-
探索TiDB Lightning源码来解决发现的bug
背景
上一篇《记一次简单的Oracle离线数据迁移至TiDB过程》 2说到在使用Lightning导入csv文件到TiDB的时候发现了一个bug,是这样一个过程。
Oracle源库中表名都是大写,经过前文所述的方法导入到TiDB后表名也是保持全大写,数据同步过程非常顺利。
第二天我把整套操作流程教给一位新手朋友,他就挑了一张表用来做实验,结果死活都不行。各种分析和重试都没有效果,就在快要懵逼的时候想到了这个大小写问题,把csv拉出来一看是个全小写的文件名,我尝试着把表名改成大写再导入一次,这次终于成功了。
原来,是这位小伙子用sqluldr2导出表数据的时候把文件名写死了,而且是个小写。。。
这里提一下TiDB表名大小写敏感相关的参数
lower-case-table-names,这个参数只能被设置成2,也就是存储表名的时候区分大小写,对比的时候统一转为小写。因此,TiDB中的表名建议使用全小写来命名。这个特性基本和MySQL是一致的,只是MySQL支持更多的场景,具体可以参考https://dev.mysql.com/doc/refman/5.7/en/identifier-case-sensitivity.html 1
那么,说好的TiDB表名不区分大小写呢,怎么用了Lightning就失效了?
Bug重现
上面说的还是有点抽象,我们通过如下的步骤重现一下。
这里我准备的TiDB测试版本是v5.2.2,和前面发现bug的版本一致,Lightning也使用配套的版本。我拿最新的master分支也能复现这个问题。
先创建一张测试表,表名全部用大写:
use test; create table LIGHTNING_BUG (f1 varchar(50),f2 varchar(50),f3 varchar(50));- 1
- 2
- 3
再准备一个待导入的csv文件,文件名是
test.lightning_bug.csv:111|aaa|%%% 222|bbb|###- 1
- 2
Lightning的完整配置文件:
[lightning] level = "info" file = "tidb-lightning.log" index-concurrency = 2 table-concurrency = 5 io-concurrency = 5 [tikv-importer] backend = "local" sorted-kv-dir = "/tmp/tidb/lightning_dir" [mydumper] data-source-dir = "/tmp/tidb/data" no-schema = true filter = ['*.*'] [mydumper.csv] # 字段分隔符,支持一个或多个字符,默认值为 ','。 separator = '|' # 引用定界符,设置为空表示字符串未加引号。 delimiter = '' # 行尾定界字符,支持一个或多个字符。设置为空(默认值)表示 "\n"(换行)和 "\r\n" (回车+换行),均表示行尾。 terminator = "" # CSV 文件是否包含表头。 # 如果 header = true,将跳过首行。 header = false # CSV 文件是否包含 NULL。 # 如果 not-null = true,CSV 所有列都不能解析为 NULL。 not-null = false # 如果 not-null = false(即 CSV 可以包含 NULL), # 为以下值的字段将会被解析为 NULL。 null = '\N' # 是否对字段内“\“进行转义 backslash-escape = true # 如果有行以分隔符结尾,删除尾部分隔符。 trim-last-separator = false [tidb] host = "x.x.x.x" port = 4000 user = "root" password = "" status-port = 10080 pd-addr = "x.x.x.x:2379" [checkpoint] enable = false [post-restore] checksum = false analyze = false- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
