-
ARM64内联汇编
前言
由于在内核代码中经常看到内联汇编代码,便总结下来。
1 Registers in AArch64 state
在 AArch64 应用程序级别视图中,Arm 处理元素具有:
R0-R30 共 31 个通用寄存器,R0 到 R30。 每个寄存器可以通过以下方式访问:
(1)名为 W0 至 W30 的 32 位通用寄存器。
(2)名为 X0 到 X30 的64 位通用寄存器。对于arm64系的CPU来说, 如果寄存器以x开头则表明的是一个64位的寄存器,如果以w开头则表明是一个32位的寄存器。
如下图所示:
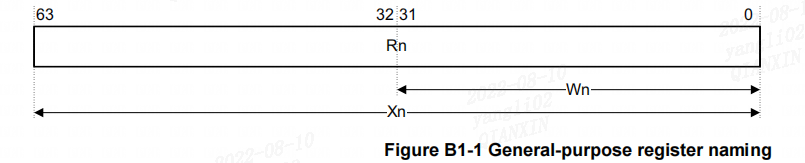
X30通用寄存器用作过程调用链接寄存器。SP:一个64位专用堆栈指针寄存器。可以使用寄存器名WSP访问堆栈指针的最低有效32位。
PC:保存当前指令地址的64位程序计数器。软件不能直接写入PC。它只能在分支、异常条目或异常返回上进行更新。2 内联汇编
2.1 dmeo
以atomic_add为例子来讲解:
// /linux-3.10.1/arch/arm64/include/asm/atomic.h /* * AArch64 UP and SMP safe atomic ops. We use load exclusive and * store exclusive to ensure that these are atomic. We may loop * to ensure that the update happens. */ static inline void atomic_add(int i, atomic_t *v) { unsigned long tmp; int result; asm volatile("// atomic_add\n" "1: ldxr %w0, %2\n" " add %w0, %w0, %w3\n" " stxr %w1, %w0, %2\n" " cbnz %w1, 1b" : "=&r" (result), "=&r" (tmp), "+Q" (v->counter) : "Ir" (i) : "cc"); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
(1)ldxr %w0, %2:w0 = %2(v->counter) //使用ldxr指令把原子变量v的值加载到32位通用寄存器中
(2)add %w0, %w0, %w3: w0 = w0 + w3 //把32位通用寄存器的值加上i
(3)stxr %w1, %w0, %2:%2(v->counter) = w0 //使用stxr指令把32位寄存器的值写到原子变量v,执行结果存储在w1
(4)cbnz %w1, 1b:若w1 != 0,跳转到标号1 //果stxr指令返回1,表示存储失败,回到上述这行 “1: ldxr %w0, %2\n”2.2 内联汇编格式
(1)
GCC嵌入式汇编,GCC嵌入式汇编的格式如下:asm volatile( Assembler Template; :outputOperands :inputOperands [:Clobbers]) )- 1
- 2
- 3
- 4
- 5
- 6
asm表示内联汇编。
volatile表示防止编译器优化后面的汇编代码部分。
内联汇编由四部分组成:
Assembler Template即汇编代码部分,必须有。其他三个为辅助参数,可选;各部分之间用冒号“:”分割,即使参数为空,也要加冒号;后面会详细介绍。(2)
在Assembler Template中我们看到 ldxr、add、stxr、cbnz等操作码。%w0,%w1,%2,%w3等操作数。操作码后面的基本都是操作数。(3)
Operands(操作数)格式:[name]"modifier+constraint"(C expression)- 1
name:别名,可选;如果指定了别名的话,那在汇编模板中,引用该变量,就可以使用别名,增加可读性。
modifier:修改符,要用双引号括起来;
constraint:限定符,要用双引号括起来;
c表达式:用小括号括起来;// /linux-5.13/arch/arm64/include/asm/atomic_lse.h #define ATOMIC_OP(op, asm_op) \ static inline void __lse_atomic_##op(int i, atomic_t *v) \ { \ asm volatile( \ __LSE_PREAMBLE \ " " #asm_op " %w[i], %[v]\n" \ : [i] "+r" (i), [v] "+Q" (v->counter) \ : "r" (v)); \ } ATOMIC_OP(andnot, stclr) ATOMIC_OP(or, stset) ATOMIC_OP(xor, steor) ATOMIC_OP(add, stadd)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
其中的 [i] 和 [v] 就是别名,在Operands指定了别名,那么就可以在汇编模板中,就可以使用别名,增加可读性。
(4)
从output operand list到input operand list,参数的命名从0开始,依次是%0,%1,%2,%3…
以上述为例:
%w0表示第0个参数,result。由于%0中间加了w,表示存放在通用寄存器中。注意在参数列表中(result)用"r"修饰。“r”表示使用一个通用寄存器。
%w1表示第1个参数tmp。由于%1中间加了w,表示存放在通用寄存器中。注意在参数列表中(tmp)用"r"修饰
%2表示第2个参数 v->counter 。
%w3表示第3个参数i。由于%3中间加了w,表示存放在通用寄存器中,同时是一个整数立即数。注意在参数列表中(i)用"r"和"I"修饰。
操作数的作用是将C语言定义的变量与汇编中使用的变量进行一 一对应,汇编器需要知道这些变量到底用在什么地方,传递前做一些转换。修饰符 说明 r 通用寄存器 m 内存地址 Q 指针间接寻址 f 浮点通用寄存器 I 整数类型的立即数 (5)
outputOperands,可以规定对输出操作数的约束条件。每个输出约束(constraint)通常以“=”号开头,接着是一个字母表示对操作数类型的说明,然后是关于变量结合的约束。
%w0操作数对应 “=&r” (result),指的是函数里的result变量。其中“&”表示该操作符只能用作输出,“=”表示该操作符只写。“r”表示使用一个通用寄存器。
%w1操作数对应"=&r" (tmp),指的是函数里的tmp变量。
%2操作数是"+Qo" (v->counter),指的是原子变量v->counter, “+”表示该操作符具有可读可写属性。inputOperands 有1个操作数:i,是%3,第三个操作数,%w3操作数对应"Ir" (i),指的是函数的参数i。用"I"和"r"修饰表示是整数类型的立即数,并且存放在通用寄存器中。
限定符 说明 = 该操作符只写,一般用于输出操作数中 & 表示该操作符只能用作输出 + 表示该操作符具有可读可写属性 (5)
Clobbers,损坏部一般以“memory”结束。“memory”告诉GCC编译器内嵌汇编指令改变了内存中的值,强制编译器在执行该汇编代码前存储所有缓存的值,在执行完汇编代码之后重新加载该值,目的是防止编译乱序。这里的"cc"表示condition registor,状态寄存器标志位。告诉编译器汇编代码会导致CPU状态位的改变。
总结
以上就是ARM64内联汇编简单介绍。
参考资料
Linux 内核 3.10.1
Linux 内核 5.13.0 -
相关阅读:
大数据_数据中台建设与架构
docker部署nacos集群
是谁在造谣杭州取消直播带货?
爬虫ip如何加入到代码里实现自动化数据抓取
Fragment碎片的切换
【FPGA教程案例35】通信案例5——基于FPGA的16QAM调制信号产生,通过matlab测试其星座图
基于Java+Spring Boot+MySQL的课程设计选题管理
BGP学习笔记
【C++ Primer Plus】第8章 函数探幽
【PHPWord】使用PHPWord替换模板变量大段文字并换行设置字体字号
- 原文地址:https://blog.csdn.net/weixin_45030965/article/details/126276377
