-
【GPU】Nvidia CUDA 编程中级教程——数据复制与计算的重叠
博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持!
博主链接本人就职于国际知名终端厂商,负责modem芯片研发。
在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。
博客内容主要围绕:
5G/6G协议讲解
算力网络讲解(云计算,边缘计算,端计算)
高级C语言讲解
Rust语言讲解数据复制与计算的重叠

CUDA 流简介
流是一个 GPU 操作序列,依发布顺序执行,CUDA 编程人员能创建并利用多个流。名为默认流的特殊流(此处标记为 stream0) ,其他所有流均称为非默认流(此处标记为 streams 1-3)。同一流中的操作将依发布顺序执行。然而,不同的非默认流中启动的操作并无固定的执行顺序。
非默认流的行为
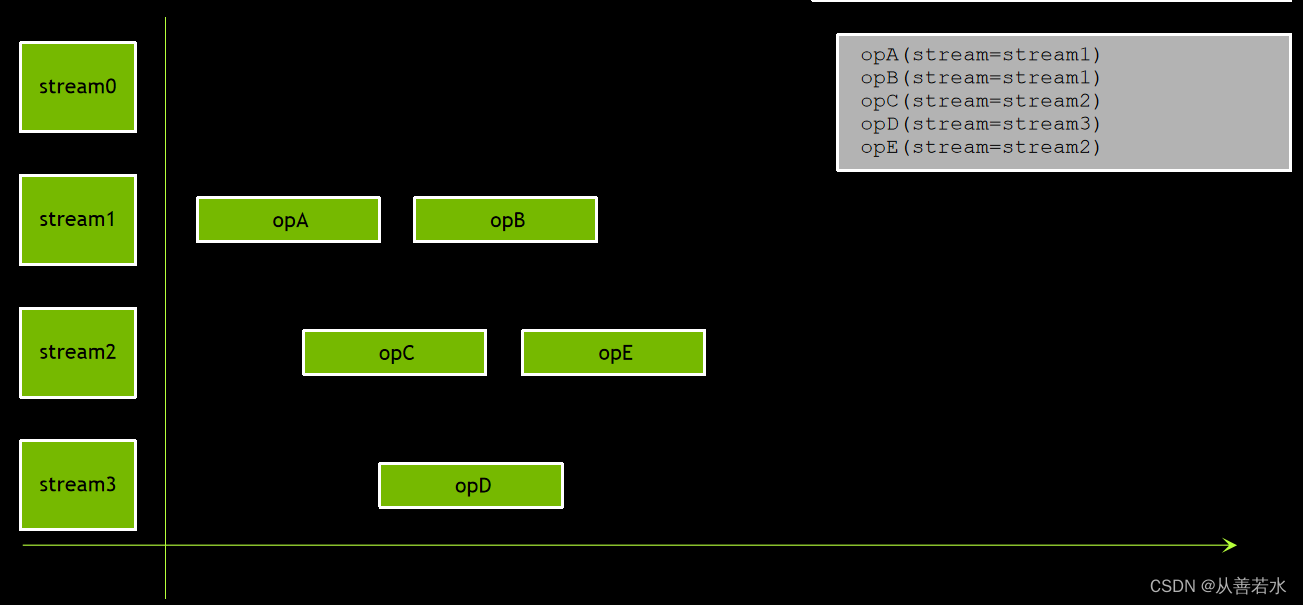
- 发布到同一流中的操作将依发布顺序执行
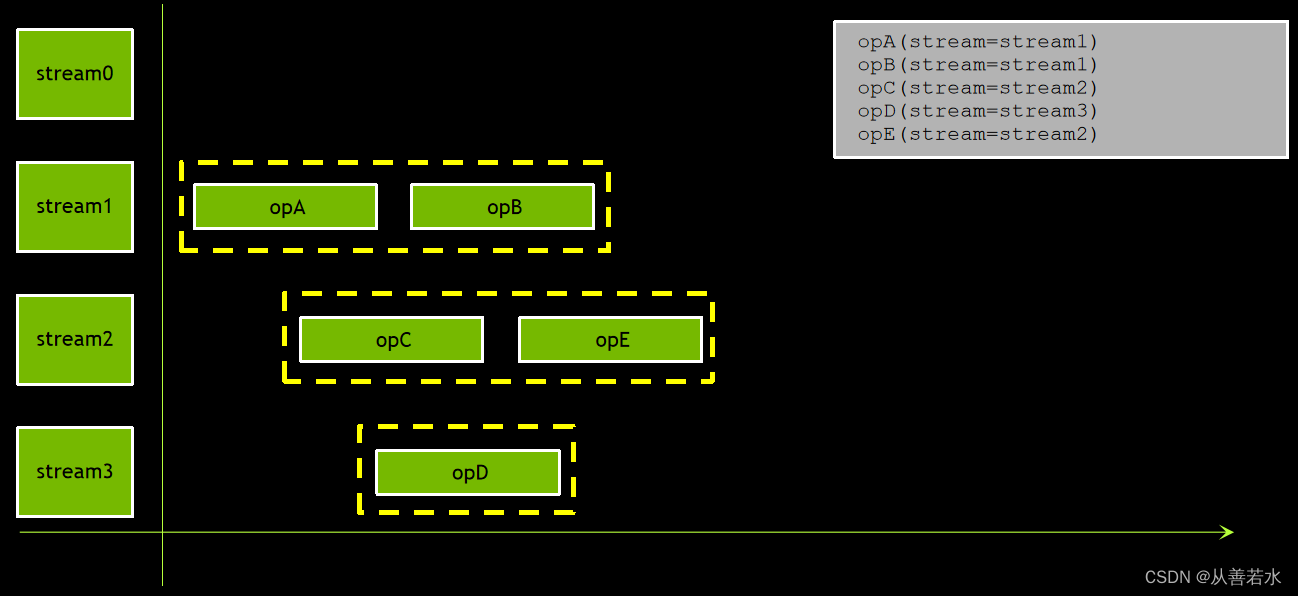
- 不同非默认流中的操作顺序不固定,例如可能是下面的几种情况:

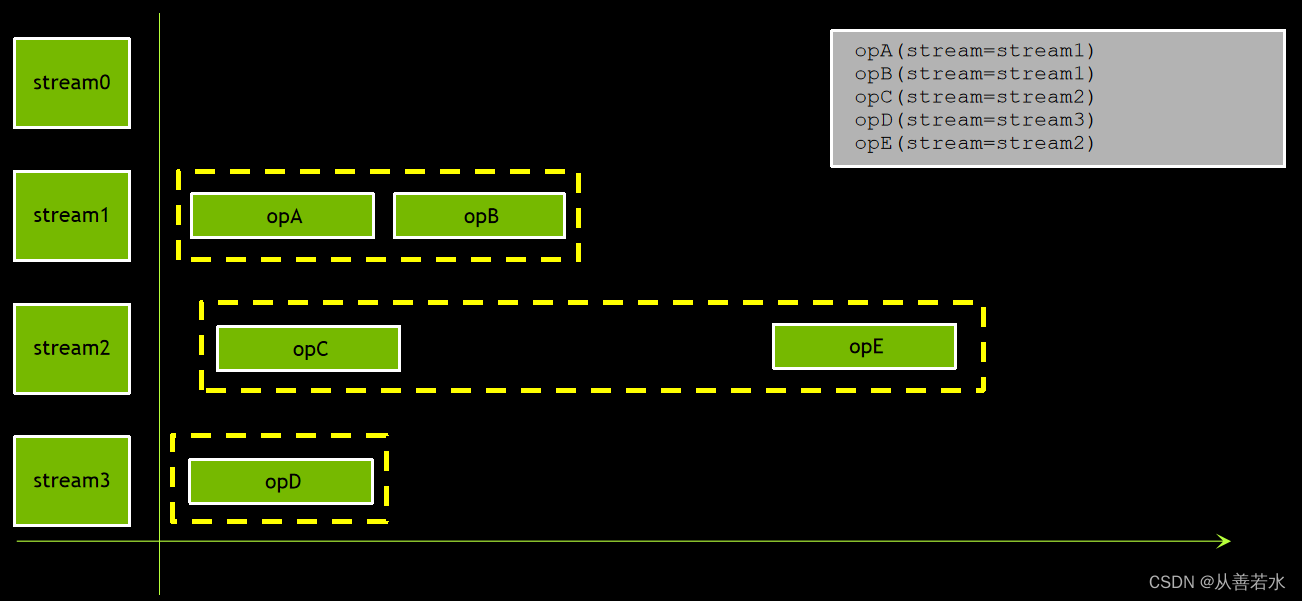
默认流的行为
默认流较为特殊。默认流中执行任何操作期间,任何非默认流中皆不可同时执行任何操作,默认流将等待非默认流全部执行完毕后再开始运行,而且在其执行完毕后,其他非默认流才能开始执行。
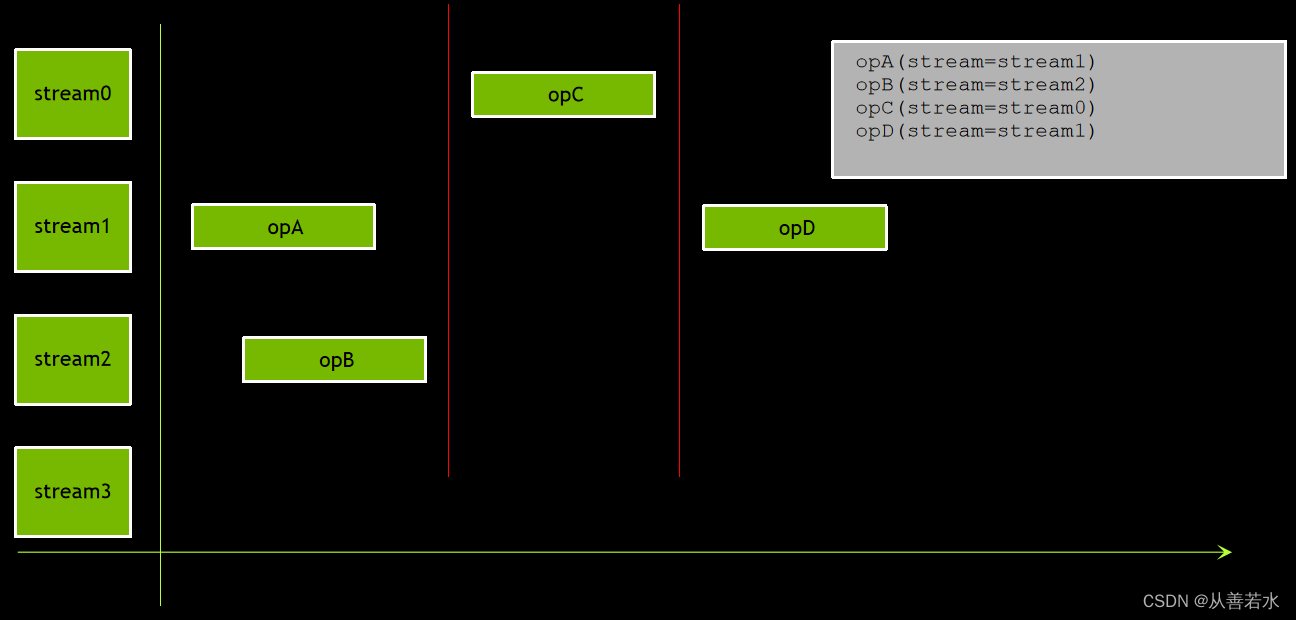
默认流与非默认流不会发生重叠。
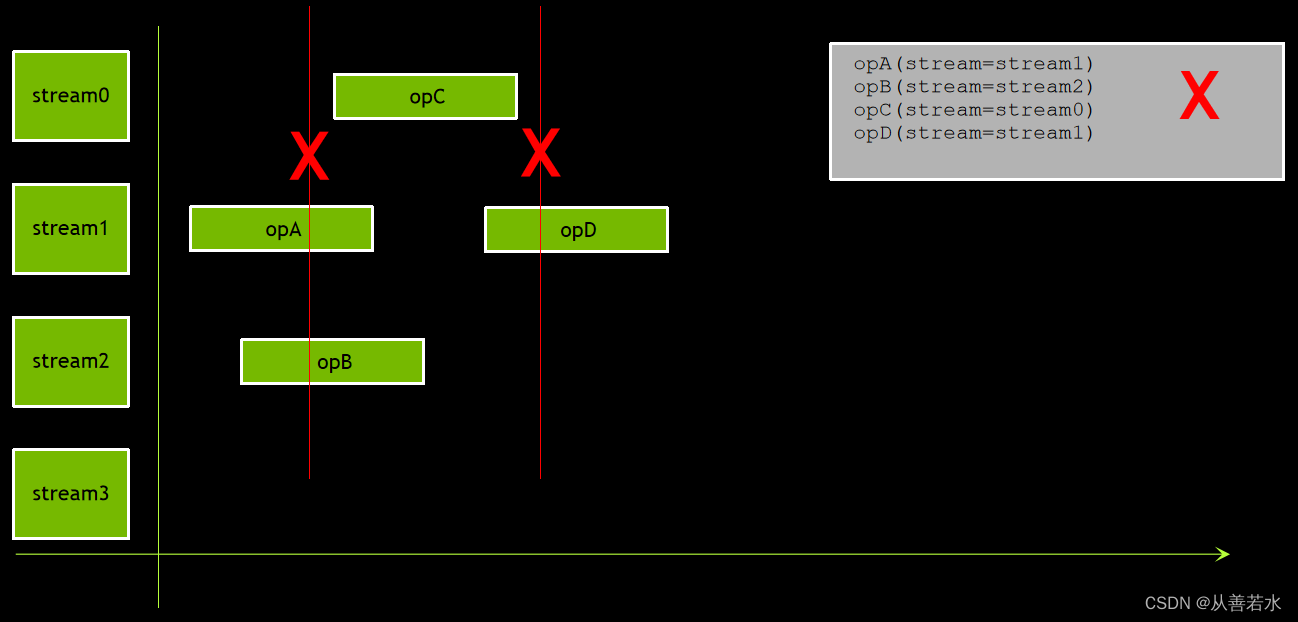
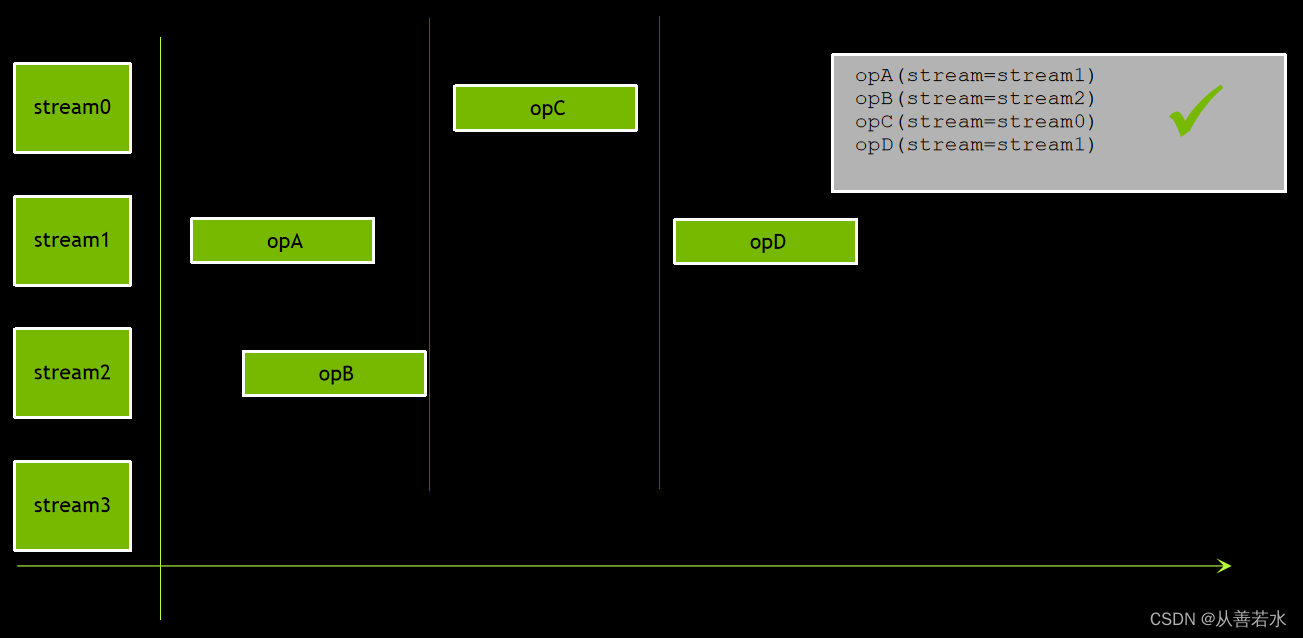
CUDA 编程中的流
许多 CUDA 运行时函数都需指定流参数,参数默认值均为 0,即默认流。核函数一律在流中启动,启动后,核函数默认值为 0,即默认流,可使用第 4 个启动配置参数,在非默认流中启动核函数,
kernel<<<grid, block, shared_memory, stream>>>()- 1
小练习:在非默认流中启动核函数
原始的code如下:
#include#include #include "helpers.cuh" #include "encryption.cuh" void encrypt_cpu(uint64_t * data, uint64_t num_entries, uint64_t num_iters, bool parallel=true) { #pragma omp parallel for if (parallel) for (uint64_t entry = 0; entry < num_entries; entry++) data[entry] = permute64(entry, num_iters); } __global__ void decrypt_gpu(uint64_t * data, uint64_t num_entries, uint64_t num_iters) { const uint64_t thrdID = blockIdx.x*blockDim.x+threadIdx.x; const uint64_t stride = blockDim.x*gridDim.x; for (uint64_t entry = thrdID; entry < num_entries; entry += stride) data[entry] = unpermute64(data[entry], num_iters); } bool check_result_cpu(uint64_t * data, uint64_t num_entries, bool parallel=true) { uint64_t counter = 0; #pragma omp parallel for reduction(+: counter) if (parallel) for (uint64_t entry = 0; entry < num_entries; entry++) counter += data[entry] == entry; return counter == num_entries; } int main (int argc, char * argv[]) { Timer timer; Timer overall; const uint64_t num_entries = 1UL << 26; const uint64_t num_iters = 1UL << 10; const bool openmp = true; timer.start(); uint64_t * data_cpu, * data_gpu; cudaMallocHost(&data_cpu, sizeof(uint64_t)*num_entries); cudaMalloc (&data_gpu, sizeof(uint64_t)*num_entries); timer.stop("allocate memory"); check_last_error(); timer.start(); encrypt_cpu(data_cpu, num_entries, num_iters, openmp); timer.stop("encrypt data on CPU"); overall.start(); timer.start(); cudaMemcpy(data_gpu, data_cpu, sizeof(uint64_t)*num_entries, cudaMemcpyHostToDevice); timer.stop("copy data from CPU to GPU"); check_last_error(); timer.start(); decrypt_gpu<<<80*32, 64>>>(data_gpu, num_entries, num_iters); timer.stop("decrypt