-
Tomcat 源码解析一JNDI
JNDI属于JEE规范范畴,是JEE 的核心技术之一,它提供了一级接口,类和关于命名空间的概念,JNDI是基于提供商技术,它暴露了一个API和一个服务供应接口(SPI),它将名称和对象联系起来 , 使我们可以用名称访问对象,我们可以把JNDI 简单的看成里面封装了一个名称到实例的对象映射,通过字符串可以方便得到想要的资源,例如JDBC ,JMail,JMS ,EJB等,这意味着任何基于名字的技术都能通过JNDI而提供的服务,现在它支持的技术包括LDAP,RMI ,CORBA, DNS,DIS,DNS等。
JNDI包含很多的服务接口,如图15.1所示 , JNDI API 提供了访问不同的JNDI 服务的一个标准的统一入口 , 其具体的实现可以由不同的服务提供商来完成 , 具体调用的类及通信过程是对用户透明的, 从架构上来看,JNDI 包含了一个API 层及SPI 层,SPI 层提供了服务的的具体实现,再通过JNDI 的API 暴露给Java 应用程序使用,这就将各种复杂的细节屏蔽掉了,提供了统一的供应程序使用。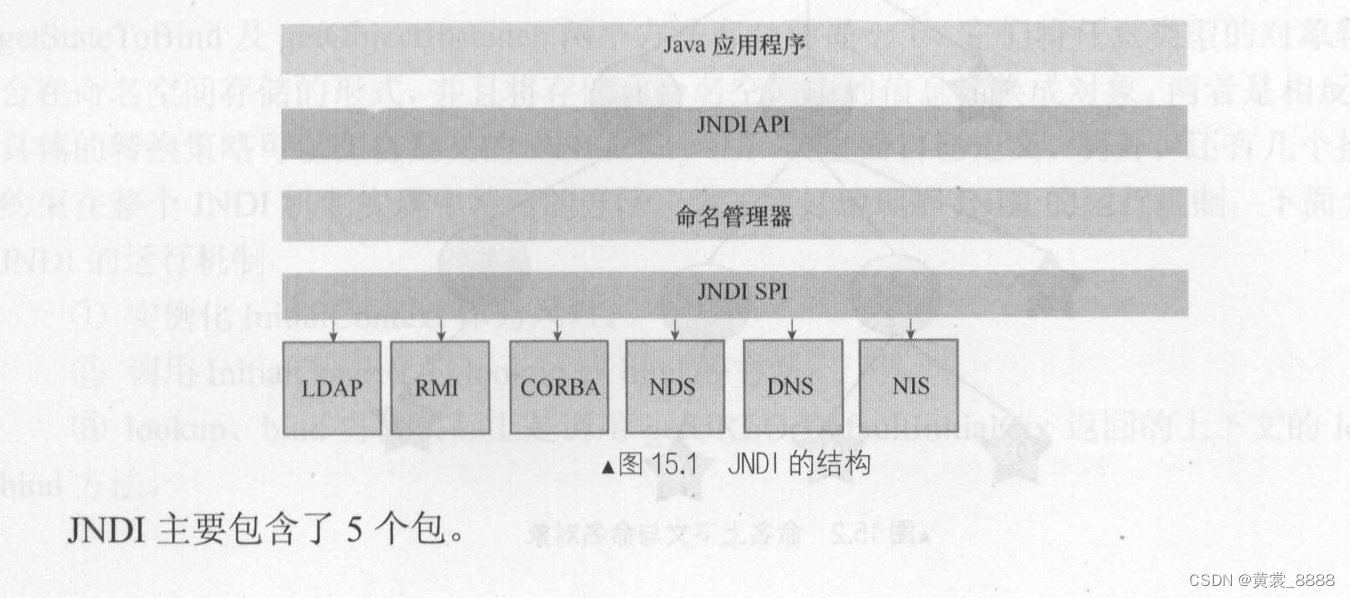
- javax.naming : 这个包下面主要是用于访问命名服务的类和接口,比如,其中定义了Context接口,该接口是执行查找时命名服务的入口点。
- javax.naming.directory : 这个包主要包含用于访问目录服务的类与接口的扩展命名和接口,例如,它增加了新的属性类,提供代表一个目录上下文的DirContext接口,并且定义了用于检查和更新与目录对象相关的属性和方法 。
- javax.naming.event : 这个包主要为访问命名和目录服务时提供了事件通知以实现监控功能,例如 , 它定义了一个NamingEvent类(用于表示由命名(目录服务生成事件)),以及一个监视的NamingEvents 类的NamingListener 接口。
- javax.naming.ldap:这个包为LDAP v3 扩展操作和空间提供了特定的支持。
- javax.naming.spi : 这个包提供了通过javax.naming及其相关的访问命名和目录服务的支持,这有那些SPI 开发人员对这个包感兴趣,Tomcat 也提供了自己的服务接口,所以必须与这个包打交道。
JNDI 运行机制
Tomcat 中涉及了JNDI SPI 的开发,下面深入讨论JNDI 的运行机制,JNDI 的主要工作就是维护两个对象:命名上下文和命名对象,它们的关系可能用图15.2简单表示,其中圆圈表示命名上下文,星形表示命名上下文所绑定的命名对象,初始化上下文为入口 , 假如查找的对象URL 是"A/C/03",那么命名上下文将对这个URL进行分拆,首先找到名字为A 的上下文,接着再找到C的上下文,最后找到名字为03的命名对象,类似的,其他的对象也是如此查找,这便是JNDI 树,所以的命名对象和命名上下文都绑定到树上,一般来说,命名上下文是树的节点,而命名对象是树的树叶,不管是命名对象还是命名上下文,都有自己的名字 。
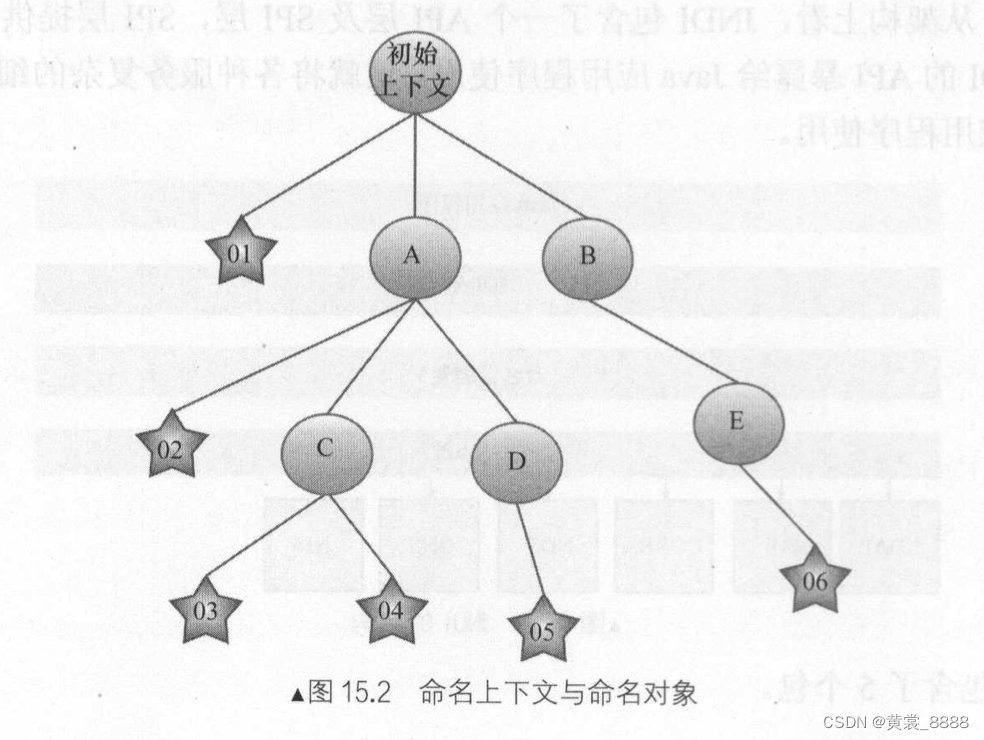
关于命名对象,一般来说,在JNDI中存在两种命名对象的形态 , 直接内存中的命名对象, 2. 使用时再根据指定类及属性信息创建命名对象 。
第一种命名对象的形态 , 将实例化好的对象通过Context.bind()绑定到上下文,当需要命名对象时,通过Context.lookup() 查找,这种情况是直接从内存中查找相应的对象,上下文会在内存中维护所有的绑定的命名对象,这种方式存在几个缺点,首先,内存大小限制了绑定到上下文的对象的数量,其次 , 一些未持久保存的对象在命名服务器重启后不可恢复 , 最后,有些对象本身不适合这种方式,例如数据库连接对象 。
第二种命名对象形态 , 将生成命名对象需要的类位置信息及一些属性信息进行绑定,在查找时就可以使用这些信息创建适合Java 应用使用的对象,这种情况下,在绑定时可能需要额外的做一些处理,例如 将Java 对象转化为对应的类位置信息及一些属性信息,绑定和查找这两个相反的过程对过ObjectFactory和StateFactory两个工厂类的getObjectInstance和getStateToBind方法进行实现, 一般来说,JNDI 提供了Reference类存储类位置信息及属性信息的标准方式,并鼓励命名对象实现这个类而不是直接另起炉灶, 同时 , Serializable也可以作为JNDI 存储对象的类型,表示可序列化对象,另外,Referenceable对象可以通过Referenceable.getReference()返回Reference对象进行存储 。
整个JNDI框架对命名上下文和命名对象的处理进行了巧妙的,合理的设计 , 下面给出JNDI 涉及的主要类图,如图15.3 所示 , 从类图中可以看到,不管是命名上下文相关的类还是命名对象相关的类, 都围绕着NamingManager这个类, 命名上下文相关的类则提供了上下文实现的一些策略,命名对象相关的类则提供了命名对象存储及创建一些策略,两大部分内容如下 。- 通过FactoryBuilder 模式,URL模式 , 环境变量模式三种机制,确定初始化上下文,相关的接口类分别为InitialContextFactoryBuilder 接口,XXXURLContextFactory类,InitialContext类。
- 通过工厂模式,定义上下文中绑定和查找对象的转化策略, 相关的接口类为StateFactory接口,ObjectFactory接口。
围绕着NamingManager这些类的接口是JNDI 能正常运行的基础,所有的上下文都要实现Context接口, 这个接口主要的方法是lookup,bind , 分别用于查找对象与绑定对象,我们熟知的InitialContext即JNDI 的入口 , NamingManager 包含很多操作上下文方法,其中getStateToBind及getObjectInstance两个方法有必要提一下, 它们将任意类型的对象转换成对象,两者是相反的过程 , 具体的转换策略可以在自定义的XXXFactory工厂类里面定义自己定义,另外,还有几个接口用于约束整个JNDI 机制实现中特定的方法 , 为了更好的理解JNDI的运行机制,下面分步说明JNDI的运行机制 。
- 实例化InitialContext作为入口 。
- 调用InitialContext的loopup或bind等方法
- lookup,bind 方法实际上是调用了getURLOrDefaultInitialCtx返回上下文lookup或bind方法 。

上面说了那么多,都是书本上的内容 , 我们来看一个例子。
public class HelloServlet extends HttpServlet { public HelloServlet() { } protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { Context ctx = null; Connection con = null; Statement stmt = null; ResultSet rs = null; try { System.out.println("开始请求============================"); ctx = new InitialContext(); DataSource ds = (DataSource)ctx.lookup("java:comp/env/jdbc/mysql"); System.out.println("bbb============================" + ds); con = ds.getConnection(); System.out.println("==con=====" + con); stmt = con.createStatement(); System.out.println("==stmt=====" + stmt); rs = stmt.executeQuery("select * from lt_company "); PrintWriter out = response.getWriter(); response.setContentType("text/html"); out.print("Employee Details
"); out.print(""); out.print("
ID "); out.print("is_delete "); out.print("cooperate_type "); out.print("company_name "); out.print("company_code "); while(rs.next()) { out.print(""); out.print(" "); } out.print("" + rs.getInt("id") + " "); out.print("" + rs.getInt("is_delete") + " "); out.print("" + rs.getInt("cooperate_type") + " "); out.print("" + rs.getString("company_name") + " "); out.print("" + rs.getString("company_code") + " "); out.print("
"); out.print("Database Details
"); out.print("Database Product: " + con.getMetaData().getDatabaseProductName() + "
"); out.print("Database Driver: " + con.getMetaData().getDriverName()); out.print(""); } catch (NamingException var24) { var24.printStackTrace(); } catch (SQLException var25) { var25.printStackTrace(); } finally { try { rs.close(); stmt.close(); con.close(); ctx.close(); } catch (SQLException var22) { System.out.println("Exception in closing DB resources"); } catch (NamingException var23) { System.out.println("Exception in closing Context"); } } } ... }上面这个例子的原理很简单, 通过 java:comp/env/jdbc/mysql 获取DataSource对象,通过DataSource创建链接,以jdbc的方式获取lt_company 所有数据,通过表格展示在前台页面上,重点关注下面代码 。
ctx = new InitialContext();
DataSource ds = (DataSource)ctx.lookup(“java:comp/env/jdbc/mysql”);
那ds又是如何获得的呢?当然我们的准备条件还没有做完,修改tomcat/conf/server.xml文件中,在其中添加 。..... servelet-test-1.0" > 在上述代码中需要注意的是servelet-test-1.0是我自己创建 servlet项目 。 github地址为 https://github.com/quyixiao/servelet-test 的version_2022_07_30_jndi分支。接下来,我们进入项目测试 。
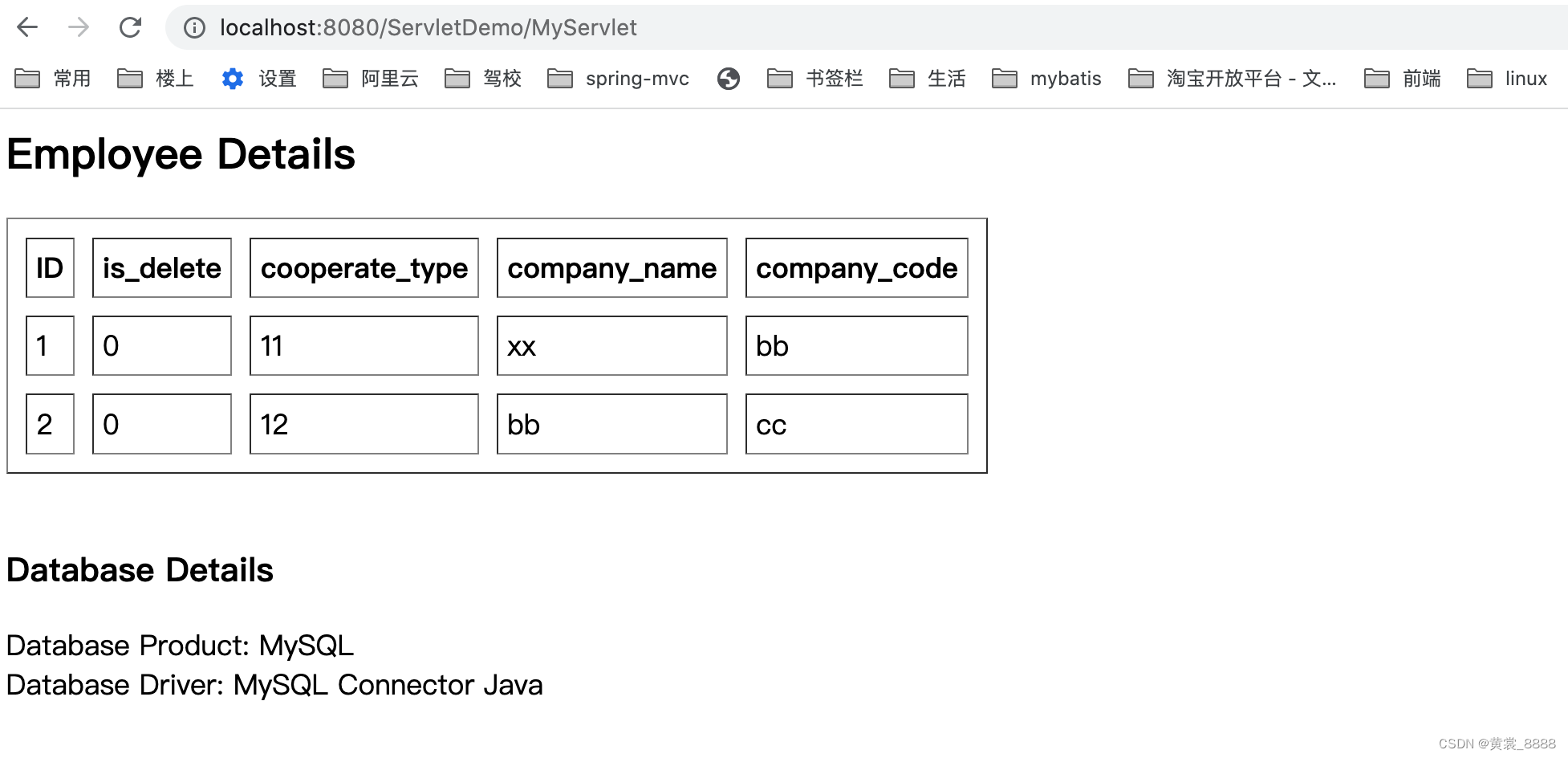
为什么,我们通过
DataSource ds = (DataSource)ctx.lookup(“java:comp/env/jdbc/mysql”); 这段代码就能获取到DataSource,为什么呢?
