-
内核网络接口层的实现
主要参考了《深入linux内核架构》和《精通Linux内核网络》相关章节
网络接口层
网络访问层。该层主要负责在计算机之间传输信息,与网卡的设备驱动程序直接协作。
网络设备的表示net_device
前面讲述了Linux内核中网络子系统的结构,现在我们把注意力转向网络实现的第一层,即网络访问层(主机到网络层 / 数据链路层)。该层主要负责在计算机之间传输信息,与网卡的设备驱动程序直接协作。
在内核中,每个网络设备都表示为net_device结构的一个实例。在分配并填充该结构的一个实例之后,必须用net/core/dev.c中的register_netdev函数将其注册到内核。该函数完成一些初始化任务,并将该设备注册到通用设备机制内。这会创建一个sysfs项(参见10.3节)/sys/class/net/
,关联到该设备对应的目录。如果系统包含一个PCI网卡和一个环回接口设备,则在/sys/class/net中有两个对应项: root@meitner # ls -l /sys/class/net total 0 lrwxrwxrwx 1 root root 0 2008-03-09 09:43 eth0 -> ../../devices/pci0000:00/0000:00:1c.5/ 0000:02:00.0/net/eth0 lrwxrwxrwx 1 root root 0 2008-03-09 09:42 lo -> ../../devices/virtual/net/lo- 1
- 2
- 3
- 4
- 5
在详细讨论struct net_device的内容之前,先阐述一下内核如何跟踪可用的网络设备,以及如何查找特定的网络设备。照例,这些设备不是全局的,而是按命名空间进行管理的。回想一下,每个命名空间(net实例)中有如下3个机制可用。
- 所有的网络设备都保存在一个单链表中,表头为dev_base。
- 按设备名散列。辅助函数dev_get_by_name(struct net * net, const char * name)根据设备名在该散列表上查找网络设备。
- 按接口索引散列。辅助函数dev_get_by_index(struct net * net, int ifindex)根据给定的接口索引查找net_device实例。
net_device结构包含了与特定设备相关的所有信息。该结构的定义有200多行代码,是内核中最庞大的结构。
net_device结构体存储着网络设备的所有信息,每个设备都有这种结构。所有设备的net_device结构放在一个全局变量dev_base所有全局列表中。和sk_buff一样,整体结构相当庞大的。结构体中有一个next指针,用来连接系统中所有网络设备。内核把这些连接起来的设备组成一个链表,并由全局变量dev_base指向链表的第一个元素。
网络设备net_device结构体包含主要设备参数
- 设备的IRQ号、设备的MTU、设备的MAC地址、设备的名称(eth1,eth0)、设备的标志(up,down)、与设备相关联的组播地址清单、设备支持的功能、网络设备回调函数的对象(net_device_ops)、设备最后一次发送数据包的时间戳、设备最后一次接收数据包的时间戳。
数据结构
include\linux\netdevice.h
struct net_device - The DEVICE structure.