data on GPU"); check_last_error(); timer.start(); cudaMemcpy(data_cpu, data_gpu, sizeof(uint64_t)*num_entries, cudaMemcpyDeviceToHost); timer.stop("copy data from GPU to CPU"); overall.stop("total time on GPU"); check_last_error(); timer.start(); const bool success = check_result_cpu(data_cpu, num_entries, openmp); std::cout << "STATUS: test " << ( success ? "passed" : "failed") << std::endl; timer.stop("checking result on CPU"); timer.start(); cudaFreeHost(data_cpu); cudaFree (data_gpu); timer.stop("free memory"); check_last_error(); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
解决方案如下:
#include#include #include "helpers.cuh" #include "encryption.cuh" void encrypt_cpu(uint64_t * data, uint64_t num_entries, uint64_t num_iters, bool parallel=true) { #pragma omp parallel for if (parallel) for (uint64_t entry = 0; entry < num_entries; entry++) data[entry] = permute64(entry, num_iters); } __global__ void decrypt_gpu(uint64_t * data, uint64_t num_entries, uint64_t num_iters) { const uint64_t thrdID = blockIdx.x*blockDim.x+threadIdx.x; const uint64_t stride = blockDim.x*gridDim.x; for (uint64_t entry = thrdID; entry < num_entries; entry += stride) data[entry] = unpermute64(data[entry], num_iters); } bool check_result_cpu(uint64_t * data, uint64_t num_entries, bool parallel=true) { uint64_t counter = 0; #pragma omp parallel for reduction(+: counter) if (parallel) for (uint64_t entry = 0; entry < num_entries; entry++) counter += data[entry] == entry; return counter == num_entries; } int main (int argc, char * argv[]) { Timer timer; Timer overall; const uint64_t num_entries = 1UL << 26; const uint64_t num_iters = 1UL << 10; const bool openmp = true; timer.start(); uint64_t * data_cpu, * data_gpu; cudaMallocHost(&data_cpu, sizeof(uint64_t)*num_entries); cudaMalloc (&data_gpu, sizeof(uint64_t)*num_entries); timer.stop("allocate memory"); check_last_error(); timer.start(); encrypt_cpu(data_cpu, num_entries, num_iters, openmp); timer.stop("encrypt data on CPU"); overall.start(); timer.start(); cudaMemcpy(data_gpu, data_cpu, sizeof(uint64_t)*num_entries, cudaMemcpyHostToDevice); timer.stop("copy data from CPU to GPU"); check_last_error(); timer.start(); // Create non-default stream. cudaStream_t stream; cudaStreamCreate(&stream); // Launch kernel in non-default stream. decrypt_gpu<<<80*32, 64, 0, stream>>>(data_gpu, num_entries, num_iters); // Destroy non-default stream. cudaStreamDestroy(stream); timer.stop("decrypt data on GPU"); check_last_error(); timer.start(); cudaMemcpy(data_cpu, data_gpu, sizeof(uint64_t)*num_entries, cudaMemcpyDeviceToHost); timer.stop("copy data from