-
从权限系统的菜单管理看算法和数据结构
菜单管理,感觉上是个小模块,但实际做下来的感触是,要做的好用,不容易。
算法和数据结构,长期活跃在面试题中,实际业务中好像接触的不多,但如果能用好,可以解决大问题。
如上图,是我在开源世界找到的一个菜单管理的设计页面,其上可以看到,菜单管理主要管理一颗菜单树,可以增删改查、排序等功能。接下来,我们就一步一步的实现菜单管理的各个功能,这里我主要介绍后端的设计方案,不涉及前端页面的处理和展示。
type IMenu interface { MenuList(ctx context.Context, platformId int, menuName string, status int) ([]*model.MenuListResp, response.Error) GetMenuInfo(ctx context.Context, menuId int) (*model.MenuInfo, response.Error) EditMenu(ctx context.Context, params *model.MenuEditParams) response.Error DeleteMenu(ctx context.Context, platformId, menuId int) response.Error AddMenu(ctx context.Context, params *model.MenuAddParams) response.Error MenuExport(ctx context.Context, platformId int) ([]byte, response.Error) MenuImport(ctx context.Context,platformId int,jsonData []byte) response.Error MenuSort(ctx context.Context, platformId int, tree []*model.MenuTree) response.Error }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
可以看到,菜单管理模块主要分三块,一是对菜单的增删改查、二是菜单的导入导出、三是菜单的排序。
由于菜单模块天然的就是一个树状结构,所以我就想到能不能在代码中用树作为处理菜单时的数据结构,把这个模块做完后,我发现这种思路是对的,可以解决菜单树的重排问题,无需在手动填写排序字段(就是人工为菜单的顺序赋值)。首先我们设计数据库,由于我们确认了以树处理菜单的思路,所以在表设计时,我把菜单信息和菜单树剥离,首先避免了字段过多,其次在用menu_id去获取单个菜单信息时,就完全不用遍历树了,直接从菜单信息表中拿数据,而且表分开后,代码逻辑也更清晰了。
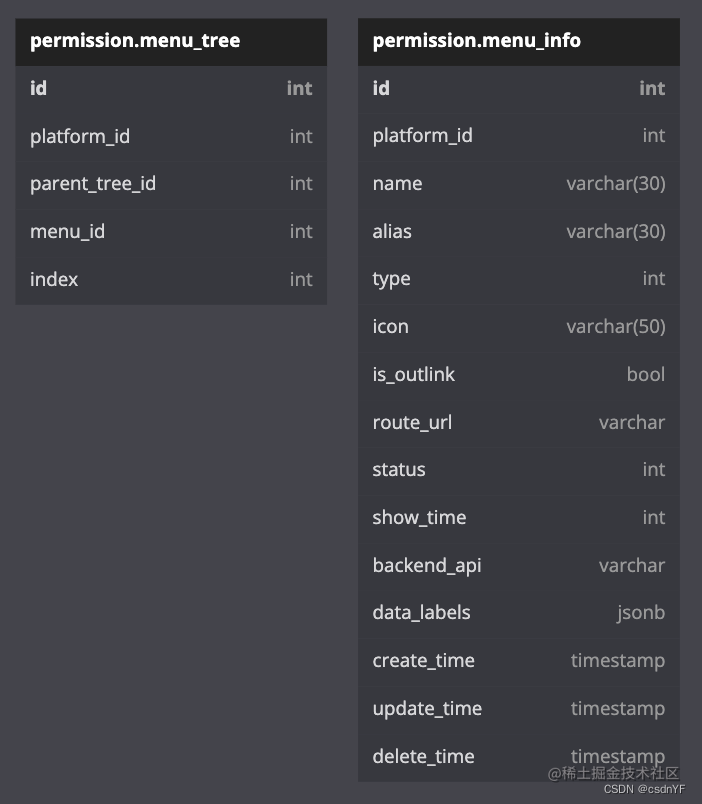
介绍一下表中的关键字段,其它字段可忽略:
表名 字段名 说明 menu_tree platform_id 这颗菜单树属于哪个业务系统 menu_tree parent_menu_id 节点的父节点id,没有父则为0 menu_tree menu_id 节点自己的id,就是 menu_info 表的主键 menu_tree index 排序字段 menu_info alias 菜单唯一标识 一、 添加菜单
添加菜单接口所需的信息如下:
type MenuAddParams struct { PlatformId int `json:"platform_id" v:"required"` // 平台ID Type int64 `json:"type" v:"required|in:1,2,3,4,5"` // 菜单类型 1菜单2子菜单3按钮4页签5数据标签 ParentMenuId int `json:"parent_menu_id"` // 上级菜单,没有则传0 // 菜单信息 Name string `json:"name" v:"required|length:3,20"` // 菜单名 ... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
添加菜单很简单,由于前端参数中已经存在父菜单id,我们只需要把这个菜单节点加到这个父菜单的子节点列表的末尾即可。
这里唯一需要注意的就是,我们需要
select MAX(index)获取父节点的子节点列表中index最大的值,然后+1作为新节点的index,这样就可以把新节点添加到列表末尾。但要注意并发问题,比如两个人同时添加菜单,有可能会导致index一样。解决方案就是把newIndex放到redis里,然后在添加时判断redis里的index是否>=数据库的maxIndex,理论上一定成立,不成立则说明newIndex还未写进db,流程图如下:
使用分布式锁,或者修改