Actually, this whole structure is a big mistake. It mixes I/O data with strictly “high-level” data, and it has to know about almost every data structure used in the INET module.struct net_device { char name[IFNAMSIZ]; struct hlist_node name_hlist; /* 设备名散列链表的链表元素 */ char *ifalias; // SNMP(简单网络管理协议) 别名 /* I/O相关字段 */ unsigned long mem_end; /* 共享内存结束位置 */ unsigned long mem_start; /* 共享内存起始位置 */ unsigned long base_addr; /* 设备I/O地址 */ unsigned int irq; /* 设备IRQ编号 */ atomic_t carrier_changes; unsigned long state; struct list_head dev_list; // The global list of network devices struct list_head napi_list; // List entry used for polling NAPI devices struct list_head unreg_list; struct list_head close_list; struct list_head ptype_all; struct list_head ptype_specific; struct { struct list_head upper; struct list_head lower; } adj_list; // Directly linked devices, like slaves for bonding netdev_features_t features; // 当前活跃的设备功能 netdev_features_t hw_features; // User-changeable features netdev_features_t wanted_features; // User-requested features netdev_features_t vlan_features; // VLAN 设备可继承的特性掩码 /* 封装设备继承的特征掩码,该字段指示硬件能够执行的封装卸载,驱动程序需要适当地设置它们。*/ netdev_features_t hw_enc_features; netdev_features_t mpls_features; netdev_features_t gso_partial_features; int ifindex; /* 接口索引。唯一的设备标识符*/ int group; struct net_device_stats stats; atomic_long_t rx_dropped; atomic_long_t tx_dropped; atomic_long_t rx_nohandler; #ifdef CONFIG_WIRELESS_EXT const struct iw_handler_def *wireless_handlers; struct iw_public_data *wireless_data; #endif const struct net_device_ops *netdev_ops; const struct ethtool_ops *ethtool_ops; #ifdef CONFIG_NET_SWITCHDEV const struct switchdev_ops *switchdev_ops; #endif #ifdef CONFIG_NET_L3_MASTER_DEV const struct l3mdev_ops *l3mdev_ops; #endif #if IS_ENABLED(CONFIG_IPV6) const struct ndisc_ops *ndisc_ops; #endif #ifdef CONFIG_XFRM const struct xfrmdev_ops *xfrmdev_ops; #endif const struct header_ops *header_ops; unsigned int flags; unsigned int priv_flags; unsigned short gflags; unsigned short padded; unsigned char operstate; unsigned char link_mode; unsigned char if_port; unsigned char dma; unsigned int mtu; // 网络设备接口的最大传输单元 unsigned int min_mtu; unsigned int max_mtu; unsigned short type; // 接口硬件类型 unsigned short hard_header_len; // 硬件接口头长度,最大硬件首部长度 unsigned