-
ES6 入门教程 6 正则的扩展 6.1 RegExp 构造函数 & 6.2 字符串的正则方法 & 6.3 u 修饰符
ES6 入门教程
作者:阮一峰
本文仅用于学习记录,不存在任何商业用途,如侵删
6 正则的扩展
6.1 RegExp 构造函数
在 ES5 中,
RegExp构造函数的参数有两种情况。第一种情况是,参数是字符串,这时第二个参数表示正则表达式的修饰符(flag)。
var regex = new RegExp('xyz', 'i'); // 等价于 var regex = /xyz/i;- 1
- 2
- 3
第二种情况是,参数是一个正则表示式,这时会返回一个原有正则表达式的拷贝。
var regex = new RegExp(/xyz/i); // 等价于 var regex = /xyz/i;- 1
- 2
- 3
但是,ES5 不允许此时使用第二个参数添加修饰符,否则会报错。
var regex = new RegExp(/xyz/, 'i'); // Uncaught TypeError: Cannot supply flags when constructing one RegExp from another- 1
- 2
ES6 改变了这种行为。
如果
RegExp构造函数第一个参数是一个正则对象,那么可以使用第二个参数指定修饰符。而且,返回的正则表达式会忽略原有的正则表达式的修饰符,只使用新指定的修饰符。new RegExp(/abc/ig, 'i').flags // "i"- 1
- 2

上面代码中,原有正则对象的修饰符是
ig,它会被第二个参数i覆盖。6.2 字符串的正则方法
ES6 出现之前,字符串对象共有 4 个方法,可以使用正则表达式:
match()、replace()、search()和split()。ES6 将这 4 个方法,在语言内部全部调用
RegExp的实例方法,从而做到所有与正则相关的方法,全都定义在RegExp对象上。String.prototype.match调用RegExp.prototype[Symbol.match]String.prototype.replace调用RegExp.prototype[Symbol.replace]String.prototype.search调用RegExp.prototype[Symbol.search]String.prototype.split调用RegExp.prototype[Symbol.split]
6.3 u 修饰符
ES6 对正则表达式添加了
u修饰符,含义为“Unicode 模式”,用来正确处理大于\uFFFF的 Unicode 字符。也就是说,会正确处理四个字节的 UTF-16 编码。/^\uD83D/u.test('\uD83D\uDC2A') // false /^\uD83D/.test('\uD83D\uDC2A') // true- 1
- 2

上面代码中,
\uD83D\uDC2A是一个四个字节的 UTF-16 编码,代表一个字符。但是,ES5 不支持四个字节的 UTF-16 编码,会将其识别为两个字符,导致第二行代码结果为
true。加了u修饰符以后,ES6 就会识别其为一个字符,所以第一行代码结果为false。一旦加上
u修饰符号,就会修改下面这些正则表达式的行为。6.3.1 点字符
点(
.)字符在正则表达式中,含义是除了换行符以外的任意单个字符。对于码点大于
0xFFFF的 Unicode 字符,点字符不能识别,必须加上u修饰符。var s = '𠮷'; /^.$/.test(s) // false /^.$/u.test(s) // true- 1
- 2