select MAX(index)的事务隔离级别也可以实现。二、菜单列表
菜单列表与其说是列表,不如说是菜单树,树状返回整个菜单结构,不分页,两个原因:一、我们要在菜单列表上做拖曳排序,需要整个菜单树结构;二、菜单数据有它本身的特点,再多也就千级别顶天了,而且我们在数据存储时就区分了菜单树表(menu_tree)和(menu_info),这时获取菜单列表只需要访问 menu_tree,菜单信息可以懒加载,需要时再通过 menu_id 主键id获取,速度很快。
接口返回结构设计如下:
{ "data": { "children": [ { "children": [ { "children": [], "menu_id": 2, "name": "子菜单1", "type": 1 } ], "menu_id": 1, "name": "菜单1", "type": 1 } ], "menu_id": 0, "name": "", "type": 0 }, "errmsg": "", "errno": 0 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
我们用一个 menu_id 为0 的节点作为根节点,因为树需要一个唯一的根。
这里有人可能会说,不对啊,你 menu_tree 表里没有name和type,你不还是得去menu_info里获取吗?确实,实践中我确实有访问menu_info,但我感觉这两个字段其实可以冗余存储到 menu_tree中,这样优化后,就真的不用访问 menu_info了,只不过我模块已经写完了,就懒得改了,哈哈。这个数据返给前端,他直接渲染成树即可,点击树中某个节点,前端拿到这个节点的menu_id,去GetMenuInfo获取菜单信息,前面说过,这个获取很简单,就是主键id查找。
要建立这样一个返回结构,用如下关键代码实现即可:
type MenuTree struct { MenuId int `json:"menu_id"` // 菜单ID Name string `json:"name"` // 菜单名 Type int64 `json:"type"` // 菜单类型 1菜单2子菜单3按钮4页签5数据标签 Children []*MenuTree `json:"children"` // 子菜单 } func (s *sMenu) MenuTree(ctx context.Context, platformId int) (*model.MenuTree, error) { // 构造一个根节点 root := &model.MenuTree{} err := s.menuTreeChildren(ctx, root) if err != nil{ return nil, err } return root, nil } func (s *sMenu) menuTreeChildren(ctx context.Context, node *model.MenuTree) (error) { if node.MenuId != 0{ menuInfo, err := dao.MenuInfo.GetMenuInfo( ctx, node.MenuId, dao.MenuInfo.Columns().Id, dao.MenuInfo.Columns().Name, dao.MenuInfo.Columns().Type, ) if err != nil { return gerror.Wrap(err, "") } node.Name = menuInfo.Name node.Type = menuInfo.Type } // 获取子节点列表 // select * from menu_tree where platform_id = ? and parent_menu_id = ? childs, err := dao.MenuTree.GetMenuTreeChild(ctx, platformId, tree.MenuId) if err != nil { return gerror.Wrap(err, "") } treeChilds := make([]*model.MenuTree, len(childs)) for i, e := range childs { tree := &model.MenuTree{ MenuId: e.Id, } err := s.menuTreeChildren(ctx, platformId, tree) if err != nil{ return err } treeChilds[i] = tree } node.Children = treeChilds return nil }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
这个构造过程有没有一点点熟悉?这不就是树的dfs前序遍历算法的递归版本吗?