之前的博客《Tomcat 源码解析一初识》中已经分析过Digester的使用,我们再来回顾本例中的Digester使用。
GlobalNamingResources xml 标签最终被封装成NamingResources对象,再通过setGlobalNamingResources方法添加到StandardServer中,那GlobalNamingResources标签下的标签又是如何解析的呢?我们进入digester.addRuleSet(new NamingRuleSet(“Server/GlobalNamingResources/”));这一行代码 。

通过上面的分析,最终Resource标签被封装成ContextResource对象通过addResource方法添加到 父亲标签对应的对象(NamingResources)的resources属性中。
同理,我们再来看看ResourceLink标签的解析。还是老套路, 看ResourceLink如何封装

从上图中,我们可以看到,最终ResourceLink标签被封装成ContextResourceLink对象通过addResourceLink方法加到StandardContext的 resources 属性中, 细心的读者发现 StandardContext 并没有resources属性,也并没有addResourceLink方法,这就奇怪了 。 我们深入SetNextNamingRule类,看它是如何解析Context标签下的ResourceRef标签的。 SetNextNamingRule并没有自己实现start()方法 ,只实现了end()方法,接下来,看end方法如何实现。public void end(String namespace, String name) throws Exception { Object child = digester.peek(0); Object parent = digester.peek(1); NamingResources namingResources = null; if (parent instanceof Context) { namingResources = ((Context) parent).getNamingResources(); } else { namingResources = (NamingResources) parent; } // Call the specified method IntrospectionUtils.callMethod1(namingResources, methodName, child, paramType, digester.getClassLoader()); }end方法中methodName为 ‘addResourceLink’,在StandardContext中并没有实现addResourceLink()方法,而在end()方法中我们也看到了,ResourceLink并没有直接存储在StandardContext中,而是存储在StandardContext的namingResources属性中,callMethod1实际上是调用namingResources的addResourceLink方法,将resourceLink添加到NamingResources的resourceLinks属性中。 而每一个StandardContext拥有一个自己的NamingResources对象 。
接下来,我们就能看明白StandardContext启动时触发configure_start事件,NamingContextListener监听到configure_start事件后做的一系列处理。public void lifecycleEvent(LifecycleEvent event) { container = event.getLifecycle(); if (container instanceof Context) { // 如果当前事件是StandardContext发起的,则直接取StandardContext的namingResources对象, // 之前我们提过 , StandardContext拥有自己的NamingResources对象 namingResources = ((Context) container).getNamingResources(); logger = log; } else if (container instanceof Server) { // 如果发起事件的容器是StandardServer,则取全局NamingResource namingResources = ((Server) container).getGlobalNamingResources(); } else { return; } // 如果事件类型是configure_start if (Lifecycle.CONFIGURE_START_EVENT.equals(event.getType())) { // 如果已经初始化,则直接返回 if (initialized) return; try { Hashtable
我们可能不太懂为什么要将classLoader与NamingContext绑定,我们再来看一个例子。 我们将相同的项目一个命名为servelet-test-1.0,另外一个命名为ServletDemo,之前我们分析过,调用http://localhost:8080/ServletDemo/MyServlet 访问接口正常
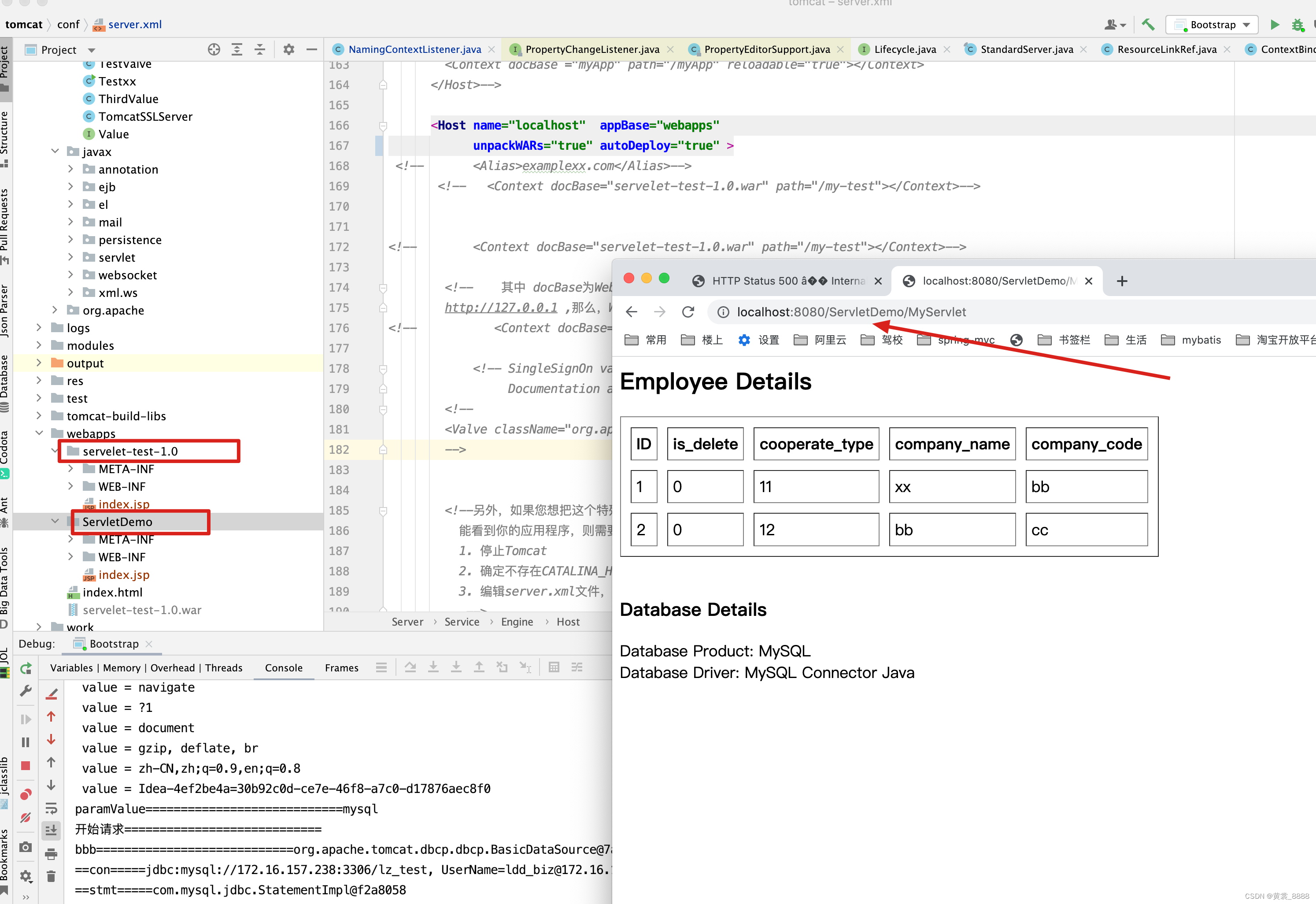
但是调用http://localhost:8080/servelet-test-1.0/MyServlet
抛出异常 。

原因,因为servelet-test-1.0的ClassLoader并没有绑定jdbc/mysql 的NamingContext ,而ServletDemo项目,在createNamingContext()方法中,通过下面这段代码,将jdbc/mysql构建成subContext保存到ServletDemo 的StandardContext的NamingContext中。
ContextResourceLink[] resourceLinks =
namingResources.findResourceLinks();
for (i = 0; i < resourceLinks.length; i++) {
addResourceLink(resourceLinks[i]);
}
我们后面来分析createNamingContext()方法,先来分析在Servlet中,如何根据当前ClassLoader获取命名上下文。- getURLOrDefaultInitialCtx方法会判断是否用NamingManager的setInitialContextFactoryBuilder方法设置了InitialContextFactoryBuilder,即判断NamingManager里面的InitialContextFactoryBuilder变量是否为空。
丢这两句话这里,我相信大家也不知道什么意思 ,我们还是来看源码 。
从lookup方法看起。
DataSource ds = (DataSource)ctx.lookup(“java:comp/env/jdbc/mysql”);进入
public Object lookup(String name) throws NamingException { return getURLOrDefaultInitCtx(name).lookup(name); }protected Context getURLOrDefaultInitCtx(String name) throws NamingException { if (NamingManager.hasInitialContextFactoryBuilder()) { return getDefaultInitCtx(); } String scheme = getURLScheme(name); if (scheme != null) { Context ctx = NamingManager.getURLContext(scheme, myProps); if (ctx != null) { return ctx; } } return getDefaultInitCtx(); } public static boolean hasInitialContextFactoryBuilder() { return (getInitialContextFactoryBuilder() != null); } getInitialContextFactoryBuilder() { return initctx_factory_builder; }
- 根据步骤4,如果设置了,则会调用InitialContextFactorybuilder的createInitialContextFactory方法返回一个InitialContextFactory,再调用这个工厂类的getInitialContext返回Context ,至此得到了上下文 。
为了理解上面这一句话的意思 , 我们接着看getDefaultInitCtx()方法 。
protected Context getDefaultInitCtx() throws NamingException{ // 如果gotDefault没有被初始化,则先初始化,如果 // 已经初始化,直接返回defaultInitCtx值即可 if (!gotDefault) { defaultInitCtx = NamingManager.getInitialContext(myProps); gotDefault = true; } // 如果gotDefault = true,表示已经初始化过,但defaultInitCtx依然为空, 则抛出NoInitialContextException异常 if (defaultInitCtx == null) throw new NoInitialContextException(); return defaultInitCtx; }如果从来没有被初始化过,则调用NamingManager.getInitialContext()方法进行初始化,我们进入getInitialContext()方法 。
public static Context getInitialContext(Hashtable env) throws NamingException { InitialContextFactory factory; InitialContextFactoryBuilder builder = getInitialContextFactoryBuilder(); // 如果initctx_factory_builder为空 if (builder == null) { // 从InitialContext的环境变量中获取java.naming.factory.initial的值 // 如在初始化InitialContext,传入env ,env中包含java.naming.factory.initial // Hashtable
写了那么多,那我们来配置一个InitialContextFactoryBuilder用试试 。
- 修改之前的HelloServlet方法 。
public class HelloServlet extends HttpServlet { public static boolean flag = true; public HelloServlet() { } protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { Context ctx = null; Connection con = null; Statement stmt = null; ResultSet rs = null; try { //System.out.println("paramValue============================" + paramValue); System.out.println("开始请求============================"); if(flag){ // 因为 initctx_factory_builder是静态变量,设置一次即可 System.out.println("设置 InitialContextFactoryBuilder ========="); NamingManager.setInitialContextFactoryBuilder(new MyInitialContextFactoryBuilder()); flag = false; } System.out.println("====================初始化InitialContext ==========="); ctx = new InitialContext(); System.out.println("--------------------------开始调用lookup查询------------ "); DataSource ds = (DataSource)ctx.lookup("java:comp/env/jdbc/mysql"); System.out.println("打印出ds============================" + ds); con = ds.getConnection(); System.out.println("==con=====" + con); stmt = con.createStatement(); System.out.println("==stmt=====" + stmt); rs = stmt.executeQuery("select * from lt_company "); PrintWriter out = response.getWriter(); response.setContentType("text/html"); out.print("Employee Details
"); out.print(""); out.print("
ID "); out.print("is_delete "); out.print("cooperate_type "); out.print("company_name "); out.print("company_code "); while(rs.next()) { out.print(""); out.print(" "); } out.print("" + rs.getInt("id") + " "); out.print("" + rs.getInt("is_delete") + " "); out.print("" + rs.getInt("cooperate_type") + " "); out.print("" + rs.getString("company_name") + " "); out.print("" + rs.getString("company_code") + " "); out.print("
"); out.print("Database Details
"); out.print("Database Product: " + con.getMetaData().getDatabaseProductName() + "
"); out.print("Database Driver: " + con.getMetaData().getDriverName()); out.print(""); } catch (NamingException var24) { var24.printStackTrace(); } catch (SQLException var25) { var25.printStackTrace(); } finally { try { rs.close(); stmt.close(); con.close(); ctx.close(); } catch (SQLException var22) { System.out.println("Exception in closing DB resources"); } catch (NamingException var23) { System.out.println("Exception in closing Context"); } } } }上面加粗代码为本次新增的代码 。
- 新增加InitialContextFactoryBuilder和InitialContextFactory
public class MyInitialContextFactoryBuilder implements InitialContextFactoryBuilder { @Override public InitialContextFactory createInitialContextFactory(Hashtable environment) throws NamingException { System.out.println("----------------------------"); return new MyInitialContextFactory(); } } public class MyInitialContextFactory implements InitialContextFactory { @Override public Context getInitialContext(Hashtable environment) throws NamingException { try { System.out.println("开始初始值x==================================="); Class clzz = Class.forName("com.luban.MyNameContext"); Object ob = clzz.newInstance(); Method method = ob.getClass().getDeclaredMethod("getNamingContext"); method.setAccessible(true); return (Context) method.invoke(ob); } catch (Exception e) { e.printStackTrace(); } return null; } }因为需要用于NamingContext 这些类,因此获取NamingContext代码并没有写在servlet-test项目中,因为我不想导入NamingContext相关的类,而是直接写到了tomcat项目中。因此在getInitialContext()只能通过反射来获取Context,接下来看获取NamingContext的实现。
