-
Keras深度学习实战(17)——使用U-Net架构进行图像分割
Keras深度学习实战(17)——使用U-Net架构进行图像分割
0. 前言
我们已经在系列博文中学习了如何检测对象类别以及定位图像中对象的边界框,即图像分类与目标检测。图像分割 (
Image Segmentation) 是计算机视觉领域中另一重要和基础性的问题,也是十分具有挑战性的任务之一。在本节中,我们将学习如何使用神经网络模型执行图像分割任务。1. 图像分割相关研究
1.1 图像分割简介
图像分割是指将图像分成若干互不重叠的子区域,使得同一个子区域内的特征具有一定相似性、不同子区域间特征呈现较为明显的差异。图像分割是是计算机视觉中一项基础的任务,已经广泛应用于许多实际场景中,例如自动驾驶、医学图像处理和面部分割等。
1.2 图像分割分类
按照图像中对象被分割后的结果,可以将图像分割分为语义分割、实例分割和全景分割三种类型,不同类型的分割结果如下图所示。

语义分割 (Semantic Segmentation) 是为了便于图像分析而为图像中的每个像素分配标签的过程,属于某个对象的所有像素都被突出显示,比如用值1覆盖车辆对象像素(假设像素值在0 - 1之间),用值0.5覆盖人物对象像素,而其他像素则使用其他值显示。
实例分割 (Instance Segmentation) 可以看作是目标检测和语义分割的结合,实例分割为属于同一对象类的不同对象实例分配不同的标签。相比目标检测标记对象的边界框,实例分割可以精确检测对象的边缘信息;相比语义分割,实例分割可以标注出图像上同一类对象的不同个体。例如,使用不同颜色覆盖不同人物。
全景分割 (Panorama Segmentation) 可以看作是语义分割和实例分割的结合,需要同时对图像中所有物体和背景进行检测和分割。其中,对背景区域的分割属于语义分割,而对物体的分割属于实例分割。1.3 U-Net 架构在图像分割中的应用
U-Net是基于卷积神经网络的一种改进架构,可以在只有少量图像数据集上训练并且能够得到很好的分割效果。该模型之所以称为U-Net,是由于其类似U形的体系结构,模型的U形结构是由于卷积层得到的特征会直接连接到上采样层,典型的U-Net架构如下图所示。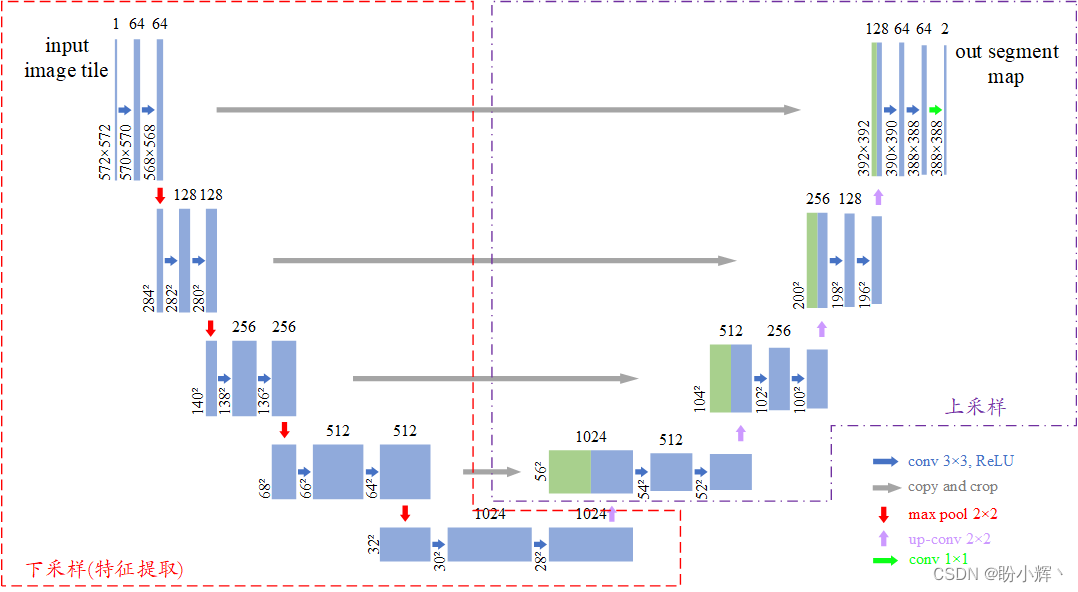
U-Net是典型的编码器-解码器结构,并且在结构上是对称的。在编码器阶段,通过多个卷积和卷积操作提取图像特征,得到较小尺寸的特征图;在解码器阶段,对特征图进行上采样,并且在上采样过程中U-Net采用了特殊的特征融合方式,将下采样(卷积)和上采样过程中的特征图在通道维度进行拼接实现特征融合。
U-Net的优势在于其能够结合底层和高层信息,增强了解码器恢复局部细节的能力,有效的捕获丰富的多尺度信息,减少信息的丢失。2. 模型与数据集分析
2.1 数据集分析
为了训练图像分割模型以检测图像中的汽车,我们首先需要对数据集有所了解。我们用于图像分割模型的数据集中包含
367张图像,并且每张图片都具有相应的包含对象蒙版的图像,此数据集中具有12个不同类别的对象,其中汽车蒙版的像素值为8。如下图所示为原始图像及其对应的汽车带有蒙版的标签图像。
该数据集可从以下链接下载:https://pan.baidu.com/s/18c-5hBjsmLGdRaBUizxeKg,提取码:
rh6p。2.2 模型分析
本节,我们将训练基于
U-Net架构的图像分割模型以检测图像中的汽车。在构建模型进行训练之前,我们首先对模型训练流程进行简要介绍:- 需要处理的数据集包括输入图像和图中对象带有蒙版的标签图像
- 将图像输入到预训练的
VGG16模型,以提取图像特征 - 逐步对获取的图像特征进行上采样,以获得形状为
224 x 224 x 1的输出图像 - 将卷积层与上采样层连接起来形成
U形连接 - 我们知道,卷积神经网络的低层输出包含的信息量更多,使用浅层特征重建图像会容易得多,如果我们通过对最后几层进行上采样来重建图像,很有可能会丢失图像的大部分信息,因此通过融合低层信息和高层信息能够更好的重建图像
- 构建并训练模型,将输入图像映射到标签图像的模型:
- 标签图像本质上是二进制图像,其中黑色值对应于像素值
0,而白色像素值为1 - 最小化尺寸为
224 x 224 x 1的真实标签图像与预测结果间的二进制交叉熵损失
- 标签图像本质上是二进制图像,其中黑色值对应于像素值
我们所采用的
U-Net模型架构如下图所示:
3. 使用 U-Net 架构进行图像分割
3.1 数据集读取
(1) 导入相关库,并将图像及其相应的蒙版图像读取为数组:
from glob import glob import os import numpy as np import matplotlib.pyplot as plt dir_data = 'dataset1' dir_seg = dir_data + '/annotations_prepped_train/' dir_img = dir_data + '/images_prepped_train/' all_img_paths = glob(os.path.join(dir_img, '*.png')) all_mask_paths = glob(os.path.join(dir_seg, '*.png'))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