char min_header_len; // 最小硬件首部长度 unsigned short needed_headroom; unsigned short needed_tailroom; /* Interface address info. */ unsigned char perm_addr[MAX_ADDR_LEN]; unsigned char addr_assign_type; unsigned char addr_len; unsigned short neigh_priv_len; unsigned short dev_id; unsigned short dev_port; spinlock_t addr_list_lock; unsigned char name_assign_type; bool uc_promisc; // 网络设备单播模式 struct netdev_hw_addr_list uc; struct netdev_hw_addr_list mc; struct netdev_hw_addr_list dev_addrs; #ifdef CONFIG_SYSFS struct kset *queues_kset; #endif unsigned int promiscuity; // 网络设备混杂模式 unsigned int allmulti; // 网络设备全组播模式 ... /* * Cache lines mostly used on receive path (including eth_type_trans()) */ /* Interface address info used in eth_type_trans() */ unsigned char *dev_addr; // 网络设备接口的MAC地址 ... unsigned char broadcast[MAX_ADDR_LEN]; // 硬件多播地址 ...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
网络设备的注册
注册网络设备
每个网络设备都按照如下过程注册。(1) alloc_netdev分配一个新的struct net_device实例,一个特定于协议的函数用典型值填充该结构。对于以太网设备,该函数是ether_setup。其他的协议(这里不详细介绍)会使用形如XXX_setup的函数,其中XXX可以是fddi(fiber distributed data interface,光纤分布式数据接口)、tr(token ring,令牌环网)、ltalk(指Apple LocalTalk)、hippi(high-performance parallel interface,高
性能并行接口)或fc(fiber channel,光纤通道)。内核中的一些伪设备在不绑定到硬件的情况下实现了特定的接口,它们也使用了net_device框架。例如,ppp_setup根据PPP协议初始化设备。内核源代码中还可以找到几个XXX_setup函数。
(2) 在struct net_device填充完毕后,需要用register_netdev或register_netdevice注册。这 两 个 函 数 的 区 别 在 于 , register_netdev 可处理用作接口名称的格式串 (有限)。 在net_device->dev中给出的名称可以包含格式说明符%d。在设备注册时,内核会选择一个唯一的数字来代替%d。例如,以太网设备可以指定eth%d,而内核随后会创建设备eth0、eth1……
便 捷 函 数 alloc_etherdev(sizeof_priv) 分 配 一 个 struct net_device 实 例 , 外 加sizeof_priv字节私有数据区。回想前文可知,net_device->priv是一个指针,指向与设备相关联的特定于驱动程序的数据。此外,还调用了上面提到的ether_setup来设置特定于以太网的标准值。
linux2.x版本

如果net_device->init提供了特定于设备的初始化函数,那么内核在进一步处理之前,将先调用该函数。由dev_new_index生成在所属命名空间中唯一标识该设备的接口索引。该索引保存在net_device->ifindex中。在确保所选择的名称尚未使用,而且没有指定自相矛盾的设备特性(所支持特性的列表,请参见
中的NETIF_F_*)后,用netdev_register_kobject将新设备添加到通用内核对象模型中。该函数还会创建上文提到的sysfs项。最后,该设备集成到特定命名空间的链表中,以及以设备名和接口索引为散列键的两个散列表中。 接收分组
分组到达内核的时间是不可预测的。所有现代的设备驱动程序都使用中断来通知内核(或系统)有分组到达。网络驱动程序对特定于设备的中断设置了一个处理例程,因此每当该中断被引发时(即分组到达),内核都调用该处理程序,将数据从网卡传输到物理内存,或通知内核在一定时间后进行处理。
几乎所有的网卡都支持DMA模式,能够自行将数据传输到物理内存。但这些数据仍然需要解释和处理,这在稍后进行。传统方法(旧式)
