-
线性回归介绍以及实现
前言
早上没睡醒!又是在梦中被坏女人骗走感情的一天。
一、一元线性回归
线性回归的定义:线性回归是一种通过自变量(一个或多个特征值)与因变量(目标值)之间的关系来进行建模的回归分析。
一元线性回归:即只用一个x来预测y,就是一元线性回归,一元线性回归的任务即找到一条直线( y = w x + b y=wx+b y=wx+b)来尽量的拟合图中的所有数据点。

二、损失函数
损失函数:用来评价直线对于图中所有数据点的拟合程度, 一般情况下,我们使用均方误差来评价直线的拟合程度,即均方误差的值越小,说明直线越能拟合我们的数据。

MSE(Mean Square Error)均方误差:即真实值与预测值的差值的平方然后求和再平均
M S E = 1 m ∑ i = 1 m ( y i − f ( x i ) ) 2 MSE = \frac1m\sum_{i=1}^m{(y_i-f(x_i))}^2 MSE=m1i=1∑m(yi−f(xi))2
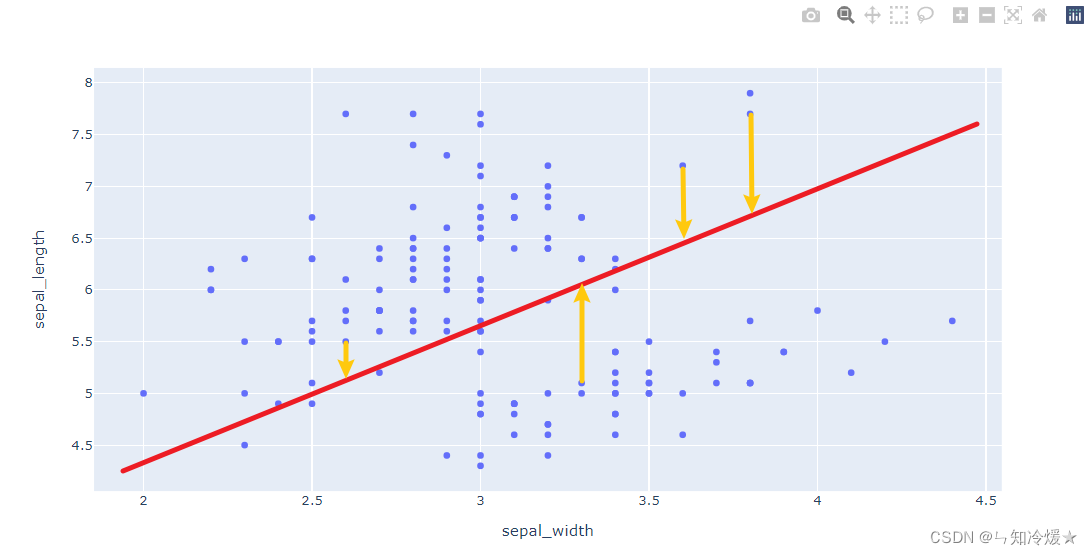
注:其中的黄色线代表真实值与预测值的差。三、损失函数的优化方法(梯度下降)
梯度下降的目的:不断学习改进,即梯度下降的目的,就是使得损失函数最小化。
梯度下降的原理:使用微积分里的导数,通过求出函数导数的值,从而找到函数下降的方向或者是最低点。

