-
SpringBoot学习小结之分库分表、读写分离利器Shardingsphere

前言
Shardingshpere 是什么
从官网上可以看到
Apache ShardingSphere 是一款开源分布式数据库生态项目,旨在碎片化的异构数据库上层构建生态,在最大限度的复用数据库原生存算能力的前提下,进一步提供面向全局的扩展和叠加计算能力。其核心采用可插拔架构,以数据库协议及 SQL 方式提供诸多增强功能,包括数据分片、访问路由、数据安全等。
Apache ShardingSphere 由 JDBC、Proxy 和 Sidecar(规划中) 3 款产品组成。 项目的线路规划和时间历程如下图
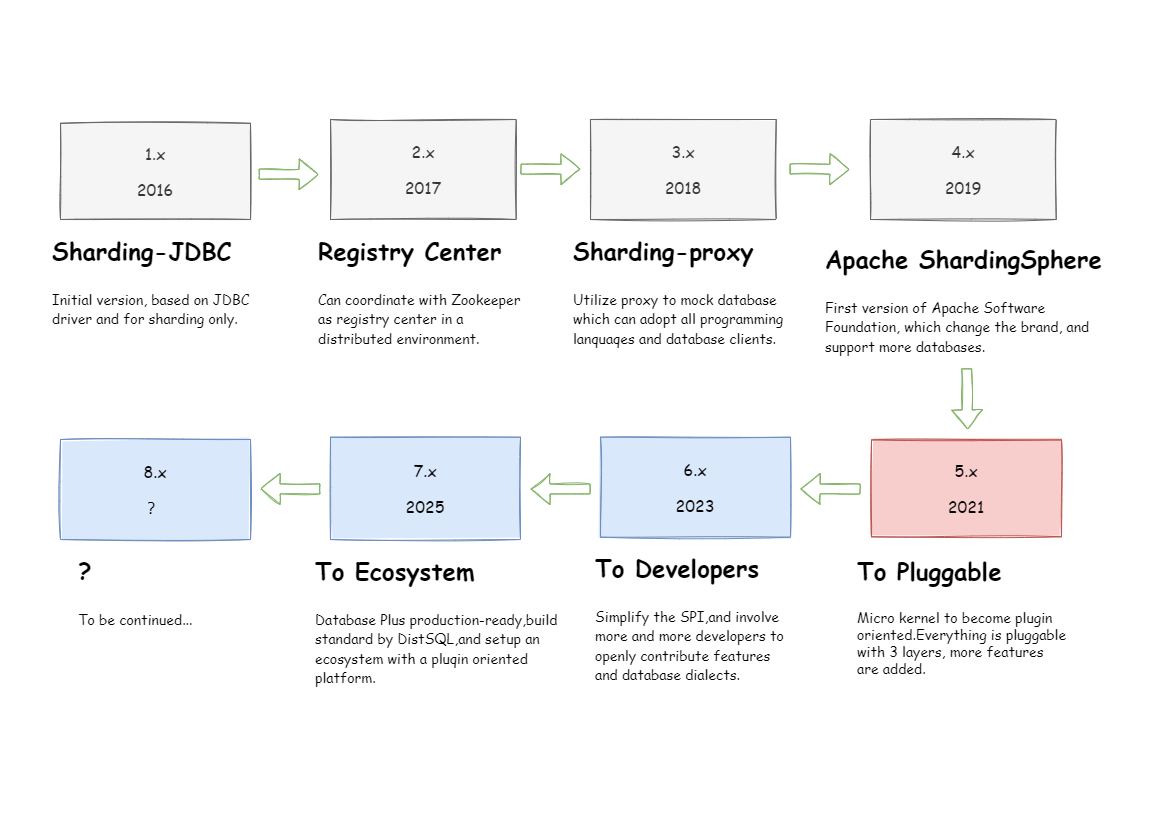
简单讲:Shardingshpere 本来是一款分库分表框架,后来在大量社区贡献者的不断迭代下,功能也逐渐完善,核心功能也变得多元化起来,已经不仅限于分库分表了,慢慢发展为开源分布式数据库生态项目。
Shardingshpere 的前世今生
- 2014 年,当当针对电商平台推出了统一开发框架 dd-frame,目的是通过分离业务和技术代码,实现开发框架统一化、技术组件标准化以及跨组沟通高效化,使研发人员的精力最大化的聚焦在业务开发上。开发框架中名为 dd-rdb 的关系型数据库模块专门用于负责数据访问,可实现简单的分库分表功能,它就是 Sharding-JDBC 的前身,也是 dd-frame 2.x 中重点规划的部分。
- 2015 年,当当决定重构 WMS 和 TMS,设计上需要引用分库分表方案,天时地利人和,当当架构部在 9 月正式启动了项目,同年 12 月份 Sharding-JDBC 1.0.0 在当当内部发布,正式开启了 ShardingSphere 的征途。
- 2016 年初,Sharding-JDBC 从 dd-rdb 中剥离,向社区开源,产品形态是增强版 JDBC 驱动,以 jar 包形式提供服务。
- 2016年2月,1.0.0 版本发布,主要功能是分库和分表,实现了 JDBC 接口,并且完整实现了 SQL 解析、SQL 改写、请求路由、结果归并的标准处理流程。
- 2016年3月,1.1.0 版本发布,大幅提升了 Sharding-JDBC 配置的友好度,增加了 YAML 、Spring 命名空间和行表达式的配置方式。
- 2016年5月,1.2.0 版本发布,实现了最大努力送达型柔性事务,完成了对分布式事务的初步支持。
- 2016年6月,1.3.0 版本发布,支持读写分离。
- 2016年11月,1.4.0 版本发布,支持无中心化分布式自增主键。至此,数据分片功能已基本实现。
- 2017年7月,1.5.0 版本发布,使用全新的自研 SQL 解析引擎替代了原有的 Druid 解析引擎,SQL兼容性大幅提升。
- 2017年12月,2.0.0 版本发布,正式将 com.dangdang 的Maven坐标与包名改为 io.shardingjdbc ,当当网将 Sharding-JDBC 正式交给社区运作和托管。2.x 版本主打数据库治理功能,同时与Apache SkyWalking 达成合作,提供 SkyWalking 的自动探针,并加入OpenTracing 组织。
- 2018年3月,3.0.0.M1 版本发布。由于京东金融等公司加入开发,Sharding-JDBC 经过社区投票,正式更名为 ShardingSphere ,将原 Sharding-JDBC 并入 ShardingSphere 生态圈,并且新开发了 Sharding-Proxy,以透明化数据库中间层的新形态提供多样化服务。同时,PMC(项目管理委员会)成立,向实现社区化迈出了重要的一步。
- 2018年6月,ShardingSphere 与 Apache ServiceComb 达成合作共识,将采用 Apache ServiceComb-saga 作为 ShardingSphere 柔性事务的决策执行引擎。
- 2018年10月末,ShardingSphere 的3.0.0稳定版本发布。
- 2018年“双11”的前一天,ShardingSphere 通过 Apache 软件基金会的投票,正式成为 Apache 孵化项目,软件更名为 Apache ShardingSphere。
- 2019 年,发布 4.0.0 版本,可支持更多的数据库产品。
- 2020 年,毕业成为 Apache 软件基金会的顶级项目。
- 2021 年 11 月 10 日,发布 5.0.0 GA 版,作为加入 Apache 软件基金会三周年纪念日的礼物,呈现给社区及整个分布式数据库和安全生态领域。
分库分表与读写分离概述
-
分库分表
关系型数据库以 MySQL 为例,单机的存储能力、连接数是有限的,它自身就很容易会成为系统的瓶颈。当单表数据量在百万以内时,我们还可以通过添加从库、优化索引提升性能。
一旦数据量朝着千万以上趋势增长,再怎么优化数据库,很多操作性能仍下降严重。为了减少数据库的负担,提升数据库响应速度,缩短查询时间,这时候就需要进行分库分表,可分为垂直拆分和水平拆分。
分库分表的目的就是要将大量数据分散到多个数据库中,使每个数据库中数据量小响应速度快,以此来提升数据库整体性能。
-
分库
- 垂直分库:专库专用,按照业务将表进行分类,分布在不同的数据库中,库可以放在不同的服务器上
- 水平分库:同一个表的数据按一定规则拆到不同的数据库中,库可以放在不同的服务器上
-
分表
- 垂直分表:将一个表按照字段拆分为多表,每个表里面都存储其中一部分字段。
- 水平分表:将一个表的数据拆分,放在多张结构一样,表名不同的表上。
-
-
读写分离
同分库分表一样,读写分离也是因为单机数据库已经很难满足业务的需要,一般在分库分表前会考虑读写分离。基本的原理是让主数据库处理事务性增、改、删操作( INSERT、UPDATE、 DELETE) ,而从数据库处理 SELECT 查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
