, int offset) { this.eventList.addAll(currentIndex + offset, eventList); }- 1
- 2
- 3
currentIndex 是当前if的EndEvent所在的位置,它把then或者else里的event插入到这个的后面,从xml的角度来看就
相当于把if…then…else里面的内容直接提出来了,假设条件为true,就比如是这样的:<contextName>logbackcontextName> <if condition='property("env").contains("dev")'> <then> <property scope="context" name="log.level" value="DEBUG" /> then> <else> <property scope="context" name="log.level" value="INFO" /> else> if> <appender name="console" class="ch.qos.logback.core.ConsoleAppender"> <encoder> <pattern>%marker %d{HH:mm:ss.SSS} %contextName [%thread] %-5level %logger{36} - %msg%n pattern> encoder> appender> || || || VVVVVV VVVV VV <contextName>logbackcontextName> <property scope="context" name="log.level" value="DEBUG" /> <appender name="console" class="ch.qos.logback.core.ConsoleAppender"> <encoder> <pattern>%marker %d{HH:mm:ss.SSS} %contextName [%thread] %-5level %logger{36} - %msg%n pattern> encoder> appender>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
二、总结
本文分析了logback是如何解析配置文件的,配置文件的标签大部分是有对应的action处理的,除了一些通过反射动态设置的action,如果
读者自己本身有扩展logback的需求,比如就拿springboot来说,它为了从spring的环境中获取属性,使用 SpringBootJoranConfigurator
去解析配置文件,并扩展了springProperty标签,对应的action为SpringPropertyAction,当然logback本身还有一个newRule标签可以
设置用户自定义的Action,但是你自定义的标签必须放在newRule的后边才能使用。 -
相关阅读:
[word] word 如何在文档中进行分栏排版? #媒体#其他#媒体
夺走的第一份工作竟是OpenAI CEO?
肖sir__设计测试用例方法之_(白盒测试)
电影评分数据分析案例-Spark SQL
河工计院ACM2022寒假培训题单以及超详细题解
SpringCloudAlibaba实战-nacos集群部署
STM32FATFS文件系统移植
如何选择合适的汽车芯片ERP系统?
栈与队列c++算法练习
适用于ARM开发板的Armbian Linux22.08发布
- 原文地址:https://blog.csdn.net/qq_27785239/article/details/126300741