- 实现自己的实现NamingContext获取 。
public class MyNameContext { private static final Log log = LogFactory.getLog(NamingContextListener.class); public NamingContext getNamingContext() throws Exception { Hashtableparams = resource.listProperties(); while (params.hasNext()) { String paramName = params.next(); String paramValue = (String) resource.getProperty(paramName); StringRefAddr refAddr = new StringRefAddr(paramName, paramValue); ref.add(refAddr); } } try { if (log.isDebugEnabled()) { log.debug(" Adding resource ref " + resource.getName() + " " + ref); } createSubcontexts(envCtx, resource.getName()); envCtx.bind(resource.getName(), ref); } catch (NamingException e) { log.error("异常", e); } if (("javax.sql.DataSource".equals(ref.getClassName()) || "javax.sql.XADataSource".equals(ref.getClassName())) && resource.getSingleton()) { try { ObjectName on = createObjectName(resource); Object actualResource = envCtx.lookup(resource.getName()); System.out.println(actualResource); // Registry.getRegistry(null, null).registerComponent(actualResource, on, null); // objectNames.put(resource.getName(), on); } catch (Exception e) { log.error("naming.jmxRegistrationFailed", e); } } } protected static ObjectName createObjectName(ContextResource resource) throws MalformedObjectNameException { String domain = null; if (domain == null) { domain = "Catalina"; } ObjectName name = null; String quotedResourceName = ObjectName.quote(resource.getName()); name = new ObjectName(domain + ":type=DataSource" + ",class=" + resource.getType() + ",name=" + quotedResourceName); return (name); } /** * Create all intermediate subcontexts. */ private static void createSubcontexts(javax.naming.Context ctx, String name) throws NamingException { javax.naming.Context currentContext = ctx; StringTokenizer tokenizer = new StringTokenizer(name, "/"); while (tokenizer.hasMoreTokens()) { String token = tokenizer.nextToken(); if ((!token.equals("")) && (tokenizer.hasMoreTokens())) { try { currentContext = currentContext.createSubcontext(token); } catch (NamingException e) { // Silent catch. Probably an object is already bound in // the context. currentContext = (javax.naming.Context) currentContext.lookup(token); } } } } private static LookupRef lookForLookupRef(ResourceBase resourceBase) { String lookupName = resourceBase.getLookupName(); if ((lookupName != null && !lookupName.equals(""))) { return new LookupRef(resourceBase.getType(), lookupName); } return null; } } 上面代码完全模拟了tomcat 的Resource标签加入到NamingContext的操作,最后返回NamingContext对象 。
因此DataSource ds = (DataSource)ctx.lookup(“java:comp/env/jdbc/mysql”);方法实际上调用的是我们自定义的NamingContext的lookup()方法,自定义的NamingContext并没有去除java:的操作,因此在上面设置resource名字时, resource.setName(“java:comp/env/jdbc/mysql”); 需要加上java:,不然通过ctx.lookup(“java:comp/env/jdbc/mysql”); 方法找不到资源 。- 如果没有设置 InitialContextFactoryBuilder ,则获取RUL的scheme ,例如"java:/comp/env" 中java即为这个URL的scheme,接着根据scheme继续判断怎么生成上下文 。
- 根据步骤6,如果scheme不为空, 则根据Context.URL_PKG_PREFIXES变量的值作为工厂的前缀,然后,指定上下文工厂类路径,形式为:前缀.scheme.schemeURLContextFactory ,例如 前缀值为com.sun.jndi , scheme 为java ,则工厂类的路径为com.sun.jndi.java.javaURLContextFactory ,接着调用工厂类的getObjectInstance返回上下文,如果按照上面的操作获取上下文失败,则根据Context.INITIAL_CONTEXT_FACTOR 变量指定的工厂类生成上下文 。
我们接着看getURLOrDefaultInitCtx()方法。
protected Context getURLOrDefaultInitCtx(String name) throws NamingException { if (NamingManager.hasInitialContextFactoryBuilder()) { return getDefaultInitCtx(); } // 通过名字获取scheme ,如java:comp/env/jdbc/mysql ,则scheme为java String scheme = getURLScheme(name); if (scheme != null) { Context ctx = NamingManager.getURLContext(scheme, myProps); if (ctx != null) { return ctx; } } return getDefaultInitCtx(); } private static String getURLScheme(String str) { // 定位出字符串第一个: 的位置 int colon_posn = str.indexOf(':'); // 定位出字符串第一个/的位置 int slash_posn = str.indexOf('/'); // 如果第一个分号的位置小于第一个反斜杠位置,则直接截取0到colon_posn的位置,作为scheme的值 if (colon_posn > 0 && (slash_posn == -1 || colon_posn < slash_posn)) return str.substring(0, colon_posn); return null; }接下来,我们来看getURLContext方法的实现。
public static Context getURLContext(String scheme, Hashtable environment) throws NamingException { Object answer = getURLObject(scheme, null, null, null, environment); if (answer instanceof Context) { return (Context)answer; } else { return null; } } private static Object getURLObject(String scheme, Object urlInfo, Name name, Context nameCtx, Hashtable environment) throws NamingException { ObjectFactory factory = (ObjectFactory)ResourceManager.getFactory( "java.naming.factory.url.pkgs", environment, nameCtx, "." + scheme + "." + scheme + "URLContextFactory", defaultPkgPrefix); if (factory == null) return null; try { return factory.getObjectInstance(urlInfo, name, nameCtx, environment); } catch (NamingException e) { throw e; } catch (Exception e) { NamingException ne = new NamingException(); ne.setRootCause(e); throw ne; } }
从上面方法中得知,如何获取对象工厂的呢?
public static Object getFactory(String propName, Hashtable env, Context ctx, String classSuffix, String defaultPkgPrefix) throws NamingException { // 1. env中不存在key为propName的属性值,则从特定类ctx关联的资源jndiprovider.properties 找到key为propName的属性值 // 2. 如果ctx 为空, 则只能从env 中查找属性值 // 3. 如果ctx 不为空,但env中有propName的属性值,则直接返回env中的属性值 // 4. 如果ctx不为空,而jndiprovider.properties 和 env中都有属性值,则用 env 中的属性值 + ":" + jndiprovider.properties 中的属性值拼起来返回 String facProp = getProperty(propName, env, ctx, true); if (facProp != null) // 如果facProp不为空,则将facProp拼上defaultPkgPrefix值 facProp += (":" + defaultPkgPrefix); else facProp = defaultPkgPrefix; ClassLoader loader = helper.getContextClassLoader(); // 以 classSuffix + " " +facProp 作为key,从弱引用中查找工厂类 String key = classSuffix + " " + facProp; Map
我相信看完上面的代码,再来理解步骤7所说的内容就很简单了,当然需要注意,系统帮我们做了进一层的优化,用了弱引用,方便提升性能,同时也能节省内存, 在本例中 , Factory为org.apache.naming.java.javaURLContextFactory ,因此我们进入javaURLContextFactory的getObjectInstance()方法 。
public Object getObjectInstance(Object obj, Name name, Context nameCtx, Hashtable environment) throws NamingException { // 如果以线程作为key绑定 if ((ContextBindings.isThreadBound()) || // 如果以ClassLoader 作为key绑定 (ContextBindings.isClassLoaderBound())) { // 返回SelectorContext作为Context return new SelectorContext((Hashtable
接下来,我们进入SelectorContext的lookup方法看看。
public Object lookup(String name) throws NamingException { if (log.isDebugEnabled()) { log.debug(sm.getString("selectorContext.methodUsingString", "lookup", name)); } return getBoundContext().lookup(parseName(name)); } protected Context getBoundContext() throws NamingException { // 默认情况下initialContext为false if (initialContext) { String ICName = IC_PREFIX; if (ContextBindings.isThreadBound()) { ICName += ContextBindings.getThreadName(); } else if (ContextBindings.isClassLoaderBound()) { ICName += ContextBindings.getClassLoaderName(); } Context initialContext = ContextBindings.getContext(ICName); if (initialContext == null) { // Allocating a new context and binding it to the appropriate // name initialContext = new NamingContext(env, ICName); ContextBindings.bindContext(ICName, initialContext); } return initialContext; } else { if (ContextBindings.isThreadBound()) { return ContextBindings.getThread(); } else { return ContextBindings.getClassLoader(); } } } protected String parseName(String name) throws NamingException { // prefix为java: ,如果name 以 java:开头,则截除它 if ((!initialContext) && (name.startsWith(prefix))) { return name.substring(prefixLength); } else { if (initialContext) { return name; } else { throw new NamingException (sm.getString("selectorContext.noJavaUrl")); } } }因为在NamingContextListener 以 classLoader 为key ,NamingContext为value保存到ContextBindings的clBindings属性中,我们看看getClassLoader方法又是从哪里取全称空间的呢?