运行如下命令开始执行导入任务:
./tidb-lightning --config tidb-lightning.toml --check-requirements=false- 1
报错信息:
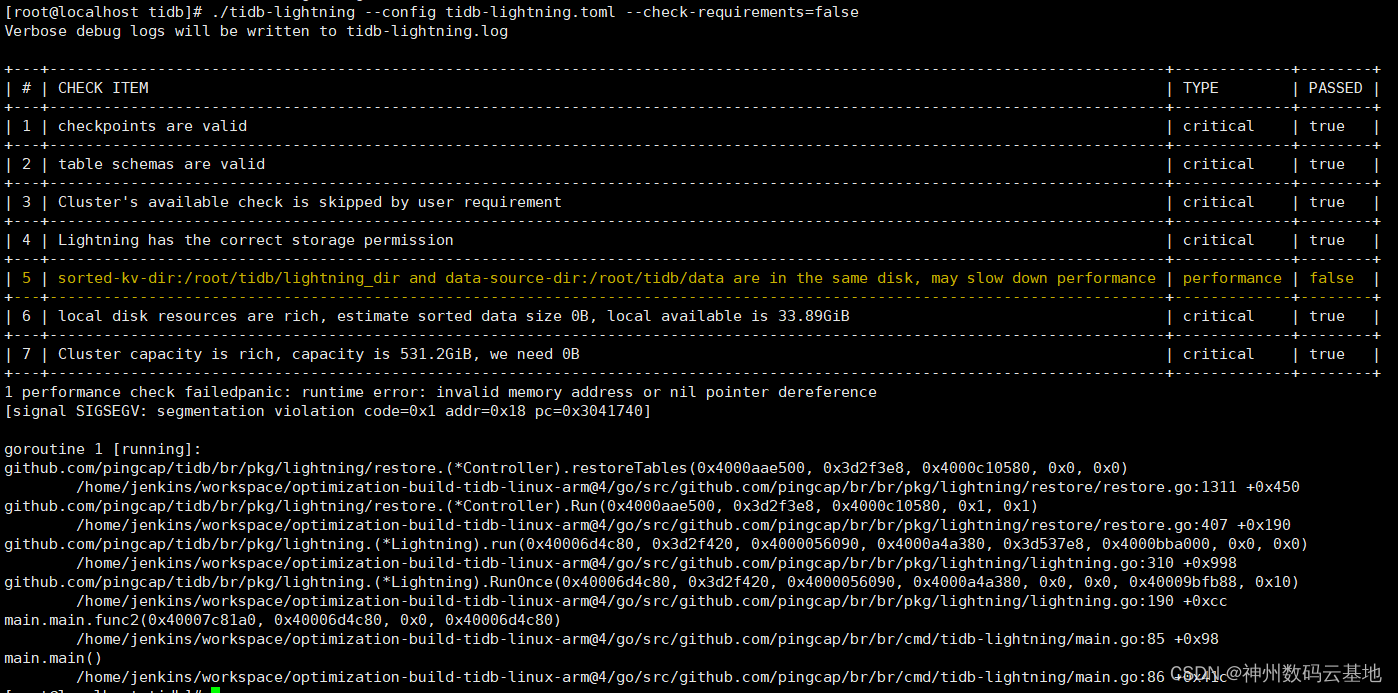
日志里面全部是Info,除了没有正常输出
tidb lightning exit以外,看不到任何报错,一幅岁月静好的样子:
我认为这里的主要问题是,panic非常不友好,而且提示信息不够明确,虽然说了是空指针异常不过没什么参考价值,当时还被
segmentation violation误导了好久,一直怀疑是数据格式有问题。我意识到这个bug应该不难,于是自己拉了一份TiDB源码开始定位问题。
Lightning的处理流程
Lightning的入口文件是
br/cmd/tidb-lightning/main.go,而它的核心实现都放在br/pkg/lightning目录下。我根据报错的堆栈信息倒推整个Lightning的导入流程,首先定位到
restore.go文件第1311行,我看到如下代码:
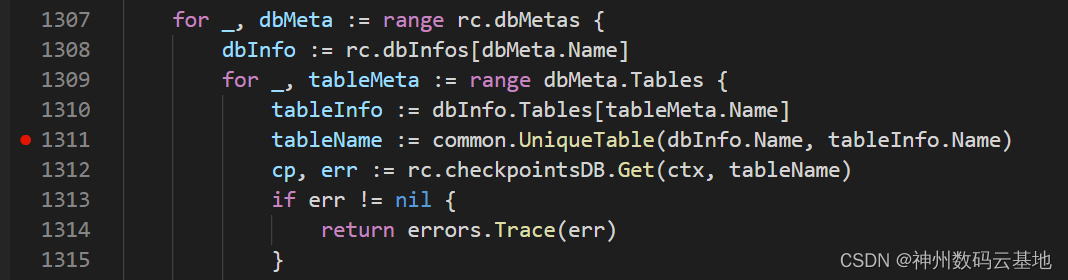
根据直觉,猜测
tableInfo是一个nil值,以至于在取tableInfo.Name的时候报出空指针异常。如果是这样的话,证明是表名不存在导致,但我记得表不存在的时候它的报错信息是这样:

所以说在此之前的某个地方,它一定是把大写表名和小写表名匹配上的,我们继续往上翻。
在报错的这个地方,需要重点关注两个被对比的map对象
rc.dbMetas和rc.dbInfos,报错的原因是dbMetas里的表在dbInfos里面找不到,那我们就分别看看这两个对象是干嘛用的。通过查找这行代码所在的方法
restoreTables调用关系,发现了Lightning的主要导入流程:func (rc *Controller) Run(ctx context.Context) error { opts := []func(context.Context) error{ rc.setGlobalVariables, rc.restoreSchema, rc.preCheckRequirements, rc.restoreTables, rc.fullCompact, rc.switchToNormalMode, rc.cleanCheckpoints, } .... for i, process := range opts { err = process(ctx) .... } .... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
这里的主要流程就是
restoreSchema和restoreTables,我们一会再来细看,先继续往上翻。再上一层是
lightning.go文件的run方法,在这儿我们找到了那个dbMetas是怎么来的:func (l *Lightning) run(taskCtx context.Context, taskCfg *config.Config, g glue.Glue) (err error) { ... dbMetas := mdl.GetDatabases() web.BroadcastInitProgress(dbMetas) var procedure *restore.Controller procedure, err = restore.NewRestoreController(ctx, dbMetas, taskCfg, s, g) if err != nil { log.L().Error("restore failed", log.ShortError(err)) return errors.Trace(err) } defer procedure.Close() err = procedure.Run(ctx) return errors.Trace(err) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