读写分离,只是分担了访问的压力,但是存储的压力没有解决,当数据量大大增加时,还是应该考虑分库分表
一、核心概念
1.1 表
- 真实表
数据库中真实存在的物理表。例如 t_order_0、t_order_1 。 - 逻辑表
在分片之后,同一类表结构的名称(总称)。例如 t_order。 - 数据节点
在分片之后,由数据源和数据表组成。例如 ds_0.t_order_1 - 绑定表
指的是分片规则一致的关系表(主表、子表),例如 t_order 和 t_order_item,均按照
order_id 分片,则此两个表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积
关联,可以提升关联查询效率。 - 广播表
在使用中,有些表没必要做分片,例如字典表、省份信息等,因为他们数据量不大,而且这
种表可能需要与海量数据的表进行关联查询。广播表会在不同的数据节点上进行存储,存储
的表结构和数据完全相同。
1.2 分片
分片是指数据分片,从概念上讲就是按照一定的规则,将数据集划分成相对独立的数据子集,然后将数据子集分布到不同的节点上,这个节点可以是逻辑上节点,也可以是物理上的节点。 具体操作就是将数据分库分表
-
分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL 中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,ShardingSphere 也支持根据多个字段进行分片。
-
分片算法( ShardingAlgorithm)
分片算法就是将数据按照某种方式分配给数据库或表,这种方式就是分片算法。下表是 ShardingSphere 内部提供的分片算法已知实现类 详细说明 BoundaryBasedRangeShardingAlgorithm 基于分片边界的范围分片算法 VolumeBasedRangeShardingAlgorithm 基于分片容量的范围分片算法 ComplexInlineShardingAlgorithm 基于行表达式的复合分片算法 AutoIntervalShardingAlgorithm 基于可变时间范围的分片算法 ClassBasedShardingAlgorithm 基于自定义类的分片算法 HintInlineShardingAlgorithm 基于行表达式的 Hint 分片算法 IntervalShardingAlgorithm 基于固定时间范围的分片算法 HashModShardingAlgorithm 基于哈希取模的分片算法 InlineShardingAlgorithm 基于行表达式的分片算法 ModShardingAlgorithm 基于取模的分片算法 常用有以下 5 种
-
行内表达式分片算法 ( InlineShardingAlgorithm )
- 最常用的分片方式
- 只需要在配置中使用 ${ expression } 或 $->{ expression } 标识行表达式即可。 目前支持数据节点和分片算法这两个部分的配置。
- 行表达式的内容使用的是 Groovy 的语法
- 常见用法
- ${begin…end} 表示范围区间
- ${[unit1, unit2, unit_x]} 表示枚举值
- ds$->{id % 10}
-
精确分片算法 ( PreciseShardingAlgorithm )
用于处理使用单一键作为分片键的 = 与 IN 进行分片的场景。spring: shardingsphere: sharding: tables: sku: # 这个配置是告诉sharding有多少个表 actual-data-nodes: ds1.sku_$->{0..1} # 配置其分片策略和分片算法 table-strategy: standard: sharding-column: sku_id precise-algorithm-class-name: com.xulei.spring.shardConfig.MyPreciseShardingAlgorithm- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
@Slf4j public class MyPreciseShardingAlgorithm implements PreciseShardingAlgorithm<String> { /** * Sharding. * 实现标准分片策略,通过计算分到不同的表来实现分表策略。 * @param collection available data sources or tables's names * @param preciseShardingValue sharding value * @return sharding result for data source or table's name */ @Override public String doSharding(Collection<String> collection, PreciseShardingValue<String> preciseShardingValue) { Comparable value = preciseShardingValue.getValue(); String columnName = preciseShardingValue.getColumnName(); String logicTableName = preciseShardingValue.getLogicTableName(); log.info("collection:" + JSON.toJSONString(collection) + ",preciseShardingValue:" + JSON.toJSONString(preciseShardingValue)); String data = value.toString(); int size = collection.size(); for(String tableName: collection){ int index = Math.abs(data.hashCode() % size); if(tableName.endsWith(index+"")){ return tableName; } } return null; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