- 3
- 4
上面代码表示,如果不添加
u修饰符,正则表达式就会认为字符串为两个字符,从而匹配失败。6.3.2 Unicode 字符表示法
ES6 新增了使用大括号表示 Unicode 字符,这种表示法在正则表达式中必须加上
u修饰符,才能识别当中的大括号,否则会被解读为量词。/\u{61}/.test('a') // false /\u{61}/u.test('a') // true /\u{20BB7}/u.test('𠮷') // true- 1
- 2
- 3
上面代码表示,如果不加
u修饰符,正则表达式无法识别\u{61}这种表示法,只会认为这匹配 61 个连续的u。6.3.3 量词
使用
u修饰符后,所有量词都会正确识别码点大于0xFFFF的 Unicode 字符。/a{2}/.test('aa') // true /a{2}/u.test('aa') // true /𠮷{2}/.test('𠮷𠮷') // false /𠮷{2}/u.test('𠮷𠮷') // true- 1
- 2
- 3
- 4
6.3.4 预定义模式
u修饰符也影响到预定义模式,能否正确识别码点大于0xFFFF的 Unicode 字符。/^\S$/.test('𠮷') // false /^\S$/u.test('𠮷') // true- 1
- 2
上面代码的
\S是预定义模式,匹配所有非空白字符。只有加了u修饰符,它才能正确匹配码点大于0xFFFF的 Unicode 字符。利用这一点,可以写出一个正确返回字符串长度的函数。
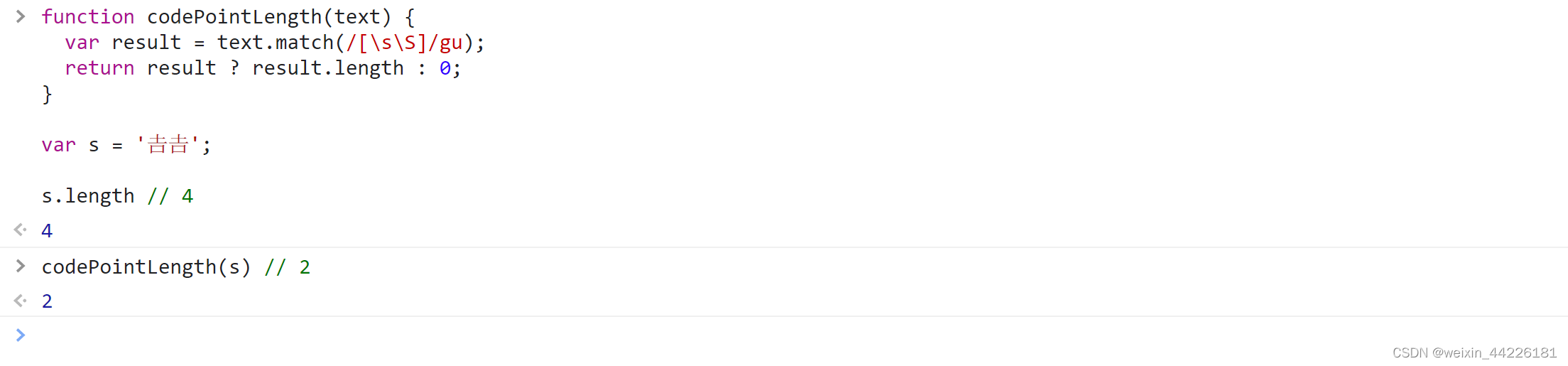
function codePointLength(text) { var result = text.match(/[\s\S]/gu); return result ? result.length : 0; } var s = '𠮷𠮷'; s.length // 4 codePointLength(s) // 2- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
6.3.5 i 修饰符
有些 Unicode 字符的编码不同,但是字型很相近,比如,
\u004B与\u212A都是大写的K。/[a-z]/i.test('\u212A') // false /[a-z]/iu.test('\u212A') // true- 1
- 2
上面代码中,不加
u修饰符,就无法识别非规范的K字符。6.3.6 转义
没有
u修饰符的情况下,正则中没有定义的转义(如逗号的转义\,)无效,而在u模式会报错。/\,/ // /\,/ /\,/u // 报错- 1
- 2
上面代码中,没有
u修饰符时,逗号前面的反斜杠是无效的,加了u修饰符就报错。 -
相关阅读:
Apifox vs Eolink,国内 Api 工具哪家强?
1373. 二叉搜索子树的最大键值和
java算法学习索引之二叉树问题
若依使用EasyExcel导入和导出数据
springbootvue电影购票网站
河北邯郸:拓展基层就业空间 助力高校毕业生就业
chatgpt
Java集合--Collection、Map、List、Set、Iterator、Collections工具类
ZZNUOJ_用C语言编写程序实现1359:数独(附完整源码)
金仓数据库KingbaseES数据库参考手册(动态性能视图3.9. sys_stat_progress_cluster )
- 原文地址:https://blog.csdn.net/weixin_44226181/article/details/127858943