-
内核Netfilter框架的原理及功能
主要参考了《深入Linux内核架构》和《精通Linux内核网络》相关章节
Netfilter框架
Netfilter子系统提供了一个框架,它支持数据包在网络栈传输路径的各个地方(Netfilter挂接点)注册回调函数,从而对数据包执行各种操作,如修改地址或端口、丢弃数据包、写人日志等。这些Netfilter挂接点为Netfilter内核模块提供了基础设施,让它能够通过注册回调函数来执行Netfilter子系统的各种任务。
扩展网络功能
简言之,netfilter框架向内核添加了下列能力。
- 根据状态及其他条件,对不同数据流方向(进入、外出、转发)进行分组过滤(packet filtering)。
- NAT(network address translation,网络地址转换),根据某些规则来转换源地址和目标地址。例如,NAT可用于实现因特网连接的共享,有几台不直接连接到因特网的计算机可以共享一个因特网访问入口(通常称为IP伪装或透明代理)。
- **分组处理(packet manghing)和操作(manipulation),根据特定的规则拆分和修改分组。**可以通过在运行时向内核载入模块来增强netfilter功能。一个定义好的规则集,告知内核在何时使用各个模块的代码。内核和netfilter之间的接口保持在很小(小到不能再小)的规模上,尽可能使两个领域彼此隔离,避免二者的相互干扰并改进网络代码的稳定性。
- 连接跟踪
- 数据包操纵 (在路由选择之前或之后修改数据包报头的内容)
- 网络统计信息收集
- 数据包选择 (iptables)
前几节中经常提到,netfilter挂钩位于内核中各个位置,以支持netfilter代码的执行。这些不仅用于IPv4,也用于IPv6和DECNET协议,以太网(ebtables)。
这里只讨论了IPv4。netfilter实现划分为如下两个部分。
- 内核代码中的挂钩,位于网络实现的核心,用于调用netfilter代码。
- netfilter模块,其代码挂钩内部调用,但其独立于其余的网络代码。一组标准模块提供了常用的函数,但可以在扩展模块中定义用户相关的函数。
iptables由管理员用来配置防火墙、分组过滤器和类似功能,这些只是建立在netfilter框架上的模块,它提供了一个功能全面、定义良好的库函数集合,以便分组的处理。这里不会详细描述如何从用户空间激活和管理这些规则,读者可以参见网终管理方面的大量文献。
Netfilter架构及挂接点
Netfilter子系统常见框架
-
IPVS(IP Virtual Server):一种传输层负载均衡解决方案。
-
lP sets:一个由用户空间工具ipset和内核部分组成的框架,IP集合(ip set)本质上就是一组IP地址。
-
iptables:可能是目前最受欢迎的Linux防火墙,它是Netfilter前端,为netfilter提供管理层,让我们能够添加和删除Netfilter规则、显示统计信息、添加表、将表中计数器重置为0等等。
内核包含针对不同协议的iptables实现:
-
用于IPv4的iptables ( net/ipv4/netfilter/ip_tables.c )
-
用于IPv6的ip6tables ( net/ipv6/netfilter/ip6_tables.c )
-
用于ARP的arptables ( net/ipv4/netfilter/arp_tables.c )
-
用于以太网的ebtables ( net/bridge/netfilter/ebtables.c)
ebtables 就像以太网桥的 iptables 。 iptables 不能过滤桥接流量,而 ebtables 可以。 ebtables 不适合作为 Internet 防火墙。
-
Netfilter挂接点
在网络栈有5个地方设置Netfilter挂接点,ipv6和ipv4中挂接点名称相同
enum nf_inet_hooks { NF_INET_PRE_ROUTING, NF_INET_LOCAL_IN, NF_INET_FORWARD, NF_INET_LOCAL_OUT, NF_INET_POST_ROUTING, NF_INET_NUMHOOKS };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- NF_INET_PRE_ROUTING:在IPv4中,这个挂接点位于方法ip_rcv()中,方法ip_rcv()是IPv4的协议处理程序。
- 这是所有入站数据包遇到的第一个挂接点,它处于路由选择子系统查找之前。
- NF_INET_LOCAL_IN:在IPv4中,这个挂接点位于方法ip_local_deliver()中。
- 对于所有发送给当前主机的入站数据包,经过挂接点NF_INET_PRE_ROUTING并执行路由选择子系统查找后,都将到达这个挂接点。
- NF_INET_FORWARD:在IPv4中,这个挂接点位于方法ip_forward()中。
- 对于所有要转发的数据包,经过挂接点
- NF_INET_PRE_ROUTING并执行路由选择子系统查找后,都将到达这个挂接点。
NF_INET_POST_ROUTING:在IPv4中,这个挂接点位于方法ip_output()中。- 所有要转发的数据包都在经过挂接点NF_INET_FORWARD后到达这个挂接点。
- 另外,当前主机生成的数据包经过挂接点NF_INET_LOCAL_OUT后将到达这个挂接点。
- NF_INET_LOCAL_OUT:在IPv4中,这个挂接点位于方法_ip_local_out()中。
- 当前主机生成的所有出站数据包都在经过这个挂接点后到达挂接点NF_INET_POST_ROUTING。
NF_HOOK宏
当数据包在内核网络栈中传输时,会在某些地方调用NF_HOOK函数。这个函数是在include/linux/netfilter.h中定义的。
static inline int NF_HOOK(uint8_t pf, unsigned int hook, struct net *net, struct sock *sk, struct sk_buff *skb, struct net_device *in, struct net_device *out, int (*okfn)(struct net *, struct sock *, struct sk_buff *)) { int ret = nf_hook(pf, hook, net, sk, skb, in, out, okfn); if (ret == 1) ret = okfn(net, sk, skb); return ret; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
NF_HOOK()宏的参数如下:
- pf:协议簇。对于IPv4来说,它为NFPROTO_IPV4,对于IPv6来说,它为NFPROTO_IPV6。hook:上述5个挂接点之一,如NF_INET_PRE_ROUTING或NF_INET_LOCAL_OUT。skb:表示要处理的数据包的SKB对象。