public static Context getClassLoader() throws NamingException { ClassLoader cl = Thread.currentThread().getContextClassLoader(); Context context = null; do { context = clBindings.get(cl); if (context != null) { return context; } // 如果取不到,以父加载器作为key去取 } while ((cl = cl.getParent()) != null); throw new NamingException(sm.getString("contextBindings.noContextBoundToCL")); }
正因为不同的类加载器存储了不同的NamingContext,而不同的StandardContext使用不同的类加载器,所以才会导致http://localhost:8080/ServletDemo/MyServlet不会抛出异常,而http://localhost:8080/servelet-test-1.0/MyServlet会抛出异常。
接下来,我们看lookup方法是如何查找到相应的类。
进入 lookup()方法 。
public Object lookup(String name) throws NamingException {
return lookup(new CompositeName(name), true);
}上面这行代码看起来很简单,但CompositeName实现还是很复杂的,在lookup方法内部,用到了很多的get(0),getSuffix(1),那来看看效果 。
public static void main(String[] args) throws Exception { String value = "comp/env/jdbc/mysql"; Name name = new CompositeName(value); String b = name.get(0); System.out.println( b); Name suffix_1 = name.getSuffix(1); System.out.println(suffix_1); } comp env/jdbc/mysql我们进入CompositeName的构造方法。
public CompositeName(String n) throws InvalidNameException { impl = new NameImpl(null, n); // null means use default syntax }
CompositeName构造方法实际上是调用了NameImpl的构造函数,我们进入NameImpl构造方法 。
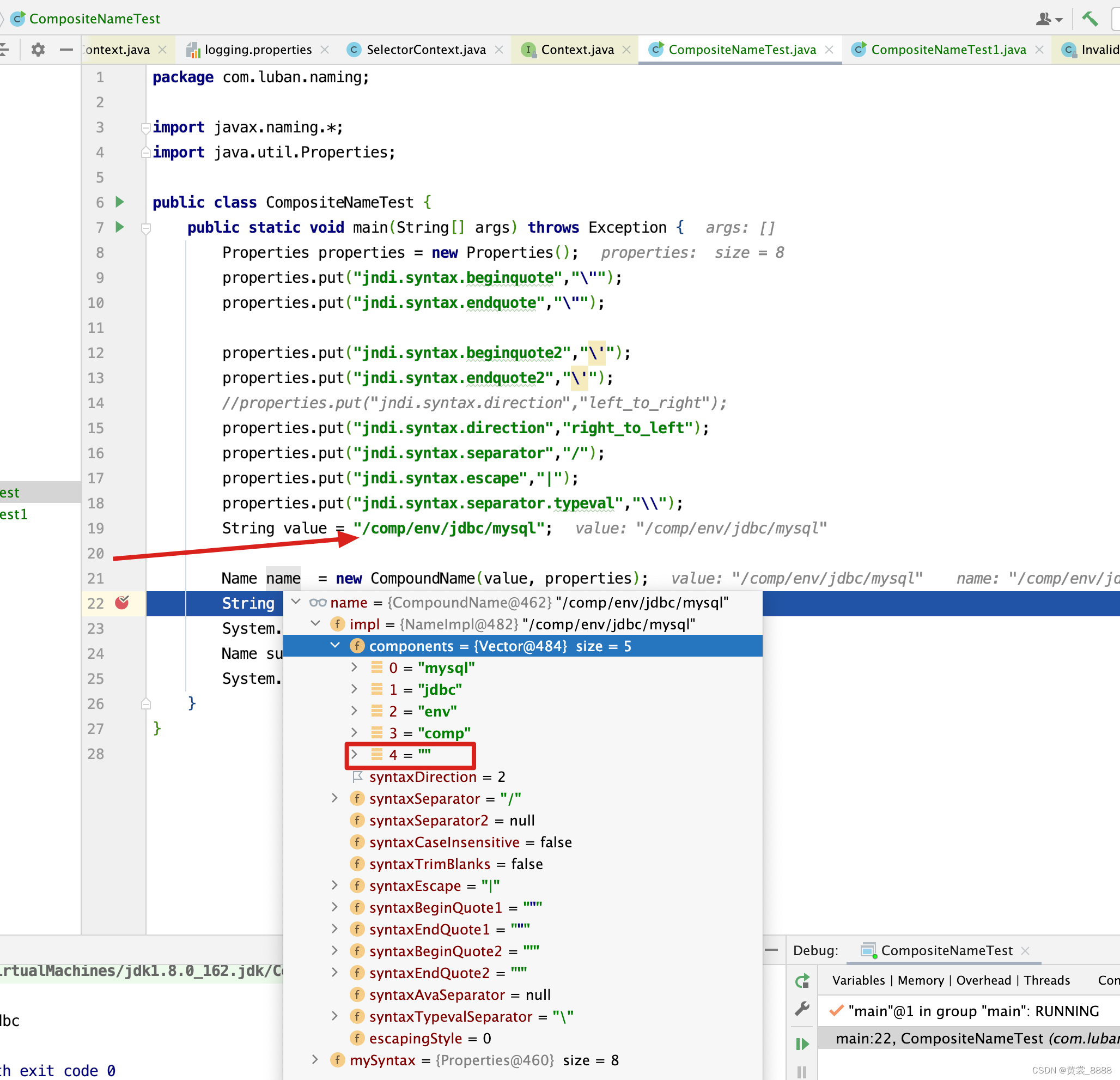
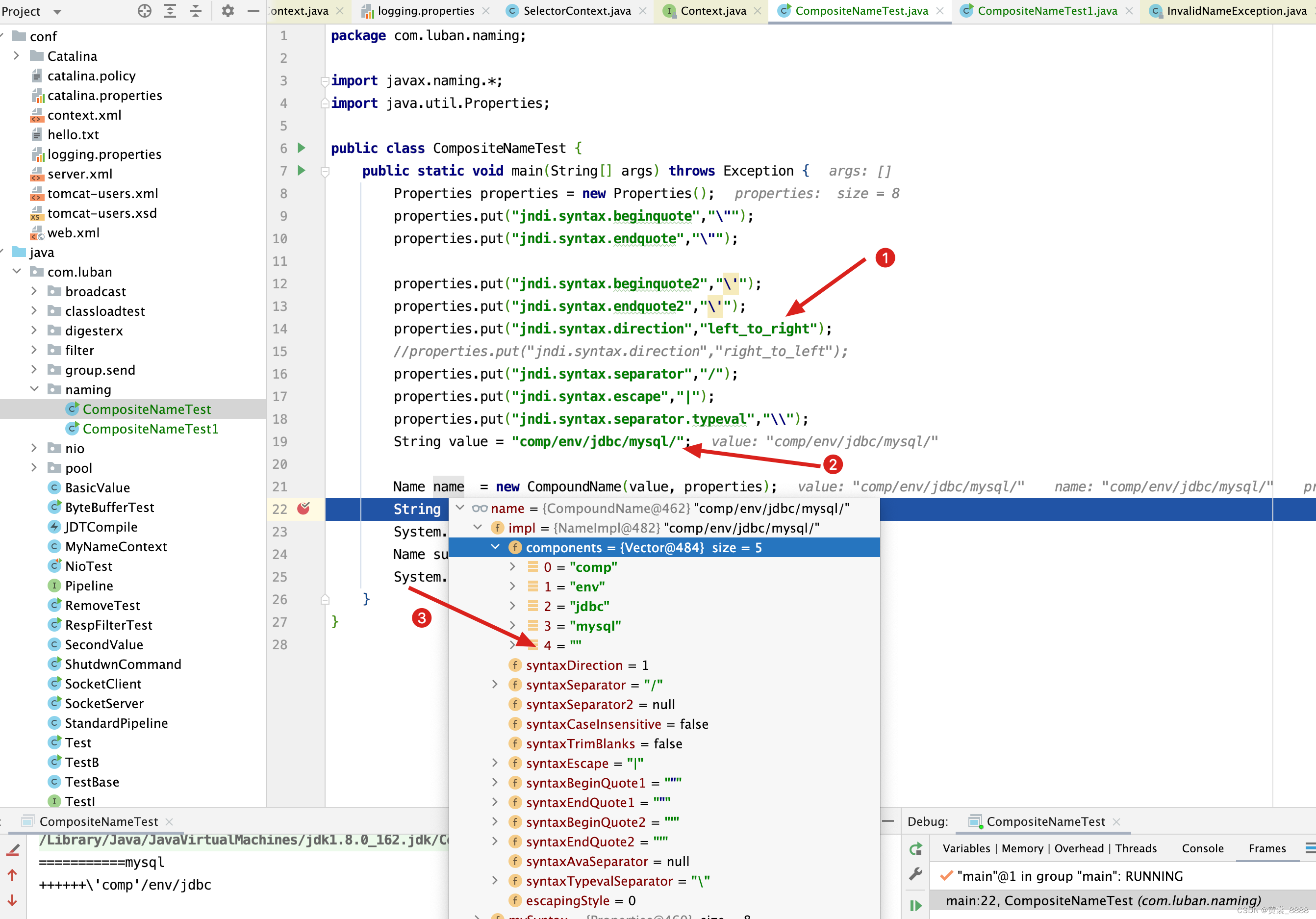
NameImpl(Properties syntax, String n) throws InvalidNameException { this(syntax); // 名称读取可以从 左向右 也可以从 右向左 ,我们可以通过 // jndi.syntax.direction参数来配置, left_to_right 表示从左向右 // right_to_left 表示从右向左 ,默认从左向右查找 boolean rToL = (syntaxDirection == RIGHT_TO_LEFT); boolean compsAllEmpty = true; int len = n.length(); for (int i = 0; i < len; ) { i = extractComp(n, i, len, components); String comp = rToL ? components.firstElement() : components.lastElement(); //compsAllEmpty表示所有的元素都为空的意思 , // 如 n = "/" 时,compsAllEmpty = true if (comp.length() >= 1) { // 如果comp不为空,则compsAllEmpty为false compsAllEmpty = false; } if (i < len) { i = skipSeparator(n, i); // 如果获取到的元素为空,并且是最后一个分隔符 // 则用 "" 空串来替代,当然,如果是从右往左读取,则插入到components的开头 // 如果是从左往右读取,则插入到components的结尾 if ((i == len) && !compsAllEmpty) { // Trailing separator found. Add an empty component. if (rToL) { components.insertElementAt("", 0); } else { components.addElement(""); } } } } } // 判断n的第i个位置的字符是不是分隔符 private final int skipSeparator(String name, int i) { if (isA(name, i, syntaxSeparator)) { i += syntaxSeparator.length(); } else if (isA(name, i, syntaxSeparator2)) { i += syntaxSeparator2.length(); } return (i); }
其实上面for循环内部的代码还是很简单的,分两种情况,如果是从右往左读取,如下所示, 当读取到最后一个字符为分隔符/时,则填充为"“空串,如下components的第4个元素所示。
当我们配置从左往右读取时,最后一个元素为分隔符 / 时, 则填充为”" 空字符串。
相信此时此刻,大家对for循环内的代码有所理解,但是大家肯定还不是全部理解,因为还有一个方法extractComp我们并没有深入分析,接下来,我们进入extractComp()方法 。 我的天呐,方法一大堆,到底做了哪些事情呢?private final int extractComp(String name, int i, int len, Vector
comps) throws InvalidNameException { String beginQuote; String endQuote; boolean start = true; boolean one = false; StringBuffer answer = new StringBuffer(len); while (i < len) { // 默认情况下,syntaxBeginQuote1 为 " 双引号 // syntaxBeginQuote2 为 ' 单引号 if (start && ((one = isA(name, i, syntaxBeginQuote1)) || isA(name, i, syntaxBeginQuote2))) { // 如果第一个字符为双引号,则 beginQuote 为双引号, endQuote 也为双引号 // 如果第一个字符为单引号,那么 beginQuote 和 endQuote 都为单引号 beginQuote = one ? syntaxBeginQuote1 : syntaxBeginQuote2; endQuote = one ? syntaxEndQuote1 : syntaxEndQuote2; if (escapingStyle == STYLE_NONE) { escapingStyle = one ? STYLE_QUOTE1 : STYLE_QUOTE2; } // 下面for循环的用意也很明显,从begineQuote开始 // 找到他的字符串中下一个endQuote出现的位置,找到则退出循环 for (i += beginQuote.length(); ((i < len) && !name.startsWith(endQuote, i)); i++) { // 如果遇到转义字符,则跳过它 if (isA(name, i, syntaxEscape) && isA(name, i + syntaxEscape.length(), endQuote)) { i += syntaxEscape.length(); } // 如果字符不是endQuote ,并且不是转义字符,则追加到answer中 answer.append(name.charAt(i)); // copy char } // 如果 字符串已经找到结尾还没有找到endQuote ,则抛出异常 // 如 'comp/env/jdbc/mysql/ ,因为只有开头的单引号 // 并没有结束的单引号,则抛出异常 if (i >= len) throw new InvalidNameException(name + ": no close quote"); new Exception("no close quote"); //i 越过endQuote i += endQuote.length(); // 如果i = 字符串的长度或name[i] 位置是分隔符,则退出循环 if (i == len || isSeparator(name, i)) { break; } // 如果endQuote后面还有字符,则抛出异常 //如: 'com'p/env/jdbc/mysql/ , 在com后面是'引号,但是 // 单引号后面还有字符p,则抛出异常 throw (new Exception( throw (new InvalidNameException(name + ": close quote appears before end of component")); // 如果读取到分隔符,则退出循环 } else if (isSeparator(name, i)) { break; //如果开头是转义字符, } else if (isA(name, i, syntaxEscape)) { // 并且转义字符后面是 \ , " , ' , / 则越过转义字符 // 如 'comp'/env/jdbc/mysql 读取成 comp/env/jdbc/mysql // 如 \'comp'/env/jdbc/mysql 被读取成'comp'/env/jdbc/mysql if (isMeta(name, i + syntaxEscape.length())) { i += syntaxEscape.length(); if (escapingStyle == STYLE_NONE) { escapingStyle = STYLE_ESCAPE; } // 但如果只剩转义字符,则抛出异常,如 // 字符串为 \\ ,则会抛出如下异常 } else if (i + syntaxEscape.length() >= len) { throw (new InvalidNameException(name + ": unescaped " + syntaxEscape + " at end of component")); } } else if (isA(name, i, syntaxTypevalSeparator) && ((one = isA(name, i+syntaxTypevalSeparator.length(), syntaxBeginQuote1)) || isA(name, i+syntaxTypevalSeparator.length(), syntaxBeginQuote2))) { beginQuote = one ? syntaxBeginQuote1 : syntaxBeginQuote2; endQuote = one ? syntaxEndQuote1 : syntaxEndQuote2; i += syntaxTypevalSeparator.length(); answer.append(syntaxTypevalSeparator+beginQuote); // add back for (i += beginQuote.length(); ((i < len) && !name.startsWith(endQuote, i)); i++) { if (isA(name, i, syntaxEscape) && isA(name, i + syntaxEscape.length(), endQuote)) { i += syntaxEscape.length(); } answer.append(name.charAt(i)); // copy char } if (i >= len) throw new InvalidNameException(name + ": typeval no close quote"); i += endQuote.length(); answer.append(endQuote); // add back if (i == len || isSeparator(name, i)) { break; } throw (new InvalidNameException(name.substring(i) + ": typeval close quote appears before end of component")); } answer.append(name.charAt(i++)); start = false; } // 如果是从右向左读取,总是将读取到的字符插到comps的第0个位置 // 如果从左往右读取,总是将读取到的字符追加到comps的结尾 if (syntaxDirection == RIGHT_TO_LEFT) comps.insertElementAt(answer.toString(), 0); else comps.addElement(answer.toString()); return i; } 加粗代码,我相信大家理解起来就有些困难了,用意是什么呢?不过细心的读者肯定发现,假如字符串为\‘comp’/env/jdbc/mysql,而想让\'comp’作为名称查询,而 \ 不想作为转义字符。 通过现有的模式就解决了不了,因此加粗代码就起作用了。
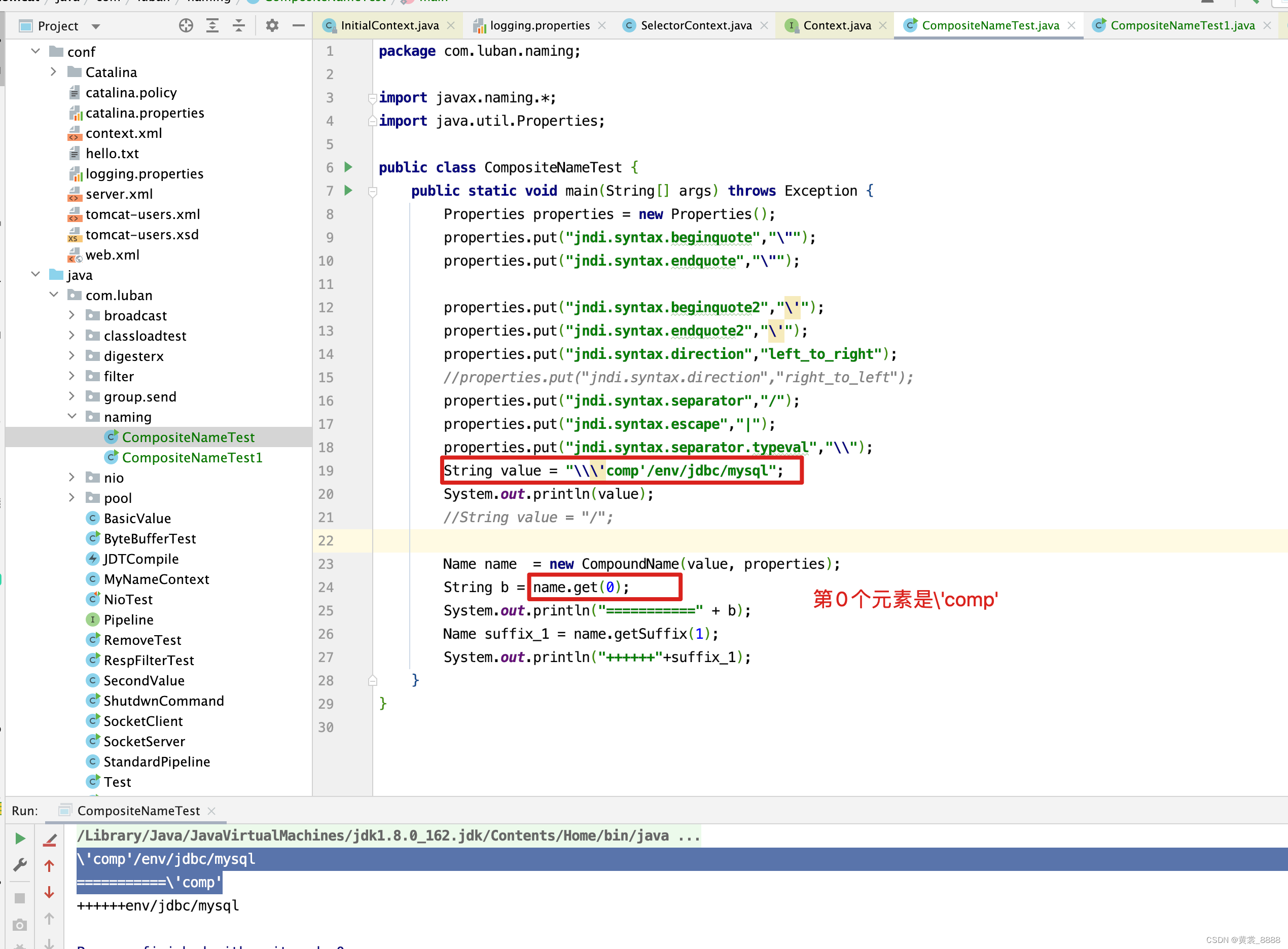
在上面例子中,我们通过设置 jndi.syntax.escape为 | 作为转义字符,而\ 就可以作为普通的字符串来处理了。
我相信读者已经理解了 extractComp方法的用意了。- 如果第一个字符是双引号或单引号,则后面一定存在一个单引号或双引号,并且单引号或双引号后面一定是 分隔符或 已经结束 。
- 如果是转义字符,则跳过它
- 如果第一个字符是分隔符,则用""空串来代替元素。
- 如果查找的名称中有转义字符,我们可以自定义一套解析规则 。
并不是我一定要来扣这些细节,从这些细节中,能看出框架的博大精深,希望能从中得到启发。 那言归正转,记得在分析Tomcat 源码时,还有一个方法createNamingContext()没有分析,我们先分析这个方法,再去看lookup方法 。
private void createNamingContext() throws NamingException { // 如果当前发起事件的容器是Server,则compCtx和envCtx都为namingContext if (container instanceof Server) { compCtx = namingContext; envCtx = namingContext; } else { // 否则创建子名称空间comp及孙名称空间env ,这也是什么在使用时会加上前缀 comp/env的原因 compCtx = namingContext.createSubcontext("comp"); envCtx = compCtx.createSubcontext("env"); } int i; if (log.isDebugEnabled()) log.debug("Creating JNDI naming context"); // 为了避免空指针异常, 如果namingResources为空,则先初始化 if (namingResources == null) { namingResources = new NamingResources(); namingResources.setContainer(container); } // 我们配置的