通过一路追踪进去,发现
dbMetas就是通过解析要导入的文件名来获得数据库名称和表名称的,也就是说它存放着要被导入的Schema信息,这也是为什么csv文件要按照{dbname}.{tablename}.csv来命名的原因。Tips:其实这个格式是可以通过[mydumper.files]自定义的,上面这种是默认格式。
再往上的话就是
RunOnce方法,这是main函数的调用入口,它传入了一个空的上下文对象,以及配置文件信息:/// br > pkg > lightning > lightning.go func (l *Lightning) RunOnce(taskCtx context.Context, taskCfg *config.Config, glue glue.Glue) error { if err := taskCfg.Adjust(taskCtx); err != nil { return err } taskCfg.TaskID = time.Now().UnixNano() ... return l.run(taskCtx, taskCfg, glue) } /// br > cmd > tidb-lightning > main.go func main() { globalCfg := config.Must(config.LoadGlobalConfig(os.Args[1:], nil)) .... err = func() error { if globalCfg.App.ServerMode { return app.RunServer() } cfg := config.NewConfig() if err := cfg.LoadFromGlobal(globalCfg); err != nil { return err } return app.RunOnce(context.Background(), cfg, nil) }() .... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
整个过程还是比较清晰的,核心处理逻辑都放在
Restore Controller里面。按照前面的分析,似乎只要在报错的地方判断一下
nil就行了,但判断之后我该做如何处理呢?感觉只是治标不治本,还需要进一步分析下。
对Bug的思考
深度分析之前再看一个现象,我把最开始的导入命令去掉
--check-requirements=false参数,看到如下提示:
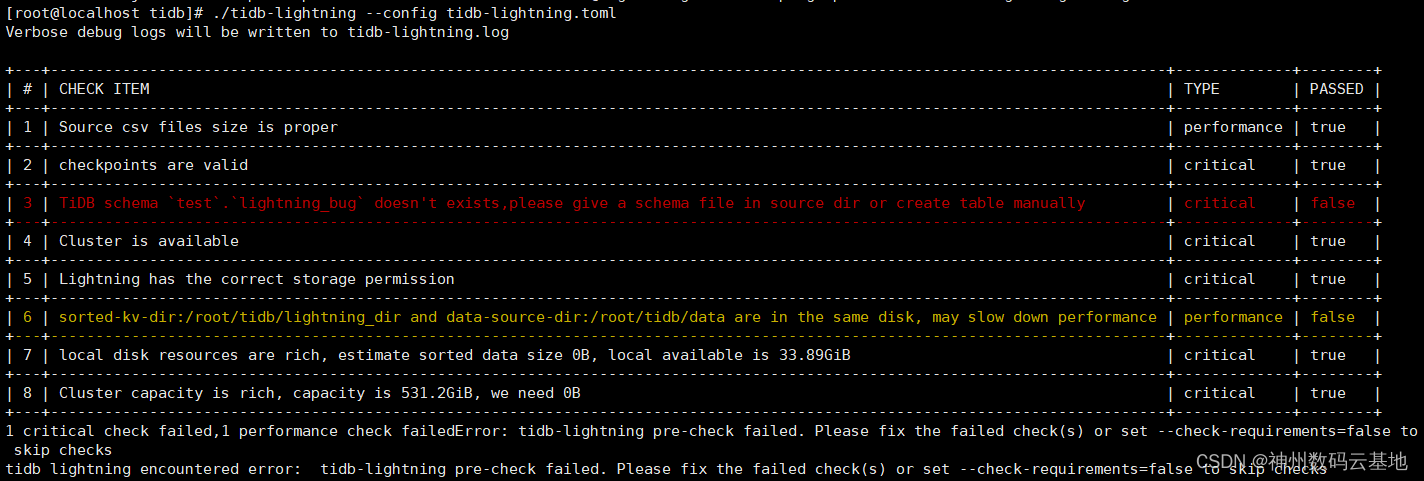
貌似lightning本身是能识别到大小写的差异呀(看到这里我一度认为修复方法是提示表不存在),再结合之前提到的
table schema not found报错,我觉得事情有点诡异。深扒源码发现,Lightning是能够对上下游Schema做非常细致的检查,这部分逻辑被封装在
SchemaIsValid方法中,只有在--check-requirements=true的时候才会启用,这里的检查包括库表名称、字段数量、数据文件、csv表头等等。那table schema not found又是怎么回事?前面提到
dbMetas是通过解析文件名获取,我们再看看dbInfos是如何获取的。回到之前提到的restoreSchema方法,我看到如下代码:getTableFunc := rc.backend.FetchRemoteTableModels .... err := worker.makeJobs(rc.dbMetas, getTableFunc) .... dbInfos, err := LoadSchemaInfo(ctx, rc.dbMetas, getTableFunc) if err != nil { return errors.Trace(err) } rc.dbInfos = dbInfos ....- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
