-
萝卜爆肝Python爬虫学习路线
最近经常有小伙伴咨询,爬虫到底该怎么学,有什么爬虫学习路线可以参考下,萝卜作为非专业爬虫爱好者,今天咱们就来分享下,对于我们平时的基础爬虫或者小规模爬虫,应该掌握哪些技能、需要如何学起!
学习路线大纲
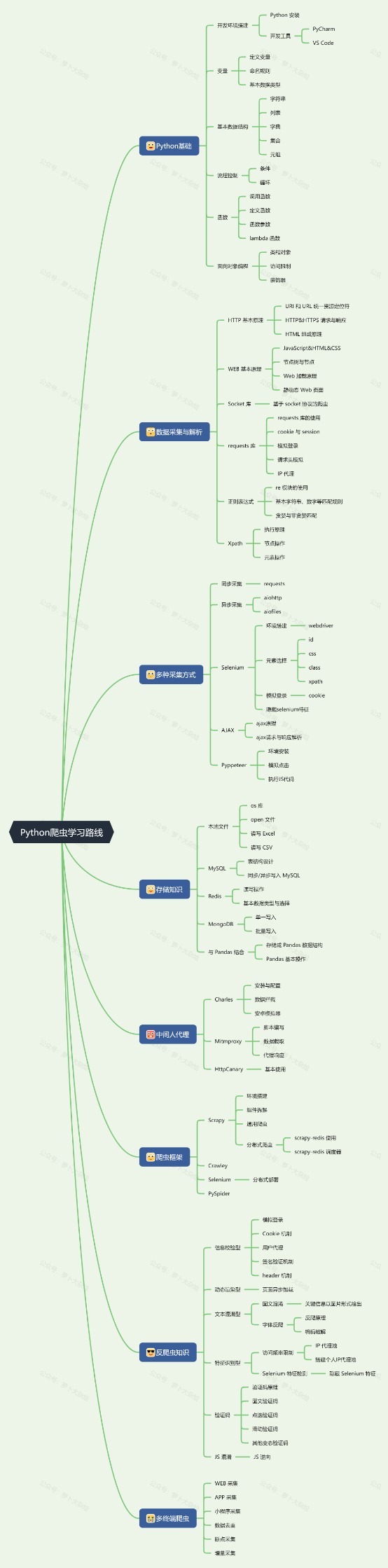
Python 基础
由于本篇主要介绍 Python 爬虫学习路线,所以对于 Python 基础知识,仅仅提取了最为基础的部分,应付基础爬虫完全够用了,当然,对于底层基础,肯定是掌握的越多、越牢固越好~
-
环境搭建 -
Python安装 -
开发工具 - PyCharm,VS Code
-
-
变量 -
定义变量 -
命名规则 -
基本数据类型
-
-
基本数据结构 -
字符串 -
列表 -
字典 -
集合 -
元组
-
-
流程控制 -
条件 -
循环
-
-
函数 -
调用函数 -
定义函数 -
函数参数 -
lambda 函数
-
-
面向对象编程 -
类和对象 -
访问限制 -
装饰器
-
数据采集与解析
-
HTTP 基本原理 -
URI 和 URL 统一资源定位符 -
HTTP&HTTPS 请求与响应 -
HTML 组成原理
-
-
WEB 基本原理 -
JavaScript&HTML&CSS -
节点树与节点 -
Web 加载原理 -
静动态 Web 页面
-
-
Socket 库 -
基于 socket 协议的爬虫
-
-
Requests 库 -
requests 库的使用 -
cookie 与 session -
模拟登录 -
请求头模拟 -
IP 代理
-
-
正则表达式 -
re 模块的使用 -
基本字符串、数字等匹配规则 -
贪婪与非贪婪匹配
-
-
Xpath -
执行原理 -
节点操作 -
元素操作
-
多种采集方式
-
同步采集 -
requests
-
-
异步采集 -
aiohttp -
aiofiles
-
-
Selenium -
环境搭建 - webdriver -
元素选择 - (id,css,class,xpath) -
模拟登录 -
隐藏 selenium 特征
-
-
AJAX -
Ajax 原理 -
Ajax 请求与响应解析
-
-
Pyppeteer -
环境安装 -
模拟点击 -
执行 JS 代码
-
存储知识
-
本地文件 -
os 库 -
open 文件 -
读写 Excel -
读写 CSV
-
-
MySQL -
表结构设计 -
同步/异步写入 MySQL
-
-
Redis -
读写操作 -
基本数据类型与选择
-
-
MongoDB -
单一写入 -
批量写入
-
-
与 Pandas 结合 -
存储成 Pandas 数据结构 -
Pandas 基本操作
-
中间人代理
-
Charles -
安装与配置 -
数据拦截 -
安卓模拟器
-
-
Mitmproxy -
脚本编写 -
数据截取 -
代理响应
-
-
HttpCanary -
基本使用
-
爬虫框架
-
Scrapy -
环境搭建 -
组件拆解 -
通用爬虫 -
分布式爬虫 - (scrapy-redis 使用,scrapy-redis 调度器)
-
-
Crawley -
Selenium -
分布式部署
-
-
PySpider
反爬虫知识
-
信息校验型 -
模拟登录 -
Cookie 机制 -
用户代理 -
签名验证机制 -
header 机制
-
-
动态渲染型 -
页面异步加载
-
-
文本混淆型 -
图文混淆 - 关键信息以图片形式给出 -