-
范围分片算法 ( RangeShardingAlgorithm )
用于处理使用单一键作为分片键的 BETWEEN AND、>、<、>=、<= 进行分片的场景。public class MyDBRangeShardingAlgorithm implements RangeShardingAlgorithm<Integer> { @Override public Collection<String> doSharding(Collection<String> databaseNames, RangeShardingValue<Integer> rangeShardingValue) { Set<String> result = new LinkedHashSet<>(); // between and 的起始值 int lower = rangeShardingValue.getValueRange().lowerEndpoint(); int upper = rangeShardingValue.getValueRange().upperEndpoint(); // 循环范围计算分库逻辑 for (int i = lower; i <= upper; i++) { for (String databaseName : databaseNames) { if (databaseName.endsWith(i % databaseNames.size() + "")) { result.add(databaseName); } } } return result; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
-
复合分片算法 ( ComplexKeysShardingAlgorithm )
用于处理使用多键作为分片键进行分片的场景,多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。
public class MyDBComplexKeysShardingAlgorithm implements ComplexKeysShardingAlgorithm<Integer> { @Override public Collection<String> doSharding(Collection<String> databaseNames, ComplexKeysShardingValue<Integer> complexKeysShardingValue) { // 得到每个分片健对应的值 Collection<Integer> orderIdValues = this.getShardingValue(complexKeysShardingValue, "order_id"); Collection<Integer> userIdValues = this.getShardingValue(complexKeysShardingValue, "user_id"); List<String> shardingSuffix = new ArrayList<>(); // 对两个分片健同时取模的方式分库 for (Integer userId : userIdValues) { for (Integer orderId : orderIdValues) { String suffix = userId % 2 + "_" + orderId % 2; for (String databaseName : databaseNames) { if (databaseName.endsWith(suffix)) { shardingSuffix.add(databaseName); } } } } return shardingSuffix; } private Collection<Integer> getShardingValue(ComplexKeysShardingValue<Integer> shardingValues, final String key) { Collection<Integer> valueSet = new ArrayList<>(); Map<String, Collection<Integer>> columnNameAndShardingValuesMap = shardingValues.getColumnNameAndShardingValuesMap(); if (columnNameAndShardingValuesMap.containsKey(key)) { valueSet.addAll(columnNameAndShardingValuesMap.get(key)); } return valueSet; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
-
Hint分片算法 ( HintShardingAlgorithm )