- in:输入网络设备( net_device对象)。
- out:输出网络设备( net_device对象)。在有些情况下,输出设备未知,因此为NULL。例如,在执行路由选择查找前调用的方法ip_rcv() ( net/ipv4/ip_input.c )中,还不知道要使用的输出设备,因此在这个方法中调用NF_HOOK()宏时,将输出设备设置为NULL。
- okfn:一个函数指针,指向钩子回调方法执行完毕后将调用的方法。它接受一个参数——SKB。
Netfilter钩子回调函数的返回值必须为下述值之一(这些值也被称为netfilter verdicts,在include/uapi/linux/netfilter.h下定义):
- NF_DROP(0):默默地丢弃数据包。
- NF_ACCEPT(1):数据包像通常那样继续在内核网络栈中传输。
- NF_STOLEN(2):数据包不继续传输,由钩子方法进行处理。
- NF_QUEUE(3):将数据包排序,供用户空间使用。
- NF_REPEAT(4):再次调用钩子函数。
当不使用Netfilter
static inline int NF_HOOK(uint8_t pf, unsigned int hook, struct net *net, struct sock *sk, struct sk_buff *skb, struct net_device *in, struct net_device *out, int (*okfn)(struct net *, struct sock *, struct sk_buff *)) { return okfn(net, sk, skb); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
相当于连续调用okfn,从而优化掉调用NF_HOOK。
执行速度和旧的内联机制一样,而又没有内联机制的代码复制问题,因而不会增加内核可执行文件的大小。因为GNU C编译器已经能够进行一项额外的优化:过程尾部调用。该机制起源于函数式语言,例如,对Scheme语言的实现来说,这种机制是必须的。如果一个函数作为另一个函数的最后一条语句被调用,那么被调用者在结束工作后是不必返回调用者的,因为其中已经无事可做。这使得可以对调用机制进行一些简化,使执行速度能够与旧的内联机制一样,而又没有内联机制的代码复制问题,因而不会增加内核可执行文件的大小。但gcc并未对所有挂钩函数进行这种优化,仍然有少量挂钩函数是内联的。
注册Netfilter钩子回调函数 nf_hook_ops
钩子(Hook)概念源于Windows的消息处理机制,通过设置钩子,应用程序对所有消息事件进行拦截,然后执行钩子函数。
钩子函数在消息刚发出,没到达目的窗口前就先捕获了该消息,先得到控制权执行钩子函数,所以他可以加工改变该消息,当然也可以不作为,还可以强行结束该消息。
要在前面所述5个挂接点注册钩子回调函数,首先需要定义一个nf_hook_ops对象(或nf_hook_ops对象数组),然后再进行注册。结构nf_hook_ops是在include/linux netfilter.h中定义的。
struct nf_hook_ops { struct list_head list; /* 下面的内容由用户填充 */ nf_hookfn *hook; struct net_device *dev; void *priv; u_int8_t pf; /* 挂载点 */ unsigned int hooknum; /* 根据优先级,升序排列回调函数 */ int priority; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- hook:要注册的钩子回调函数,其原型如下。unsigned int nf_hookfn(unsigned int hooknum, struct sk_buff *skb, const struct net_device *in, const struct net_device *out, int (*okfn)(struct sk_buff *));
- pf:协议簇,对于IPv4来说,它为NFPROTO_IPV4,对于IPv6来说,它为NFPROTO_IPV6.
- hooknum:前面所述5个Nitfilter挂接点之一。
- priority:在同一个挂接点可注册多个回调函数,优先级越低的回调函数越早被调用。
枚举nf_ip_hook_priorities定义了IPv4钩子回调函数优先级的可能取值( include/uapi/linux/netfilter_ipv4.h),另请参见9.5节中的表9-4。
注册Netfilter钩子回调函数的方法有下面两个。
- int nf_register_hook(struct nf_hook_ops *reg) —— 注册一个nf_hook_ops对象。
- int nf_register_hooks(struct nf_hook_ops *reg, unsigned int n) —— 注册一个nf_hook_ops对象数组,其中第2个参数指出了该数组的元素数。
连接跟踪
在现代网络中,仅根据L4和L3报头来过滤流量还不够,还应考虑流量基于会话((如FTP会话或SIP会话)的情形。这里说的FTP会话指的是如下的事件序列。客户端首先在TCP端口21((默认的FTP端口)上建立TCP控制连接。FTP客户端通过这个控制端口向服务器发送命令(如列出目录的内容)。FTP服务器在端口20上打开一个数据套接字,其中,客户端的目标端口是动态分配的。应根据其他参数对流量进行过滤,如连接的状态以及超时情况。这是使用连接跟踪层的主要原因之一。
连接跟踪能够让内核跟踪会话。连接跟踪的主要目标是为NAT打下基础。如果没有设置CONFIG_NF_CONNTRACK_IPV4,就不能构建IPv4 NAT模块( net/ipv4/netfilter/iptable_nat.c )。然而,连接跟踪并不依赖于NAT。即便没有激活任何NAT规则,也可以运行连接跟踪模块。
连接跟踪初始化
ipv4_conntrack_ops - 内核注册的6个连接跟踪nf_hook_ops
以下代码片段定义了一个名为ipv4_conntrack_ops的nf_hook_ops对象数组。