GPU to CPU"); overall.stop("total time on GPU"); check_last_error(); timer.start(); const bool success = check_result_cpu(data_cpu, num_entries, openmp); std::cout << "STATUS: test " << ( success ? "passed" : "failed") << std::endl; timer.stop("checking result on CPU"); timer.start(); cudaFreeHost(data_cpu); cudaFree (data_gpu); timer.stop("free memory"); check_last_error(); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
重点函数讲解:
- 创建非默认流:要创建新的非默认流,请向 cudaStreamCreate 传递一个 cudaStream_t 指针:
cudaStream_t stream; cudaStreamCreate(&stream);- 1
- 2
- 在非默认流中启动核函数:要在非默认流中启动核函数,请传递一个非默认流标识符作为该函数的第 4 个启动配置参数。由于核函数的第 3 个启动配置参数定义了动态分配的共享内存,因此如果您不打算修改其默认值,则可能需向其传递 0(其默认值):
cudaStream_t stream; cudaStreamCreate(&stream); kernel<<<grid, blocks, 0, stream>>>();- 1
- 2
- 3
- 4
- 销毁非默认流:完成相关操作后,您可以向 cudaStreamDestroy 传递一个非默认流标识符来销毁非默认流:
cudaStream_t stream; cudaStreamCreate(&stream); kernel<<<grid, blocks, 0, stream>>>(); cudaStreamDestroy(stream);- 1
- 2
- 3
- 4
- 5
- 6
非默认流中的内存复制
分配固定内存
- 为了要异步复制数据,CUDA 需对其位置作出假设。典型的主机内存使用 分页技术,这样除了 RAM 之外,数据还可存储在某个备份存储设备上(如物理磁盘)。
- 固定(或锁页)内存会绕过主机操作系统分页,在 RAM 中存储所分配的内存。在非默认流中异步传输内存时,必须使用锁页(或固定)内存。
- 固定内存会阻止将数据存储在某个备份存储设备上,因此是一个受限资源,请务必当心不要过度使用它。
固定主机内存通过 cudaMallocHost 进行分配:
const uint64_t num_entries = 1UL << 26; uint64_t *data_cpu; cudaMallocHost(&data_cpu, sizeof(uint64_t)*num_entries);- 1
- 2
- 3
非默认流中主机到设备的内存传输
通过使用类似于
cudaMemcpy的cudaMemcpyAsync,您可在非默认流中将固定主机内存传输到 GPU 显存,但需提供第 5 个流标识符参数:cudaStream_t stream; cudaStreamCreate(&stream); const uint64_t num_entries = 1UL << 26; uint64_t *data_cpu, *data_gpu; cudaMallocHost(&data_cpu, sizeof(uint64_t)*num_entries); cudaMalloc(&data_gpu, sizeof(uint64_t)*num_entries); cudaMemcpyAsync(data_gpu, data_cpu, sizeof(uint64_t)*num_entries, cudaMemcpyHostToDevice, stream);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
非默认流中设备到主机的内存传输
通过使用
cudaMemcpyAsync,您也可在非默认流中将 GPU 显存传输到固定主机内存:// Assume data is already present on the GPU, and that `data_cpu` is pinned. cudaMemcpyAsync(data_cpu, data_gpu, sizeof(uint64_t)*num_entries, cudaMemcpyDeviceToHost, stream);- 1
- 2
- 3
- 4
- 5
- 6
- 7
与所有现代 GPU 一样,具有 2 个或更多复制引擎的 GPU 设备可以同时在不同的非默认流中执行主机到设备和设备到主机的内存传输。
流同步
使用
cudaStreamSynchronize可导致主机代码阻塞,直到给定的流完成其操作为止。 当需要保证完成流工作时,例如,当主机代码需要等待非默认流中的异步内存传输完成时,应使用流同步:// Assume data is already present on the GPU, and that `data_cpu` is pinned. cudaMemcpyAsync(data_cpu, data_gpu, sizeof(uint64_t)*num_entries, cudaMemcpyDeviceToHost, stream); // Block until work (in this case memory transfer to host) in `stream` is complete. cudaStreamSyncronize(stream); // `data_cpu` transfer to host via `stream` is now guaranteed to be complete. checkResultCpu(data_cpu);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
