推荐系统之K近邻(KNN)算法
1.引入库
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
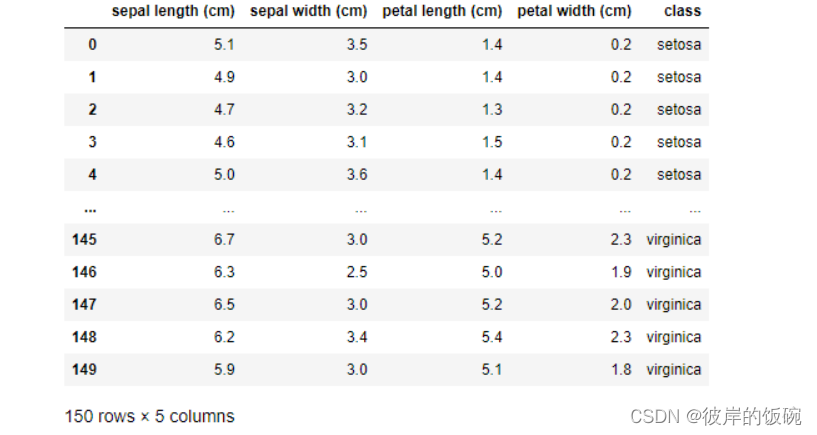
2.数据加载与预处理
iris=load_iris()
df=pd.DataFrame(data=iris.data,columns=iris.feature_names)
df['class']=iris.target
df['class']=df['class'].map({0:iris.target_names[0],1:iris.target_names[1],2:iris.target_names[2]})
df
x=iris.data
y=iris.target.reshape(-1,1)
print(x.shape,y.shape)
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=35,stratify=y)
print(x_train.shape,y_train.shape)
print(x_test.shape,y_test.shape)
3.核心算法实现
def l1_distance(a,b):
return np.sum(np.abs(a-b),axis=1)
def l2_distance(a,b):
return np.sqrt(np.sum((a-b)**2,axis=1))
class kNN(object):
def __init__(self,n_neighbors=1,dist_func = l1_distance):
self.n_neighbors=n_neighbors
self.dist_func=dist_func
def fit(self,x,y):
self.x_train=x
self.y_train=y
def predict(self,x):
y_pred= np.zeros((x.shape[0],1),dtype=self.y_train.dtype)
for i,x_test in enumerate(x):
distance=self.dist_func(self.x_train,x_test)
nn_index=np.argsort(distance)
nn_y=self.y_train[nn_index[:self.n_neighbors]].ravel()
y_pred[i]=np.argmax(np.bincount(nn_y))
return y_pred
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
4.测试
knn=kNN(n_neighbors=3)
knn.fit(x_train,y_train)
y_pred=knn.predict(x_test)
accuracy=accuracy_score(y_test,y_pred)
print("预测准确率为:",accuracy)
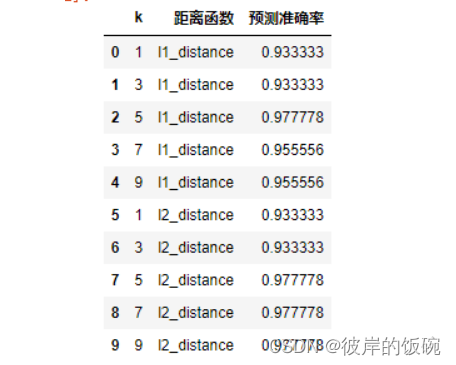
5.拓展,不同参数的准确率比较
knn=kNN()
knn.fit(x_train,y_train)
result_list=[]
for p in [1,2]:
knn.dist_func= l1_distance if p==1 else l2_distance
for k in range(1,10,2):
knn.n_neighbors=k
y_pred=knn.predict(x_test)
accuracy=accuracy_score(y_pred,y_test)
result_list.append([k,'l1_distance' if p==1 else 'l2_distance',accuracy])
df=pd.DataFrame(result_list,columns=['k','距离函数','预测准确率'])
df
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22