/* Connection tracking may drop packets, but never alters them, so make it the first hook. */ static struct nf_hook_ops ipv4_conntrack_ops[] __read_mostly = { { .hook = ipv4_conntrack_in, .pf = NFPROTO_IPV4, .hooknum = NF_INET_PRE_ROUTING, // 挂载点 .priority = NF_IP_PRI_CONNTRACK, }, { .hook = ipv4_conntrack_local, .pf = NFPROTO_IPV4, .hooknum = NF_INET_LOCAL_OUT, .priority = NF_IP_PRI_CONNTRACK, }, { .hook = ipv4_helper, .pf = NFPROTO_IPV4, .hooknum = NF_INET_POST_ROUTING, .priority = NF_IP_PRI_CONNTRACK_HELPER, }, { .hook = ipv4_confirm, .pf = NFPROTO_IPV4, .hooknum = NF_INET_POST_ROUTING, .priority = NF_IP_PRI_CONNTRACK_CONFIRM, }, { .hook = ipv4_helper, .pf = NFPROTO_IPV4, .hooknum = NF_INET_LOCAL_IN, .priority = NF_IP_PRI_CONNTRACK_HELPER, }, { .hook = ipv4_confirm, .pf = NFPROTO_IPV4, .hooknum = NF_INET_LOCAL_IN, .priority = NF_IP_PRI_CONNTRACK_CONFIRM, }, };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
-
注册的两个最重要的连接跟踪回调函数是:NF_INET_PRE_ROUTING钩子回调函数ipv4_conntrack_in()和NF_INET_LOCAL_OUT钩子回调函数ipv4_conntrack_local()。这两个钩子回调函数的优先级为NF_IP_PRI_CONNTRACK ( -200 )。
-
数组ipv4_conntrack_ops定义的其他钩子回调函数的优先级为NF_IP_PRI_CONNTRACK_HELPER ( 300)或NF_IP_PRI_CONNTRACK.CONFIRM ( INT_MAX,其值为2^31-1 )。
在Netfilter挂接点处,优先级值越小的回调函数越先执行( include/uapi/linux/netfilter_ipv4.h中定义的枚举nf_ip_hook_priorities指定了IPv4回调函数优先级的可能取值)。
在构建内核时,如果指明了要支持连接跟踪(即设置了CONFIG_NF_CONNTRACK),则即便没有激活任何iptables规则,也会调用连接跟踪钩子回调函数。这显然会影响性能。如果说性能至关重要,而你又知道设备不会使用Netfilter子系统,应考虑构建不支持连接跟踪的内核,或者将连接跟踪构建为内核模块,而不加载它。
IPv4连接跟踪钩子回调函数的注册工作,是在方法nf_conntrack_l3proto_ipv4_init()net/ipv4/netfilter/nf_conntrack_I3proto_ipv4.c)中通过调用方法nf_register_hooks()来完成的。
in nf_conntrack_l3proto_ipv4_init(void) { . . . ret = nf_register_hooks(ipv4_conntrack_ops, ARRAY_SIZE(ipv4_conntrack_ops)) . . . }- 1
- 2
- 3
- 4
- 5
- 6
四个连接跟踪回调函数及其挂载点
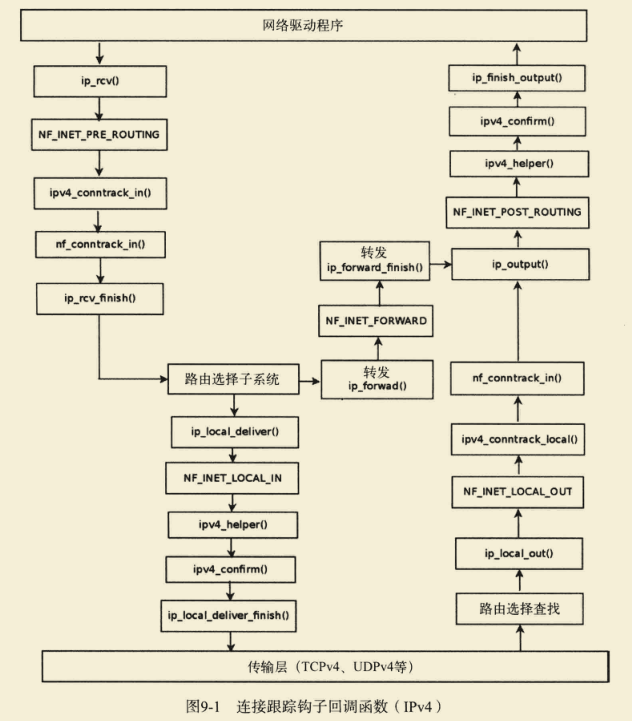
出于简化考虑,图9-1中不包含更复杂的情形,如使用IPsec、分段或组播的情形。该图还省略了在当前主机上生成并发送数据包时调用的方法,如ip_queue_xmit()和ip_buildand_send_pkt()。
图9-1显示了连接跟踪回调函数(ipv4_conntrack_in() 、 ipv4_conntrack_local()、ipv4_helper()和ipv4_confirm())及其挂接点。
连接跟踪的基本元素 nf_conntrack_tuple - 特定方向的流
连接跟踪的基本元素是结构nf_conntrack_tuple
结构nf_conntrack_tuple表示特定方向上的流。
- 结构dst的联合体包含各种协议对象,如TCP、UDP、ICMP等。每种传输层(L4)协议都有一个连接跟踪模块,这个模块实现了那些因协议而异的部分。例如,有用于TCP协议的net/netfilter/nf_conntrack_proto_tcp.c、用于UDP协议的net/netfilter/nf_conntrack_proto_udp.c,用于FTP协议的net/netfilter/nf_conntrack_ftp.c,等等。这些模块同时支持IPv4和IPv6。
include\net\netfilter\nf_conntrack_tuple.h
/* 这包含区分连接的信息 */ struct nf_conntrack_tuple { // tuple的可操作部分 struct nf_conntrack_man src; /* 下面是tuple的固定部分 */ struct { union nf_inet_addr u3; union { /* 在这里添加协议 */ __be16 all; struct { __be16 port; } tcp; struct { __be16 port; } udp; struct { u_int8_t type, code; } icmp; struct { __be16 port; } dccp; struct { __be16 port; } sctp; struct { __be16 key; } gre; } u; /* The protocol. */ u_int8_t protonum; // 协议 /* The direction (for tuplehash) */ u_int8_t dir; // 方向 } dst; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
连接跟踪条目 nf_conn
管理连接跟踪的信息
include\net\netfilter\nf_conntrack.h