当前,内核为分组的接收提供了两个框架。其中一个很早以前就集成到内核中了,因而称为传统方法。但与超高速网络适配器协作时,该API会出现问题,因而网络子系统的开发者已经设计了一种新的API(通常称为NAPI)。我们首先从传统方法开始,因为它比较易于理解。另外,使用旧API的适配器较多,而使用新API的较少。这没有问题,因为其物理传输速度没那么高,不需要新方法。NAPI在稍后讨论。
硬中断
下图给出了在一个分组到达网络适配器之后,该分组穿过内核到达网络层函数的路径。
下面忽略DMA

因为分组是在中断上下文中接收到的,所以处理例程只能执行一些基本的任务,避免系统(或当前CPU)的其他任务延迟太长时间。
在中断上下文中,数据由3个短函数处理,执行了下列任务。
- **net_interrupt是由设备驱动程序设置的中断处理程序。**它将确定该中断是否真的是由接收到的分组引发的(也存在其他的可能性,例如,报告错误或确认某些适配器执行的传输任务)。如果确实如此,则控制将转移到net_rx。
- **net_rx函数也是特定于网卡的,首先创建一个新的套接字缓冲区。**分组的内容接下来从网卡传输到缓冲区(也就是进入了物理内存),然后使用内核源代码中针对各种传输类型的库函数来分析首部数据。这项分析将确定分组数据所使用的网络层协议,例如IP协议。
- 与上述两个方法不同,netif_rx函数不是特定于网络驱动程序的,该函数位于net/core/dev.c。调用该函数,标志着控制由特定于网卡的代码转移到了网络层的通用接口部分。
该函数的作用在于,将接收到的分组放置到一个特定于CPU的等待队列上,并退出中断上下文,使得CPU可以执行其他任务。
内 核 在 全 局 定 义 的 softnet_data 数 组 中 管 理 进 出 分 组 的 等 待 队 列 , 数 组 项 类 型 为softnet_data。**为提高多处理器系统的性能,对每个CPU都会创建等待队列,支持分组的并行处理。不心使用显式的锁机制来保护等待队列免受并发访问,因为每个CPU都只修改自身的队列,不会干扰其他CPU的工作。**下文将忽略多处理器相关内容,只考虑单“softnet_data等待队列”,避免过度复杂化。
struct softnet_data { ... struct sk_buff_head input_pkt_queue; ... };- 1
- 2
- 3
- 4
- 5
- 6
软中断
input_pkt_queue使用上文提到的sk_buff_head表头,对所有进入的分组建立一个链表。 netif_rx在结束工作之前将软中断NET_RX_SOFTIRQ标记为即将执行,然后退出中断上下文。
net_rx_action用作该软中断的处理程序。其代码流程图在下图给出。请记住,这里描述的是一个简化的版本。完整版包含了对高速网络适配器引入的新方法,将在下文介绍。
在一些准备任务之后,工作转移到process_backlog,该函数在循环中执行下列步骤。为简化描述,假定循环一直进行,直至所有的待决分组都处理完成,不会被其他情况中断。
(1) __skb_dequeue从等待队列移除一个套接字缓冲区,该缓冲区管理着一个接收到的分组。
(2) ==由netif_receive_skb函数分析分组类型,以便根据分组类型将分组传递给网络层的接收函数(即传递到网络系统的更高一层)。==为此,该函数遍历所有可能负责当前分组类型的所有网络层函数,一一调用deliver_skb。
接下来deliver_skb函数使用一个特定于分组类型的处理程序func,承担对分组的更高层(例如互联网络层)的处理。
netif_receive_skb也处理诸如桥接之类的专门特性,但讨论这些边角情况是不必要的,至少在平均水准的系统中,此类特性都属于边缘情况。
所有用于从底层的网络访问层接收数据的网络层函数都注册在一个散列表中,通过全局数组ptype_base实现。
新的协议通过dev_add_pack增加。各个数组项的类型为struct packet_type,定义如下:struct packet_type { __be16 type; /* 这实际上是htons(ether_type)的值。 */ struct net_device *dev;/* NULL在这里表示通配符 */ int (*func) (struct sk_buff *, struct net_device *, struct packet_type *, struct net_device *); ... void *af_packet_priv; struct list_head list; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
type指定了协议的标识符,处理程序会使用该标识符。dev将一个协议处理程序绑定到特定的网卡(NULL指针表示该处理程序对系统中所有网络设备都有效)。
func是该结构的主要成员。它是一个指向网络层函数的指针,如果分组的类型适当,将其传递给该函数。其中一个处理程序就是ip_rcv,用于基于IPv4的协议,在下文讨论。
netif_receive_skb对给定的套接字缓冲区查找适当的处理程序,并调用其func函数,将处理分组的职责委托给网络层,这是网络实现中更高的一层。NAPI —— 禁用中断 与 轮询