小练习:在非默认流中执行内存传输
原始code如下:
#include#include #include "helpers.cuh" #include "encryption.cuh" void encrypt_cpu(uint64_t * data, uint64_t num_entries, uint64_t num_iters, bool parallel=true) { #pragma omp parallel for if (parallel) for (uint64_t entry = 0; entry < num_entries; entry++) data[entry] = permute64(entry, num_iters); } __global__ void decrypt_gpu(uint64_t * data, uint64_t num_entries, uint64_t num_iters) { const uint64_t thrdID = blockIdx.x*blockDim.x+threadIdx.x; const uint64_t stride = blockDim.x*gridDim.x; for (uint64_t entry = thrdID; entry < num_entries; entry += stride) data[entry] = unpermute64(data[entry], num_iters); } bool check_result_cpu(uint64_t * data, uint64_t num_entries, bool parallel=true) { uint64_t counter = 0; #pragma omp parallel for reduction(+: counter) if (parallel) for (uint64_t entry = 0; entry < num_entries; entry++) counter += data[entry] == entry; return counter == num_entries; } int main (int argc, char * argv[]) { Timer timer; Timer overall; const uint64_t num_entries = 1UL << 26; const uint64_t num_iters = 1UL << 10; const bool openmp = true; timer.start(); uint64_t * data_cpu, * data_gpu; cudaMallocHost(&data_cpu, sizeof(uint64_t)*num_entries); cudaMalloc (&data_gpu, sizeof(uint64_t)*num_entries); timer.stop("allocate memory"); check_last_error(); timer.start(); encrypt_cpu(data_cpu, num_entries, num_iters, openmp); timer.stop("encrypt data on CPU"); overall.start(); timer.start(); cudaMemcpy(data_gpu, data_cpu, sizeof(uint64_t)*num_entries, cudaMemcpyHostToDevice); timer.stop("copy data from CPU to GPU"); check_last_error(); timer.start(); decrypt_gpu<<<80*32, 64>>>(data_gpu, num_entries, num_iters); timer.stop("decrypt data on GPU"); check_last_error(); timer.start(); cudaMemcpy(data_cpu, data_gpu, sizeof(uint64_t)*num_entries, cudaMemcpyDeviceToHost); timer.stop("copy data from GPU to CPU"); overall.stop("total time on GPU"); check_last_error(); timer.start(); const bool success = check_result_cpu(data_cpu, num_entries, openmp); std::cout << "STATUS: test " << ( success ? "passed" : "failed") << std::endl; timer.stop("checking result on CPU"); timer.start(); cudaFreeHost(data_cpu); cudaFree (data_gpu); timer.stop("free memory"); check_last_error(); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
优化后的代码如下:
#include#include #include "helpers.cuh" #include "encryption.cuh" void encrypt_cpu(uint64_t * data, uint64_t num_entries, uint64_t num_iters, bool parallel=true) { #pragma omp parallel for if (parallel) for (uint64_t entry = 0; entry < num_entries; entry++) data[entry] = permute64(entry, num_iters); } __global__ void decrypt_gpu(uint64_t * data, uint64_t num_entries, uint64_t num_iters) { const uint64_t thrdID = blockIdx.x*blockDim.x+threadIdx.x; const uint64_t stride = blockDim.x*gridDim.x; for (uint64_t entry = thrdID; entry < num_entries; entry += stride) data[entry] = unpermute64(data[entry], num_iters); } bool check_result_cpu(uint64_t * data, uint64_t num_entries, bool parallel=true) { uint64_t counter = 0; #pragma omp parallel for reduction(+: counter) if (parallel) for (uint64_t entry = 0; entry < num_entries; entry++) counter += data[entry] == entry; return counter == num_entries; } int main (int argc, char * argv[]) { Timer timer; Timer overall; const uint64_t num_entries = 1UL << 26; const uint64_t num_iters = 1UL << 10; const bool openmp = true; timer.start(); uint64_t * data_cpu, * data_gpu; // Host memory is page-locked/pinned. cudaMallocHost(&data_cpu, sizeof(uint64_t)*num_entries); cudaMalloc (&data_gpu, sizeof(uint64_t)*num_entries); timer.stop("allocate memory"); check_last_error(); timer.start(); encrypt_cpu(data_cpu, num_entries, num_iters, openmp); timer.stop("encrypt data on CPU"); overall.start(); timer.start(); // Create non-default stream. cudaStream_t stream; cudaStreamCreate(&stream); // Async host-to-device copy in non-default stream. cudaMemcpyAsync(data_gpu, data_cpu, sizeof(uint64_t)*num_entries, cudaMemcpyHostToDevice, stream); timer.stop("copy data from CPU to GPU"); check_last_error(); timer.start(); decrypt_gpu<<<80*32, 64>>>(data_gpu, num_entries, num_iters); timer.stop("decrypt data on GPU"); check_last_error(); timer.start(); // Async device-to-host copy in non-default stream. cudaMemcpyAsync(data_cpu, data_gpu, sizeof(uint64_t)*num_entries, cudaMemcpyDeviceToHost, stream); // Wait for memory transfer to complete before proceeding. cudaStreamSynchronize(stream); // Clean up non-default stream. cudaStreamDestroy(stream); timer.stop("copy data from GPU to CPU"); overall.stop("total time on GPU"); check_last_error(); timer.start(); const bool success = check_result_cpu(data_cpu, num_entries, openmp); std::cout << "STATUS: test " << ( success ? "passed" : "failed") << std::endl; timer.stop("checking result on CPU"); timer.start(); cudaFreeHost(data_cpu); cudaFree (data_gpu); timer.stop("free memory"); check_last_error(); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
数据复制与计算重叠的注意事项
使用流将复制和计算进行重叠
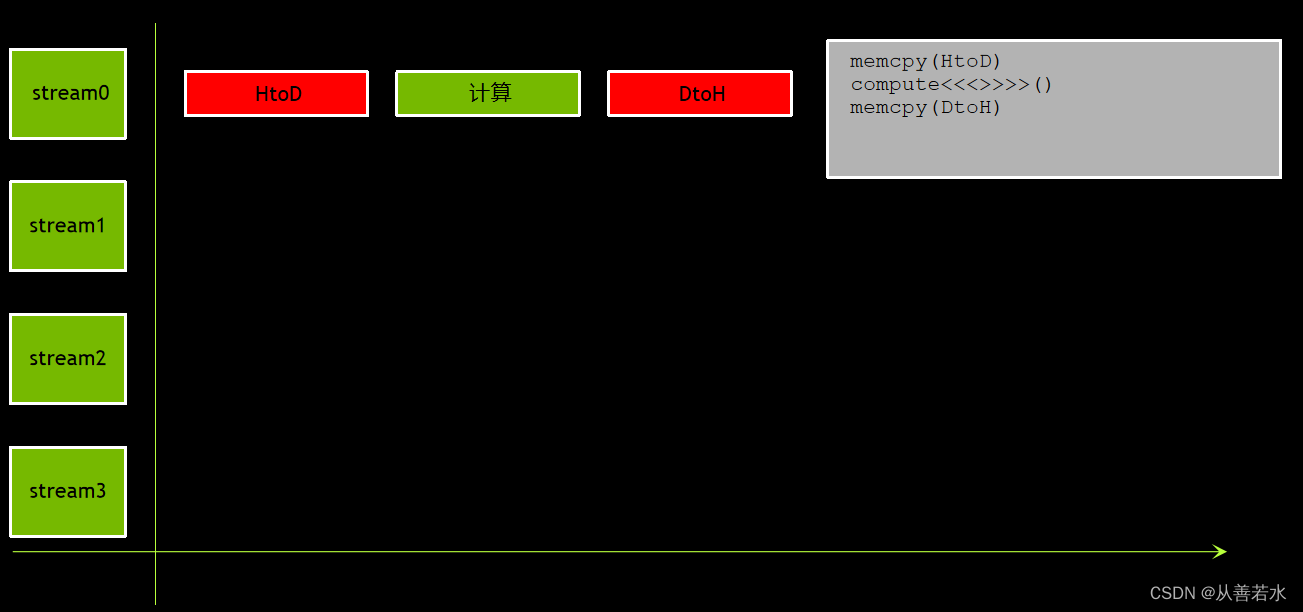
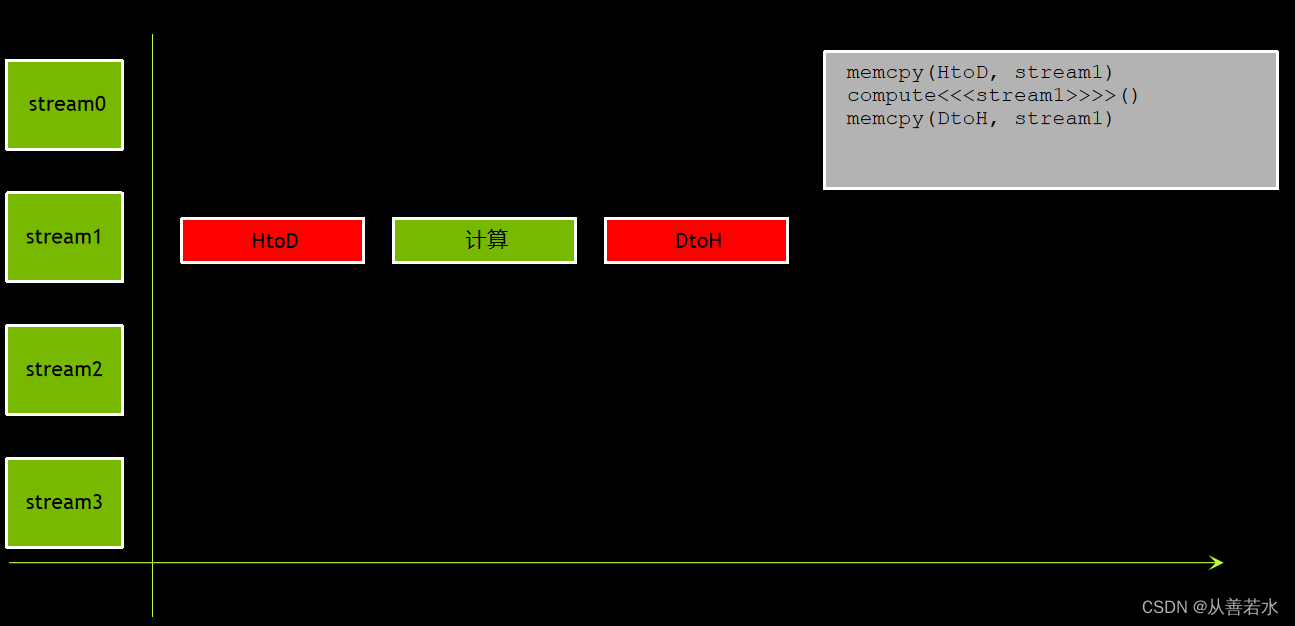
通过使用默认流,典型的三步式 CUDA 程序会顺次执行 HtoD 复制、计算和 DtoH 复制(为便于演示,下面的图片中使用简略代码),如下图:
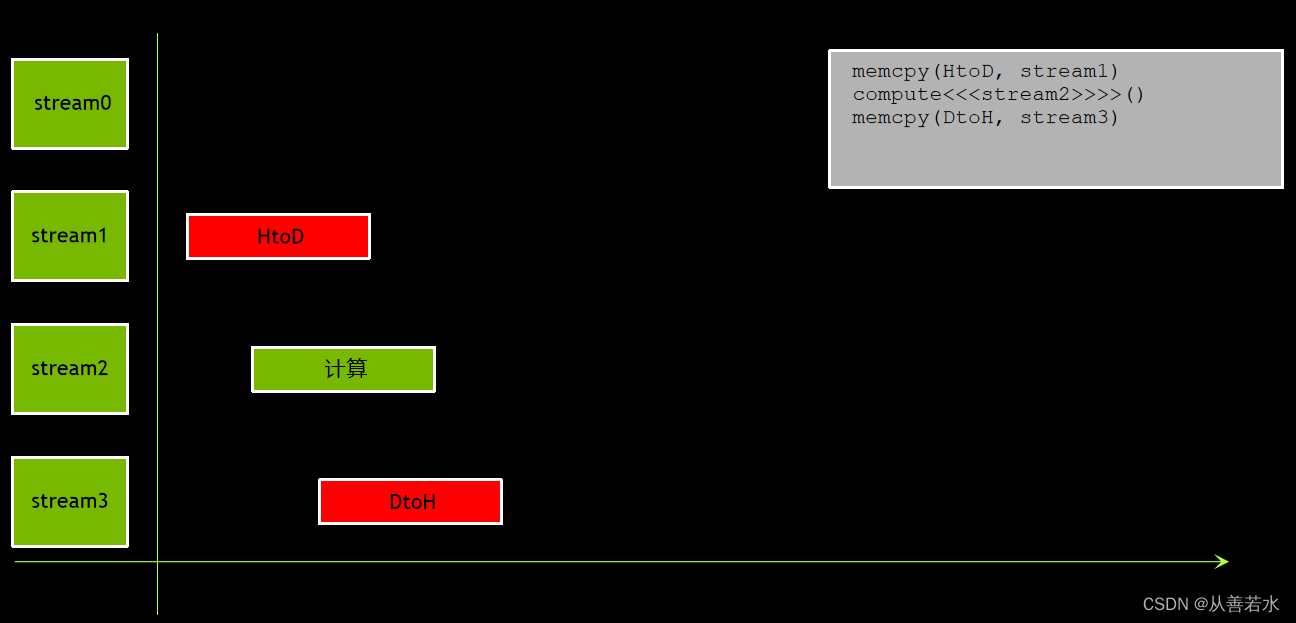
我们或许可以采用一种初级做法:简单地将这三个操作逐一发布在不同的非默认流中,如下图:
这可行吗?