struct nf_conn { /* 引用计数,散列表/析构定时器包含它,每个skb也包含它。 每创建一个相关联的期望连接,该计数器都加1*/ struct nf_conntrack ct_general; spinlock_t lock; u16 cpu; #ifdef CONFIG_NF_CONNTRACK_ZONES struct nf_conntrack_zone zone; #endif /* XXX should I move this to the tail ? - Y.K */ /* These are my tuples; original and reply */ struct nf_conntrack_tuple_hash tuplehash[IP_CT_DIR_MAX]; /* Have we seen traffic both ways yet? (bitset) */ unsigned long status; /* jiffies32 when this ct is considered dead */ u32 timeout; possible_net_t ct_net; #if IS_ENABLED(CONFIG_NF_NAT) struct rhlist_head nat_bysource; #endif /* all members below initialized via memset */ u8 __nfct_init_offset[0]; /* If we were expected by an expectation, this will be it */ struct nf_conn *master; #if defined(CONFIG_NF_CONNTRACK_MARK) u_int32_t mark; #endif #ifdef CONFIG_NF_CONNTRACK_SECMARK u_int32_t secmark; #endif /* Extensions */ struct nf_ct_ext *ext; /* Storage reserved for other modules, must be the last member */ union nf_conntrack_proto proto; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- ct_general:引用计数。
- tuplehash:有两个tuplehash对象——tuplehash[o]表示原始方向,而tuplehash[1]表示应答方向。它们通常被称为tuplehash[IP_CT_DIR_ORIGINAL]和tuplehash[IP_CT_DIR_REPLY]。
- status:条目的状态。刚开始跟踪连接时为IP_CT_NEW,连接建立后将变成IP_CT_ESTABLISHED。详情请参阅include/uapi/linux/netfilter/nf_conntrack_common.h中定义的枚举ip_conntrack_info。
- master:期望连接的主连接。由init_conntrack()方法在期望数据包到达(即init_conntrack()调用的方法nf_ct_find_expectation()找到期望连接)时设置。另请参见9.3.3节。
- timeout:连接条目的定时器。每个连接条目都会在连续一段时间内没有流量的情况下过期。这个时间段随协议而异。在方法_nf_conntrack_alloc()分配nf_conn对象时,将定时器函数timeout设置为方法death_by_timeout()。
nf_conntrack_in
详情可参考:连接跟踪子系统之核心实现
方法ipv4_conntrack_local()和ipv4_conntrack_in()都会调用方法nf_conntrack_in(),并将相应的hooknum作为参数传递给它。
方法nf_conntrack_in()包含在协议无关NAT核心中,同时用于IPv4连接跟踪和IPv6连接跟踪。它的第二个参数为协议簇,用于指明是IPv4(PF_INET)还是IPv6 (PF_INET6 )。下面来讨论回调函数nf_conntrack_in(),其他回调函数( ipv4_confirm()和ipv4_help())将在后面讨论。
nf_conntrack_in,这个函数是在PRE_ROUTING链和OUTING链调用,PRE_ROUTING链、OUTING链数netfilter的两个入口链,调用这个函数主要是初始化一条链接、更新链接状态
梳理下关键步骤:
-
根据skb找到能够处理该skb的L3协议和L4协议;
-
如果有,调用L4协议的error()回调进行报文校验,校验通过继续,否则结束;
-
调用resolve_normal_ct()查询该skb是否属于某个已有连接,没有则创建一个;
- 调用方法hash_conntrack_raw(),计算元组的散列值。
- 调用方法_nf_conntrack_find_get(),并将计算得到的散列值作为参数以查找匹配的元组。
- 如果没有找到匹配的元组,就调用方法init_conntrack()创建一个nf_conntrack_tuple_hash对象。
- 这个nf_conntrack_tuple_hash对象会被加入到未确定tuplehash对象列表中。该列表包含在网络命名空间对象中。结构net包含一个netns_ct对象,该对象中包含网络命名空间的连接跟踪信息。netns_ct的成员之一就是unconfirmed,这是一个未确认tuplehash对象列表(参见include/net/netns/conntrack.h )。随后,在方法__nf_conntrack_confirm()中,将把新创建的nf_conntrack_tuple_hash对象从未确认列表中删除。方法__nf_conntrack_confirm()将在本节后面讨论。
每个SKB都有一个名为nfctinfo的成员,它表示连接状态(例如,对于新连接来说,它为IP_CT_NEW);还有一个名为nfct的成员(一个nf_conntrack结构实例),它实际上是一个引用计数。这两个成员都由方法resolve_normal_ct()进行初始化。
-
调用L4协议的packet()回调,该回调的返回值将作为该Netfilter钩子的返回值,一般应该都是NF_ACCEPT。
方法ipv4_confirm()在挂接点NF_INET_POST_ROUTING和NF_INET_LOCAL_IN被调用,它通常调用方法_nf_conntrack_confirm(),来将元组从未确认列表中删除。
unsigned int nf_conntrack_in(struct net *net, u_int8_t pf, unsigned int hooknum, struct sk_buff *skb) { struct nf_conn *ct, *tmpl; // 连接跟踪条目 enum ip_conntrack_info ctinfo; struct nf_conntrack_l3proto *l3proto; struct nf_conntrack_l4proto *l4proto; unsigned int *timeouts; unsigned int dataoff; u_int8_t protonum; int ret; tmpl = nf_ct_get(skb, &ctinfo); /*nfct不为NULL说明已经建立连接跟踪选项*/ if (tmpl || ctinfo == IP_CT_UNTRACKED) { /* Previously seen (loopback or untracked)? Ignore. */ // 首先判断skb->nfct不为NULl而且nf_ct_is_template为NULL说明数据包已经建立了连接跟踪选项,就直接返回 if ((tmpl && !nf_ct_is_template(tmpl)) || ctinfo == IP_CT_UNTRACKED) { NF_CT_STAT_INC_ATOMIC(net, ignore); return NF_ACCEPT; } skb->_nfct = 0; } /* rcu_read_lock()ed by nf_hook_thresh */ /* 首先检查能否跟踪网络层(L3)协议,根据三层协议号在nf_ct_l3protos数组中寻找三层struct nf_conntrack_l3proto实例 */ l3proto = __nf_ct_l3proto_find(pf); // 获取四层协议号 ret = l3proto->get_l4proto(skb, skb_network_offset(skb), &dataoff, &protonum); if (ret <= 0) { pr_debug("not prepared to track yet or error occurred\n"); NF_CT_STAT_INC_ATOMIC(net, error); NF_CT_STAT_INC_ATOMIC(net, invalid); ret = -ret; goto out; } // 根据三层协议号、四层协议号获取四层struct nf_conntrack_l4proto实例 l4proto = __nf_ct_l4proto_find(pf, protonum); /* 检查协议特定的错误条件,前面所讲用于检查数据包是否受损、校验和是否有效等 */ if (l4proto->error != NULL) { ret = l4proto->error(net, tmpl, skb, dataoff, pf, hooknum); if (ret <= 0) { NF_CT_STAT_INC_ATOMIC(net, error); NF_CT_STAT_INC_ATOMIC(net, invalid); ret = -ret; goto out; } /* ICMP[v6] protocol trackers may assign one conntrack. */ if (skb->_nfct) goto out; } repeat: ret = resolve_normal_ct(net, tmpl, skb, dataoff, pf, protonum, l3proto, l4proto); if (ret < 0) { /* Too stressed to deal. */ NF_CT_STAT_INC_ATOMIC(net, drop); ret = NF_DROP; goto out; } /* 从tuple hash表中获取struct nf_conn结构体和reply方向数据包标志 */ ct = nf_ct_get(skb, &ctinfo); if (!ct) { /* Not valid part of a connection */ NF_CT_STAT_INC_ATOMIC(net, invalid); ret = NF_ACCEPT; goto out; } /* Decide what timeout policy we want to apply to this flow. */ timeouts = nf_ct_timeout_lookup(net, ct, l4proto); /*填充tuple结构中四层的元素*/ ret = l4proto->packet(ct, skb, dataoff, ctinfo, pf, hooknum, timeouts); if (ret <= 0) { /* Invalid: inverse of the return code tells * the netfilter core what to do */ pr_debug("nf_conntrack_in: Can't track with proto module\n"); nf_conntrack_put(&ct->ct_general); skb->_nfct = 0; NF_CT_STAT_INC_ATOMIC(net, invalid); if (ret == -NF_DROP) NF_CT_STAT_INC_ATOMIC(net, drop); /* 特殊情况:TCP 跟踪器报告尝试重新打开一个关闭/中止连接。 我们必须回去创建一个新的 conntrack。*/ if (ret == -NF_REPEAT) goto repeat; ret = -ret; goto out; } if (ctinfo == IP_CT_ESTABLISHED_REPLY && !test_and_set_bit(IPS_SEEN_REPLY_BIT, &ct->status)) nf_conntrack_event_cache(IPCT_REPLY, ct); out: if (tmpl) nf_ct_put(tmpl); return ret; } EXPORT_SYMBOL_GPL(nf_conntrack_in);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
iptables
iptables由两部分组成:内核部分和用户空间部分。
-
内核部分是核心。用于IPv4的内核部分位于net/ipv4/netfilter/ip_tables.c中。
-
用户空间部分提供了用于访问iptables内核层的前端(例如,使用iptables命令添加和删除规则)
- 每个表都由include/linux/netfilter/x_tables.h中定义的结构xt_table表示。
表规定了挂载点、协议、优先级、名字、初始化函数(注册) - 注册和注销表的工作分别由方法 ipt_register_table()和ipt_unregister_table()完成。
这些方法是在net/ipv4/netfilter/ip_tables.c中实现的。
- 每个表都由include/linux/netfilter/x_tables.h中定义的结构xt_table表示。
iptables内核层的前端
为理解iptables的工作原理,现在来看一个真实的过滤表。出于简化考虑,这里假设只创建了这个过滤表,另外还支持LOG目标。所用的唯一一条规则是用于日志的,稍后你将看到这一点。首先来看看这个过滤表的定义。
net\ipv4\netfilter\iptable_filter.c (iptables filter table模块)
MODULE_LICENSE("GPL"); MODULE_AUTHOR("Netfilter Core Team- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
请注意,这个过滤表有如下3个钩子:
- NF_INET_LOCAL_IN
- NF_INET_FORWARD
- NF_INET_LOCAL_OUT