从这里可以看到,获取目标库的表清单是通过各自Backend提供的远程方式读取的,对于local模式而言,实际就是调用TiDB的状态端口去获取(现在知道配置文件中10080的作用了吧):
curl http://{tidb-server}:10080/schema/test- 1
makeJobs方法是创建Schema的核心实现,主要包括恢复数据库、恢复表结构、恢复视图3部分。看如下一部分代码;// 2. restore tables, execute statements concurrency for _, dbMeta := range dbMetas { // we can ignore error here, and let check failed later if schema not match tables, _ := getTables(worker.ctx, dbMeta.Name) tableMap := make(map[string]struct{}) for _, t := range tables { tableMap[t.Name.L] = struct{}{} } for _, tblMeta := range dbMeta.Tables { if _, ok := tableMap[strings.ToLower(tblMeta.Name)]; ok { // we already has this table in TiDB. // we should skip ddl job and let SchemaValid check. continue } else if tblMeta.SchemaFile.FileMeta.Path == "" { return errors.Errorf("table `%s`.`%s` schema not found", dbMeta.Name, tblMeta.Name) } ... } ...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
这里很让人迷惑,它检查表是否存在的时候是用全小写去判断的,和前面的
SchemaIsValid方法不一致,我又认为修复方法应该是转为全小写判断了。。。我们再来看
LoadSchemaInfo方法,从代码来看它就是产生dbInfos的地方,而这个对象存放的是目标库的实际Schema信息,下面这段代码是重头戏:func LoadSchemaInfo( ctx context.Context, schemas []*mydump.MDDatabaseMeta, getTables func(context.Context, string) ([]*model.TableInfo, error), ) (map[string]*checkpoints.TidbDBInfo, error) { result := make(map[string]*checkpoints.TidbDBInfo, len(schemas)) for _, schema := range schemas { tables, err := getTables(ctx, schema.Name) if err != nil { return nil, err } tableMap := make(map[string]*model.TableInfo, len(tables)) for _, tbl := range tables { tableMap[tbl.Name.L] = tbl } dbInfo := &checkpoints.TidbDBInfo{ Name: schema.Name, Tables: make(map[string]*checkpoints.TidbTableInfo), } for _, tbl := range schema.Tables { tblInfo, ok := tableMap[strings.ToLower(tbl.Name)] if !ok { return nil, errors.Errorf("table '%s' schema not found", tbl.Name) } tableName := tblInfo.Name.String() if tblInfo.State != model.StatePublic { err := errors.Errorf("table [%s.