(2) 创建输入和输出数组,并对输入数组进行了归一化。由于此数据集中具有
12个不同类别的对象,其中汽车蒙版的像素值为8,我们需要将汽车的蒙版与其他元素分开。import cv2 from scipy import ndimage from skimage import io x = [] y = [] for i in range(len(all_img_paths)): img = cv2.imread(all_img_paths[i]) img = cv2.resize(img, (224, 224)) # print(all_img_paths[i]) mask_path = dir_seg + all_img_paths[i].split('/')[-1] img_mask = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE) img_mask = cv2.resize(img_mask, (224, 224)) x.append(img) y.append(img_mask) x = np.array(x) y = np.array(y) y2 = np.where(y==8, 0, 1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
查看数据集,输入图像和蒙版图像的示例如下:
plt.subplot(221) plt.imshow(cv2.cvtColor(x[0], cv2.COLOR_BGR2RGB)) plt.title('Original image') plt.subplot(222) plt.imshow(y2[0], cmap='gray') plt.title('Masked image') plt.subplot(223) plt.imshow(cv2.cvtColor(x[2], cv2.COLOR_BGR2RGB)) plt.subplot(224) plt.imshow(y2[2], cmap='gray') plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
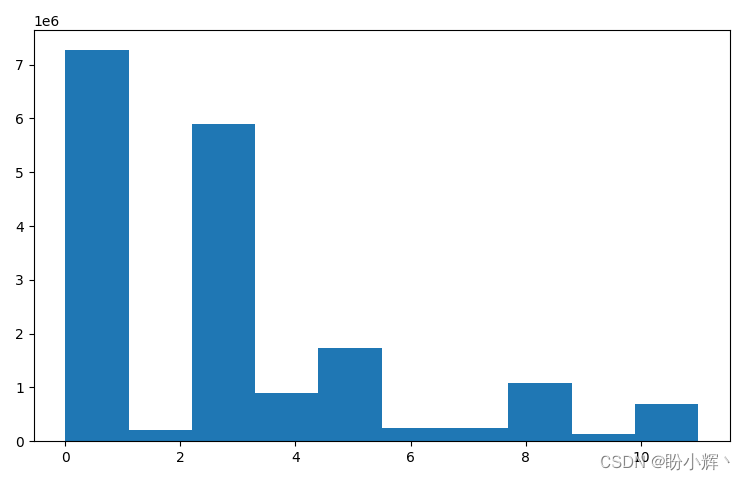
我们还可以对比蒙版分离前后的图像直方图:
plt.hist(y.flatten()) plt.show()- 1
- 2
plt.hist(y2.flatten()) plt.show()- 1
- 2

(3) 将输入和输出数组进行整形以便可以将其传递到神经网络中,并缩放输入数组:
x = x.reshape(-1, 224, 224, 3)/255. y2 = np.array(y2) y2 = y2.reshape(y2.shape[0],y2.shape[1],y2.shape[2],1)- 1
- 2
- 3
3.2 构建 U-Net 模型进行图像分割
(1) 构建模型,在该模型中,图像首先通过预训练的
VGG16模型,并提取卷积特征。
首先,导入所需库和预训练的VGG16模型:from keras.applications.vgg16 import VGG16 from keras.layers import Input, Conv2D, UpSampling2D, BatchNormalization from keras.applications.vgg16 import preprocess_input from keras.layers import concatenate, Dropout from keras.models import Model base_model = VGG16(input_shape=(224, 224, 3), include_top=False, weights='imagenet') base_model.trainable = False- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
然后,提取输入通过预训练的
VGG16模型时在各个卷积层中得到的图像特征:conv1 = Model(inputs=base_model.input,outputs=base_model.get_layer('block1_conv2').output).output conv2 = Model(inputs=base_model.input,outputs=base_model.get_layer('block2_conv2').output).output conv3 = Model(inputs=base_model.input,outputs=base_model.get_layer('block3_conv3').output).output conv4 = Model(inputs=base_model.input,outputs=base_model.get_layer('block4_conv3').output).output drop4 = Dropout(0.5)(conv4) conv5 = Model(inputs=base_model.input,outputs=base_model.get_layer('block5_conv3').output).output drop5 = Dropout(0.5)(conv5)- 1