不可行回忆一下,非默认流中的操作顺序不固定,因此可能会出现这种情况:
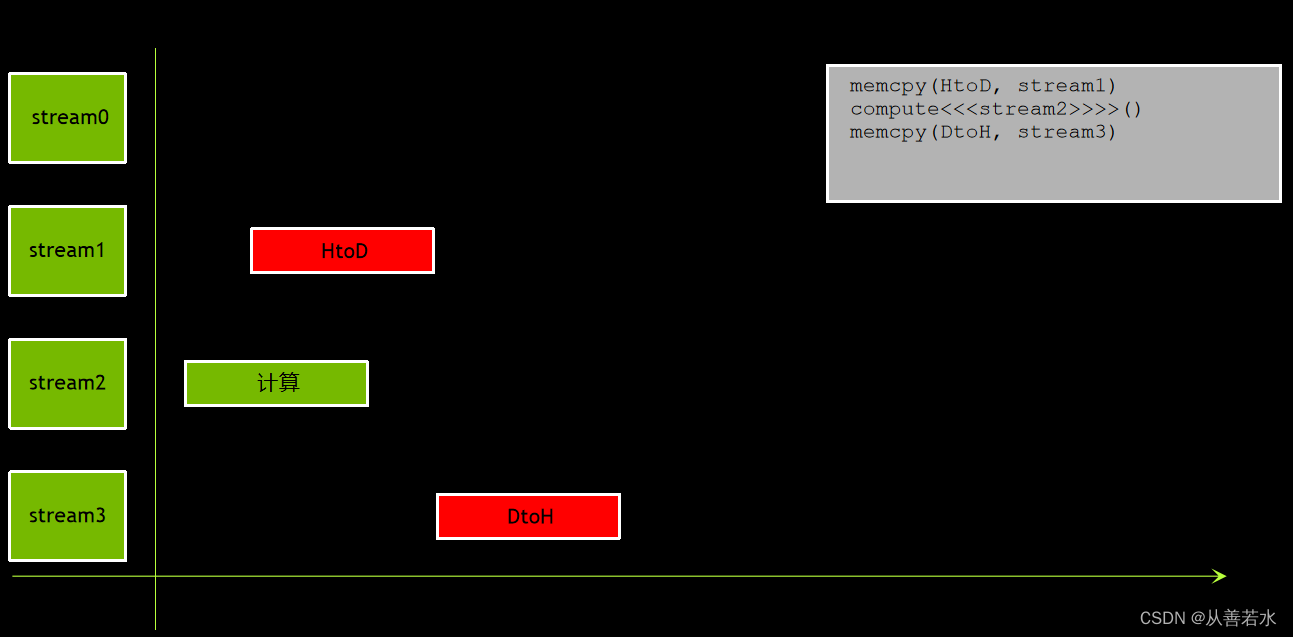
在其所需的数据传输到 GPU 之前,计算可能便会开始,
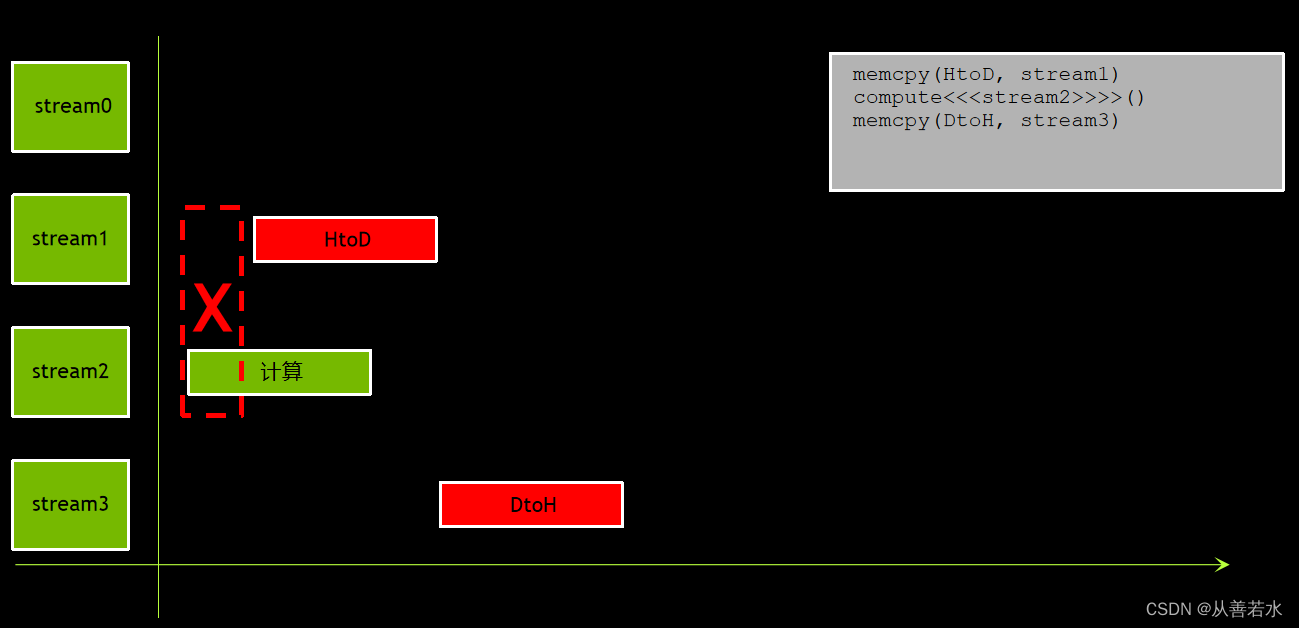
我们还可采用另一种初级做法:将所有操作全部发布在同一个非默认流中,以确保数据和计算的顺序,
但这样做与使用默认流没有区别,结果是依然没有重叠。
思考一下,如果采用现有程序并将数据分为 2 块
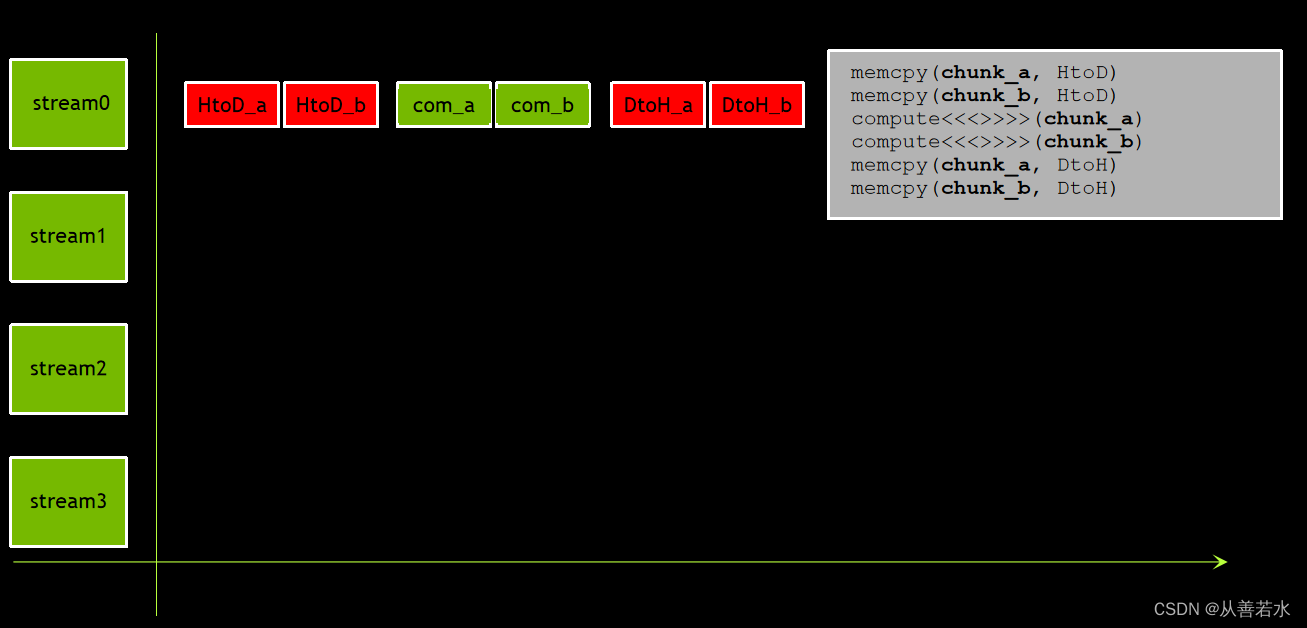
如果现将针对每个数据块的所有操作移至其各自独立的非默认流,数据和计算顺序得以保持,同时能够实现部分重叠。
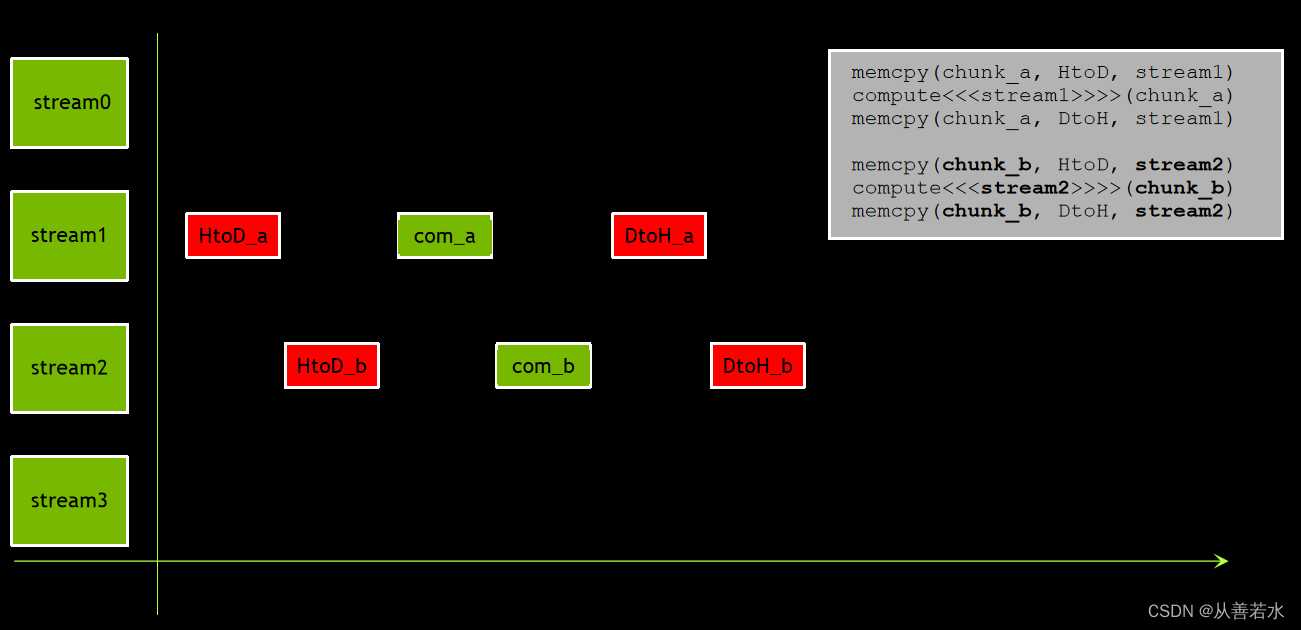

根据假设,通过增加数据块数量,重叠效果可能更好。要获得理想的分块数量,最好的途径是观察程序性能。

复制和计算重叠索引
将数据分块以在多个流中使用时,索引可能较为棘手。让我们通过几个示例了解一下如何进行索引。首先为所有数据块分配所需数据,为使示例更加清晰,我们使用了较小规模的数据。
- 为CPU和GPU分配内存(N表示总的数据量);
cudaMallocHost(&data_cpu, N) cudaMalloc(&data_gpu, N)- 1
- 2
- 接下来,定义流的数量,并通过执行循环代码以数组形式创建和收集流(此处定义的流的数量为2);
num_streams = 2 for stream_i in num_streams cudaStreamCreate(stream) streams[stream_i] = stream- 1
- 2
- 3
- 4
- 每个数据块的大小取决于数据条目的数量以及流的数量;
chunk_size = N / num_streams- 1
- 每个流需要处理一个数据块,我们需要计算其在整个数据集中的索引。为此,我们将遍历流的数量,从 0 开始然后乘以数据块大小。从 lower 索引开始,并使用一个数据块大小的数据,如此即可从全部数据中获得流数据,此方法将会应用至每一个 stream_i;
for stream_i in num_streams lower = chunk_size*stream_i- 1
- 2
- 计算完这些值后,我们现在即可执行非默认流 HtoD 内存复制;
cudaMemcpyAsync( data_cpu+lower, data_gpu+lower, sizeof(uint64_t)*chunk_size, cudaMemcpyHostToDevice, streams[stream_i] )- 1
- 2
- 3
- 4
- 5
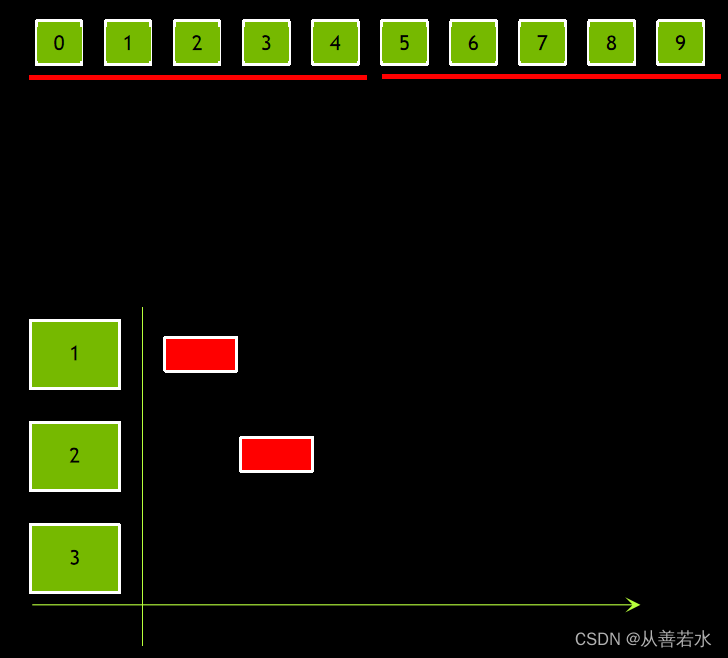
上面的示例中,N 被流数量整除。如果不能整除呢?为解决该问题,我们使用向上取整的除法运算来计算数据块大小。但是这还是会有问题,如下图:

我们确实可以访问所有数据,但又产生了新问题:对于最后一个数据块而言,数据块大小过大。
解决方法如下:
- 为每个数据块计算 upper 索引(不得超过 N);
upper = min(lower+chunk_size, N)- 1
- 然后使用 upper 和 lower 计算数据块 width;
width = upper - lower- 1
- 现在使用 width 而非数据块大小进行迭代;
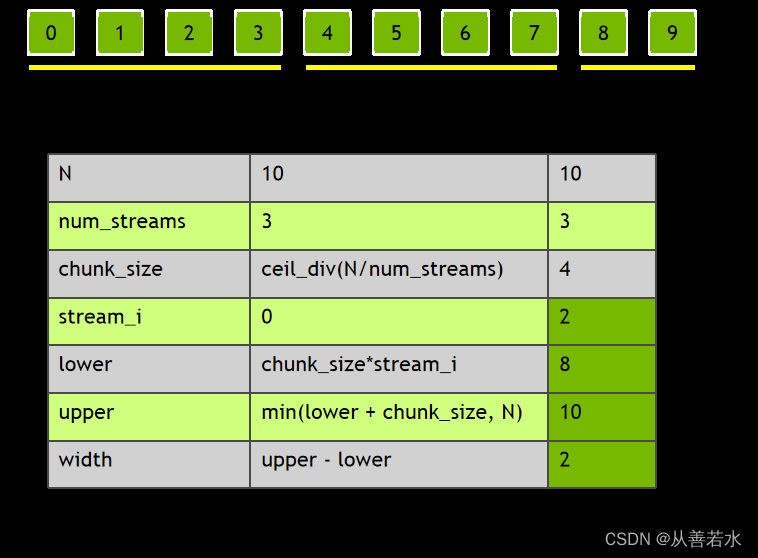
这样我们就能完美适配数据,而不受其大小或流数量的影响。
复制与计算重叠的代码示例
下面是上述方法的两个代码示例,第一个示例适用于数据的条目数能被流的数量整除的情况,第二个示例则是不能整除的情况。
N可被流的数量整除
// "Simple" version where number of entries is evenly divisible by number of streams. // Set to a ridiculously low value to clarify mechanisms of the technique. const uint64_t num_entries = 10; const uint64_t num_iters = 1UL << 10; // Allocate memory for all data entries. Make sure to pin host memory. cudaMallocHost(&data_cpu, sizeof(uint64_t)*num_entries); cudaMalloc (&data_gpu, sizeof(uint64_t)*num_entries); // Set the number of streams. const uint64_t num_streams = 2; // Create an array of streams containing number of streams cudaStream_t streams[num_streams]; for (uint64_t stream = 0; stream < num_streams; stream++) cudaStreamCreate(&streams[stream]); // Set number of entries for each "chunk". Assumes `num_entires % num_streams == 0`. const uint64_t chunk_size = num_entries / num_streams; // For each stream, calculate indices for its chunk of full dataset and then, HtoD copy, compute, DtoH copy. for (uint64_t stream = 0; stream < num_streams; stream++) { // Get start index in full dataset for this stream's work. const uint64_t lower = chunk_size*stream; // Stream-indexed (`data+lower`) and chunk-sized HtoD copy in the non-default stream // `streams[stream]`. cudaMemcpyAsync(data_gpu+lower, data_cpu+lower, sizeof(uint64_t)*chunk_size, cudaMemcpyHostToDevice, streams[stream]); // Stream-indexed (`data_gpu+lower`) and chunk-sized compute in the non-default stream // `streams[stream]`. decrypt_gpu<<<80*32, 64, 0, streams[stream]>>> (data_gpu+lower, chunk_size, num_iters); // Stream-indexed (`data+lower`) and chunk-sized DtoH copy in the non-default stream // `streams[stream]`. cudaMemcpyAsync(data_cpu+lower, data_gpu+lower, sizeof(uint64_t)*chunk_size, cudaMemcpyDeviceToHost, streams[stream]); } // Destroy streams. for (uint64_t stream = 0; stream < num_streams; stream++) cudaStreamDestroy(streams[stream]);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
N不可被流的数量整除