用于处理使用 Hint 行分片的场景。对于分片字段非 SQL 决定,而由其他外置条件决定的场景,可使用 SQL Hint 灵活的注入分片字段。例:内部系统,按照员工登录主键分库,而数据库中并无此字段。SQL Hint 支持通过 Java API 和 SQL 注释两种方式使用。public class MyTableHintShardingAlgorithm implements HintShardingAlgorithm<String> { @Override public Collection<String> doSharding(Collection<String> tableNames, HintShardingValue<String> hintShardingValue) { Collection<String> result = new ArrayList<>(); for (String tableName : tableNames) { for (String shardingValue : hintShardingValue.getValues()) { if (tableName.endsWith(String.valueOf(Long.valueOf(shardingValue) % tableNames.size()))) { result.add(tableName); } } } return result; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
-
-
分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供5种分片策略。
-
标准分片策略( StandardShardingStrategy )
提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。StandardShardingStrategy 只支持单分片键,提供PreciseShardingAlgorithm 和 RangeShardingAlgorithm 两个分片算法。PreciseShardingAlgorithm 是必选的,用于处理=和IN的分片。RangeShardingAlgorithm 是可选的,用于处理 BETWEEN AND, >, <, >=, <= 分片,如果不配置RangeShardingAlgorithm ,SQL 中的 BETWEEN AND 将按照全库路由处理。
-
复合分片策略( ComplexShardingStrategy )
提供对SQL语句中的 =, >, <, >=, <=, IN 和 BETWEEN AND 的分片操作支持。ComplexShardingStrategy 支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
-
行表达式分片策略 ( InlineShardingStrategy )
使用 Groovy 的表达式,提供对 SQL 语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如:
t_user_$->{u_id % 8}表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7。 -
Hint分片策略 ( HintShardingStrategy )
通过Hint指定分片值而非从 SQL 中提取分片值的方式进行分片的策略。
-
不分片策略 ( NoneShardingStrategy )
不分片的策略。
-
二、pom 依赖
下面会演示 shardingsphere 和 mybatisplus 一起使用
<dependency> <groupId>org.apache.shardingspheregroupId> <artifactId>shardingsphere-jdbc-core-spring-boot-starterartifactId> <version>5.1.1version> dependency> <dependency> <groupId>com.baomidougroupId> <artifactId>mybatis-plus-boot-starterartifactId> <version>3.5.2version> dependency> <dependency> <groupId>mysqlgroupId> <artifactId>mysql-connector-javaartifactId> <scope>runtimescope> dependency> <dependency> <groupId>org.projectlombokgroupId> <artifactId>lombokartifactId> <optional>trueoptional> dependency>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
三、数据准备
3.1 SQL
准备三个数据库,也就是三个数据源,一个 master 和两个 slave
DROP DATABASE IF EXISTS demo_dev_master; create database demo_dev_master; DROP DATABASE IF EXISTS demo_dev_slave_0; create database demo_dev_slave_0; DROP DATABASE IF EXISTS demo_dev_slave_1; create database demo_dev_slave_1; use demo_dev_master; DROP TABLE IF EXISTS `t_address`; CREATE TABLE `t_address` ( `address_id` bigint(20) NOT NULL, `address_name` varchar(100) NOT NULL, PRIMARY KEY (`address_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; DROP