// 在这里取出 ContextResourceLink[] resourceLinks = namingResources.findResourceLinks(); for (i = 0; i < resourceLinks.length; i++) { addResourceLink(resourceLinks[i]); } // Resources ContextResource[] resources = namingResources.findResources(); for (i = 0; i < resources.length; i++) { addResource(resources[i]); } // Resources Env ContextResourceEnvRef[] resourceEnvRefs = namingResources.findResourceEnvRefs(); for (i = 0; i < resourceEnvRefs.length; i++) { addResourceEnvRef(resourceEnvRefs[i]); } // Environment entries ContextEnvironment[] contextEnvironments = namingResources.findEnvironments(); for (i = 0; i < contextEnvironments.length; i++) { addEnvironment(contextEnvironments[i]); } // EJB references ContextEjb[] ejbs = namingResources.findEjbs(); for (i = 0; i < ejbs.length; i++) { addEjb(ejbs[i]); } // Message Destination References MessageDestinationRef[] mdrs = namingResources.findMessageDestinationRefs(); for (i = 0; i < mdrs.length; i++) { addMessageDestinationRef(mdrs[i]); } // WebServices references ContextService[] services = namingResources.findServices(); for (i = 0; i < services.length; i++) { addService(services[i]); } // Binding a User Transaction reference if (container instanceof Context) { try { Reference ref = new TransactionRef(); compCtx.bind("UserTransaction", ref); ContextTransaction transaction = namingResources.getTransaction(); if (transaction != null) { Iterator params = transaction.listProperties(); while (params.hasNext()) { String paramName = params.next(); String paramValue = (String) transaction.getProperty(paramName); StringRefAddr refAddr = new StringRefAddr(paramName, paramValue); ref.add(refAddr); } } } catch (NameAlreadyBoundException e) { // Ignore because UserTransaction was obviously // added via ResourceLink } catch (NamingException e) { logger.error(sm.getString("naming.bindFailed", e)); } } // Binding the resources directory context if (container instanceof Context) { try { compCtx.bind("Resources", ((Container) container).getResources()); } catch (NamingException e) { logger.error(sm.getString("naming.bindFailed", e)); } } } 对于Tomcat来说,我们把上面的实现JNDI 放进Tomcat 中就可以动作了, 在Tomcat初始化期间,要完成JND所有必要的工作,组成一个树形结构的对象供Web 程序开发使用,那么整个Tomcat集成JNDI所有必要工作,组成一个树形结构的对象供Web程序开发使用,那么,整个Tomcat集成JNDI的过程可以用图15.11表述,在Tomcat 初始化时,通过Digester框架将server.xml 的描述映射到对象,在StandardServer或StandardContext中创建了两个对象,其中,一个是NamingResources,它包含不再的类别的命名对象属性,例如,我们常见的数据源用ContextResources 保存命名对象属性, 除此之外,还有ContextEjb 命名对象属性,ContextEnvironment命名对象属性, ContextService 命名对象属性等, 另外一个创建一个NamingContextListener,此监听器将在初始化时利用ContextResources 里面的属性创建命名上下文,并组织成树状,完成以上操作后, 我们也就全部完成 了Tomcat的JNDI的集成工作 。

Tomcat 中包含了全局与局部的两种不同的命名资源 , 全局命名资源也就是上面提到的, Tomcat 启动时将server.xml 配置文件里面的GlobalNamingResources 节点通过Digester 框架映射到一个NamingResources对象中,当然,这个对象里面包含了不同的类型的资源对象,同时创建一个NamingContextListener监听器, 这个监听器负责的重要事情就是在Tomcat初始化期间触发一些响应事件,接收到事件后,将完成对命名资源的所有创建,组织,绑定工作,使之符合JNDI 标准,而创建,组织,绑定等是根据NamingResources对象描述的资源属性中进行处理, 绑定的路径由配置文件的Resource 节点的name属性决定,name即为JNDI对象树的分支节点,例如,如果name为"jdbc/myDB",那么此对象就可以通过"java:jdbc/myDB" 访问 , 而树的位置应该是jdbc/myDB ,但在Web 应用中是无法直接访问全局命名资源,因为根据Web应用类加载器无法找到该全局命名上下文,由于这些资源是全局命名资源,因此它们都必须放在Server作用域中 。
对于局部命名资源,工作机制也是相似的, 如图15.12 所示, 局部资源同样主要由NamingResources 与 NamingContextListener两个对象完成所需要的工作,作为JNDI对象树,NamingContext实现了JNDI的各种标准接口与方法 。 NamingResources描述的对象资源都将绑定到这个对象树上,基础分支为"comp/env",每个Web应用都会有一个自己的命名上下文 , 组织过程中NamingContext将与相应的Web应用类加载器进行绑定, 不同的Web应用只能调用自己的类加载器对应的JNDI对象树, 互相隔离 , 互不影响 ,当Web 应用使用JNDI时,通过JNDI运行机制进入不同的命名上下文中查找命名对象 。
两种配置方式本质上是一样的, 二者只是分别从服务器级别和应用级别提供了各自的配置方式,最终达到效果都一样,另外,为什么这样配置后生成的资源只能由相应的Web应用访问呢? 通过什么机的机制实现了不同的应用之间的隔离呢? 因为每个Web应用都有自己的类加载器,为了提供不同的Web 应用之间的资源隔离功能,Tomcat 把这些命名资源与类加载器进行了绑定 , 当我们在Web应用中查找命名资源时, 将会根据本身的Web应用类加载器获取对应的命名上下文对象, 当然,进行查找,由此达到隔离资源的效果,也就是说,每个Web应用只能访问自己的命名资源 。
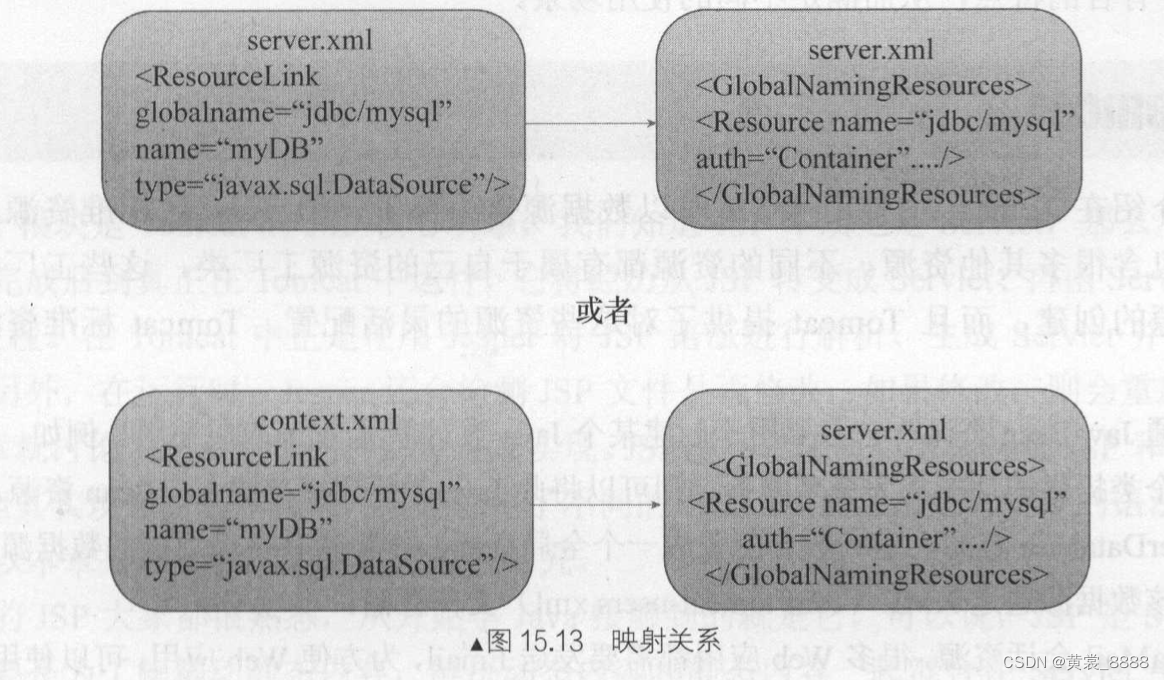
通过配置文件可以清晰的看出映射关系,它们之间的关系如图15.13所示 , 映射关系可能为server.xml(ResourceLink )->server.xml(GlobalNamingResources) ;也可能是context.xml(ResourceLink) ->server.xml(GlobalNamingResources) ,这里把ResourceLink 作为资源连接引用得到全局的命名资源 。
可能大家看了上面理论上的东西还是比较模糊,之前我们已经知道,Digester框架会将标签封装成ContextResourceLink对象存储在namingResources的resourceLinks属性中, 通过ContextResourceLink[] resourceLinks =
namingResources.findResourceLinks();取出所有StandardContext对应的ContextResourceLink,再通过addResourceLink()加入到jndi框架中。 那我们进入addResourceLink()方法,看其如何实现。

public void addResourceLink(ContextResourceLink resourceLink) { // 创建引用类型的资源 Reference ref = new ResourceLinkRef (resourceLink.getType(), resourceLink.getGlobal(), resourceLink.getFactory(), null); // Degister框架会将除基本属性type ,global , factory之外的属性封装到properties 中 // 通过listProperties取出,并封装成StringRefAddr存储于addrs中 Iterator
i = resourceLink.listProperties(); while (i.hasNext()) { String key = i.next(); Object val = resourceLink.getProperty(key); if (val!=null) { StringRefAddr refAddr = new StringRefAddr(key, val.toString()); ref.add(refAddr); } } javax.naming.Context ctx = "UserTransaction".equals(resourceLink.getName()) ? compCtx : envCtx; try { if (logger.isDebugEnabled()) log.debug(" Adding resource link " + resourceLink.getName()); // 创建子上下文 createSubcontexts(envCtx, resourceLink.getName()); // 将resourceLink与ctx绑定 ctx.bind(resourceLink.getName(), ref); } catch (NamingException e) { logger.error(sm.getString("naming.bindFailed", e)); } ResourceLinkFactory.registerGlobalResourceAccess( getGlobalNamingContext(), resourceLink.getName(), resourceLink.getGlobal()); } 关于上面listProperties()我们可以举个例子, 修改

看到没有,如果ContextResourceLink中没有的属性,会封装到properties属性中。private void createSubcontexts(javax.naming.Context ctx, String name) throws NamingException { javax.naming.Context currentContext = ctx; StringTokenizer tokenizer = new StringTokenizer(name, "/"); while (tokenizer.hasMoreTokens()) { String token = tokenizer.nextToken(); if ((!token.equals("")) && (tokenizer.hasMoreTokens())) { try { currentContext = currentContext.createSubcontext(token); } catch (NamingException e) { currentContext = (javax.naming.Context) currentContext.lookup(token); } } } }
要理解上面代码StringTokenizer的使用,先来看一个例子。
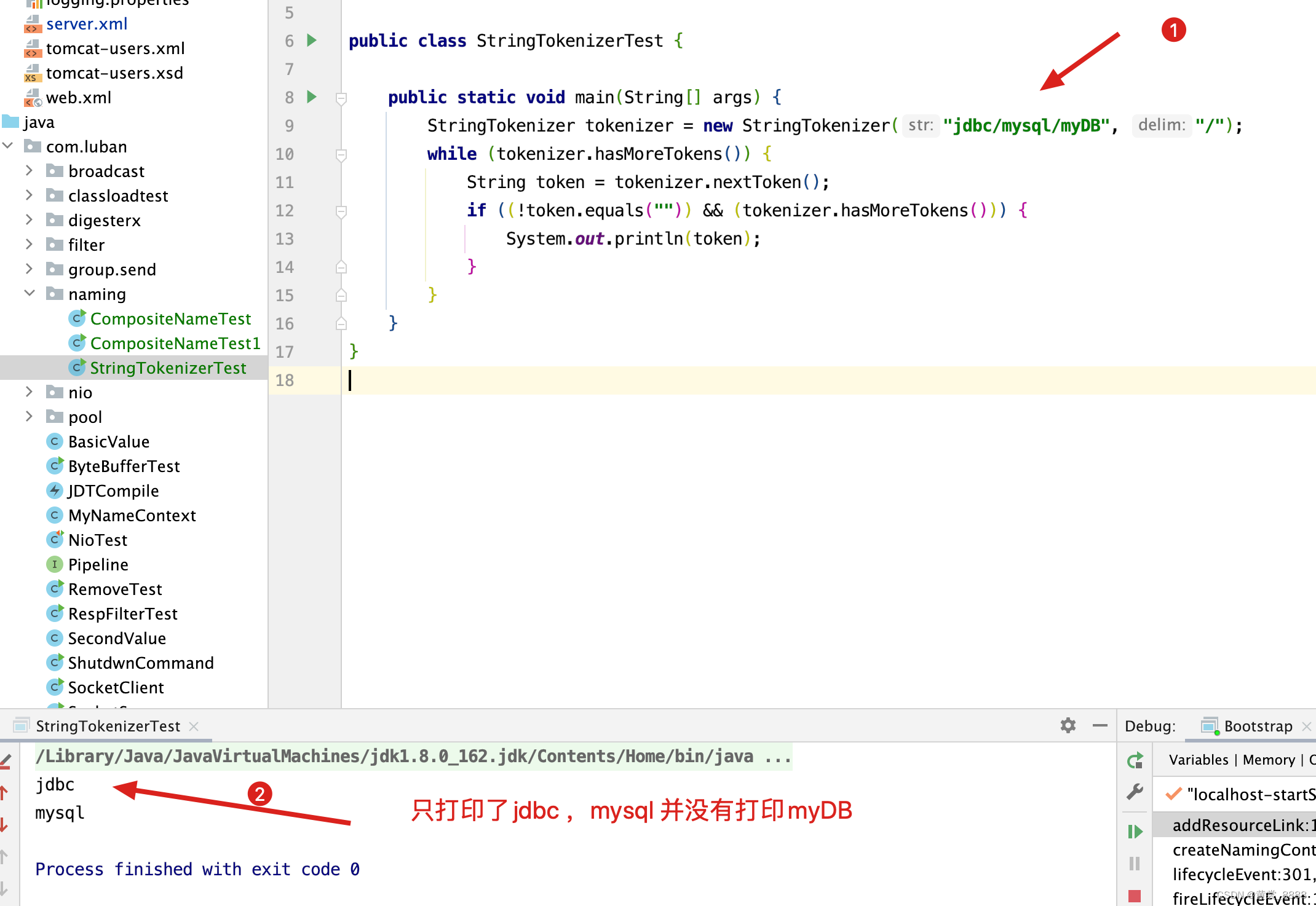 通过上面这个例子可以看到,jdbc 和 mysql可以创建命名上下文,而myDB作为叶子节点,是不会创建上下文的,而是会存储具体需要创建对象的信息。 先来看createSubcontext是如何创建 ,但需要注意currentContext = currentContext.createSubcontext(token);上下文树建立的关建,如先创建jdbc上下文,再通过jdbc为其创建子上下文mysql。
通过上面这个例子可以看到,jdbc 和 mysql可以创建命名上下文,而myDB作为叶子节点,是不会创建上下文的,而是会存储具体需要创建对象的信息。 先来看createSubcontext是如何创建 ,但需要注意currentContext = currentContext.createSubcontext(token);上下文树建立的关建,如先创建jdbc上下文,再通过jdbc为其创建子上下文mysql。public Context createSubcontext(String name) throws NamingException { return createSubcontext(new CompositeName(name)); } public Context createSubcontext(Name name) throws NamingException { if (!checkWritable()) { return null; } NamingContext newContext = new NamingContext(env, this.name); bind(name, newContext); newContext.setExceptionOnFailedWrite(getExceptionOnFailedWrite()); return newContext; }
每一次创建子上下文都会创建NamingContext对象,并且将name与之绑定,我们进入bind()方法 。
public void bind(Name name, Object obj) throws NamingException { bind(name, obj, false); } protected void bind(Name name, Object obj, boolean rebind) throws NamingException { // 如果当前是只读的,抛出异常或直接返回,是否抛出异常 和 exceptionOnFailedWrite值有关 if (!checkWritable()) { return; } // 去除掉空字符串, 如 jdbc/mysql///myDB ,被转化为jdbc/mysql/myDB while ((!name.isEmpty()) && (name.get(0).length() == 0)) name = name.getSuffix(1); if (name.isEmpty()) throw new NamingException (sm.getString("namingContext.invalidName")); //bindings是一个hashmap对象,从当前Context的bindings中获取NamingEntry NamingEntry entry = bindings.get(name.get(0)); // 如name为 jdbc/mysql/myDB ,name.get(0) 为 jdbc // 则name.size() = 3 > 0 if (name.size() > 1) { // 如果entry为空,则抛出异常 // 也就是说,来绑定jdbc/mysql/myDB时,那么jdbc和mysql 的上下文一定存在,如果不存在,则抛出异常 // 为什么会这么肯定entry一定存在呢?