通过这种方式,我们把数据库中的树加载到内存中,后续的很多操作,都依赖对树的遍历实现。
三、编辑菜单、获取菜单信息
这两个操作都是只针对 menu_info 表的,用menu_id主键操作就行,没什么技术含量。
四、删除菜单
删除怎么实现呢?前面说过,后续的很多操作都是在对树进行遍历,那么删除也就很简单了,我们通过menuId确定要删除的节点,并遍历它的所有子节点,放到 treeIds 这个收集器中,当子节点遍历完毕时,把treeIds中收集的id取出来,去删除这条记录即可。
// menuIds 负责在遍历过程中收集所有的 menus_ids,treeIds 负责在遍历过程中收集 menu_tree表的主键 func (s *sMenu) deleteMenuTree(ctx context.Context, platformId, menuId int, menuIds []int, treeIds []int) ([]int, []int, error) { // 把menuId从菜单树中删除,并递归删除它的所有子菜单 child, err := dao.MenuTree.GetMenuTreeChild(ctx, platformId, menuId) if err != nil { return menuIds, treeIds, err } menuIds = append(menuIds, menuId) menuTree, err := dao.MenuTree.GetMenuTreeByMenuId(ctx, platformId, menuId, dao.MenuTree.Columns().Id) if err != nil { return menuIds, treeIds, err } treeIds = append(treeIds, int(menuTree.Id)) for _, e := range child { menuIds, treeIds, err = s.deleteMenuTree(ctx, platformId, int(e.MenuId), menuIds, treeIds) if err != nil { return menuIds, treeIds, err } } return menuIds, treeIds, nil }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
后续的删除代码就不再展示了,主键都收集完毕了,
DELETE FROM ... WHERE id IN ()一条语句搞定即可。五、菜单排序
来到本文的重点,菜单重排序,很多系统都是直接让用户填排序字段,非常容易出错,用过的人都知道,不太好用。我们直接来实现拖曳排序,而且可以任意拖曳,把节点拖到其它父节点,把节点拖到顶级菜单等,都可以实现。
首先前端同学需要实现拖曳组件,然后直接把拖曳后的整个菜单树回给我们即可,我们负责检查树的节点发生了什么变动。
前端同学也可以直接检测被拖曳的菜单id,和拖曳后的位置,把这些信息发给后端即可。不过为了让前端同学早点下班,这些活还是我们交给我们来干把。
我们现在拿到了前端发回的树结构,字段和数据跟我们通过菜单列表返回的json数据一致,只是其中有一个被拖曳的节点,不再原来的位置,它可能跟兄弟节点交换了顺序,可能变更了父节点,也可能变为顶级菜单。如何找到被拖曳的是哪个节点,并找到它拖曳后的位置和顺序呢?
在算法知识中,有一个很重要的思想,就是分治,当我们碰到比较复杂的问题时候,就一定要把它拆解为几个子问题解决,针对这个场景,我们可以拆分为以下几个问题:
- 如果被拖曳的节点变更了父节点,我们如何找到它的位置和顺序?