TABLE IF EXISTS `t_order`; CREATE TABLE `t_order` ( `order_id` bigint(20) NOT NULL AUTO_INCREMENT, `order_type` int(11) DEFAULT NULL, `user_id` int(11) NOT NULL, `address_id` bigint(20) NOT NULL, `status` varchar(50) DEFAULT NULL, PRIMARY KEY (`order_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; DROP TABLE IF EXISTS `t_order_0`; create table `t_order_0` like `t_order`; DROP TABLE IF EXISTS `t_order_1`; create table `t_order_1` like `t_order`; DROP TABLE IF EXISTS `t_order_2`; create table `t_order_2` like `t_order`; DROP TABLE IF EXISTS `t_order_3`; create table `t_order_3` like `t_order`; DROP TABLE IF EXISTS `t_order_4`; create table `t_order_4` like `t_order`; DROP TABLE IF EXISTS `t_order_item`; CREATE TABLE `t_order_item` ( `order_item_id` bigint(20) NOT NULL AUTO_INCREMENT, `order_id` bigint(20) DEFAULT NULL, `user_id` int(11) NOT NULL, `phone` varchar(50) DEFAULT NULL, `status` varchar(50) DEFAULT NULL, PRIMARY KEY (`order_item_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; DROP TABLE IF EXISTS `t_order_item_0`; create table `t_order_item_0` like `t_order_item`; DROP TABLE IF EXISTS `t_order_item_1`; create table `t_order_item_1` like `t_order_item`; DROP TABLE IF EXISTS `t_order_item_2`; create table `t_order_item_2` like `t_order_item`; DROP TABLE IF EXISTS `t_order_item_3`; create table `t_order_item_3` like `t_order_item`; DROP TABLE IF EXISTS `t_order_item_4`; create table `t_order_item_4` like `t_order_item`;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
将上面的 master 数据库复制两份 slave ,可以用下面的方法
mysqldump -u root --password=<pwd> demo_dev_master | mysql -u root -p demo_dev_slave_0 mysqldump -u root --password=<pwd> demo_dev_master | mysql -u root -p demo_dev_slave_1- 1
- 2
3.2 实体
@TableName("t_address") @Data @Builder public class Address { @TableId private Long addressId; private String addressName; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
@TableName("t_order") @Data @Builder public class Order { @TableId private Long orderId; private Integer orderType; private Integer userId; private Long addressId; private String status; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
@TableName("t_order_item") @Data @Builder public class OrderItem { @TableId private Long orderItemId; private Long orderId; private Integer userId; private String phone; private String status; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3.3 DAO 接口
@Mapper public interface AddressDao extends BaseMapper<Address> { }- 1
- 2
- 3
@Mapper public interface OrderDao extends BaseMapper<Order> { }- 1