%s] state is not public", schema.Name, tableName) metric.RecordTableCount(metric.TableStatePending, err) return nil, err } metric.RecordTableCount(metric.TableStatePending, err) if err != nil { return nil, errors.Trace(err) } tableInfo := &checkpoints.TidbTableInfo{ ID: tblInfo.ID, DB: schema.Name, Name: tableName, Core: tblInfo, } dbInfo.Tables[tableName] = tableInfo } result[schema.Name] = dbInfo } return result, nil }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
看到这里好像真相大白了,前半部分都一直用小写匹配,到取
tableName的时候貌似忘了这个事???最后看看
tblInfo.Name.String()返回的是啥:// CIStr is case insensitive string. type CIStr struct { O string `json:"O"` // Original string. L string `json:"L"` // Lower case string. } // String implements fmt.Stringer interface. func (cis CIStr) String() string { return cis.O }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这样来看,
SchemaIsValid其实是受到了LoadSchemaInfo的影响,给人一种能够区分大小写的假象。
我的修复思路
上面的分析过程也提到了我的修复思路的变化,汇总有以下两种办法:
第一种,在报错的地方做
nil值判断提示表结构不存在,但是碰到这个提示后是继续导入还是整个任务退出需要深度考虑一下,如果还有类似的问题是不是也这样去修复。第二种,整个逻辑全部转为全小写去判断,从根源上解决问题,这样的话我觉得有两个好处,一个是避免大小写引发新的bug,二是TiDB的表名本身就是不区分大小写。
接下来,我会按第二种方式提交PR尝试修复这个问题。
不过,针对这个bug我又想起了另一种情况,就是数据库表名是小写文件名是大写,我测试了会有相同的问题。
总结
在TiDB中给Schema对象命名的时候养成好习惯,统一使用小写,避免引起不必要的麻烦。
在使用Lightning的时候,不要轻易关闭
check-requirements,它会帮你提前预判很多风险,这点还是很重要的。从一些TiDB工具的使用经验上来看,它们的很多异常提示并不是很友好,这样会让用户多走弯路,希望官方能关注下这块的优化。
还有就是,碰到报错不要慌(实际上在客户现场的时候慌的一批),啃一啃源码也挺有意思的~
更多好方案也欢迎大家推荐,为TiDB生态助力。
-
相关阅读:
在uni-app中引入uView
[NOIP2002 普及组] 产生数
intel 一些偏门汇编指令总结
基于B/S架构的合同信息管理系统(Java+Web+MySQL)
阿里云轻量应用服务器流量价格表(计费/免费说明)
鸿蒙原生应用元服务-访问控制(权限)开发应用权限列表三
MySQL数据库基础操作
YOLOv5的Tricks | 【Trick10】从PyTorch Hub加载YOLOv5
css通过行内样式绑定背景图片
XPS测试分峰的基础操作-科学指南针
- 原文地址:https://blog.csdn.net/CBGCampus/article/details/126241619