- 2
- 3
- 4
- 5
- 6
- 7
(2) 使用上采样
UpSampling方法对图像特征进行放大,然后在每个上采样层中将计算结果与相同尺寸的VGG16卷积层特征进行串联(按通道进行连接,即在保持尺寸不变的情况下,增加通道的数量):up6 = Conv2D(512, 2, activation = 'relu', padding = 'same',kernel_initializer = 'he_normal')(UpSampling2D(size =(2,2))(drop5)) merge6 = concatenate([drop4,up6], axis = 3) conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same',kernel_initializer = 'he_normal')(merge6) conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same',kernel_initializer = 'he_normal')(conv6) conv6 = BatchNormalization()(conv6) up7 = Conv2D(256, 2, activation = 'relu', padding = 'same',kernel_initializer = 'he_normal')(UpSampling2D(size =(2,2))(conv6)) merge7 = concatenate([conv3,up7], axis = 3) conv7 = Conv2D(256, 3, activation = 'relu', padding = 'same',kernel_initializer = 'he_normal')(merge7) conv7 = Conv2D(256, 3, activation = 'relu', padding = 'same',kernel_initializer = 'he_normal')(conv7) conv7 = BatchNormalization()(conv7) up8 = Conv2D(128, 2, activation = 'relu', padding = 'same',kernel_initializer = 'he_normal')(UpSampling2D(size =(2,2))(conv7)) merge8 = concatenate([conv2,up8],axis = 3) conv8 = Conv2D(128, 3, activation = 'relu', padding = 'same',kernel_initializer = 'he_normal')(merge8) conv8 = Conv2D(128, 3, activation = 'relu', padding = 'same',kernel_initializer = 'he_normal')(conv8) conv8 = BatchNormalization()(conv8) up9 = Conv2D(64, 2, activation = 'relu', padding = 'same',kernel_initializer = 'he_normal')(UpSampling2D(size =(2,2))(conv8)) merge9 = concatenate([conv1,up9], axis = 3) conv9 = Conv2D(64, 3, activation = 'relu', padding = 'same',kernel_initializer = 'he_normal')(merge9) conv9 = Conv2D(64, 3, activation = 'relu', padding = 'same',kernel_initializer = 'he_normal')(conv9) conv9 = Conv2D(64, 3, activation = 'relu', padding = 'same',kernel_initializer = 'he_normal')(conv9) conv9 = BatchNormalization()(conv9) conv10 = Conv2D(1, 1, activation = 'sigmoid')(conv9)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
3.3 模型训练与测试