字体反爬 - (反爬原理,编码破解)
-
-
特征识别型 -
访问频率限制 - (IP 代理池,搭建个人 IP 代理池) -
Selenium 特征检测 - 隐藏 Selenium 特征
-
-
验证码 -
验证码原理 -
图文验证码 -
点选验证码 -
滑动验证码 -
其他变态验证码
-
-
JS 混淆 -
JS 逆向
-
多终端爬虫
-
WEB 采集 -
APP 采集 -
小程序采集 -
数据去重 -
断点采集 -
增量采集
以上就是整理的基础爬虫所需的学习路线,当然鉴于个人水平有限,难免有不足之处,还望不吝指教!
下面分享一些免费好用的学习资料,大家自选
视频
-
2020年Python爬虫全套课程(学完可做项目) -
https://www.bilibili.com/video/BV1Yh411o7Sz
-
-
Python爬虫编程基础5天速成(2021全新合集)Python入门+数据分析 -
https://www.bilibili.com/video/BV12E411A7ZQ
-
-
2021年最新Python爬虫教程+实战项目案例(最新录制) -
https://www.bilibili.com/video/BV1i54y1h75W
-
网盘资料
-
《Python 网络爬虫实战》 -
https://pan.baidu.com/s/1ZZ1G047X_gsd3Gq7boHKcw 提取码: h5fx
-
-
《Python 网络数据采集》 -
链接: https://pan.baidu.com/s/1yMguYZ61GaXcadYQ9_FpQA 提取码: vq8y
-
-
Python 分布式爬虫 -
链接: https://pan.baidu.com/s/1EY_n6FTnzkA7ahHstUp2oQ 提取码: 73s8
-
在线网站
-
廖雪峰官网 Python教程 -
https://www.liaoxuefeng.com/wiki/1016959663602400
-
-
莫凡 Python -
https://mofanpy.com/
-
相关法律法规
-
遵守 Robots -
控制访问速率 -
敏感信息不碰触 -
国家安全大于天 -
获取的数据不进行非法盈利 -
其他违反法律法规的动作
基本上做到以上几点,我们的爬虫就是安全的,不要过度妖魔化爬虫,当然网络更不是法外之地,要做一个合格的遵纪守法好公民!
尾声
以上就是萝卜断断续续写了几天,结合个人经验,同时也参考了网上大量的视频、文章总结而成的 Python 爬虫学习路线,确实非常的不容易,如果大家觉得满意请务必点个赞 + 在看 支持下。
公众号后台回复【爬虫路线】可以获取学习大纲思维导图原图
本文由 mdnice 多平台发布
-
-
相关阅读:
js去除字符串空格的几种方式
Cadence Allegro学习笔记【原理图篇】
windows安装 vnc server
关系数据库是如何工作的(8)
Redis-学习之字典类型
springboot+基于vue的响应式代购商城APP的设计与实现 毕业设计-附源码191654
实验1: 交换机MAC地址表学习过程实验
IT企业管理
SpringSecurity(二十)---OAuth2:实现资源服务器(上)资源服务器搭建以及直接调用授权服务器模式
@Transactional注解在类上还是接口上使用,哪种方式更好?
- 原文地址:https://blog.csdn.net/zhouwei_1989_/article/details/126273535