细心的读者肯定会发现 // 先调用createSubcontexts(envCtx, resourceLink.getName()); 这一行代码,再调用下面这一行绑定代码 // ctx.bind(resourceLink.getName(), ref); // 而createSubcontexts方法中用了一个for 循环,循环创建子孙上下文 if (entry == null) { throw new NameNotFoundException(sm.getString( "namingContext.nameNotBound", name, name.get(0))); } // 如果entry的类型是上下文,则递归绑定上下文 if (entry.type == NamingEntry.CONTEXT) { if (rebind) { ((Context) entry.value).rebind(name.getSuffix(1), obj); } else { ((Context) entry.value).bind(name.getSuffix(1), obj); } } else { throw new NamingException (sm.getString("namingContext.contextExpected")); } } else { // 如果并不是重新绑定,但entry已经存在,则抛出异常 if ((!rebind) && (entry != null)) { throw new NameAlreadyBoundException (sm.getString("namingContext.alreadyBound", name.get(0))); } else { // 其实大家不用担心,大部分情况都是走getStateToBind()方法中的加粗代码 // 也就是toBind = obj Object toBind = NamingManager.getStateToBind(obj, name, this, env); // 如果toBind是上下文,则创建上下文类型的NamingEntry if (toBind instanceof Context) { entry = new NamingEntry(name.get(0), toBind, NamingEntry.CONTEXT); } else if (toBind instanceof LinkRef) { entry = new NamingEntry(name.get(0), toBind, NamingEntry.LINK_REF); // 如果toBind是引用类型,则创建引用类型的NamingEntry } else if (toBind instanceof Reference) { entry = new NamingEntry(name.get(0), toBind, NamingEntry.REFERENCE); } else if (toBind instanceof Referenceable) { toBind = ((Referenceable) toBind).getReference(); entry = new NamingEntry(name.get(0), toBind, NamingEntry.REFERENCE); } else { entry = new NamingEntry(name.get(0), toBind, NamingEntry.ENTRY); } // 将创建好的NamingEntry存储于bindings中 bindings.put(name.get(0), entry); } } } public static Object getStateToBind(Object obj, Name name, Context nameCtx, Hashtable environment) throws NamingException { FactoryEnumeration factories = ResourceManager.getFactories( Context.STATE_FACTORIES, environment, nameCtx); if (factories == null) { return obj; } // Try each factory until one succeeds StateFactory factory; Object answer = null; while (answer == null && factories.hasMore()) { factory = (StateFactory)factories.next(); answer = factory.getStateToBind(obj, name, nameCtx, environment); } return (answer != null) ? answer : obj; }
此时此刻,我相信你对ctx.bind(resourceLink.getName(), ref);这一行代码理解也是迎刃而解。

聪明的读者肯定发现了,建立了一棵ctx(NamingContext)->jdbc(NamingEntry)->mysql(NamingEntry)->ResourceLinkRef的树,但是这和我们获取DataSource有什么关系呢?不急,请听我尾尾道来,其实我们知道GlobalNamingResources 标签的解析肯定在Context标签之前解析,因为容器的启动肯定先启动Server 再会启动Context ,我们通过这样本末倒置的方式,主要想让大家带着疑问去看源码,而不是一味的接收新的知识,如果只知道学习,不知道思考,这样的学习也没有太大用。
通过Digester框架分析得到,GlobalNamingResources的Resource标签最终封装成ContextResource对象存储于Server的namingResources对象的resources属性中,通过findResources()方法可以获取所有的ContextResource,接着进入addResource()方法 。
public void addResource(ContextResource resource) { //
// 如我们resource标签中配置了lookupName标识 Reference ref = lookForLookupRef(resource); if (ref == null) { // 构建resourceRef 对象 ref = new ResourceRef(resource.getType(), resource.getDescription(), resource.getScope(), resource.getAuth(), resource.getSingleton()); // 多余的属性放到properties中 Iterator params = resource.listProperties(); while (params.hasNext()) { String paramName = params.next(); String paramValue = (String) resource.getProperty(paramName); StringRefAddr refAddr = new StringRefAddr(paramName, paramValue); ref.add(refAddr); } } try { if (log.isDebugEnabled()) { log.debug(" Adding resource ref " + resource.getName() + " " + ref); } // 创建子孙上下文 createSubcontexts(envCtx, resource.getName()); // 开始绑定 envCtx.bind(resource.getName(), ref); } catch (NamingException e) { logger.error(sm.getString("naming.bindFailed", e)); } // 如果Resource标签配置的Type是javax.sql.DataSource或javax.sql.XADataSource if (("javax.sql.DataSource".equals(ref.getClassName()) || "javax.sql.XADataSource".equals(ref.getClassName())) && resource.getSingleton()) { try { ObjectName on = createObjectName(resource); Object actualResource = envCtx.lookup(resource.getName()); Registry.getRegistry(null, null).registerComponent(actualResource, on, null); objectNames.put(resource.getName(), on); } catch (Exception e) { logger.warn(sm.getString("naming.jmxRegistrationFailed", e)); } } } private static LookupRef lookForLookupRef(ResourceBase resourceBase) { String lookupName = resourceBase.getLookupName(); if ((lookupName != null && !lookupName.equals(""))) { return new LookupRef(resourceBase.getType(), lookupName); } return null; } LookupRef类和ResourceRef的最大区别在于getDefaultFactoryClassName方法,LookupRef的默认工厂类是org.apache.naming.factory.LookupFactory,而ResourceRef的默认工厂类是org.apache.naming.factory.ResourceFactory,在lookup()方法中通过NamingManager.getObjectInstance
(entry.value, name, this, env)方法最终会调用 Factory中的getObjectInstance方法返回对象。 接下来我们先来看LookupFactory的getObjectInstance方法实现。public Object getObjectInstance(Object obj, Name name, Context nameCtx, Hashtable environment) throws Exception { String lookupName = null; Object result = null; // 如果Reference 是LookupRef if (obj instanceof LookupRef) { Reference ref = (Reference) obj; ObjectFactory factory = null; RefAddr lookupNameRefAddr = ref.get("lookup-name"); //public LookupRef(String resourceType, String factory, String factoryLocation, String lookupName) { // super(resourceType, factory, factoryLocation); // if (lookupName != null && !lookupName.equals("")) { // RefAddr ref = new StringRefAddr("lookup-name", lookupName); // add(ref); // } //} if (lookupNameRefAddr != null) { //lookupNameRefAddr.getContent()的值也就是之前配置的lookupName值 lookupName = lookupNameRefAddr.getContent().toString(); } try { if (lookupName != null) { // 如果两个Resource中配置了相同的lookupName值,则抛出异常 if (!names.get().add(lookupName)) { String msg = sm.getString("lookupFactory.circularReference", lookupName); NamingException ne = new NamingException(msg); log.warn(msg, ne); throw ne; } } // 如果Resource标签中配置了factory,则调用factory的getObjectInstance方法获取对象 // 如果没有配置,则通过new InitialContext().lookup(name)方法查找 RefAddr factoryRefAddr = ref.get(Constants.FACTORY); if (factoryRefAddr != null) { String factoryClassName = factoryRefAddr.getContent().toString(); // Loading factory ClassLoader tcl = Thread.currentThread().getContextClassLoader(); Class factoryClass = null; if (tcl != null) { try { factoryClass = tcl.loadClass(factoryClassName); } catch (ClassNotFoundException e) { NamingException ex = new NamingException( sm.getString("lookupFactory.loadFailed")); ex.initCause(e); throw ex; } } else { try { factoryClass = Class.forName(factoryClassName); } catch (ClassNotFoundException e) { NamingException ex = new NamingException( sm.getString("lookupFactory.loadFailed")); ex.initCause(e); throw ex; } } if (factoryClass != null) { try { factory = (ObjectFactory) factoryClass.getConstructor().newInstance(); } catch (Throwable t) { if (t instanceof NamingException) throw (NamingException) t; NamingException ex = new NamingException( sm.getString("lookupFactory.createFailed")); ex.initCause(t); throw ex; } } } if (factory != null) { result = factory.getObjectInstance(obj, name, nameCtx, environment); } else { if (lookupName == null) { throw new NamingException(sm.getString("lookupFactory.createFailed")); } else { result = new InitialContext().lookup(lookupName); } } Class clazz = Class.forName(ref.getClassName()); if (result != null && !clazz.isAssignableFrom(result.getClass())) { String msg = sm.getString("lookupFactory.typeMismatch", name, ref.getClassName(), lookupName, result.getClass().getName()); NamingException ne = new NamingException(msg); log.warn(msg, ne); if (isInstance(result.getClass(), "java.lang.AutoCloseable")) { try { Method m = result.getClass().getMethod("close"); m.invoke(result); } catch (Exception e) { // Ignore } } throw ne; } } finally { names.get().remove(lookupName); } } return result; }现在所有的矛头都指向了lookup()方法的具体实现, 接下来,我们进入lookup()方法 。
