-
Towards a Unified View of Parameter-Efficient Transfer Learning
参考
【论文分享】Towards a Unified View of Parameter-Efficient Transfer Learning
ICLR 2022分享会
Existing Methods

-
Adapter:把input representation经过矩阵W_down映射到低维空间,然后经过非线性激活层,比如ReLU,然后再又经过矩阵W_up映射回高维空间。W_down和W_up都是低秩矩阵,只能在几个维度上进行调整,所以调整的参数量不大。
-
Prefix tuning:把每一层attention的key和value前面都prepend一些向量,把attention原本的K和V前面分别加上P_k,P_v,得到新的attention。
-
LORA:用两个low rank的矩阵的乘积近似估计原本W_q和W_k这两个矩阵的参数更新情况,s是一个常数超参数(s>=1),实验前就设定好的。
A Unified Framework

这里发现,prefix tuning实际上是对原来的hidden states作了一个线性插值。将prefix tuning的公式写成这个形式之后,和Adapters就很像了。这个时候Prefix tuning和Adapters的公式 高度相似。且改写后的Prefix tuning公式中的W_down和W_up也是低秩矩阵,秩为prefix tuning在key和value前面加入的向量的数量。
如果我们把公式以及计算流图放在一起对比,发现我们可以说prefix tuning是一种形式的adapters。
Transfer Design Elements

这就启发了作者去寻找一种统一的框架。于是作者又对比分析了Adapter,Prefix Tuning和LoRA这三种design的具体结构,从四个维度去对比不同设计。
Sequential or Parallel

-
functional form是只加入的结构的函数形式、insertion form是指functional form怎么和原来的部分连接,像adapters就是从h出去的,作者把它形容为串联;
-
而Prefix Tuning和LoRA都是从x出去的,作者把它们形容为并联。
-
Prefix tuning没法做串联(sequential),他只能加在attention上面(在key和value之前),没法加在feed forward(ffn)上。
-
而无论是加在attn还是加在ffn上,Parallel Adapter都比Sequential Adapter在这两个任务上表现更好。
Attention or FFN

Modified representation是指这些设计是作用于Transformer的具体位置。-
prefix tuning是作用在attn上的;
-
adapter同时作用在attn和ffn上;
-
LoRA是作用在atten上的。
composition function表示Δh和h如何结合。
加ffn主要是增加非线性变换 attention的加权求和本质上只是线性变换。
对于modified representation,作者对比了加在attention上和加在feed forward上的效果,并发现总体来说,加在feed forward上效果更好。
Multi-head or Single head
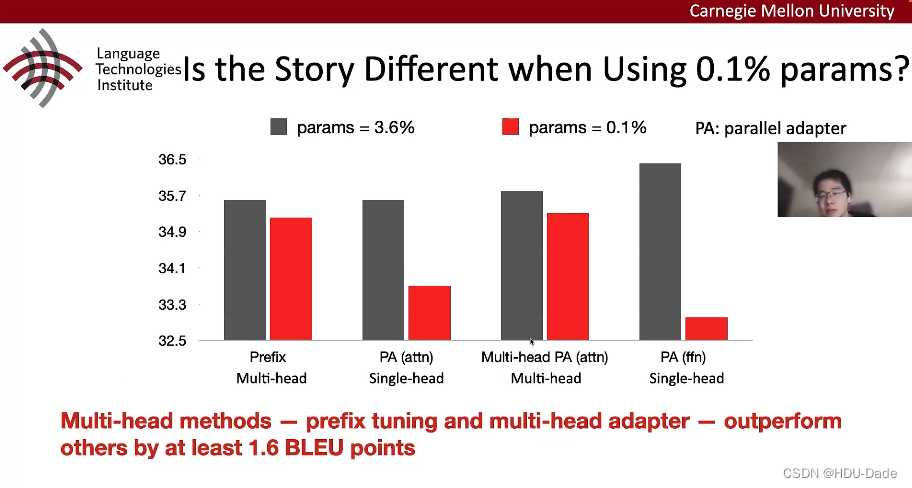
理论上,多头的结构应该比单头好,但是这里的Prefix tuning(多头结构)并没有比PA (单头的Parallel adapter)好。于是作者猜想,是否在参数很少的情况下,多头的优势才体现出来?-
当参数量很少的时候,multi-head表现的和参数数量很多时基本一致;
-
而作用在ffn上的设计受参数量影响较大。
由此可以引出结论:当只想改动少量参数时,用multi-head结构; 当可以调整较大数目参数的时候,可以用ffn结构。
总结
-
并联比串联好;
-
通常情况下,feedforward比attention好,而在只调整0.1%参数的情况下,multihead attn比ffn好;
-
Composition的对比实验这里没有展开,实际上作者也做了,并发现LoRA的设计是比较好的,简单且效果好,Prefix tuning的线性插值是比较复杂的。
-
-
相关阅读:
el-date-picker日期列表样式更换为完全不同的样式保证弹出日期弹窗的功能不变
几何光学与 Mathematica
面试算法43:在完全二叉树中添加节点
Fastjson 结合 jdk 原生反序列化的利用手法 ( Aliyun CTF )
(01)ORB-SLAM2源码无死角解析-(55) 闭环线程→闭环检测:寻找闭环候选关键帧 LoopClosing::DetectLoop()
Eigen-Matrix矩阵
Redis 事务
seaborn绘图(自用)
管理需因人而异,因时而变
Day51:动态规划 LeedCode 300.最长递增子序列 674. 最长连续递增序列 718. 最长重复子数组
- 原文地址:https://blog.csdn.net/qq_43130927/article/details/126034775