// Able to handle when `num_entries % num_streams != 0`. const uint64_t num_entries = 10; const uint64_t num_iters = 1UL << 10; cudaMallocHost(&data_cpu, sizeof(uint64_t)*num_entries); cudaMalloc (&data_gpu, sizeof(uint64_t)*num_entries); // Set the number of streams to not evenly divide num_entries. const uint64_t num_streams = 3; cudaStream_t streams[num_streams]; for (uint64_t stream = 0; stream < num_streams; stream++) cudaStreamCreate(&streams[stream]); // Use round-up division (`sdiv`, defined in helper.cu) so `num_streams*chunk_size` // is never less than `num_entries`. // This can result in `num_streams*chunk_size` being greater than `num_entries`, meaning // we will need to guard against out-of-range errors in the final "tail" stream (see below). const uint64_t chunk_size = sdiv(num_entries, num_streams); for (uint64_t stream = 0; stream < num_streams; stream++) { const uint64_t lower = chunk_size*stream; // For tail stream `lower+chunk_size` could be out of range, so here we guard against that. const uint64_t upper = min(lower+chunk_size, num_entries); // Since the tail stream width may not be `chunk_size`, // we need to calculate a separate `width` value. const uint64_t width = upper-lower; // Use `width` instead of `chunk_size`. cudaMemcpyAsync(data_gpu+lower, data_cpu+lower, sizeof(uint64_t)*width, cudaMemcpyHostToDevice, streams[stream]); // Use `width` instead of `chunk_size`. decrypt_gpu<<<80*32, 64, 0, streams[stream]>>> (data_gpu+lower, width, num_iters); // Use `width` instead of `chunk_size`. cudaMemcpyAsync(data_cpu+lower, data_gpu+lower, sizeof(uint64_t)*width, cudaMemcpyDeviceToHost, streams[stream]); } // Destroy streams. for (uint64_t stream = 0; stream < num_streams; stream++) cudaStreamDestroy(streams[stream]);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
练习:应用数据复制与计算的重叠
原始code如下:
#include#include #include "helpers.cuh" #include "encryption.cuh" void encrypt_cpu(uint64_t * data, uint64_t num_entries, uint64_t num_iters, bool parallel=true) { #pragma omp parallel for if (parallel) for (uint64_t entry = 0; entry < num_entries; entry++) data[entry] = permute64(entry, num_iters); } __global__ void decrypt_gpu(uint64_t * data, uint64_t num_entries, uint64_t num_iters) { const uint64_t thrdID = blockIdx.x*blockDim.x+threadIdx.x; const uint64_t stride = blockDim.x*gridDim.x; for (uint64_t entry = thrdID; entry < num_entries; entry += stride) data[entry] = unpermute64(data[entry], num_iters); } bool check_result_cpu(uint64_t * data, uint64_t num_entries, bool parallel=true) { uint64_t counter = 0; #pragma omp parallel for reduction(+: counter) if (parallel) for (uint64_t entry = 0; entry < num_entries; entry++) counter += data[entry] == entry; return counter == num_entries; } int main (int argc, char * argv[]) { Timer timer; Timer overall; const uint64_t num_entries = 1UL << 26; const uint64_t num_iters = 1UL << 10; const bool openmp = true; timer.start(); uint64_t * data_cpu, * data_gpu; cudaMallocHost(&data_cpu, sizeof(uint64_t)*num_entries); cudaMalloc (&data_gpu, sizeof(uint64_t)*num_entries); timer.stop("allocate memory"); check_last_error(); timer.start(); encrypt_cpu(data_cpu, num_entries, num_iters, openmp); timer.stop("encrypt data on CPU"); overall.start(); timer.start(); cudaMemcpy(data_gpu, data_cpu, sizeof(uint64_t)*num_entries, cudaMemcpyHostToDevice); timer.stop("copy data from CPU to GPU"); check_last_error(); timer.start(); decrypt_gpu<<<80*32, 64>>>(data_gpu, num_entries, num_iters); timer.stop("decrypt data on GPU"); check_last_error(); timer.start(); cudaMemcpy(data_cpu, data_gpu, sizeof(uint64_t)*num_entries, cudaMemcpyDeviceToHost); timer.stop("copy data from GPU to CPU"); overall.stop("total time on GPU"); check_last_error(); timer.start(); const bool success = check_result_cpu(data_cpu, num_entries, openmp); std::cout << "STATUS: test " << ( success ? "passed" : "failed") << std::endl; timer.stop("checking result on CPU"); timer.start(); cudaFreeHost(data_cpu); cudaFree (data_gpu); timer.stop("free memory"); check_last_error(); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
