-
机器学习算法——聚类3(k均值算法)
一、理论讲解
给定样本集
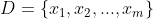 ,k均值(k-means)算法针对聚类所得簇划分
,k均值(k-means)算法针对聚类所得簇划分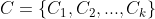 最小化平方误差为:
最小化平方误差为: (1)
(1)其中
 x是簇内
x是簇内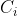 的均值向量。直观来看,(1)式在一定程度上刻画了簇内样本围绕簇均值向量的紧密程度,E越小,则簇内样本相似度越高。
的均值向量。直观来看,(1)式在一定程度上刻画了簇内样本围绕簇均值向量的紧密程度,E越小,则簇内样本相似度越高。最小化(1)式并不容易,找到它的最优解需考察样本集D所有可能的簇划分,这是一个NP难问题。因此,k均值算法采用了贪心策略,通过迭代优化来近似求解(1)式。算法流程为:
输入:样本集
;聚类簇数k过程:从D中随机选择k个样本最为初始均值向量

repeat
令

for j = 1,2,..,m do
计算样本
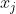 与各均值向量
与各均值向量 的距离:
的距离: ;
;根据距离最近的均值向量确定
的簇标记: ;
;将样本
划入相应的簇:
end for
for i=1,2,..,k do
计算新均值向量:

if
 then
then将当前均值向量
 更新为
更新为
else
保持当前均值不变
end if
end for
until 当前均值向量均未更新
输出:簇划分
二、案例讲解
用西瓜数据集4.0解释上述算法:
编号 密度 含糖率 1 0.697 0.460 2 0.774 0.376 3 0.634 0.264 4 0.608 0.318 5 0.556 0.215 6 0.403 0.237 7 0.481 0.149 8 0.437 0.211 9 0.666 0.091 10 0.243 0.267 11 0.245 0.057 12 0.343 0.099 13 0.639 0.161 14 0.657 0.198 15 0.360 0.370 16 0.593 0.042 17 0.719 0.103 18 0.359 0.188 19 0.339 0.241 20 0.282 0.257 21 0.748 0.232 22 0.714 0.346 23 0.483 0.312 24 0.478 0.437 25 0.525 0.369 26 0.751 0.489 27 0.532 0.472 28 0.473 0.376 29 0.725 0.445 30 0.446 0.459 假定聚类簇数为3,算法开始时随机选取三个样本
 做为初始均值向量,即
做为初始均值向量,即
考察样本
 ,它与当前均值向量
,它与当前均值向量 的距离为:
的距离为:


因此将
 划入簇
划入簇 中。类似地,对样本集中的所有样本考察一遍后,可得当前簇划分为
中。类似地,对样本集中的所有样本考察一遍后,可得当前簇划分为


于是从
 分别求出新得均值向量
分别求出新得均值向量
更新当前均值向量后,不断重复上述过程。最终在第五轮迭代产生得结果与第四轮迭代相同,于是算法终止,得到最终的簇划分。
三、代码实现
- import matplotlib.pyplot as plt
- from sklearn.cluster import KMeans
- import pandas as pd
- xigua = pd.read_csv('D:/Machine_Learning/西瓜数据集4.0.csv', encoding='gbk')
- data = xigua.values[:, [1,2]]
- print(data.shape)
- model = KMeans(n_clusters=3, random_state=10).fit(data) #默认为k-means++
- label = model.predict(data)
- print(label)
- plt.scatter(data[:,0], data[:,1], c=label)
- plt.show()
得到的结果如下:

-
相关阅读:
征服BAT精选《Spring 源码分析》核心,欢迎围观
浅谈SpringMVC的请求流程
Unity 图片相关
VSCode-常用快捷键
win10更新错误0x800f0922的解决方法
【算能全国产AI盒子】基于BM1688&CV186AH+FPGA智能物联工作站,支持差异化泛AI视觉产品定制
VPS2104 小功率反激电源控制器 4-100VIN/120V/4A 功率管
aarch64 libvirt 编译笔记
中心化决议管理——云端分析
springMvc27-get乱码解决
- 原文地址:https://blog.csdn.net/Vicky_xiduoduo/article/details/126262545