梯度下降的过程:
1、for 循环 to 训练次数(一般来说训练1000次,即较多次数,设置条件只要满足损失小于多少就停止):
2、随机生成权重w和偏差b,要求符合正态分布。(直接设置两个1也可以,后续会w和b会更新)。设置学习率,一般设置为(0.01, 0.1, 1)
3、计算每一个训练数据的预测值( y = w x + b y=wx+b y=wx+b),求得损失函数,并且计算每一个训练数据的权重和偏差相对于损失函数的梯度,即我们最终会得到每一个训练数据的权重和偏差的梯度值。
4、计算所有训练数据权重w的梯度的总和。
5、计算所有训练数据偏差b的梯度的总和。
6、求得所有样本的权重和偏差的梯度的平均值
7、根据公式来更新权重值和偏差值
w = w − L R ∗ w . g r a d w = w- LR*w.grad w=w−LR∗w.grad
b = b − L R ∗ w . g r a d b = b- LR*w.grad b=b−LR∗w.grad
8、循环,直到满足损失小于多少为止。四、使用Torch来实现线性回归
import torch import matplotlib.pyplot as plt # 设置CPU生成随机数的种子,方便下次复现实验结果。 torch.manual_seed(9) # 设置学习率为0.1 lr = 0.05 # 创建训练数据 # 创建二维列表, x = torch.rand(20, 1)*10 y = 2*x + (5 + torch.randn(20, 1))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
输出x和y:

# 随机参数w和b w = torch.randn((1), requires_grad=True) b = torch.randn((1), requires_grad=True)- 1
- 2
- 3
输出w和b:

for i in range(1000): # 前向传播 # torch.mul作element-wise的矩阵点乘,维数不限,可以矩阵乘标量 # 当a, b维度不一致时,会自动填充到相同维度相点乘。 wx = torch.mul(w, x) # 支持广播相加 y_pred = torch.add(wx, b) # 计算MSE Loss # 反向传播, ✖2分之一是为了方便求导 loss = (0.5 * (y - y_pred) ** 2).mean() # 反向传播, 计算当前梯度 loss.backward() # 更新参数 # w = w- LR*w.grad # b = b- LR*w.grad # 函数形式:torch.sub(input, other, *, alpha=1, out=None) # 参数解读: # input: 输入的被减数,格式为tensor格式 # other:输入的减数 # alpha:与上面other参数搭配使用,用来与other相乘,当使用torch.sub()函数时不指定alpha的值时,alpha默认为1 # out: 指定torch.sub()输出值被赋给的变量,可不指定。 # 然而 # torch.sub_()功能与torch.sub()相同,区别在与torch.sub_()是torch.sub()的in-place操作版本。 b.data.sub_(lr * b.grad) w.data.sub_(lr * w.grad) # 绘图 if i % 20 == 0: plt.cla() # 防止社区版可视化时模型重叠2020-12-15 plt.scatter(x.data.numpy(), y.data.numpy()) plt.plot(x.data.numpy(), y_pred.data.numpy(), 'r-', lw=5) plt.text(2, 20, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'}) plt.xlim(1.5, 10) plt.ylim(8, 28) plt.title("Iteration: {}\nw: {} b: {}".format(i, w.data.numpy(), b.data.numpy())) plt.pause(0.5) if loss.data.numpy() < 1: break plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
迭代的最终图:

参考文章:
用人话讲明白线性回归LinearRegression.
线性回归,损失的定义,损失函数与优化方法,用统计学习方法来理解线性回归、损失函数和优化方法,Sklearn使用方法.
梯度下降算法(Gradient Descent)的原理和实现步骤.
总结
年纪大了,推个简单公式得写好久。
-
相关阅读:
前端获取ip地址判断国家请求不同baseUrl
【云原生】简单谈谈海量数据采集组件Flume的理解
Mysql数据库管理-Innodb 内存优化分析
解锁前端Vue3宝藏级资料 第四章 VUE常用 UI 库 2 ( ailwind 后台框架)
数据结构-单链表-力扣题
存储设计——如何优化 ClickHouse 索引(一)
四川古力未来科技公司抖音小店:靠谱的新电商之旅
1157 Anniversary – PAT甲级真题
【R语言】生存分析模型
江西广电会展集团总经理李悦一行莅临拓世科技集团调研参观,科技璀璨AIGC掀新潮
- 原文地址:https://blog.csdn.net/weixin_42475060/article/details/126262453