我们先序dfs遍历这个新的菜单树,每个节点都去数据库查询它的parent_menu_id,如果发现数据库的父节点id跟新菜单树的父节点id对不上,则可以断定这个节点是被拖曳过来的,同时也就知道了它的新位置和顺序。 - 如果被拖曳的节点未变更父节点,只是变更了顺序,我们如何找到它?
我们后序dfs遍历这个新菜单树,收集当前节点的子节点列表list1,并且从数据库中拉出当前节点的子节点列表list2,- 如果 list1.len < list2.len
说明这个节点有子节点被拖曳走了,我们不需要管这个节点,因为我们不关注被拖曳节点原先在哪儿。这个情况直接忽略即可 - 如果 list1.len > list2.len
说明有节点被拖曳进来,那我们遍历list1和list2找不同即可。 - 如果 list1.len == list2.len
也是遍历list1和list2,看看它们两是不是完全一样。
- 如果 list1.len < list2.len
- 找到被拖曳的节点以及它的新位置和顺序后,如何更新到数据库?
更新这个节点的父节点id,并要判断它的顺序- 它的新顺序就在父节点的子节点列表末尾
子节点列表(有序的)最后一个节点的index + 1即可 - 它在子节点列表的开头或者中间
它获得原节点的index,后续节点的index依次+1 - 原先就没有子节点,它是第一个
那它的index设为1即可
- 它的新顺序就在父节点的子节点列表末尾
具体的代码实现如下:
func (s *sMenu) MenuSort(ctx context.Context, platformId int, tree []*model.MenuTree) response.Error { s.lockSortMenu(ctx, platformId) defer s.unlockSortMenu(ctx, platformId) err = s.dfsTreeSort(ctx, platformId, &model.MenuTree{ Children: tree, }, 0) if err != nil && err != StopDFS { return nil, response.NewErrorAutoMsg( http.StatusServiceUnavailable, response.ServerError, ).WithErr(err) } return } var StopDFS = gerror.New("STOP") // 这个dfsTreeSort遍历时有个隐含条件,由于我们知道被拖曳的节点只有一个,所以我们找到这个节点后,马上就可以终止遍历 func (s *sMenu) dfsTreeSort(ctx context.Context, platformId int, node *model.MenuTree, parentTreeId int) error { if node == nil { return nil } childsMenus := make([]*model.MenuTree, 0) for i := 0; i < len(node.Children); i++ { n := node.Children[i] mt, err := dao.MenuTree.GetMenuTreeByMenuId(ctx, platformId, n.MenuId, dao.MenuTree.Columns().ParentTreeId) if err != nil { return err } if int(mt.PlatformId) != parentTreeId { // 发现被移动节点 err = s.swapTreeNode(ctx, platformId, n, parentTreeId, i) if err != nil { return err } return StopDFS // 终止遍历 } // 收集子菜单 childsMenus = append(childsMenus, n) err = s.dfsTreeSort(ctx, platformId, n, n.MenuId) if err != nil { return err } } // 判断子节点列表的顺序 if node.MenuId != 0 && len(childsMenus) > 0 { oldChilds, err := dao.MenuTree.GetMenuTreeChild(ctx, platformId, node.MenuId) if err != nil { return err } if len(childsMenus) < len(oldChilds) { // 这个情况不处理 return nil } for i := 0; i < len(childsMenus); i++ { if i < len(oldChilds) && childsMenus[i].MenuId != int(oldChilds[i].MenuId) { // 发现被移动节点 err = s.swapTreeNode(ctx, platformId, childsMenus[i], parentTreeId, i) if err != nil { return err } return StopDFS } } // 前面顺序如果都一样,那必然是最后一个节点新增的 if len(childsMenus) > len(oldChilds){ L := len(childsMenus) - 1 err = s.swapTreeNode(ctx, platformId, childsMenus[L], parentTreeId, L) if err != nil { return err } return StopDFS } } return nil } func (s *sMenu) swapTreeNode(ctx context.Context, platformId int, node *model.MenuTree, newParentMenuId