优化后的code如下:
#include#include #include "helpers.cuh" #include "encryption.cuh" void encrypt_cpu(uint64_t * data, uint64_t num_entries, uint64_t num_iters, bool parallel=true) { #pragma omp parallel for if (parallel) for (uint64_t entry = 0; entry < num_entries; entry++) data[entry] = permute64(entry, num_iters); } __global__ void decrypt_gpu(uint64_t * data, uint64_t num_entries, uint64_t num_iters) { const uint64_t thrdID = blockIdx.x*blockDim.x+threadIdx.x; const uint64_t stride = blockDim.x*gridDim.x; for (uint64_t entry = thrdID; entry < num_entries; entry += stride) data[entry] = unpermute64(data[entry], num_iters); } bool check_result_cpu(uint64_t * data, uint64_t num_entries, bool parallel=true) { uint64_t counter = 0; #pragma omp parallel for reduction(+: counter) if (parallel) for (uint64_t entry = 0; entry < num_entries; entry++) counter += data[entry] == entry; return counter == num_entries; } int main (int argc, char * argv[]) { Timer timer; Timer overall; const uint64_t num_entries = 1UL << 26; const uint64_t num_iters = 1UL << 10; const bool openmp = true; // Define the number of streams. const uint64_t num_streams = 32; // Use round-up division to calculate chunk size. const uint64_t chunk_size = sdiv(num_entries, num_streams); timer.start(); uint64_t * data_cpu, * data_gpu; cudaMallocHost(&data_cpu, sizeof(uint64_t)*num_entries); cudaMalloc (&data_gpu, sizeof(uint64_t)*num_entries); timer.stop("allocate memory"); check_last_error(); timer.start(); encrypt_cpu(data_cpu, num_entries, num_iters, openmp); timer.stop("encrypt data on CPU"); timer.start(); // Create array for storing streams. cudaStream_t streams[num_streams]; // Create number of streams and store in array. for (uint64_t stream = 0; stream < num_streams; stream++) cudaStreamCreate(&streams[stream]); timer.stop("create streams"); check_last_error(); overall.start(); timer.start(); // For each stream... for (uint64_t stream = 0; stream < num_streams; stream++) { // ...calculate index into global data (`lower`) and size of data for it to process (`width`). const uint64_t lower = chunk_size*stream; const uint64_t upper = min(lower+chunk_size, num_entries); const uint64_t width = upper-lower; // ...copy stream's chunk to device. cudaMemcpyAsync(data_gpu+lower, data_cpu+lower, sizeof(uint64_t)*width, cudaMemcpyHostToDevice, streams[stream]); // ...compute stream's chunk. decrypt_gpu<<<80*32, 64, 0, streams[stream]>>> (data_gpu+lower, width, num_iters); // ...copy stream's chunk to host. cudaMemcpyAsync(data_cpu+lower, data_gpu+lower, sizeof(uint64_t)*width, cudaMemcpyDeviceToHost, streams[stream]); } for (uint64_t stream = 0; stream < num_streams; stream++) // Synchronize streams before checking results on host. cudaStreamSynchronize(streams[stream]); // Note modification of timer instance use. timer.stop("asynchronous H2D->kernel->D2H"); overall.stop("total time on GPU"); check_last_error(); timer.start(); const bool success = check_result_cpu(data_cpu, num_entries, openmp); std::cout << "STATUS: test " << ( success ? "passed" : "failed") << std::endl; timer.stop("checking result on CPU"); timer.start(); for (uint64_t stream = 0; stream < num_streams; stream++) // Destroy streams. cudaStreamDestroy(streams[stream]); timer.stop("destroy streams"); check_last_error(); timer.start(); cudaFreeHost(data_cpu); cudaFree (data_gpu); timer.stop("free memory"); check_last_error(); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 发布到同一流中的操作将依发布顺序执行
-
相关阅读:
基于单片机16位智能抢答器设计
论文翻译 VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection
maptalks三维地图网址
c# xml 参数读取的复杂使用
【无标题】
【Go】单例模式与Once源码
第十章 引用
大模型部署手记(3)通义千问+Windows GPU
百趣代谢组学资讯:植物挥发性有机物生物合成机理及抗菌性研究IF14.46
【OpenCV】- 模板匹配(浩瀚星空只为寻找那一抹明月)
- 原文地址:https://blog.csdn.net/qq_31985307/article/details/126237070