如果设备不支持过高的传输率,那么此前讨论的旧式方法可以很好地将分组从网络设备传输到内核的更高层。每次一个以太网帧到达时,都使用一个IRQ来通知内核。这里暗含着“快”和“慢”的概念。 对低速设备来说,在下一个分组到达之前,IRQ的处理通常已经结束。由于下一个分组也通过IRQ通知,如果前一个分组的IRQ尚未处理完成,则会导致问题,高速设备通常就是这样。现代以太网卡的运作高达10 000 Mbit/s,如果使用旧式方法来驱动此类设备,将造成所谓的“中断风暴”。如果在分组等待处理时接收到新的IRQ,内核不会收到新的信息:在分组进入处理过程之前,内核是可以接收IRQ的,在分组的处理结束后,内核也可以接收IRQ,这些不过是“旧闻”而已。为解决该问题,NAPI使用了IRQ和轮询的组合。
当前,几乎所有Linux网络设备驱动程序都支持该技术。NAPI是在2.5/2.6内核中首次引入的,并向后移植到了2.4.20内核。采用NAPI技术时,如果负载很高,网络设备驱动程序将在轮询模式,而不是中断驱动模式下运行。**这意味着,不会在每次接收数据包时都触发中断。相反,驱动程序会将数据包存储在缓冲区,由内核不时地向驱动程序轮询,以取回数据包。**采用NAPI技术,可提高设备在高负载下的性能。从内核3.11起,Linux新增了频繁轮询套接字(Busy Polling on Sockets )的功能,用于那些不惜以提高CPU使用率为代价而尽可能降低延迟的套接字应用程序。
NAPI的另一个优点是可以高效地丢弃分组。如果内核确信因为有很多其他工作需要处理,而导致无法处理任何新的分组,那么网络适配器(网卡)可以直接丢弃分组,无须复制到内核。
只有设备满足如下两个条件时,才能实现NAPI方法。
(1) 设备必须能够保留多个接收的分组,例如保存到DMA环形缓冲区中。下文将该缓冲区称为Rx缓冲区。
(2) 该设备必须能够**禁用用于分组接收的IRQ**。而且,发送分组或其他可能通过IRQ进行的操作,都仍然必须是启用的。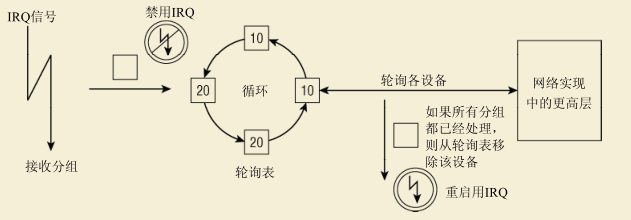
与普通轮询的区别
- NAPI轮询的目的是**不停处理分组,处理完或一定规则下(见后文)就立马停止轮询(无额外消耗CPU,避免了频繁的中断)**
- 普通轮询的是不停轮询直到有分组到来**(空耗CPU)**
细节如下
假定某个网络适配器此前没有分组到达,但从现在开始,分组将以高频率频繁到达。这就是NAPI设备的情况,如下所述。
- (1) 第一个分组将导致网络适配器发出IRQ。为防止进一步的分组导致发出更多的IRQ,驱动程序会关闭该适配器的Rx IRQ(关闭硬中断)。并将该适配器放置到一个轮询表上。
- (2) 只要适配器上还有分组需要处理,内核就一直对轮询表上的设备进行轮询。
- (3) 重新启用Rx中断。 (开启硬中断)
如果在新的分组到达时,旧的分组仍然处于处理过程中,工作不会因额外的中断而减速。**虽然对设备驱动程序(和一般意义上的内核代码)来说轮询通常是一个很差的方法,但在这里该方法没有什么不利之处:在没有分组还需要处理时,将停止轮询,设备将回复到通常的IRQ驱动的运行方式。**在没有中断支持的情况下,轮询空的接收队列将不必要地浪费时间,但NAPI并非如此。
对高速接口的支持(NAPI)具体实现
内核以循环方式处理链表上的所有设备:内核依次轮询各个设备,如果已经花费了一定的时间来处理某个设备,则选择下一个设备进行处理。此外,某个设备都带有一个相对权重,表示与轮询表中其他设备相比,该设备的相对重要性。较快的设备权重较大,较慢的设备权重较小。由于权重指定了在一个轮询的循环中处理多少分组,这确保了内核将更多地注意速度较快的设备。
与旧的API相比,关键性的变化在于,支持NAPI的设备必须提供一个poll函数。该方法是特定于设备的,在用netif_napi_add注册网卡时指定。调用该函数注册,表明设备可以且必须用新方法处理。
static inline void netif_napi_add(struct net_device *dev, struct napi_struct *napi, int (*poll)(struct napi_struct *, int), int weight);- 1
- 2
- 3
- 4
dev指向所述设备的net_device实例,poll指定了在IRQ禁用时用来轮询设备的函数,weight指定了设备接口的相对权重。
- 实际上可以对weight指定任意整数值。通常10/100 Mbit网卡的驱动程序指定为16,而1 000/10 000 Mbit网卡的驱动程序指定为64。无论如何,权重都不能超过该设备可以在Rx缓冲区中存储的分组的数目。
netif_napi_add还需要另一个参数,是一个指向struct napi_struct实例的指针。该结构用于管理轮询表上的设备。其定义如下
struct napi_struct { struct list_head poll_list; unsigned long state; int weight; int (*poll)(struct napi_struct *, int); };- 1
- 2
- 3
- 4
- 5
- 6
轮询表通过一个标准的内核双链表实现,poll_list用作链表元素。weight和poll的语义同上文所述。
- state可以是NAPI_STATE_SCHED或NAPI_STATE_DISABLE,前者表示设备将在内核的下一次循环时被轮询,后者表示轮询已经结束且没有更多的分组等待处理,但设备尚未从轮询表移除。