- 2
- 3
@Mapper public interface OrderItemDao extends BaseMapper<OrderItem> { }- 1
- 2
- 3
四、分库分表
4.1 只分库
将 demo_dev_slave_0 和 demo_dev_slave_1 用作只分库的数据源
一个简单的分库配置文件,将 user_id 为偶数的数据分配给slave_0, 奇数则给slave_1. 具体 yml 配置文件 application-sharding-database.yml 如下所示
spring: shardingsphere: datasource: names: dev_slave_0, dev_slave_1 dev_slave_0: type: com.zaxxer.hikari.HikariDataSource driverClassName: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/demo_dev_slave_0?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 username: root password: dev_slave_1: type: com.zaxxer.hikari.HikariDataSource driverClassName: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/demo_dev_slave_1?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 username: root password: props: sql-show: true rules: sharding: default-database-strategy: standard: sharding-algorithm-name: database-inline sharding-column: user_id sharding-algorithms: database-inline: type: INLINE props: algorithm-expression: dev_slave_$->{user_id % 2} tables: t_order: actual-data-nodes: dev_slave_$->{0..1}.t_order t_order_item: actual-data-nodes: dev_slave_$->{0..1}.t_order_item- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
测试
@SpringBootTest // @ActiveProfiles("readwrite-splitting") @ActiveProfiles("sharding-database") class DemoShardingSphereApplicationTests { private static final Logger logger = LoggerFactory.getLogger(DemoShardingSphereApplicationTests.class); @Autowired private OrderDao orderDao; @Autowired private OrderItemDao orderItemDao; @Autowired private AddressDao addressDao; @BeforeEach void setUp() { addressDao.delete(null); orderDao.delete(null); orderItemDao.delete(null); Address address1 = Address.builder().addressId(1L).addressName("北京朝阳区").build(); Address address2 = Address.builder().addressId(2L).addressName("海南三亚市").build(); addressDao.insert(address1); addressDao.insert(address2); for (int i = 0; i < 50; i++) { Order order = Order.builder().orderType(1).userId(i % 2).addressId( i % 2L).status("发货中").build(); orderDao.insert(order); for (int j = 0; j < 2; j++) { OrderItem orderItem = OrderItem.builder().orderId(order.getOrderId()).phone("1333333333").userId(i % 2).status("发货中").build(); orderItemDao.insert(orderItem); } } } @Test void test() { List<Order> orders = orderDao.selectList(null); logger.info("{}", orders); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
最终数据库结果展示
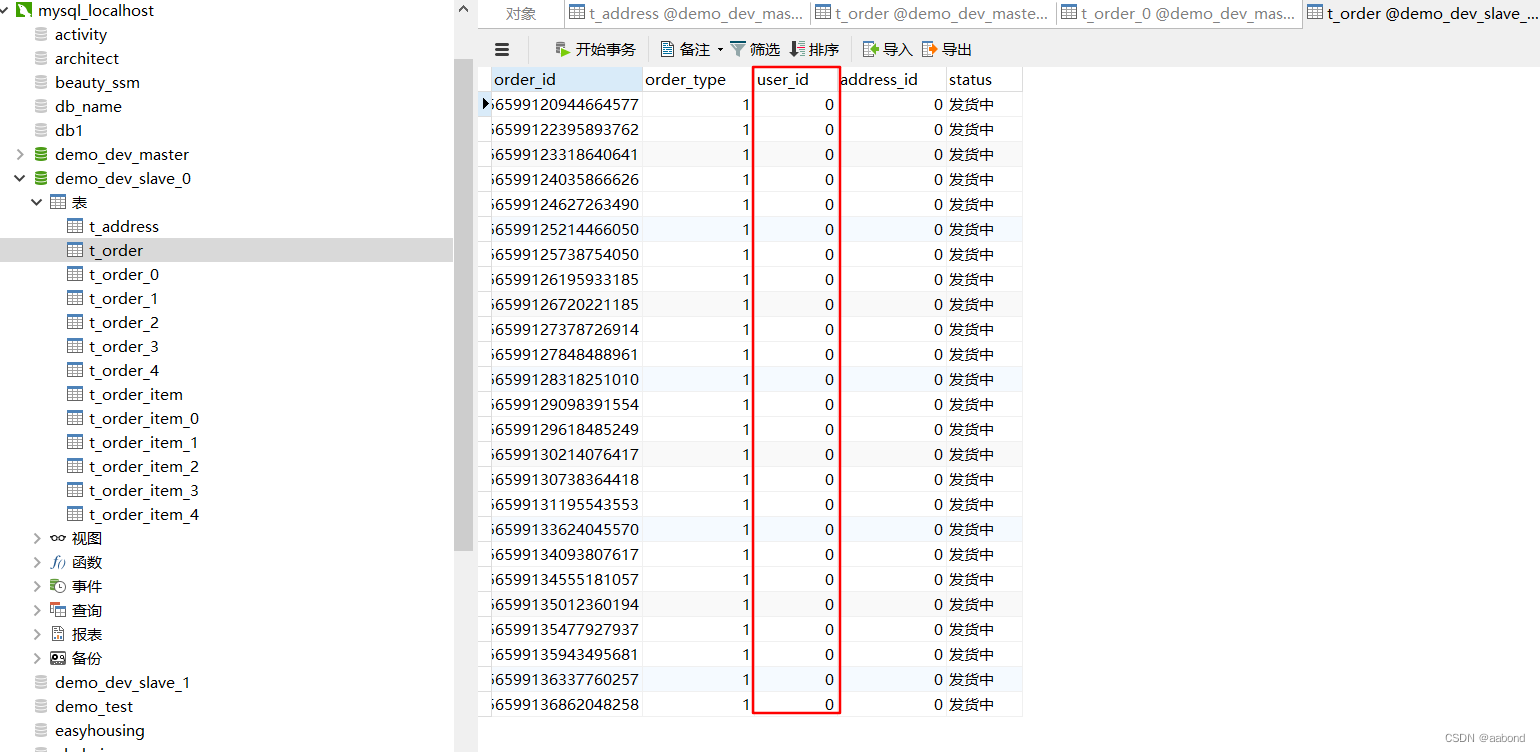
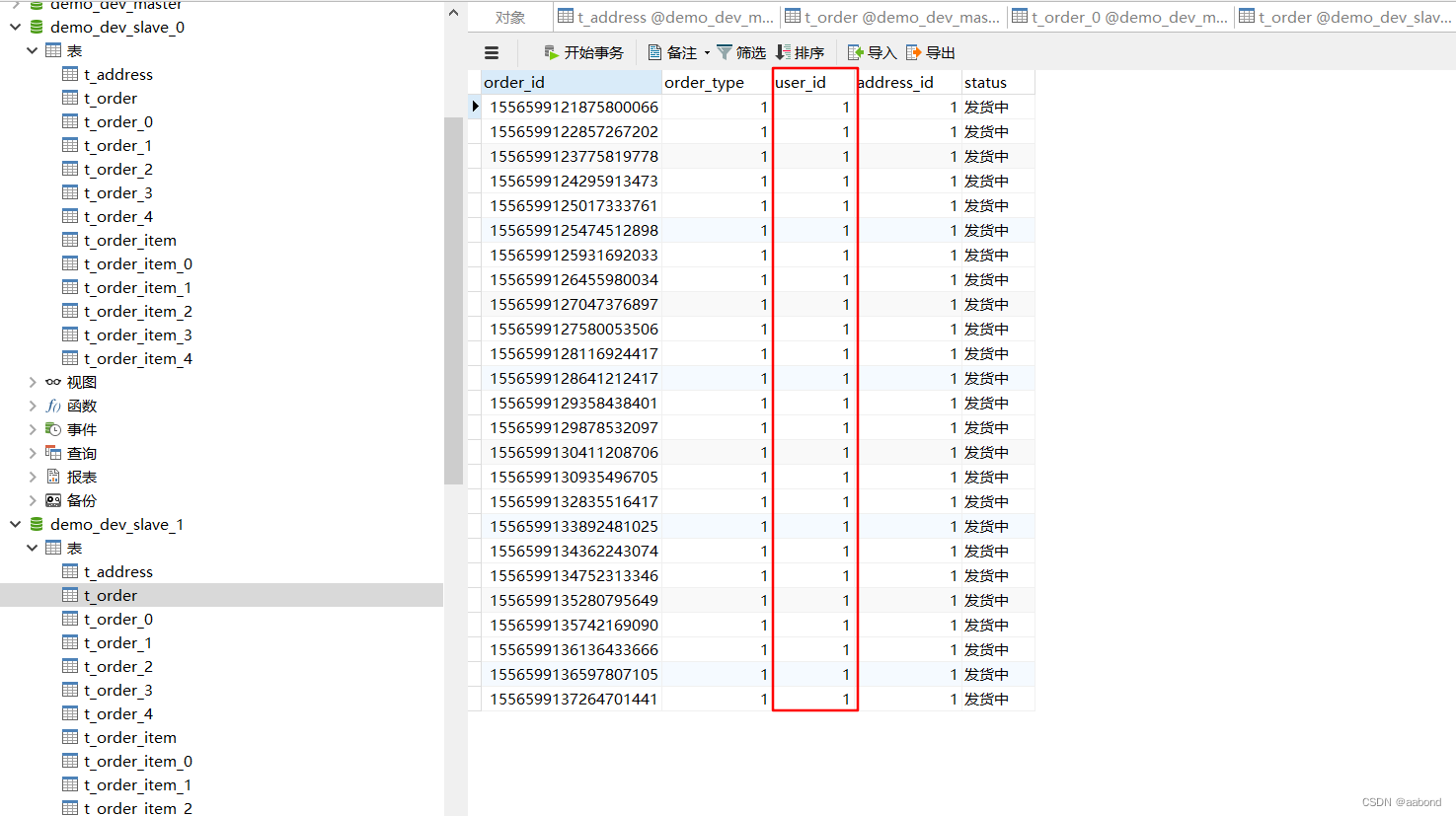
4.2 只分表
将 demo_dev_slave_0 用作只分表的数据源。
