-
语义分割算法及在无人驾驶的应用
一.物体检测算法的不足
1.稀疏的输出结果
- 目标物体的位置、大小、类别、速度等
- 无法感知非物体,比如道路、建筑物、数目等
- 无法识别可行驶区域,无法规避所有障碍物
2.粗略的物体框表示
- 矩形框:中心点+长宽
- 无法精确表述物体形状
3. 受限的应用场景
- 自适应巡航
- 自动紧急刹车
- 盲区监测
不适用于车道保持和泊车辅助
二.语义分割
1.稠密的输出结果
- 每个像素点的语义类别
- 物体:实例ID+分割Mask
- 非物体:分割Mask
2.应用场景
- 可行驶道路检测
- 车道线监测
- 障碍物监测
3.最直接的方法
- 滑动窗口遍历整幅图像
- 对固定大小的图像块进行分类
- 分类器:SVM或者全连接网络
问题:大量的冗余计算,无法利用上下文信息
4.全连接网络(FCN)
- 叠加多个卷积层和下采样层
- 逐层扩大感受野,提取不同层次的空间上下文特征
- 最终的特征图通过反卷积恢复到原始图形的分辨率
问题:下采样导致空间细节信息的丢失,影响分类正确率和空间位置分辨率,尤其是影响细小物体
5.U-Net
- 编码器-解码器的结构
- 同样分辨率的特征图之间,增加了Skip连接
- 同时保留高层的上下文特征和底层的细节特征
- 网络通过学习来自动的平衡上下文和细节信息的比重
问题:底层特征图具有较大的感受野,但是牺牲了空间分辨率
6.空洞卷积(Dilated/Atrous Convolution)
- 拓展标准卷积核,使其铺盖更大的空间位置
- 代替下采样的操作:保持空间分辨率;在不增加计算量的前提下扩大感受野;
7.大卷积核
- 增加卷积操作的感受野
- 卷积结果的空间分辨率不受影响
- 降低计算量的Trick:二维的大卷积核(K×K)分解为两个一维的卷积核(1×K和K×1);二维卷积的结果用两个一维卷积结果的和来模拟;计算量由 O ( K 2 ) O(K^2) O(K2)降低到 O ( K ) O(K) O(K)
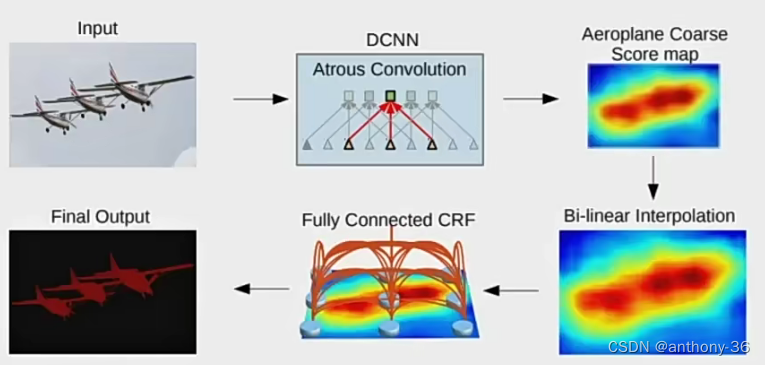
8.DeepLab
- 采用扩张卷积扩大感受野
- 采用ASPP(Atrous Spatial Pyramid Pooling)提取多尺度信息
- 采用条件随机场(CRF)优化分割结果
9.Mask R-CNN
- 在Faster R-CNN的基础上增加实例分割分支
- 对于每个ROI,利用FCN输出一个固定大小的二值Mask
- ROI Align代替Pooling,提高特征与像素的空间对齐程度
3.自动驾驶中的应用
1车道线检测
用FCN输出一个固定大小的二值Mask
- ROI Align代替Pooling,提高特征与像素的空间对齐程度
三.自动驾驶中的应用
1车道线检测

-
相关阅读:
Sqoop Hook
Android在XML和代码中,同时设置背景,导致背景叠加的问题
【博客436】kubeadm init原理
【Linux】部署单机项目以及前后端分离项目
240. 搜索二维矩阵 II Python
springboot整合redis
网络安全-黑客技术-小白学习
选择工业交换机时,需要关注哪些方面的性能?
百度文心一言与谷歌Gemini的对比
产品推荐 - 基于复旦微 JFM7K325T FPGA 的高性能 PCIe 总线数据预处理载板(100%国产化)
- 原文地址:https://blog.csdn.net/qq_46067306/article/details/126193842