(1) 定义模型的输入和输出,首先将输入传递到
base_model,输出为conv10(形状为224 x 224 x 1):model = Model(inputs=base_model.input, outputs=conv10)- 1
(2) 冻结预训练的
VGG16模型的卷积层,即在模型训练过程中不改变VGG16模型的卷积层的权重:# 打印模型每一层的名字 for layer in model.layers: print(layer.name) for layer in model.layers[:18]: layer.trainable = False- 1
- 2
- 3
- 4
- 5
- 6
(3) 编译模型,并使用训练数据集拟合模型:
from keras import optimizers adam = optimizers.Adam(1e-3, decay = 1e-6) model.compile(loss='binary_crossentropy',optimizer=adam, metrics=['acc']) history = model.fit(x, y2, validation_split=0.1, batch_size=2, epochs=20, verbose=1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
模型训练过程中,在训练集和测试集上的损失值和准确率变化情况如下所示:

(4) 在测试图像上测试训练完成的模型,使用数据集的最后两张图像,它们在训练时并未使用:
y_pred = model.predict(x[-2:].reshape(2,224,224,3)) import matplotlib.pyplot as plt plt.subplot(231) plt.imshow(x[-1,:,:,::-1]) plt.title('Original image') plt.subplot(232) plt.imshow(y2[-1,:,:,0], cmap='gray') plt.title('Actual mask image') plt.subplot(233) plt.imshow(y_pred[-1,:,:,0], cmap='gray') plt.title('Predicted mask image') plt.subplot(234) plt.imshow(x[-2,:,:,::-1]) plt.subplot(235) plt.imshow(y2[-2,:,:,0], cmap='gray') plt.subplot(236) plt.imshow(y_pred[-2,:,:,0], cmap='gray') plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19

我们可以看到,对于给定的输入图像,生成的蒙版图像具有很高的可用性,并且在预测的蒙版图像中并不存在噪点。
小结
图像分割是是计算机视觉中一项基础的任务,已经广泛应用于许多实际场景中,也是计算机视觉领域十分具有挑战性的任务之一。本节中,我们首先介绍了图像分割的基本概念与主要类型。然后,我们训练一个基于
U-Net架构的图像分割模型,用于检测图像中的汽车,对于给定的输入图像,可以生成具有很高可用性的预测标签图像。系列链接
Keras深度学习实战(1)——神经网络基础与模型训练过程详解
Keras深度学习实战(2)——使用Keras构建神经网络
Keras深度学习实战(3)——神经网络性能优化技术
Keras深度学习实战(4)——深度学习中常用激活函数和损失函数详解
Keras深度学习实战(5)——批归一化详解
Keras深度学习实战(6)——深度学习过拟合问题及解决方法
Keras深度学习实战(7)——卷积神经网络详解与实现
Keras深度学习实战(8)——使用数据增强提高神经网络性能
Keras深度学习实战(9)——卷积神经网络的局限性
Keras深度学习实战(10)——迁移学习详解
Keras深度学习实战(11)——可视化神经网络中间层输出
Keras深度学习实战(12)——面部特征点检测
Keras深度学习实战(13)——目标检测基础详解
Keras深度学习实战(14)——从零开始实现R-CNN目标检测
Keras深度学习实战(15)——从零开始实现YOLO目标检测
Keras深度学习实战(16)——自编码器详解 -
相关阅读:
Spring 线程池的使用和配置
不就是Java吗之String类 PartI
试试用Markdown来设计表单
ARM day5
机器学习——神经网络、决策树(深度学习)
【JavaSE专栏25】进制转换的那些事,十进制转R进制、R进制转十进制是什么操作?
C++中的有参构造函数
【NR 定位】3GPP NR Positioning 5G定位标准解读(十五)-UL-TDOA 定位
React的高阶函数
如何阅读论文、文献的搜索与免费下载的一件套总结
- 原文地址:https://blog.csdn.net/LOVEmy134611/article/details/125837007