一个简单的分表配置文件,将 order_id 对 5 取余,分配给 t_order_{0…4}。具体 yml 配置文件 application-sharding-table.yml 如下所示。
spring: shardingsphere: datasource: names: dev_slave_0 dev_slave_0: type: com.zaxxer.hikari.HikariDataSource driverClassName: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/demo_dev_slave_0?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 username: root password: root props: sql-show: true rules: sharding: tables: t_order: actual-data-nodes: dev_slave_0.t_order_${0..4} table-strategy: standard: sharding-column: order_id sharding-algorithm-name: t_order_inline t_order_item: actual-data-nodes: dev_slave_0.t_order_item_${0..4} table-strategy: standard: sharding-column: order_id sharding-algorithm-name: t_order_item_inline binding-tables: t_order,t_order_item broadcast-tables: t_address sharding-algorithms: t_order_inline: type: INLINE props: algorithm-expression: t_order_$->{order_id % 5} t_order_item_inline: type: INLINE props: algorithm-expression: t_order_item_$->{order_id % 5}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
测试代码如分库所示,只不过要修改 profile 为 sharding-table
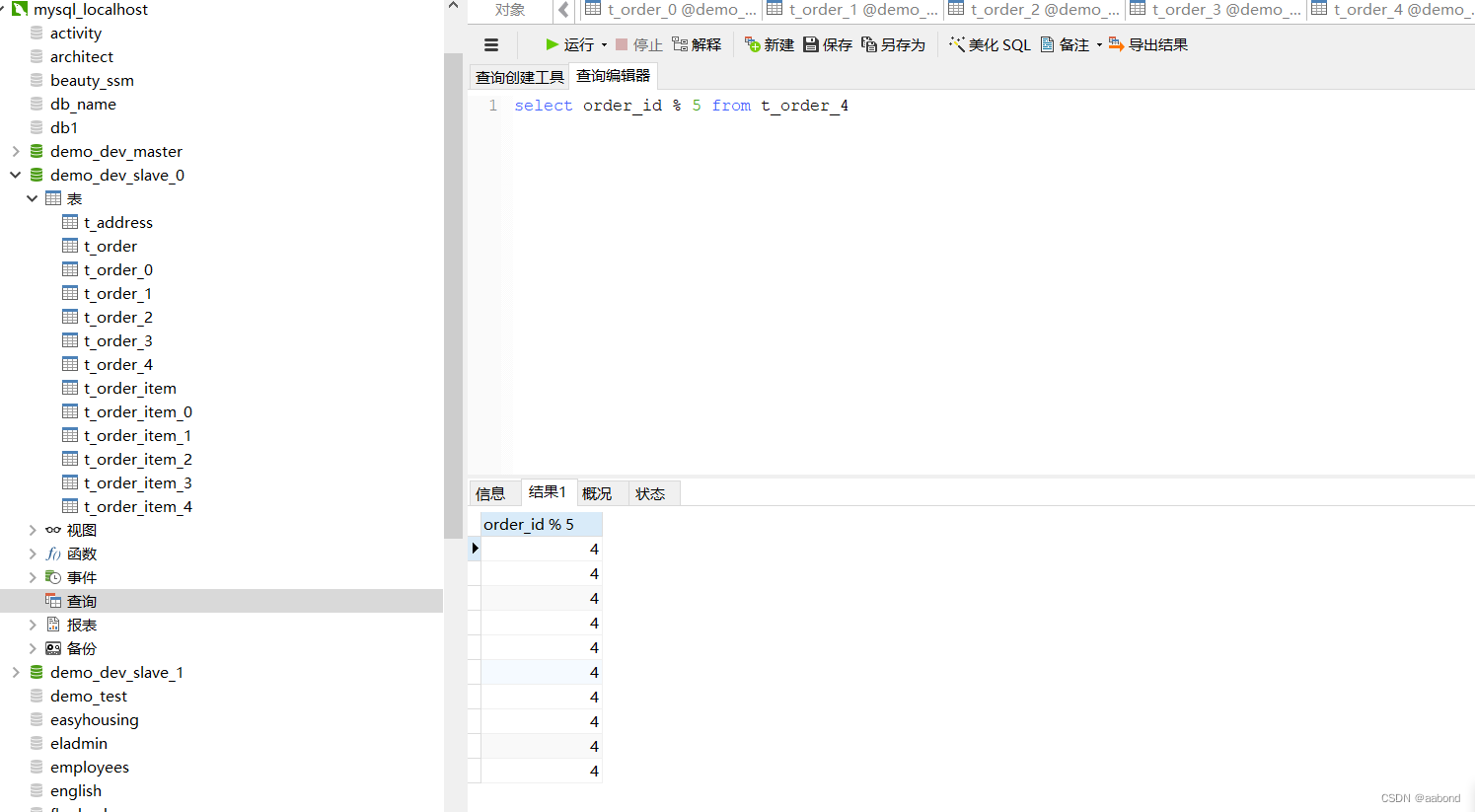
数据库结果如下:t_order_{0…4} 都有数据
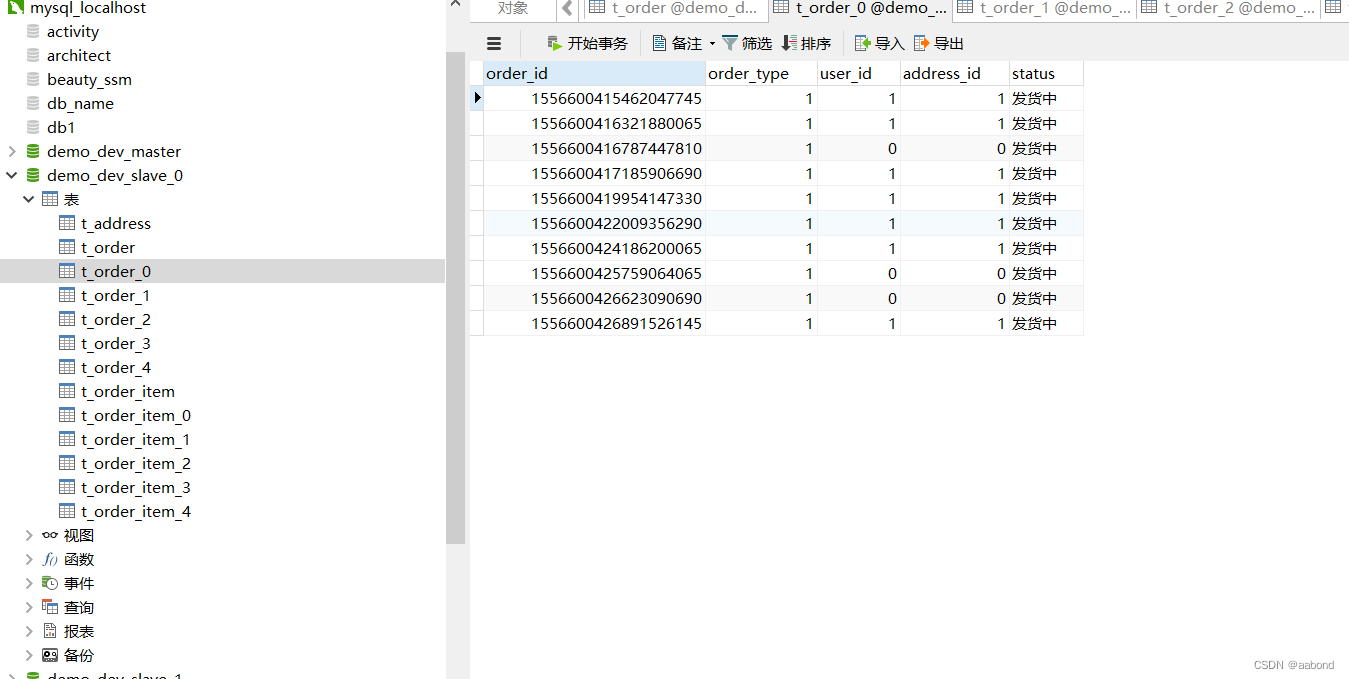
对任意t_order_{0…4}表 order_id 进行取余运算,发现满足规则
4.3 分库 + 分表
将 demo_dev_slave_0 和 demo_dev_slave_1 用作分库分表的数据源
一个简单的分库分表配置文件,将 上述两种情况整合.。具体 yml 配置文件 application-sharding-database-table.yml 如下所示
spring: shardingsphere: datasource: names: dev_slave_0, dev_slave_1 dev_slave_0: type: com.zaxxer.hikari.HikariDataSource driverClassName: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/demo_dev_slave_0?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 username: root password: dev_slave_1: type: com.zaxxer.hikari.HikariDataSource driverClassName: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/demo_dev_slave_1?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 username: root password: props: sql-show: true rules: sharding: default-database-strategy: standard: sharding-algorithm-name: database-inline sharding-column: user_id binding-tables: t_order,t_order_item broadcast-tables: t_address tables: t_order: actual-data-nodes: dev_slave_$->{0..1}.t_order_$->{0..4} table-strategy: standard: sharding-algorithm-name: order_mod sharding-column: order_id t_order_item: actual-data-nodes: dev_slave_$->{0..1}.t_order_item_$->{0..4} table-strategy: standard: sharding-algorithm-name: order_item_mod sharding-column: order_id sharding-algorithms: auto-mod: type: MOD props: sharding-count: 2 database-inline: type: INLINE props: algorithm-expression: dev_slave_$->{user_id % 2} order_mod: type: INLINE props: algorithm-expression: t_order_$->{order_id % 5} order_item_mod: type: INLINE props: algorithm-expression: t_order_item_$->{order_id % 5}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