int, index int) error { tx, err := g.DB().Begin(ctx) if err != nil { return gerror.Wrap(err, "") } ctx = context.WithValue(ctx, "tx", tx) childs, err := dao.MenuTree.GetMenuTreeChild(ctx, platformId, newParentMenuId) if err != nil { return err } var newIndex int64 = 1 if len(childs) == 0 { // 原先没有子节点 newIndex = 1 } if len(childs) != 0 && index > len(childs)-1 { // 在末尾 newIndex = childs[len(childs)-1].Index + 1 } if len(childs) != 0 { // 在中间 或者在开头 for i := index; i < len(childs); i++ { newIndex = childs[i].Index for j, e := range childs[i:] { fileds := make([]interface{}, 0) fileds = append(fileds, dao.MenuTree.Columns().Index) if int(e.MenuId) == node.MenuId{ // 不遍历到自己 continue } err = dao.MenuTree.EditMenuTree(ctx, &entity.MenuTree{ Id: e.Id, Index: newIndex + int64(j) + 1, }, fileds...) if err != nil { tx.Rollback() return err } } } } fileds := make([]interface{}, 0) fileds = append(fileds, dao.MenuTree.Columns().ParentTreeId) fileds = append(fileds, dao.MenuTree.Columns().Index) err = dao.MenuTree.EditMenuTreeByMenuId(ctx, &entity.MenuTree{ MenuId: int64(node.MenuId), PlatformId: int64(platformId), ParentTreeId: int64(newParentMenuId), Index: newIndex, }, fileds...) if err != nil { tx.Rollback() return err } tx.Commit() return nil }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
在菜单排序操作时,最好也加上分布式锁,菜单排序时禁止添加菜单、导入菜单等操作。
六、菜单导入、导出
菜单导入、导出在实践中也是非常有用的,常用的场景是:测试环境添加、更新、删除菜单后,想同步到正式环境,难道要再操作一遍吗?简单的办法就是导出测试环境的菜单,再导入到正式环境即可。
1. 菜单导出
既然已经获取到了菜单列表,那么把它导出成json文件也不是什么难事,这里的矛盾是,菜单列表里返回的菜单树信息是不全的,我们需要补充信息,导出一颗完整的菜单树:
type MenuExportTree struct { MenuInfo Children []*MenuExportTree `json:"children"` // 子菜单 } type MenuTree struct { MenuId int `json:"id"` // 菜单ID ParentMenuId int `json:"parent_id"` // 父菜单ID Name string `json:"name"` // 菜单名 Type int64 `json:"type"` // 菜单类型 1菜单2子菜单3按钮4页签5数据标签 Children []*MenuTree `json:"lists"` // 子菜单 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
菜单列表返回的字段是不全的,我们需要拿到 menu_info 表的所有字段,这里有两种思路,一种是仿照菜单列表的写法再写一遍,但是这次建立树节点时要获取下 menu_info 表的信息;另一种做法则是调用菜单列表获取到菜单树,然后做一个树克隆的算法,在克隆的过程中,把 menu_info 的信息写进去。
这里介绍第二种做法,原树的节点(MenuTree)克隆一个新树(MenuExportTree),这里我们为了
炫技复习基础,换用BFS来遍历树和克隆树。// BFS 树克隆,原树 node ,新树 newNode // BFS 遍历原树,在遍历过程中,建立新树节点 func (s *sMenu) bfsTreeCopy(node *model.MenuTree, newNode *model.MenuExportTree) { p := node if p == nil { return } q := newNode // isVisit是防止树中有回环指向,在菜单树中其实不存在回环,其实可以不要。 isVisit := make(map[*model.MenuTree]int) queueP := list.New() // P 原树队列 queueQ := list.New() // Q 新树队列 queueP.PushBack(p) queueQ.PushBack(q) for queueP.Len() != 0 { size := queueP.Len() for i := 0; i < size; i++ { e := queueP.Front() eq := queueQ.Front() p = e.Value.