请注意,struct napi_struct经常嵌入到一个更大的结构中,后者包含了与网卡有关的、特定于驱动程序的数据。这样在内核使用poll函数轮询网卡时,可用container_of机制获得相关信息。
实现NAPI设备的poll函数(获取分组并传递到高层)
poll函数需要两个参数:一个指向napi_struct实例的指针和一个指定了“预算”的整数,预算表示内核允许驱动程序处理的分组数目。
我们并不打算处理真实网卡的可能的奇异之处,因此讨论一个伪函数,该函数用于一个需要NAPI的超高速适配器:
static int hyper_card_poll(struct napi_struct *napi, int budget) { struct nic *nic = container_of(napi, struct nic, napi); struct net_device *netdev = nic->netdev; int work_done; work_done = hyper_do_poll(nic, budget); if (work_done < budget) { netif_rx_complete(netdev, napi); hcard_reenable_irq(nic); } return work_done; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
从napi_struct的容器获得特定于设备的信息之后,调用一个特定于硬件的方法(这里是hyper_do_poll)来执行所需要的底层操作从网络适配器获取分组,并使用像此前那样使用netif_receive_skb将分组传递到网络实现中更高的层。
hyper_do_poll最多允许处理budget个分组。该函数返回实际上处理的分组的数目。必须区分以下两种情况。
- 如果处理分组的数目小于预算,那么没有更多的分组,Rx缓冲区为空,否则,肯定还需要处理剩余的分组(亦即,返回值不可能小于预算)。
- 因此,netif_rx_complete将该情况通知内核,内核将从轮询表移除该设备。
- 接下来,驱动程序必须通过特定于硬件的适当方法来重新启用IRQ。
- 已经完全用掉了预算,但仍然有更多的分组需要处理。设备仍然留在轮询表上,不启用中断。
实现IRQ处理程序(硬中断)
NAPI也需要对网络设备的IRQ处理程序做一些改动。这里仍然不求助于任何具体的硬件,
而介绍针对虚构设备的代码:static irqreturn_t e100_intr(int irq, void *dev_id) { struct net_device *netdev = dev_id; struct nic *nic = netdev_priv(netdev); if(likely(netif_rx_schedule_prep(netdev, &nic->napi))) { hcard_disable_irq(nic); __netif_rx_schedule(netdev, &nic->napi); } return IRQ_HANDLED; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
假定特定于接口的数据保存在net_device->private中,这是大多数网卡驱动程序使用的方法。
使用辅助函数netdev_priv访问该字段。
现在需要通知内核有新的分组可用。这需要如下二阶段的方法。
- (1) netif_rx_schedule_prep准备将设备放置到轮询表上。本质上,这会安置napi_struct->flags中的NAPI_STATE_SCHED标志。
- (2) 如果设置该标志成功(仅当NAPI已经处于活跃状态时,才会失败),驱动程序必须用特定于设备的适当方法来禁用相应的IRQ。调用__netif_rx_schedule将**设备的napi_struct添加到轮询表,并引发软中断NET_RX_SOFTIRQ。**这通知内核在net_rx_action中开始轮询。
处理Rx软中断
在讨论了为支持NAPI驱动程序需要做哪些改动之后,我们来考察一下内核需要承担的职责。
net_rx_action依旧是软中断NET_RX_SOFTIRQ的处理程序。在前一节给出了该函数的一个简化版本。随着有关NAPI的更多细节尘埃落定,现在可以讨论该函数的所有细节了。图12-13给出了其代码流程图。

本质上,内核通过依次调用各个设备特定的poll方法,处理轮询表上当前的所有设备。
设备的权重用作该设备本身的预算,即轮询的一步中可能处理的分组数目。必须确保在这个软中断的处理程序中,不会花费过多时间。如果如下两个条件成立,则放弃处理。
-
(1) 处理程序已经花费了超出一个jiffie的时间。
jiffies记录了系统启动以来,经过了多少tick。
一个tick代表多长时间(取决于设备的频率),在内核的CONFIG_HZ中定义。比如CONFIG_HZ=200,则一个jiffies对应5ms时间。所以内核基于jiffies的定时器精度也是5ms。
-
(2) 所处理分组的总数,已经超过了netdev_budget指定的预算总值。通常,总值设置为300,但可以通过/proc/sys/net/core/netdev_budget修改。
这个预算不能与各个网络设备本身的预算混淆!