五、读写分离
5.1 例子
读写分离会将读写的 sql 应用到主从数据库中,主库和从库的数据复制需要自己实现,shardingSphere 并不提供这样的功能。 具体 yml 配置文件 application-readwrite-splitting.yml 如下所示
spring: shardingsphere: datasource: names: dev_master, dev_slave_0, dev_slave_1 dev_master: type: com.zaxxer.hikari.HikariDataSource driverClassName: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/demo_dev_master?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 username: root password: root dev_slave_0: type: com.zaxxer.hikari.HikariDataSource driverClassName: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/demo_dev_slave_0?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 username: root password: root dev_slave_1: type: com.zaxxer.hikari.HikariDataSource driverClassName: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/demo_dev_slave_1?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 username: root password: root props: sql-show: true rules: readwrite-splitting: data-sources: read_write_db: type: Static props: write-data-source-name: dev_master read-data-source-names: dev_slave_0, dev_slave_1 load-balancer-name: round_robin load-balancers: round_robin: type: ROUND_ROBIN- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
5.2 负载均衡
因为从库有多个,所以我们需要根据一定的策略将请求分发到不同的数据库上,防止单节点的压力过大或者空闲,ShardingSphere 内置了多种负载均衡算法,如果我们想实现自己的 算法,那么可以实现
ReadQueryLoadBalanceAlgorithm接口-
ROUND_ROBIN
基于轮询的读库负载均衡算法,原理是每一次读库的请求轮流分配,从1开始,直到N(从库个数),然后重新开始循环。
例子如上所示
-
RANDOM
基于随机的读库负载均衡算法,原理就是随机分配
spring: shardingsphere: rules: readwrite-splitting: data-sources: read_write_db: type: Static props: write-data-source-name: dev_master read-data-source-names: dev_slave_0, dev_slave_1 load-balancer-name: random loadBalancers: random: type: RANDOM- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
-
WEIGHT
基于权重的读库负载均衡算法
spring: shardingsphere: rules: readwrite-splitting: data-sources: read_write_db: type: Static props: write-data-source-name: dev_master read-data-source-names: dev_slave_0, dev_slave_1 load-balancer-name: weight loadBalancers: weight: type: WEIGHT props: dev_slave_0: 2 dev_slave_1: 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
参考
-
相关阅读:
PHP 魔术常量
CentOS遇到的麻烦与解决方案
业务级灾备架构设计
CompletableFuture使用示例
es(网站的搜索技术)
webpack
NSDT孪生场景编辑器系统介绍
openpyxl应用
【Pytorch笔记】5.DataLoader、Dataset、自定义Dataset
Nacos使用教程(二)——nacos注册中心(1)
- 原文地址:https://blog.csdn.net/qq_23091073/article/details/126243246