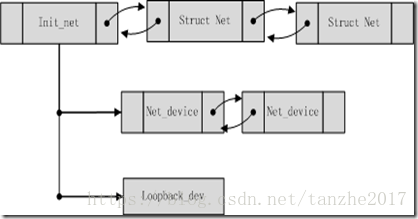
linux内核中网络空间的概念,即struct net表示内核网络的命名空间。网络系统在初始化的时候会初始化一个初始网络命名空间,即init_net命名空间。后续创建的net namespace命名空间会和init_net一起通过list项组织起来,且每个网络设备都对应一个命名空间,同一命名空间下的网络设备通过dev_base_head组织在一起。组织结构如下:
// net初始化 static struct pernet_operations iptable_filter_net_ops = { .init = iptable_filter_net_init, .exit = iptable_filter_net_exit, }; static int __net_init iptable_filter_net_init(struct net *net) { if (net == &init_net || !forward) return iptable_filter_table_init(net); // 调用iptable_filter_table_init return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
为了初始化这个表,首先调用方法ipt_alloc_initial_table。
接下来,调用方法ipt_register_table()(请注意,IPv4 netns对象net->ipv4包含一个指过滤表iptable_filter的指针)。static int __net_init iptable_filter_table_init(struct net *net) { struct ipt_replace *repl; int err; if (net->ipv4.iptable_filter) return 0; repl = ipt_alloc_initial_table(&packet_filter); if (repl == NULL) return -ENOMEM; /* Entry 1 is the FORWARD hook */ ((struct ipt_standard *)repl->entries)[1].target.verdict = forward ? -NF_ACCEPT - 1 : -NF_DROP - 1; err = ipt_register_table(net, &packet_filter, repl, filter_ops, &net->ipv4.iptable_filter); kfree(repl); return err; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
在这个示例中,使用iptable命令行设置如下规则。
iptables -A INPUT -p udp --dport=5001 -j LOG --log-level 1 这条规则的意思是,将目标端口为5001的UDP入站数据包转储到系统日志中。修饰符log-level可指定0~7的系统日志标准等级。其中0表示紧急,7表示调试。
**请注意,运行iptables命令时,应使用修饰符-t来指定要使用的表。例如,iptables -t nat -A POSTROUTING -o etho -jMASQUERADE会在NAT表中添加一条规则。**如果没有使用修饰符-t指定表,默认将使用过滤表。因此,命令iptables -A INPUT -p udp --dport=5001 -j LOG --log-level 1将在过滤表中添加一条规则。 请注意,要像前面的示例那样在iptables规则中使用目标LOG,必须设置CONFIG_NETFILTER.XT_TARGET_LOG。有关iptables目标模块的示例,请参阅netnetfilter/xt_LOGc的代码。
**目标端口为5001的UDP数据包在到达网络驱动程序,并向上传递到网络层(L3)后,将遇到第一个挂接点NF_INET_PRE_ROUTING,但这里的过滤表并没有注册这个挂接点。它只有3个挂接点:NF_INET_LOCAL_IN、NF_INET_FORWARD和NF_INET_LOCAL_OUT,这在前面说过。因此,将接着执行方法ip_rcv_finish(),在路由选择子系统中查找。此时可能出现的情况有两种:数据包需要投递到当前主机或数据包需要转发(这里不考虑数据包需要丢弃的情形)。**图9-2说明了数据包在这两种情形下的旅程。可以为iptables规则指定目标,这个目标通常是Linux Netfilter子系统定义的目标(参见前面使用目标LOG的示例)。你还可以编写自己的目标,并通过扩展iptables用户空间代码来支持它们。详情请参阅Jan Engelhardt和Nicolas Bouliane撰写的文章“Writing NetfilterModules”,其网址为http://inai.de/documents/Netfilter_Modules.pdf。

网络地址转换(NAT)
顾名思义,网络地址转换(NAT,Network Address Translation )模块主要用于处理IP地址转换或端口操纵。
NAT最常见的用途之一是,让局域网中一组使用私有IP地址的主机能够通过内部网关访问Internet。为此,可设置NAT规则。安装在网关上的NAT可使用这样的规则,从而让主机能够访问Web。 Netfilter子系统包含用于IPv4和IPv6的NAT实现。IPv6NAT实现主要基于IPv4实现,在用户看来,它提供的接口与IPv4类似。NAT配置类型很多,网上有大量NAT管理方面的文档。
这里讨论两种常见的配置:SNAT和DNAT。
- 其中,前者指的是源NAT,修改的是源IP地址;而后者指的是目标NAT,修改的是目标IP地址。
- 要指定使用SNAT还是DNAT,可使用-j标志。DNAT和SNAT的实现都包含在net/netfilter/xt_nat.c中。下面来讨论NAT的初始化。
NAT有三种类型:静态NAT,动态地址NAT、网络地址端口转换NAPT(把内部地址映射到外部网络的一个IP地址的不同端口上)。
NAT主要实现功能:数据包伪装、负载平衡、端口转发和透明代理。
NAT工作原理:当私有网主机和公共网主机通信的IP包经过NAT网关时,将IP包中的源或目的IP在私有IP和NAT的公共IP之间进行转换。NAT模块初始化
内核的参考这里:netfilter之nat初始化
与上一节介绍的过滤表一样,NAT表也是一个xt_table对象,在除NF_INET_FORWARD外的所有挂接点都注册了它。
net\ipv4\netfilter\iptable_nat.c