在每个轮询步之后,都从全局预算中减去处理的分组数目,如果该预算值下降到0,则退出软中断处理程序。在轮询了一个设备之后,内核会检查所处理的分组数目,与该设备的预算是否相等。
如果相等,那么尚未获得该设备上所有等待的分组,即代码流程图中work == weight所表示的情况。内核接下来将该设备移动到轮询表末尾,在链表中所有其他设备都处理过之后,继续轮询该设备。显然,这实现了网络设备之间的循环调度。在NAPI之上实现旧式API
最后,请注意旧的API是如何在NAPI上实现的。
内核的常规行为,由一个与softnet队列关联的伪网络设备控制,net/core/dev.c中的process_backlog标准函数用作poll方法。
如果没有网络适配器将其自身添加到该队列的轮询表,其中只包含这个伪适配器,那么net_rx_action的行为就是通过对process_backlog的单一调用来处理队列中的分组,而不管分组的来源设备。
频繁轮询套接字 Busy Polling on Sockets
套接字队列变空后,网络栈的传统工作方式如下:要么进入休眠状态,等待驱动程序将其他数据加入套接字队列,要么返回(如果它是以非阻断方式运行的)。由于中断和上下文切换,使得延迟增加了。对于愿意以CPU使用率更高换取延迟尽可能低的套接字应用程序,Linux从内核3.11起为其提供了频繁轮询套接字的功能(这种技术最初命名为低延迟套接字轮询,根据Linus的建议而更名为频繁轮询套接字)。==在将数据移交给应用程序方面,频繁轮询采用了更激进的方式。当应用程序请求更多数据,而套接字队列中没有时,网络栈将主动询问设备驱动程序。驱动程序检查新到达的数据,并经网络层(L3)将其交给套接字。==驱动程序可能会发现有其他套接字的数据,进而将这些数据也交给相应的套接字。当轮询调用返回到网络栈时,套接字代码将检查套接字接收队列中是否有未处理的新数据。
要支持频繁轮询,网络驱动程序必须提供频繁轮询方法,并将其作为net_device_ops对象的ndo_busy_poll回调函数。这个驱动程序的ndo_busy_poll回调函数必须将数据包移到网络栈,请参阅方法 ixgbe_low_latency_recv() (rivers/net/ethernet/intelixgbe/ixgbe_main.c )。这个ndo_busy_poll回调函数还必须返回已移到网络栈的数据包数。如果没有将任何数据包移到网络栈,就返回0;如果出现了问题,则返回LL_FLUSH_FAILED或LL_FLUSH_BUSY。如果驱动程序没有设置ndo_busy_poll回调函数,将按正常情况工作,而不会顿繁地轮询它。
网络设备驱动程序的主要任务如下:
接收目的地为当前主机的数据包,并将其传递给网络层(L3 ),之后再将其传递给传输层( L4)。
传输当前主机生成的外出数据包或转发当前主机收到的数据包。对于每个数据包,无论它是接收到的还是发送出去的,都需要在路由子系统中执行一次查找操作。根据路由子系统的查找结果,决定是否应对数据包进行转发以及该从哪个接口发送出去。传输当前主机生成的外出数据包或转发当前主机收到的数据包。
提供低延迟的一个重要组件是频繁轮询。有时候,当驱动程序轮询方法无功而返时,刚好会有新数据到达。这些数据会与返回到网络栈的机会失之交臂。这正是频繁轮询的用武之地。网络栈以可配置的时间间隔轮询驱动程序,从而在新数据包到达后立即获取它们。
支持主动、频繁轮询的设备驱动程序可将延迟降低到接近于硬件延迟。可将频繁轮询同时用于大量套接字,但这无法获得最佳效果。因为在一些套接字上使用频繁轮询时,将降低其他使用相同CPU核心的套接字的速度。图14-1对传统接收流程与启用了频繁轮询的套接字的接收流程进行了比较,其中不断重复的步骤如下。

对特定套接字启用
一种启用频繁轮询的更佳方式是,修改应用程序,使用套接字选项SO_BUSY_POLL,这将设置套接字对象(sock结构实例)的sk_ll_usec。
