-
PettingZoo:多智能体游戏环境库入门
概述
PettingZoo1 类似于 Gym 的多智能体版本。Gym2是 OpenAI 开发的一个著名的强化学习库,它为环境提供了标准的 API,可以轻松地使用不同的强化学习代码库进行学习。
文档:https://www.pettingzoo.ml
代码:https://github.com/Farama-Foundation/PettingZoo但是当前大多数单智能体环境库存在一些问题。
- 基于POSG(partially observable stochastic game)的环境库,例如Gym,所有的智能体一起行动、一起观察、一起得到奖励。但是这种库对回合制游戏支持不好,且无法更改智能体的数量。这类库由于难以处理智能体回合顺序、智能体死亡和创建这类数量上的变化,难以扩展到超过两个智能体的范畴。
- 基于扩展式博弈(EFG)的环境库,由于模型复杂、当前应用面不广。当前基于EFG的库只有OpenSpiel API3,这个库的局限性在于无法处理连续动作。且EFG游戏结束时才有奖励,而强化学习通常需要频繁的奖励。
因此,为了解决上述问题,PettingZoo引入了AEG(Agent Environment Cycle games)作为PettingZoo API的基础。在AEG模型中,智能体依次看到他们的观察结果、采取行动,从其他智能体发出奖励,并选择下一个要采取行动的智能体。这实际上是POSG模型的一个顺序步进形式。
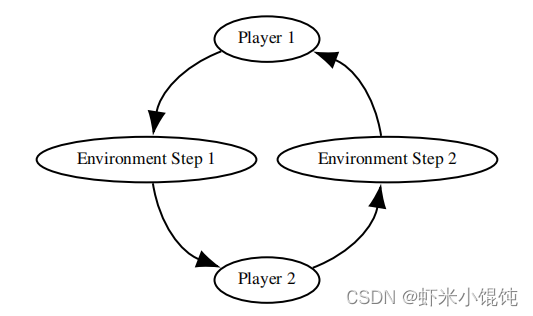
按顺序步进形式建模多智能体环境有许多好处:- 可以更清楚地将奖励归因到不同的来源,并允许各种学习改进
- 可以防止开发人员添加混乱和竞争条件
- 可以在每一步之后获得奖励,而这是EFG模型通常不具备的
- 更改智能体死亡或创建的数量更容易,学习代码不需要考虑到不断变化的列表大小
- 同时步进需要有无操作选项,如果不是所有的智能体都可以行动,这是非常难以处理的,而顺序步进可以同时操作并且排队处理它们的操作
PettingZoo的设计还考虑了以下原则:
- 尽可能重用Gym的设计,并且使API成为标准化
- 具有大量智能体的环境
- 具有智能体死亡和创建的环境
- 不同的智能体可以选择参与每个episode
- 学习方法需要访问低级别特征学习方法
游戏环境
当前PettingZoo支持的多智能体游戏环境如下表所示。
游戏环境 示例图 Atari: Multi-player Atari 2600 games (包含合作、竞争、混合环境) pip install pettingzoo[sisl]

Butterfly: 合作式游戏 pip install pettingzoo[butterfly]
Classic: 经典游戏,比如棋牌、卡牌游戏等。
pip install pettingzoo[classic]

MAgent: 网格世界中的大量像素智能体,在战斗或其他竞争场景中进行交互。4 pip install pettingzoo[magent]
MPE: 一组面向通信的粒子环境,粒子可以移动、通信、互相看到、互相推动,并与固定的地标交互。5 pip install pettingzoo[mpe]
SISL: 3个合作环境 6 pip install pettingzoo[sisl]
安装 PettingZoo
配置虚拟环境7:
# create venv python3 -m venv marl-env # active venv source marl-env/bin/activate # upgrade really old pip version on my system pip install --upgrade pip- 1
- 2
- 3
- 4
- 5
- 6
安装pettingzoo包:
# install packages pip install pettingzoo[classic] pip install spyder-notebook pip install dill- 1
- 2
- 3
- 4
导入包
import random import numpy as np from collections import defaultdict import dill- 1
- 2
- 3
- 4
初始化环境
from pettingzoo.classic import tictactoe_v3 env = tictactoe_v3.env()- 1
- 2
有的环境可以在初始化时进行参数配置:
cooperative_pong.env(ball_speed=18, left_paddle_speed=25, right_paddle_speed=25, is_cake_paddle=True, max_cycles=900, bounce_randomness=False)- 1
- 2
与环境交互
env.reset() for agent in env.agent_iter(): observation, reward, done, info = env.last() action = policy(observation, agent) env.step(action)- 1
- 2
- 3
- 4
- 5
这段代码中,
agent_iter(max_iter=2**63)返回一个迭代器,它产生环境的当前智能体。max_iter它在环境中的所有代理都完成或(已执行步骤)时终止。last(observe=True)返回observation, reward, done, info,代表当前能够行动的代理。返回的奖励是代理自上次行动以来收到的累积奖励。如果 observe 设置为False,则不会计算观测值,并将None在其位置返回。请注意,完成单个代理并不意味着环境已完成。reset()重置环境,并在第一次调用时设置它以供使用。只有在调用此函数后,对象才会agents变得可用。step(action)在环境中采取并执行代理的动作,自动将控制权切换到下一个代理。agent_selection显示当前选择的代理。agents列出所有可用的代理。完整 API 文档:
https://www.pettingzoo.ml/api
-
相关阅读:
java-php-python-会议查询系统计算机毕业设计
机器学习(一)
使用npm下载包提示idealTree:pxx: sill idealTree buildDeps的解决方法
Nacos面试题
汇总区间问题
《算法导论》18.2 B树上的基本操作(搜索、创建、插入)(包含C++代码)
Pthon中的文件处理
day30_servlet
智能制造时代下,MES管理系统需要解决哪些问题
如何理解分布式架构和微服务架构呢
- 原文地址:https://blog.csdn.net/Bit_Coders/article/details/125544958