protected Object lookup(Name name, boolean resolveLinks) throws NamingException { // 移除掉所有的空串 while ((!name.isEmpty()) && (name.get(0).length() == 0)) name = name.getSuffix(1); if (name.isEmpty()) { return new NamingContext(env, this.name, bindings); } // 获取name的第0个元素 // 如 comp/env/jdbc/mysql ,name.get(0) 为 comp NamingEntry entry = bindings.get(name.get(0)); // 因为 createSubcontexts(envCtx, resource.getName()); // envCtx.bind(resource.getName(), ref); 这两行代码是成对调用 // 如在bind 这 comp/env/jdbc/mysql 这个名名称时,则comp/env/jdbc // 的上下文肯定建立好了,如果没有创建好,抛出异常 if (entry == null) { throw new NameNotFoundException (sm.getString("namingContext.nameNotBound", name, name.get(0))); } // 如果name.size() 大于 0,说明没有找到叶子节点,继续向下寻找 if (name.size() > 1) { // 如果entry不是叶子节点,其类型一定是上下文,如果不是抛出异常 if (entry.type != NamingEntry.CONTEXT) { throw new NamingException (sm.getString("namingContext.contextExpected")); } // 递归查找,直到叶子节点,也就是name.size() == 1 时 return ((Context) entry.value).lookup(name.getSuffix(1)); } else { // 如果是链接类型,目前没有看到源码中使用,就不分析了 if ((resolveLinks) && (entry.type == NamingEntry.LINK_REF)) { String link = ((LinkRef) entry.value).getLinkName(); if (link.startsWith(".")) { return lookup(link.substring(1)); } else { return new InitialContext(env).lookup(link); } } else if (entry.type == NamingEntry.REFERENCE) { try { // 如果NamingEntry类型是引用类型 Object obj = NamingManager.getObjectInstance (entry.value, name, this, env); if(entry.value instanceof ResourceRef) { // 如果是ResourceRef 并且是单例,默认为单例 boolean singleton = Boolean.parseBoolean( (String) ((ResourceRef) entry.value).get( "singleton").getContent()); if (singleton) { // 则将 entry.type 设置为实体类型 // 也就是只需要初始化一次,下次不需要再初始化了 entry.type = NamingEntry.ENTRY; entry.value = obj; } } return obj; } catch (NamingException e) { throw e; } catch (Exception e) { String msg = sm.getString("namingContext.failResolvingReference"); log.warn(msg, e); NamingException ne = new NamingException(msg); ne.initCause(e); throw ne; } } else { // 直接返回实体 return entry.value; } } }
如果是引用类型,会调用NamingManager.getObjectInstance()方法,接下来,看getObjectInstance()方法的实现。
public static Object getObjectInstance(Object refInfo, Name name, Context nameCtx, Hashtable environment) throws Exception { ObjectFactory factory; // 之前分析过,如果我们设置了ObjectFactoryBuilder // 则会调用builder创建的Factory,从而调用其getObjectInstance方法,创建实体 ObjectFactoryBuilder builder = getObjectFactoryBuilder(); if (builder != null) { factory = builder.createObjectFactory(refInfo, environment); return factory.getObjectInstance(refInfo, name, nameCtx, environment); } Reference ref = null; if (refInfo instanceof Reference) { ref = (Reference) refInfo; } else if (refInfo instanceof Referenceable) { ref = ((Referenceable)(refInfo)).getReference(); } Object answer; if (ref != null) { String f = ref.getFactoryClassName(); if (f != null) { // 当前ClassLoader加载factory factory = getObjectFactoryFromReference(ref, f); if (factory != null) { // 调用Factory 的 getObjectInstance()方法获取实例 return factory.getObjectInstance(ref, name, nameCtx, environment); } return refInfo; } else { answer = processURLAddrs(ref, name, nameCtx, environment); if (answer != null) { return answer; } } } answer = createObjectFromFactories(refInfo, name, nameCtx, environment); return (answer != null) ? answer : refInfo; } public final String getFactoryClassName() { String factory = super.getFactoryClassName(); if (factory != null) { return factory; } else { factory = System.getProperty("java.naming.factory.object"); if (factory != null) { return null; } else { // 如果Resource标签中没有配置factory // 则调用相应的Ref 的 getDefaultFactoryClassName()方法 return getDefaultFactoryClassName(); } } }如果没有配置factory,则调用相关Ref的getDefaultFactoryClassName()方法获取其工厂类名,调用当前类加载器加载工厂类名,得到工厂类对象,调用工厂类的getObjectInstance()获取对象实例,在本例中,我们得知ResourceRef 的工厂类为org.apache.naming.factory.ResourceFactory,因此我们进入ResourceFactory的getObjectInstance看其如何实现。 但是遗憾的是ResourceFactory并没有实现getObjectInstance()方法,而是其父类FactoryBase实现了getObjectInstance()方法,我们看其如何如下 。
public final Object getObjectInstance(Object obj, Name name, Context nameCtx, Hashtable environment) throws Exception { if (isReferenceTypeSupported(obj)) { Reference ref = (Reference) obj; Object linked = getLinked(ref); if (linked != null) { return linked; } ObjectFactory factory = null; // 如果配置了factory ,获取通过类加载器加载或反射加载factory RefAddr factoryRefAddr = ref.get(Constants.FACTORY); if (factoryRefAddr != null) { String factoryClassName = factoryRefAddr.getContent().toString(); ClassLoader tcl = Thread.currentThread().getContextClassLoader(); Class factoryClass = null; try { if (tcl != null) { factoryClass = tcl.loadClass(factoryClassName); } else { factoryClass = Class.forName(factoryClassName); } } catch(ClassNotFoundException e) { NamingException ex = new NamingException(sm.getString("factoryBase.factoryClassError")); ex.initCause(e); throw ex; } try { factory = (ObjectFactory) factoryClass.getConstructor().newInstance(); } catch(Throwable t) { if (t instanceof NamingException) { throw (NamingException) t; } if (t instanceof ThreadDeath) { throw (ThreadDeath) t; } if (t instanceof VirtualMachineError) { throw (VirtualMachineError) t; } NamingException ex = new NamingException(sm.getString("factoryBase.factoryCreationError")); ex.initCause(t); throw ex; } } else { // 如果没有配置factory,则调用getDefaultFactory 方法 // 获取factory factory = getDefaultFactory(ref); } if (factory != null) { return factory.getObjectInstance(obj, name, nameCtx, environment); } else { throw new NamingException(sm.getString("factoryBase.instanceCreationError")); } } return null; }
这里有好几个获取Factory的地方,大家不要被搞晕了, 根据标签的类型有不同的Ref如下 。
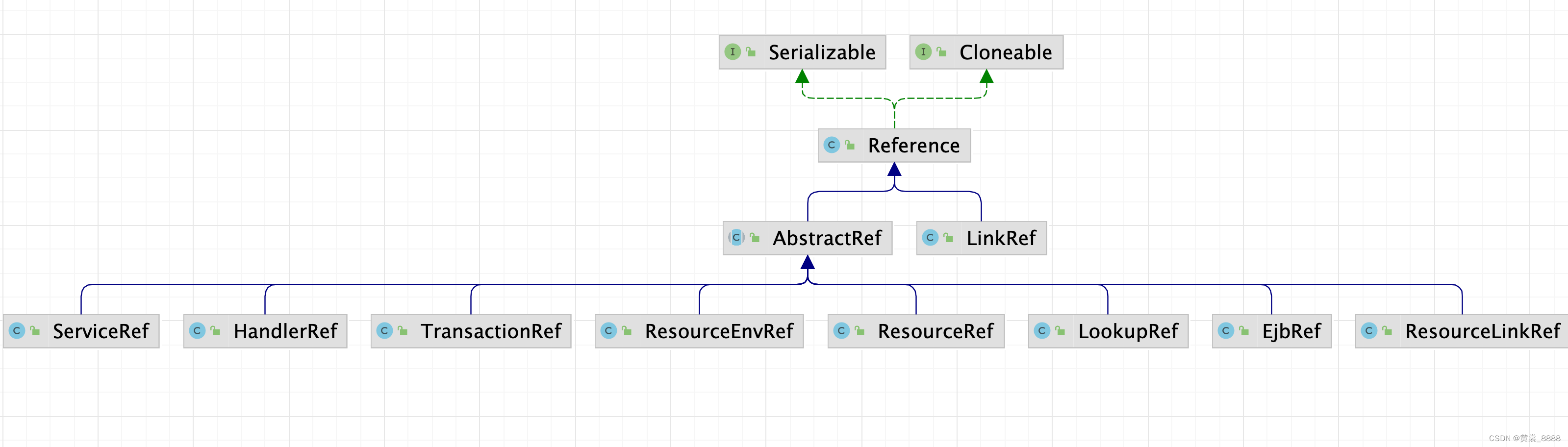
即使同样是ResourceRef ,也需要调用不同的工厂方法来获取实例,Tomcat标准资源不仅有数据源, 还包含很多的其他资源 ,不再的资源都有属于自己的资源工厂类, 这些工厂类负责提供服务资源的创建,而且,Tomcat提供了对这些资源的灵活配置, Tomcat标准资源包括了以下几个类。
- 普通JavaBean资源,它主要用于创建某个Java类对象供Web应用使用,例如,如果要将某个类提供的功能作为命名服务,则可以将此Java 类配置成JavaBean资源 。
- UserDataBase资源 , 它一般会配置成一个全局资源 , 作为具有认证功能的数据源使用, 一般该数据源通过XML(config/tomcat-user.xml)文件存储 。
- JavaMail 会话资源 , 很多的Web应用都需要发送Email,为了方便Web应用 , 可以使用JavaMail 接口,Tomcat 提供了JavaMail 服务,让使更加方便,简单。
- JDBC 数据源资源, 基本上大多数Web 应用都需要与数据库交互,而Java都是通过JDBC 驱动操作数据库, 为了方便Web应用,可以使用JDBC ,并且提供一个数据库连接池, 所以,提供了JDBC 数据源资源, 默认的JDBC 数据源基于DBCP 连接池。
以上便是Tomcat自带的标准资源,在Tomcat中配置资源都通过
节点配置,可以配置全局资源,也可以配置局部资源 , 如果存在Tomcat标准资源满足不了的场景,则可以自定义资源并在Tomcat中配置。 protected ObjectFactory getDefaultFactory(Reference ref) throws NamingException { ObjectFactory factory = null; if (ref.getClassName().equals("javax.sql.DataSource")) { String javaxSqlDataSourceFactoryClassName = System.getProperty("javax.sql.DataSource.Factory", "org.apache.tomcat.dbcp.dbcp.BasicDataSourceFactory"); try { factory = (ObjectFactory) Class.forName( javaxSqlDataSourceFactoryClassName).getConstructor().newInstance(); } catch (Exception e) { NamingException ex = new NamingException(sm.getString("resourceFactory.factoryCreationError")); ex.initCause(e); throw ex; } } else if (ref.getClassName().equals("javax.mail.Session")) { String javaxMailSessionFactoryClassName = System.getProperty("javax.mail.Session.Factory", "org.apache.naming.factory.MailSessionFactory"); try { factory = (ObjectFactory) Class.forName( javaxMailSessionFactoryClassName).getConstructor().newInstance(); } catch(Throwable t) { if (t instanceof NamingException) { throw (NamingException) t; } if (t instanceof ThreadDeath) { throw (ThreadDeath) t; } if (t instanceof VirtualMachineError) { throw (VirtualMachineError) t; } NamingException ex = new NamingException(sm.getString("resourceFactory.factoryCreationError")); ex.initCause(t); throw ex; } } return factory; }
从上面加粗代码可以看出,如果resource的类类型是javax.sql.DataSource,则默认取org.apache.tomcat.dbcp.dbcp.BasicDataSourceFactory作为工厂类创建实例,当然我们也可以通过javax.sql.DataSource.Factory来配置,那我们来看org.apache.tomcat.dbcp.dbcp.BasicDataSourceFactory如何实现。
public Object getObjectInstance(Object obj, Name name, Context nameCtx, Hashtable environment) throws Exception { if ((obj == null) || !(obj instanceof Reference)) { return null; } Reference ref = (Reference) obj; if (!"javax.sql.DataSource".equals(ref.getClassName())) { return null; } Properties properties = new Properties(); // 过滤掉多余不属于BasicDataSource 需要的属性 // 如你在Resource标签中配置了aaa ="xxx", 这将被剔除掉 for (int i = 0 ; i < ALL_PROPERTIES.length ; i++) { String propertyName = ALL_PROPERTIES[i]; RefAddr ra = ref.get(propertyName); if (ra != null) { String propertyValue = ra.getContent().toString(); properties.setProperty(propertyName, propertyValue); } } return createDataSource(properties); } public static DataSource createDataSource(Properties properties) throws Exception { BasicDataSource dataSource = new BasicDataSource(); String value = null; value = properties.getProperty("defaultAutoCommit"); if (value != null) { dataSource.setDefaultAutoCommit(Boolean.valueOf(value).booleanValue()); } value = properties.getProperty("defaultReadOnly"); if (value != null) { dataSource.setDefaultReadOnly(Boolean.valueOf(value).booleanValue()); } value = properties.getProperty("defaultTransactionIsolation"); ... value = properties.getProperty("defaultCatalog"); if (value != null) { dataSource.setDefaultCatalog(value); } value = properties.getProperty("driverClassName"); if (value != null) { dataSource.setDriverClassName(value); } ... // DBCP-215 // Trick to make sure that initialSize connections are created if (dataSource.getInitialSize() > 0) { dataSource.getLogWriter(); } // Return the configured DataSource instance return dataSource; }
