-
SparkSQL系列-1、快速入门
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
传送门:大数据系列文章目录
官方网址:http://spark.apache.org/、 http://spark.apache.org/sql/

先来个介绍
Spark 2.0开始,应用程序入口为SparkSession,加载不同数据源的数据,封装到DataFrame/Dataset集合数据结构中,使得编程更加简单,程序运行更加快速高效。

SparkSession 应用入口
SparkSession:这是一个新入口,取代了原本的SQLContext与HiveContext。 对于DataFrameAPI的用户来说, Spark常见的混乱源头来自于使用哪个“context”。现在使用SparkSession,它作为单个入口可以兼容两者,注意原本的SQLContext与HiveContext仍然保留,以支持向下兼容。
文档: http://spark.apache.org/docs/2.4.5/sql-getting-started.html#starting-point-sparksession
1)SparkSession在SparkSQL模块中,添加MAVEN依赖
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>2.4.5</version> </dependency>- 1
- 2
- 3
- 4
- 5
2)SparkSession对象实例通过建造者模式构建,代码如下:

其中①表示导入SparkSession所在的包,②表示建造者模式构建对象和设置属性, ③表示导入SparkSession类中implicits对象object中隐式转换函数。3)范例演示:构建SparkSession实例,加载文本数据,统计条目数。
import org.apache.spark.sql.{Dataset, SparkSession} /** * Spark 2.x开始,提供了SparkSession类,作为Spark Application程序入口, * 用于读取数据和调度Job,底层依然为SparkContext */ object SparkStartPoint { def main(args: Array[String]): Unit = { // TODO: 构建SparkSession实例对象,读取数据 val spark = SparkSession.builder() // 设置应用名称和运行模式 .appName(this.getClass.getSimpleName.stripSuffix("$")) .master("local[2]") // 通过装饰模式获取实例对象,此种方式为线程安全的 .getOrCreate() // TODO: 2. 从文件系统读取数据,包含本地文件系统或HDFS文件系统 val inputDS: Dataset[String] = spark.read.textFile("datas/wordcount/wordcount.data") println(s"Count = ${inputDS.count()}") inputDS.show(10) // TODO: 3. 应用运行结束,关闭资源 spark.stop() } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
使用SparkSession加载数据源数据,将其封装到DataFrame或Dataset中,直接使用show函数就可以显示样本数据(默认显示前20条)。
Spark2.0使用全新的SparkSession接口替代Spark1.6中的SQLContext及HiveContext接口来实现其对数据加载、转换、处理等功能。
词频统计 WordCount
前面使用RDD封装数据,实现词频统计WordCount功能,从Spark 1.0开始,一直到Spark 2.0,建立在RDD之上的一种新的数据结构DataFrame/Dataset发展而来,更好的实现数据处理分析。DataFrame 数据结构相当于给RDD加上约束Schema,知道数据内部结构(字段名称、字段类型),提供两种方式分析处理数据: DataFrame API(DSL编程) 和SQL(类似HiveQL编程), 下面以WordCount程序为例编程实现,体验DataFrame使用。
基于DSL编程
使用SparkSession加载文本数据,封装到Dataset/DataFrame中,调用API函数处理分析数据(类似RDD中API函数,如flatMap、 map、 filter等),编程步骤:
第一步、构建SparkSession实例对象,设置应用名称和运行本地模式;
第二步、读取HDFS上文本文件数据;
第三步、使用DSL(Dataset API),类似RDD API处理分析数据;
第四步、控制台打印结果数据和关闭SparkSession;具体演示代码如下:
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} /** * 使用SparkSQL进行词频统计WordCount: SQL、 DSL */ object SparkDSLWordCount { def main(args: Array[String]): Unit = { // TODO: 1、构建SparkSession实例对象,通过建造者模式创建 val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName.stripSuffix("$")) .master("local[3]") .getOrCreate() import spark.implicits._ // TODO: 2、读取HDFS上文本文件数据 val inputDS: Dataset[String] = spark.read.textFile("datas/wordcount/wordcount.data") // TODO: 3、使用DSL(Dataset API),类似RDD API val resultDF: DataFrame = inputDS // 过滤不合格的数据 .filter(line => null != line && line.trim.length > 0) // 将每行数据进行分割 .flatMap(line => line.split("\\s+")) // 按照单词分组统计: SELECT word, count(1) FROM tb_words GROUP BY word .groupBy("value") // 使用count函数,获取值类型Long类型 -> 数据库中就是BigInt类型 .count() resultDF.show(10) // TODO: 关闭资源 spark.stop() } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
运行程序结果如下:
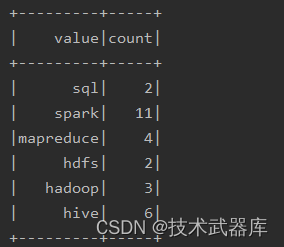
基于SQL编程
也可以实现类似HiveSQL方式进行词频统计,直接对单词分组group by,再进行count即可,步骤如下:
第一步、构建SparkSession对象,加载文件数据,分割每行数据为单词;
第二步、将DataFrame/Dataset注册为临时视图(Spark 1.x中为临时表);
第三步、编写SQL语句,使用SparkSession执行获取结果;
第四步、控制台打印结果数据和关闭SparkSession;具体演示代码如下:
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} object SparkSQLWordCount { def main(args: Array[String]): Unit = { // TODO: 1、构建SparkSession实例对象,通过建造者模式创建 val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName.stripSuffix("$")) .master("local[3]") .getOrCreate() import spark.implicits._ // TODO: 2、读取HDFS上文本文件数据 val inputDS: Dataset[String] = spark.read.textFile("datas/wordcount/wordcount.data") // TODO: 3、使用DSL(Dataset API),类似RDD API val wordsDS: Dataset[String] = inputDS // 过滤不合格的数据 .filter(line => null != line && line.trim.length > 0) // 将每行数据分割单词 .flatMap(line => line.trim.split("\\s+")) wordsDS.printSchema() wordsDS.show(20) // select value, count(1) as cnt from tb_words // TODO: 第一步,将Dataset注册为临时视图 wordsDS.createOrReplaceTempView("view_tmp_words") // TODO: 第二步,编写SQL执行分析 val resultDF: DataFrame = spark.sql( """ |SELECT value, COUNT(1) AS cnt FROM view_tmp_words GROUP BY value ORDER BY cnt DESC """.stripMargin) resultDF.show(10) // TODO: 关闭资源 spark.stop() } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
运行程序结果如下:
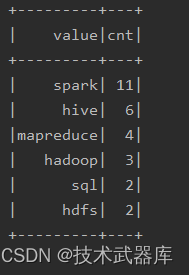
无论使用DSL还是SQL编程方式,底层转换为RDD操作都是一样,性能一致,查看WEB UI监控中Job运行对应的DAG图如下
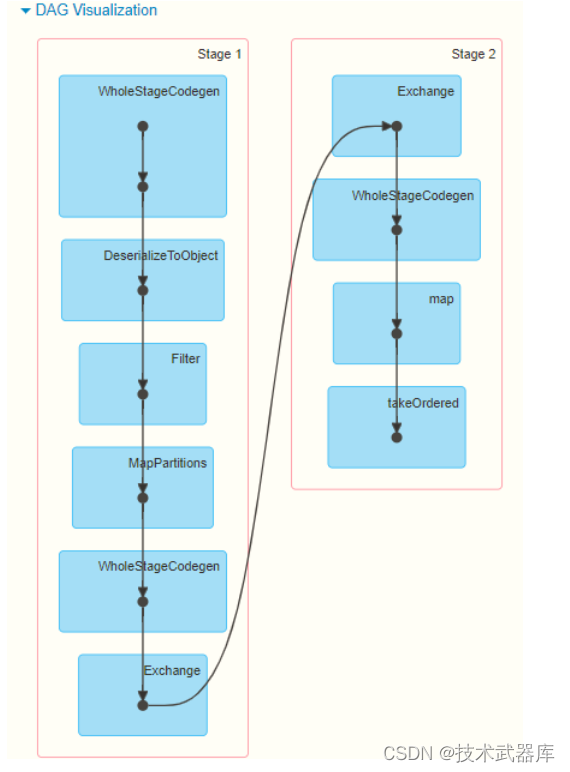
从上述的案例可以发现将数据封装到Dataset/DataFrame中,进行处理分析,更加方便简洁,这就是Spark框架中针对结构化数据处理模块: Spark SQL模块。下回分解
下篇文章介绍下SparkSQL的前世今生。
-
相关阅读:
Python学习基础笔记十一——编码
浅谈Elasticsearch安全和权限管理
iOS 实现悬浮跟手滚动效果
央视纪录:全球首创 “佛脸识别技术”,探索文物虚拟修复
如何设计一个完美的笔记本电脑
css中的hover用法示例(可以在vue中制作鼠标悬停显示摸个按钮的效果)
【Nacos】源码之客户端服务发现
【Qt开发流程】之富文本处理
php实现无限级分类的树形结构
Java线上云酒馆单预约系统源码小程序源码
- 原文地址:https://blog.csdn.net/l848168/article/details/126228739