static const struct xt_table nf_nat_ipv4_table = { .name = "nat", .valid_hooks = (1 << NF_INET_PRE_ROUTING) | (1 << NF_INET_POST_ROUTING) | (1 << NF_INET_LOCAL_OUT) | (1 << NF_INET_LOCAL_IN), .me = THIS_MODULE, .af = NFPROTO_IPV4, .table_init = iptable_nat_table_init, };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
NAT表的注册和注销是分别通过调用ipt_register_table()和ipt_unregister_table()( net/ipv4/netfilter/iptable_nat.c)完成的。
struct netns_ipv4 { ... #ifdef CONFIG_NETFILTER struct xt_table *iptable_filter; struct xt_table *iptable_mangle; struct xt_table *iptable_raw; struct xt_table *arptable_filter; #ifdef CONFIG_SECURITY struct xt_table *iptable_security; #endif struct xt_table *nat_table; #endif ... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
nf_nat_ipv4_ops
网络命名空间(结构net)包含一个IPv4专用对象(netns_ipv4),其中包含指向IPv4NAT表(nat_table)的指针。表示NAT表的xt_table对象由方法ipt_register_table()创建,并被分配给指针nat_table。此外,还定义并注册了一个nf_hook_ops对象数组。
static struct nf_hook_ops nf_nat_ipv4_ops[] __read_mostly = { /* 包过滤前,改变目的地 */ { .hook = iptable_nat_ipv4_in, // 注册的钩子回调函数 .pf = NFPROTO_IPV4, .hooknum = NF_INET_PRE_ROUTING, .priority = NF_IP_PRI_NAT_DST, }, /* 包过滤后,改变源 */ { .hook = iptable_nat_ipv4_out, .pf = NFPROTO_IPV4, .hooknum = NF_INET_POST_ROUTING, .priority = NF_IP_PRI_NAT_SRC, }, /* 包过滤前,改变目的地 */ { .hook = iptable_nat_ipv4_local_fn, .pf = NFPROTO_IPV4, .hooknum = NF_INET_LOCAL_OUT, .priority = NF_IP_PRI_NAT_DST, }, /* 包过滤后,改变源 */ { .hook = iptable_nat_ipv4_fn, .pf = NFPROTO_IPV4, .hooknum = NF_INET_LOCAL_IN, .priority = NF_IP_PRI_NAT_SRC, }, };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
注册数组nf_nat_ipv4_ops的工作是在方法iptable_nat_init()中完成的。
static int __net_init iptable_nat_table_init(struct net *net) { struct ipt_replace *repl; int ret; if (net->ipv4.nat_table) return 0; repl = ipt_alloc_initial_table(&nf_nat_ipv4_table); if (repl == NULL) return -ENOMEM; ret = ipt_register_table(net, &nf_nat_ipv4_table, repl, nf_nat_ipv4_ops, &net->ipv4.nat_table); kfree(repl); return ret; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
NAT钩子回调函数和连接跟踪钩子回调函数
钩子(Hook)概念源于Windows的消息处理机制,通过设置钩子,应用程序对所有消息事件进行拦截,然后执行钩子函数。
钩子函数在消息刚发出,没到达目的窗口前就先捕获了该消息,先得到控制权执行钩子函数,所以他可以加工改变该消息,当然也可以不作为,还可以强行结束该消息。
在有些挂接点处,同时注册了NAT回调函数和连接跟踪回调函数。
-
例如,在挂接点NF_INET_PRE_ROUTING(入站数据包遇到的第一个挂接点)处,注册了两个回调函数:连接跟踪回调函数ipv4_conntrack_in()和NAT回调函数nf_nat_ipv4_in()。
- 连接跟踪回调函数ipv4_conntrack_in()的优先级为NF_IP_PRI_CONNTRACK( -200 ),而NAT回调函数nf_nat_ipv4_in()的优先级为NF_IP_PRI_NAT_DST ( -100)。在同一个挂接点,优先级越低的回调函数越先被调用,因此优先级为-200的连接跟踪回调函数ipv4_conntrack_in()将先于优先级为-100的NAT回调函数nf_nat_ipv4_in()被调用。
- ipv4_conntrack_in()和nf_nat_ipv4_in()的位置。它们的位置相同,都位于挂接点NF_INET_PRE_ROUTING处。这是因为NAT在连接跟踪层查找,如果没有找到匹配的条目(未被跟踪),NAT将不会执行地址转换。
-
在挂接点NF_INET_POST_ROUTING处,注册了两个连接跟踪回调函数: ipv4_helper()和ipv4_confirm(),它们的优先级分别为NF_IP_PRI_CONNTRACK_HELPER (300)和NF_IP_PRI_CONNTRACK_CONFIRM(INT_MAX,最大的优先级整数值)。**该挂接点处还注册了一个NAT回调函数nf_nat_ipv4_out(),其优先级为NF_IP_PRI_NAT_SRC(100)。**因此,到达挂接点NF_INET_POST_ROUTING后,将首先调用NAT回调函数nf_nat_ipv4_out(),然后调用方法ipv4_helper(),最后调用ipv4_confirm(),如图9-4所示。
下面来看一条简单的DNAT规则、被转发的数据包的旅程以及连接跟踪回调函数和NAT回调函数的调用顺序(出于简化考虑,这里假设内核映像不包含过滤表功能)。在图9-3所示的网络中中间的主机(AMD服务器)运行下面这条DNAT规则。
iptables -t nat -A PREROUTING -j DNAT -p udp --dport 9999 --to-destination 192.168.1.8- 1