通过使用这个套接字选项,应用程序可指定要启用频繁轮询的套接字,确保只有这些套接字的CPU使用率更高。其他应用程序和服务中的套接字将继续使用传统接收流程。
推荐将SO_BUSY_POLL的初始值设置为50。sysctl.net.busy_read必须设置为0,而sysctl.net.busy_poll必须根据Documentation/sysctVnet.txt的描述设置。
调整和配置
调整和配置频繁轮询套接字的方式有多种。
- 为降低中断频率,应将网络设备的中断结合值( rx-usecs的ethtool -c设置)设置为100左右。这可限制中断导致的上下文切换次数。
- **使用ethtool -K对网络设备禁用GRO和LRO,这也许能够避免接收队列中的数据包不按顺序排列。**仅当同一个队列同时包含批量流量和低延迟流程时,才会出现这种问题。一般而言,启用GRO和LRO可获得最佳结果。
- **应用程序线程和网络设备IRQ应绑定到不同的CPU核心。**这两组CPU核心应与网络设备属于同一个CPU NUMA结点,应用程序和IRQ在同一个CPU核心中运行时,性能将受到影响。如果中断结合值很小,这种影响可能会非常大。
- **为尽可能降低延迟,禁用IO内存管理单元支持可能会有所帮助。**在有些系统上,默认禁用了这项功能。
性能
对于很多应用程序来说,使用频繁轮询套接字可以降低延迟和抖动,并提高每秒处理的事务数。然而,当系统包含过多的频繁轮询套接字时,会加剧CPU争用,进而影响性能。参数net.core.busy_poll和net.core.busy_read以及套接字选项SO_BUSY_POLL都是可调整的。可以尝试为各种应用程序中的此类设置指定不同的值,以获得最佳结果。
发送分组
在网络层中特定于协议的函数通知网络访问层处理由套接字缓冲区定义的一个分组时,将发送完成的分组。
当信息从计算机发送出去时,必须注意哪些事项?除了特定协议需要完成的首部和校验和,以及由高层协议实例生成的数据之外,分组的路由是最重要的。(即使计算机只有一个网卡,内核仍然需要区分发送到外部目标的分组和针对环回接口的分组。)
因为该问题只能由更高层的协议实例决定(特别是,如果可以选择到预期目标的路由时),所以设备驱动程序假定高层协议已经做出了决策。在分组可以发送到下一个正确的计算机之前(通常不同于目标计算机,因为除非存在直接的硬件链路,否则IP分组通常通过网关发送),必须确定接收方网卡的硬件地址。这是一个复杂的过程。此时,我们假定已经知道接收方的MAC地址。网络访问层的所需的另一个首部,通常由特定于协议的函数产生。
net/core/dev.c中的dev_queue_xmit用于将分组放置到发出分组的队列上。这里将忽略这个特定于设备的队列的实现,因为它并没有揭示什么网络层的运作机制。只要知道,在分组放置到等待队列上一定的时间之后,分组将发出即可。这是通过特定于适配器的函数hard_start_xmit完成的,在每个net_device结构中都以函数指针的形式出现,由硬件设备驱动程序实现。
总结
- 首部封装
- 放置到发出分组的队列(等待特定设备驱动程序取走发出)
-
相关阅读:
启动uniapp小程序报错:Error:app.json:在项目根目录中未找到app.json
使用yum进行软件安装的基础命令
物联网应用技术专业是属于什么类
Python对象序列化
Nacos配置中心1-配置文件的加载
什么是恶意代码?
【ML-SVM案例学习】案例一:对鸢尾花数据进行SVM分类(附源码)
网络爬虫之爬虫原理
计算机竞赛 目标检测-行人车辆检测流量计数
RedHat8升级GLIBC_2.29,解决ImportError: /lib64/libm.so.6: version `GLIBC_2.29
- 原文地址:https://blog.csdn.net/qq_53111905/article/details/126250990