(*model.MenuTree) q = eq.Value.(*model.MenuExportTree) if _, ok := isVisit[p]; !ok { q.MenuId = p.MenuId q.Children = make([]*model.MenuExportTree, 0) if q.MenuId != 0 { // 获取 menu_info 表数据 menuInfo, _ := dao.MenuInfo.GetMenuInfo( context.Background(), q.MenuId, dao.MenuInfo.Columns().Status, dao.MenuInfo.Columns().Icon, dao.MenuInfo.Columns().CreateTime, ) q.MenuInfo = menuInfo } isVisit[p] = 1 } for _, child := range p.Children { queueP.PushBack(child) t := &model.MenuExportTree{} q.Children = append(q.Children, t) queueQ.PushBack(t) // 推一个空的新节点到queueQ,下次循环会为其赋值 } queueP.Remove(e) queueQ.Remove(eq) } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
BFS 比较擅长处理需要针对每层节点进行操作的情况, DFS则可以在遍历时方便的获取到父节点的id,大部分时候我们选择一种遍历算法使用即可。
2. 菜单导入
导入则比较简单了,这里的导入是指我们用导入数据覆盖原数据,比较简单。如果要支持导入部分树节点,则可能比较麻烦,不能用 menu_id 数据库主键作为菜单唯一标识了,因为不同环境的主键不同。需要为菜单生成唯一标识,比如 menu_key 之类的字段,然后用它作为导入时定位菜单的依据。
所以不如简单点,导入就是用导入的数据覆盖原来数据,步骤就是,删除原来的菜单树,然后建立一颗新的菜单树。
// 根据 MenuExportTree 建立一个新的菜单树写入数据库中 func (s *sMenu) dfsTreeImport(ctx context.Context, tx *gdb.TX, root *model.MenuExportTree, parentMenuId int, index int) error { if root == nil { return nil } menuId := 0 // 前序遍历,写入 menu_info 表 if len(root.Name) != 0 { menuInfo := &entity.MenuInfo{ PlatformId: int64(root.PlatformId), Name: root.Name, Type: root.Type, Icon: root.Icon, IsOutlink: root.IsOutLink, RouteUrl: root.RouteData, Status: root.Status, ShowTime: root.Showtime, BackendApi: root.BackendApi, DataLabels: gjson.New(root.DataLabels.Data), } err := dao.MenuInfo.AddMenuInfoReturnId(ctx, menuInfo) if err != nil { _ = tx.Rollback() return gerror.Wrap(err, "") } menuId = int(menuInfo.Id) } for i := 0; i < len(root.Children); i++ { n := root.Children[i] err := s.dfsTreeImport(ctx, tx, n, menuId, i+1) if err != nil { _ = tx.Rollback() return err } } // 当遍历完这个节点的子节点后,把这个节点写入 menu_tree if len(root.Name) != 0 { tree := &entity.MenuTree{ PlatformId: int64(root.PlatformId), ParentTreeId: int64(parentMenuId), MenuId: int64(menuId), Index: int64(index), } err := dao.MenuTree.AddMenuTree(ctx, tree) if err != nil { _ = tx.Rollback() return err } } return nil }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
七、参考文献
- LeetCode
- https://gitee.com/fe.zookeeper/wx-api (图源)
- 代码风格(GoFrameV2)
-
相关阅读:
Leetcode978. Longest Turbulent Subarray
《蛤蟆先生去看心里医生》阅读笔记
9 个 yyds 的 Java 项目,可应对各种私活
Android进阶笔记-7. Context详解
mysql出现提示错误10061的解决方法
千万级大型API网关设计
Vue - 判断访问网页客户端设备是手机移动端还是 PC 电脑端(判断设备类型是否是移动端手机)
模仿快猫猫App实现的微信小程序,前端页面基本完成
SSIM公式:结构相似性计算原理,基于SSIM的图像质量评价
数据分享|R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病...
- 原文地址:https://blog.csdn.net/csdnYF/article/details/126247187