这条DNAT规则的意思是,对于前往UDP目标端口9999的人站UDP数据包,会将其目标地址改为192.168.1.8。右边的机器(Linux台式机)向192.168.1.9发送UDP目标端口为9999的数据包。在AMD服务器中,根据DNAT规则,会将这个IPv4目标地址改为192.168.1.8,并将数据包发送给左边的笔记本电脑。
图9-4说明了第一个UDP数据包的旅程,这个数据包是根据上述配置发送的。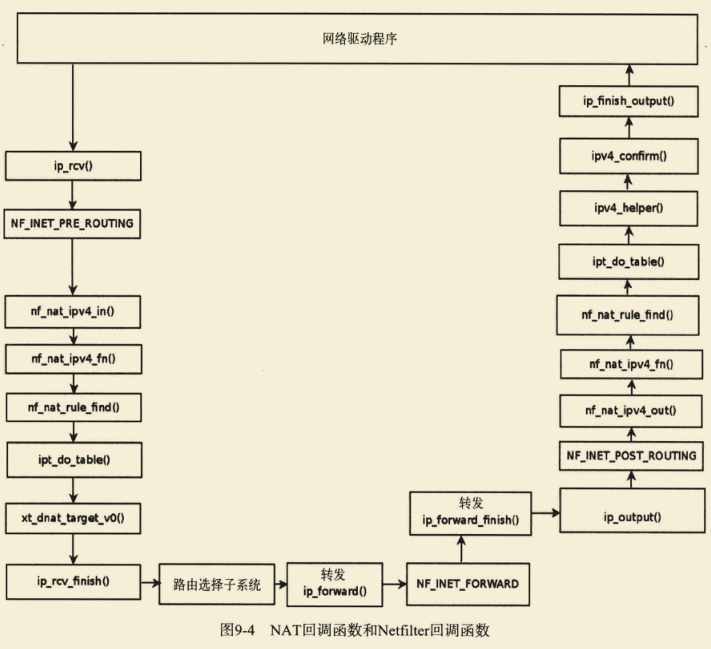
TCP协议的manip_pkt(),更换端口
通用的NAT模块为net/netfilter/nf_nat_core.c。NAT实现的基本元素为结构nf_nat_l4proto( include/net/netfilter/nf_nat_l4proto.h)和nf_nat_l3proto。这两个结构提供了协议无关的NAT核心支持。
const struct nf_nat_protocol nf_nat_protocol_tcp = { .protonum = IPPROTO_TCP, .me = THIS_MODULE, /*对四层协议的做NAT转换*/ .manip_pkt = tcp_manip_pkt, /*做NAT时判断四层协议是否在合法范围内(TCP/UDP就是判断端口是否合法)*/ .in_range = nf_nat_proto_in_range, /*根据tuple和rang选择一个没有使用的tuple*/ .unique_tuple = tcp_unique_tuple, #if defined(CONFIG_NF_CT_NETLINK) || defined(CONFIG_NF_CT_NETLINK_MODULE) .range_to_nlattr = nf_nat_proto_range_to_nlattr, .nlattr_to_range = nf_nat_proto_nlattr_to_range, #endif };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
这两个结构都包含函数指针manip_pkt(),它会修改数据包报头。来看看TCP协议的manip_pkt()实现( net/netfilter/nf_nat_proto_tcp.c ) .
static bool tcp_manip_pkt(struct sk_buff *skb, const struct nf_nat_l3proto *l3proto, unsigned int iphdroff, unsigned int hdroff, const struct nf_conntrack_tuple *tuple, enum nf_nat_manip_type maniptype) { struct tcphdr *hdr; __be16 *portptr, newport, oldport; int hdrsize = 8; /* TCP连接跟踪控制的报头的长度 */ /* 这可能是ICMP数据包的内部报头;在这种情况下, 无法更新校验和字段(在icmp的data内部),因为它不在我们控制的8字节传输层报头内 */ if (skb->len >= hdroff + sizeof(struct tcphdr)) // 保证能安全访问tcphdr,icmp和ip的校验和另行更新 hdrsize = sizeof(struct tcphdr); if (!skb_make_writable(skb, hdroff + hdrsize)) return false; hdr = (struct tcphdr *)(skb->data + hdroff); /* 根据maniptype来设置newport。 如果maniptype为NF_NAT_MANIP_SRC,说明需要修改源端口,因此从tuple->src中提取源端口。 如果maniptype为NF_NAT_MANIP_DST,说明需要修改目标端口,因此从tuple->dst中提取目标端口. */ if (maniptype == NF_NAT_MANIP_SRC) { /* Get rid of src port */ newport = tuple->src.u.tcp.port; portptr = &hdr->source; } else { /* Get rid of dst port */ newport = tuple->dst.u.tcp.port; portptr = &hdr->dest; } /* 接下来修改TCP报头的源端口( maniptype为NF_NAT_MANIP_SRC时)或目标端口( maniptype为NF_NAT_MANIP_DST时),并重新计算校验和。 必须保留原来的端口,以供重新计算校验和时使用。重新计算校验和的工作是通过调用方法csum_update()和inet_proto_csum_replace2()完成的。 */ oldport = *portptr; *portptr = newport; if (hdrsize < sizeof(*hdr)) // 只能控制8字节,无法重新计算校验和 return true; // 重新计算校验和 l3proto->csum_update(skb, iphdroff, &hdr->check, tuple, maniptype); inet_proto_csum_replace2(&hdr->check, skb, oldport, newport, false); return true; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
IPv4协议的专用NAT(略)
IPv4协议的专用NAT模块为net/ipv4/netfilter/iptable_nat.c,而IPv6协议的专用NAT模块为net/ipv6/ netfilter/ip6table nat.c。这两个NAT模块都有4个钩子回调函数,如表9-1所示

在这些IPv4回调函数中,最重要的是方法nf_nat_ipv4_fn(),其他3个方法( nf_nat_ipv4_in().nf_nat_ipv4_out()和nf_nat_ipv4_local_fn())都调用它。
-
相关阅读:
Centos7上使用yum安装mysql8.x
【SpringCloud】Gateway网关、SpringCloud Config配置中心、消息总线BUS以及Spring Cloud Stream
python re findall search finditer complie 预加载
合并集合(c++题解)
738. 单调递增的数字
python进程与线程
我该如何入门Python机器学习?
vue实现无感刷新token
redis set命令总结
Mybatis动态sql全面详解
- 原文地址:https://blog.csdn.net/qq_53111905/article/details/126251910
