-
网络爬虫基础
目录
一、了解 爬虫的概念
模拟浏览器,发送请求,获取响应
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟客户端(主要指浏览器)发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
-
原则上,只要是客户端(浏览器)能做的事情,爬虫都能够做
-
爬虫也只能获取客户端(浏览器)所展示出来的数据
二、了解 爬虫的作用
1.数据收集:
- 抓取微博评论
- 抓取招聘网站的招聘信息
2.软件测试:
- 爬虫之自动化测试
3.抢票、刷流量
- 12306网站上抢票
- 投票网站刷票
- 秒杀抢购
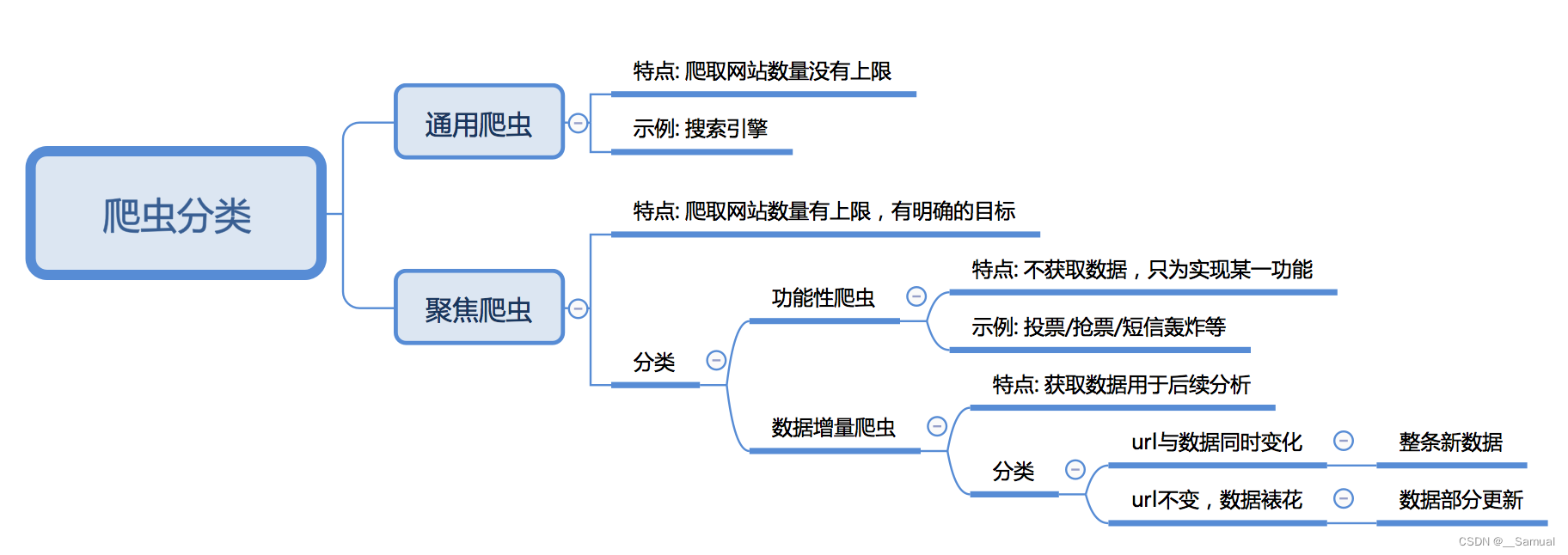
三、了解 爬虫的分类
3.1 根据被爬取网站的数量不同,可以分为:
-
通用爬虫,如 搜索引擎
-
聚焦爬虫,如12306抢票,或专门抓取某一个(某一类)网站数据
3.2 根据是否以获取数据为目的,可以分为:
-
功能性爬虫,给你喜欢的明星投票、点赞
-
数据增量爬虫,比如招聘信息
3.3 根据url地址和对应的页面内容是否改变,数据增量爬虫可以分为:
-
基于url地址变化、内容也随之变化的数据增量爬虫
-
url地址不变、内容变化的数据增量爬虫
四、掌握 爬虫的流程

-
获取一个url
-
向url发送请求,并获取响应(需要http协议)
-
如果从响应中提取url,则继续发送请求获取响应
-
如果从响应中提取数据,则将数据进行保存
-
-
相关阅读:
华为方舟编译器开源项目编译第三弹——自带测试框架使用
6、Linux-服务管理、权限管理和授权(sudo权限)
【无标题】
【菜狗学前端】uniapp(vue3|微信小程序)实现外卖点餐的左右联动功能
MySQL 是什么有什么用处下载和安装教程等值连接数据库基础知识怎么读取增删改短语优化的几种方法
农村公交与异构无人机协同配送优化
【新版】系统架构设计师 - 案例分析 - 架构设计<SOA与微服务>
Java实现Excel数据导入数据库
20min带你学习——HTTP协议、以及经典面试问题
第九章认识Express模板
- 原文地址:https://blog.csdn.net/m0_61491995/article/details/126260687