我相信大家对dataSource的获取过程有了一个清晰的认识了。 但是聪明的读者肯定会发现 ,你说的是Resource的bind和lookup啊,那和ResourceLink有什么关系呢?我们在Context下配置的ResourceLink是怎样找到全局配置的Resource的呢?请听我娓娓道来。不知道大家还记得 lifecycleEvent方法没有。 在这个方法中有如下一段代码 。
public void lifecycleEvent(LifecycleEvent event) { ... if (Lifecycle.CONFIGURE_START_EVENT.equals(event.getType())) { .... if (container instanceof Server) { org.apache.naming.factory.ResourceLinkFactory.setGlobalContext (namingContext); try { ContextBindings.bindClassLoader (container, container, this.getClass().getClassLoader()); } catch (NamingException e) { logger.error(sm.getString("naming.bindFailed", e)); } if (container instanceof StandardServer) { ((StandardServer) container).setGlobalNamingContext (namingContext); } } } finally { // Regardless of success, so that we can do cleanup on configure_stop initialized = true; } } else if (Lifecycle.CONFIGURE_STOP_EVENT.equals(event.getType())) { ... } } public static void setGlobalContext(Context newGlobalContext) { SecurityManager sm = System.getSecurityManager(); if (sm != null) { sm.checkPermission(new RuntimePermission( ResourceLinkFactory.class.getName() + ".setGlobalContext")); } globalContext = newGlobalContext; }如果lifecycleEventgk事件的container是StandardServer,则将namingContext设置为全局上下文,也就是说我们配置的Resource
被设置到了全局上下文。
再来看org.apache.naming.factory.ResourceLinkFactory的getObjectInstance方法实现。public Object getObjectInstance(Object obj, Name name, Context nameCtx, Hashtable environment) throws NamingException { if (!(obj instanceof ResourceLinkRef)) { return null; } // Can we process this request? Reference ref = (Reference) obj; // Read the global ref addr String globalName = null; RefAddr refAddr = ref.get(ResourceLinkRef.GLOBALNAME); if (refAddr != null) { globalName = refAddr.getContent().toString(); // Confirm that the current web application is currently configured // to access the specified global resource if (!validateGlobalResourceAccess(globalName)) { return null; } Object result = null; result = globalContext.lookup(globalName); // Check the expected type String expectedClassName = ref.getClassName(); if (expectedClassName == null) { throw new IllegalArgumentException( sm.getString("resourceLinkFactory.nullType", name, globalName)); } try { Class expectedClazz = Class.forName( expectedClassName, true, Thread.currentThread().getContextClassLoader()); if (!expectedClazz.isAssignableFrom(result.getClass())) { throw new IllegalArgumentException(sm.getString("resourceLinkFactory.wrongType", name, globalName, expectedClassName, result.getClass().getName())); } } catch (ClassNotFoundException e) { throw new IllegalArgumentException(sm.getString("resourceLinkFactory.unknownType", name, globalName, expectedClassName), e); } return result; } return null; }上面加粗代码为关键代码,如果是ResourceLinkRef,则从全局上下文中查找。
我相信此刻,大家对Tomcat中使用JNDI有了一个清晰的认知了。下面是书本上对JNDI的总结 。
JNDI 有自己的接入机制,Tomcat 要支持JNDI 就要对这些接入的框架有足够的理解,接入框架使得不同的服务提供者能共用JNDI的统一接口来访问各种不同的服务,一般接入JNDI必须与以下几个类打交道,初始化上下文,对象工厂,状态工厂,总的来说,初始化上下文负责封装JNDI连接底层服务提供者的默认策略,而对象工厂及状态工厂用来定制命名上下文的实现, 其中,对象工厂用于定制使用绑定的信息创建命名对象的策略, 状态工厂用于定制从命名对象生成绑定信息的策略。
初始化上下文有以下几个特点
- 它是访问命名服务的入口 。
- 它将根据特定的策略指定一个上下文工厂类并生成一个上下文 。
- 它支持以URL格式访问命名空间,根据特定的策略指定一个URL 上下文工厂类并生成一个上下文,一般情况下, 服务提供者没有必要提供URL 上下文工厂和URL 上下文的实现,只有在自定义方案识别的URL字符串名称时才需要,这是为了保证初始化上下文能够识别这个scheme标识 。
- 根据实际需要,我们可以覆盖默认的策略。
- 如果自己重新定义一个上下文接口,为了使使用初始化上下文支持,我们需要扩展初始化上下文,这样便可以继承初始化上下文处理方式 。
对象工厂有以下几个特点 。
- 它以命名上下文存储形式(绑定信息)转换成对对象提供的机制策略, 将Reference或一个URL 或其他任意类型等转换成一个Java对象 。
- 它通过环境属性java.naming.factory.object定位对象工厂类位置,多个工厂类用冒号分隔, JNDI 会尝试利用每个工厂类处理直接创建一个非空结果对象 。
- 如果没有指定对象工厂类,则不会对对象做处理。
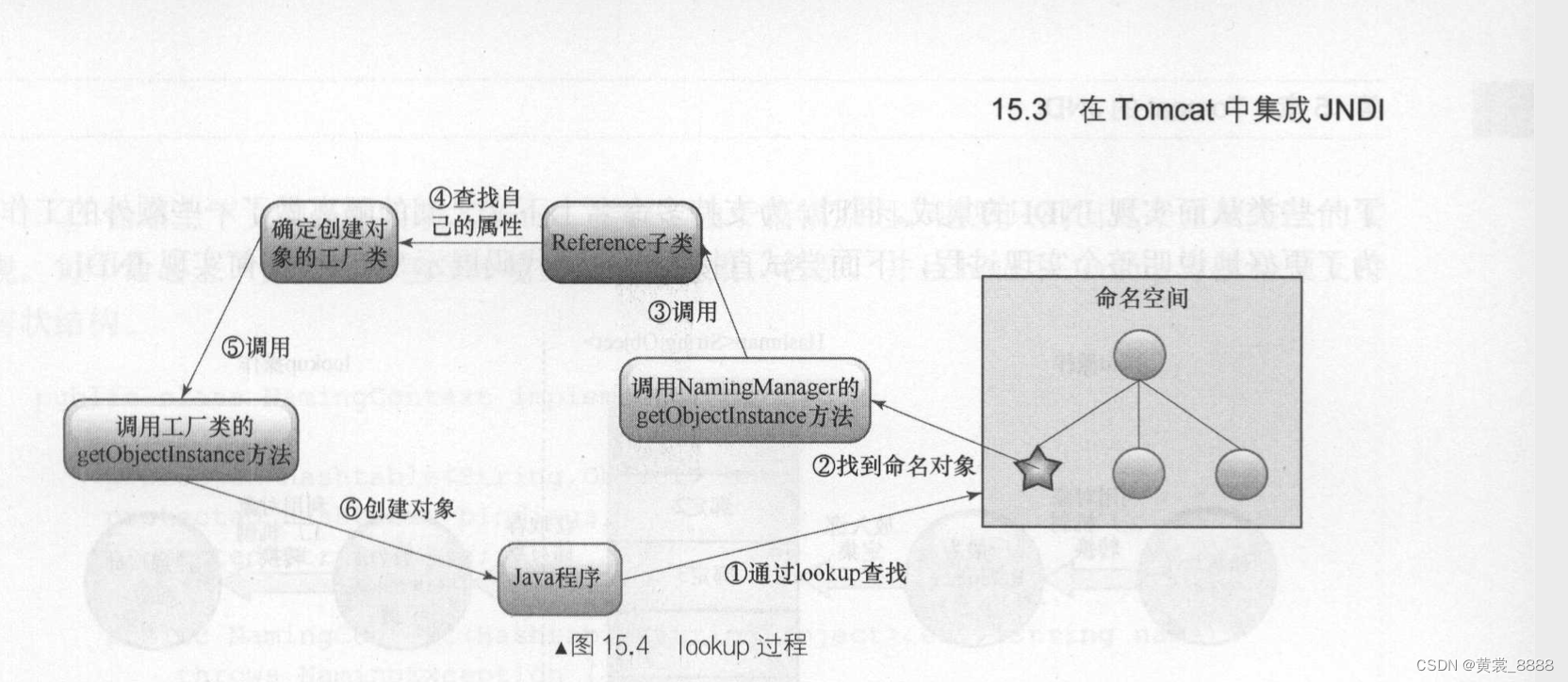
整个转换过程其实就是将现有的存储对象转换成可以使用Java 对象的过程 , 可以用图15.4进行说明,从Java程序一步步的调用,按照特定的转换机制,最后获取到转换后的Java 对象 。
状态工厂有以下几个特点 。
- 它为对象转换成适合的命名上下文实现存储的形式(绑定信息)提供了机制策略, 转换后可以是Reference , Serialiable对象,属性集或其他任意数据 。
- 它通过环境属性java.naming.factory.state 定位状态工厂的类位置 , 多个工厂类用冒号分隔 。
- 如果没有指定状态工厂类,则不会对对象做处理。
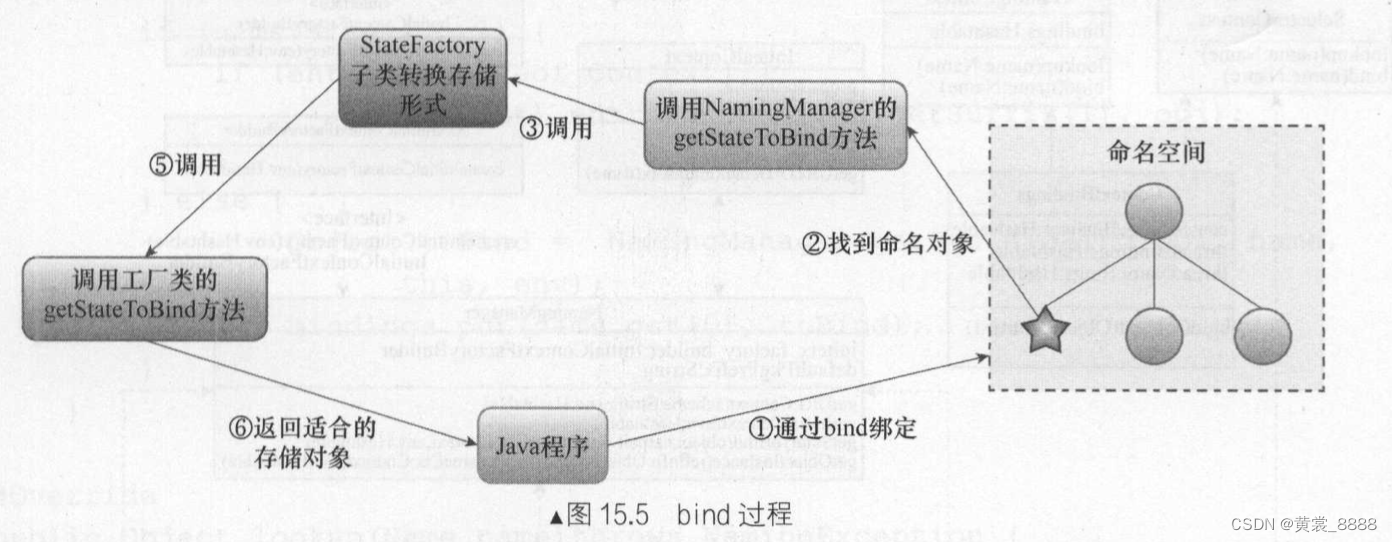
整个转换过程其实就是将现有的对象可存储对象,可以用图15.5 进行说明 , Java 程序一步步的调用,按照特定的转换机制。最后获得适合存储的对象 。
对于 Tomcat 来说, 如果想集成 JNDI ,则要加入对命名空间的支持,维护一个对状数据结构,通过命名上下文实现树状结构操作,每个命名上下文面包含绑定集, 绑定和查找围绕着这个绑定集进行操作,如图15.6 ,通过bind操作将任意Java对象转换为适合存储的对象( 一般是Reference子类),并放进一个HashMap结构中绑定集中,再通过lookup操作将存储的对象(Reference子类)转换成对应的Java对象 。
在讲清楚 JNDI 开发时的几个要点后,开始看Tomcat 对JNDI 的集成 , 如图15.7所示 , 可以看到 JNDI 的几个核心类都在, 只是扩展了一些从而实现了JNDI的集成 , 同时, 为了支持多个命名上下文的隔离做了一些额外的工作 。 为了更好的说明整个实现过程 , 下面尝试直接用简化的代码展示了Tomcat 如何实现JNDI 的。

上面是Tomcat 中提供命名服务的基本实现过程 , 结合图15.8 能更加形象的说明Tomcat 的JNDI 实现, 由于Web应用需要保证以InitialContext作为入口,而且为了使用简单,因此都会以URL 方式查找命名上下文,另外,因为不同的Web应用有自己的命名上下文,而且Tomcat还包含一个全局的命名上下文,所以引用了SelectorContext 上下文用于根据运行时当前线程或类加载来获取相应的命名上下文,这个工作就次给了ContextBindings, 不同的Web应用在使用JNDI 时会路由到相应的命名资源上。
为了使Tomcat的命名上下文互相隔离 , 需要绑定环节和查找环节 。
对于绑定环节,如图15.9所示 。 Tomcat 在初始化时将需要绑定对象转换成ResourceRef对象, 然后绑定到NamingContext中,当然,一个NamingContext里面可能又有若干个NamingContext,以树状命名上下文的三种绑定机制,直接绑定,与线程绑定,与类加载器进行分隔 。
对于查找环节,如图15.10 所示 , 程序查找命名资源前先实例化一个InitialContext实例, 通过URL 模式查找,假如用Java作为scheme ,则定位到javaURLContextFactory工厂类,返回一个SelectContext对象,并且这个SelectContext封装了对ContextBindings 的操作,而ContextBinding则封装了对NamingContext与线程,类加载器等的绑定机制,最终找到URL指定的ResourceRef对象, 并由此对象指定ResourceFactory 工厂类,此工厂类将生成Java对象供程序使用。

ResourceLink的工作原理其实很简单, 如图15.14 所示 , 因为对于Tomcat来说,它可能有若干个命名上下文对象, 在各自的命名上下文对象中只能找到自己拥有的资源 , 所以,如果在Web应用中查找全局资源 , 就必须通过ResourceLink ,它通过一个工厂类ResourceLinkFactory会到全局命名资源上下文对象中查找关联的资源 ,返回对应的资源供Web应用使用。
我觉得15.14 非常形象的讲述了绑定,查找的整个过程,大家感兴趣的可以去看看原书《Tomcat内核设计剖析》,博客中的大量的理论知识都来源于这本书 。
因为我觉得JNDI 这个框架确实很好用,也很方便 ,我将Tomcat 7中的JNDI 框架的源码抽取出来了,方便将来如果要写框架用到jndi时使用 https://github.com/quyixiao/tomcat-naming.git , 感兴趣可以下载看看。
当然JNDI 还有很多的配置没有去分析,如ejb,environment,localEjb, resourceEnvRef, service ,在实现上大同小异,感兴趣可以自己去分析。
我们在工作中用得比较多和JNDI相关的两个类是FirDirContext和WARDirContext ,这两个类在我们工作中有什么用呢?如我们要访问我们项目中的一个资源,如js ,如果项目解压了,则会用到FirDirContext,如果没有解压,则会用WARDirContext,还有其他的上下文,大家感兴趣自己去研究,接着围绕着这两个类来研究 。先来研究FirDirContext。
FirDirContext
在研究之前先来看一个例子。
- 在我们项目的webapp下创建一个js的目录,在js 目录下放一个jquery-3.6.0.min.js
2. 打包放到tomcat的webapps目录下。
3. 运行tomcat ,访问http://localhost:8080/servelet-test-1.0/js/jquery-3.6.0.min.js ,得到jquery-3.6.0.min.js内容。

大家有没有感到好奇,tomcat如何实现的呢?
首先,我们来看StandardContext的startInternal()方法,我们之前在《Tomcat 源码解析一初识》里已经对startInternal()在Tomcat生命周期中起到的作用做了详细分析,这里就不再赘述,直接看StandardContext的startInternal方法里的代码块。protected synchronized void startInternal() throws LifecycleException { ... // Add missing components as necessary if (webappResources == null) { // (1) Required by Loader if (log.isDebugEnabled()) log.debug("Configuring default Resources"); try { // 设置Context的资源 // 赋值webappResources属性 // docBase地址 String docBase = getDocBase(); if (docBase == null) { setResources(new EmptyDirContext()); } else if (docBase.endsWith(".war") && !(new File(getBasePath())).isDirectory()) { // war包 setResources(new WARDirContext()); } else { // 文件目录, WARDirContext处理不同的是 ,WARDirContext 需要对.war 包进行解压,然后才能获取对应的文件内容,而FileDir可以直接获取文件内容 setResources(new FileDirContext()); } } catch (IllegalArgumentException e) { log.error(sm.getString("standardContext.resourcesInit"), e); ok = false; } } if (ok) { if (!resourcesStart()) { throw new LifecycleException("Error in resourceStart()"); } } ... }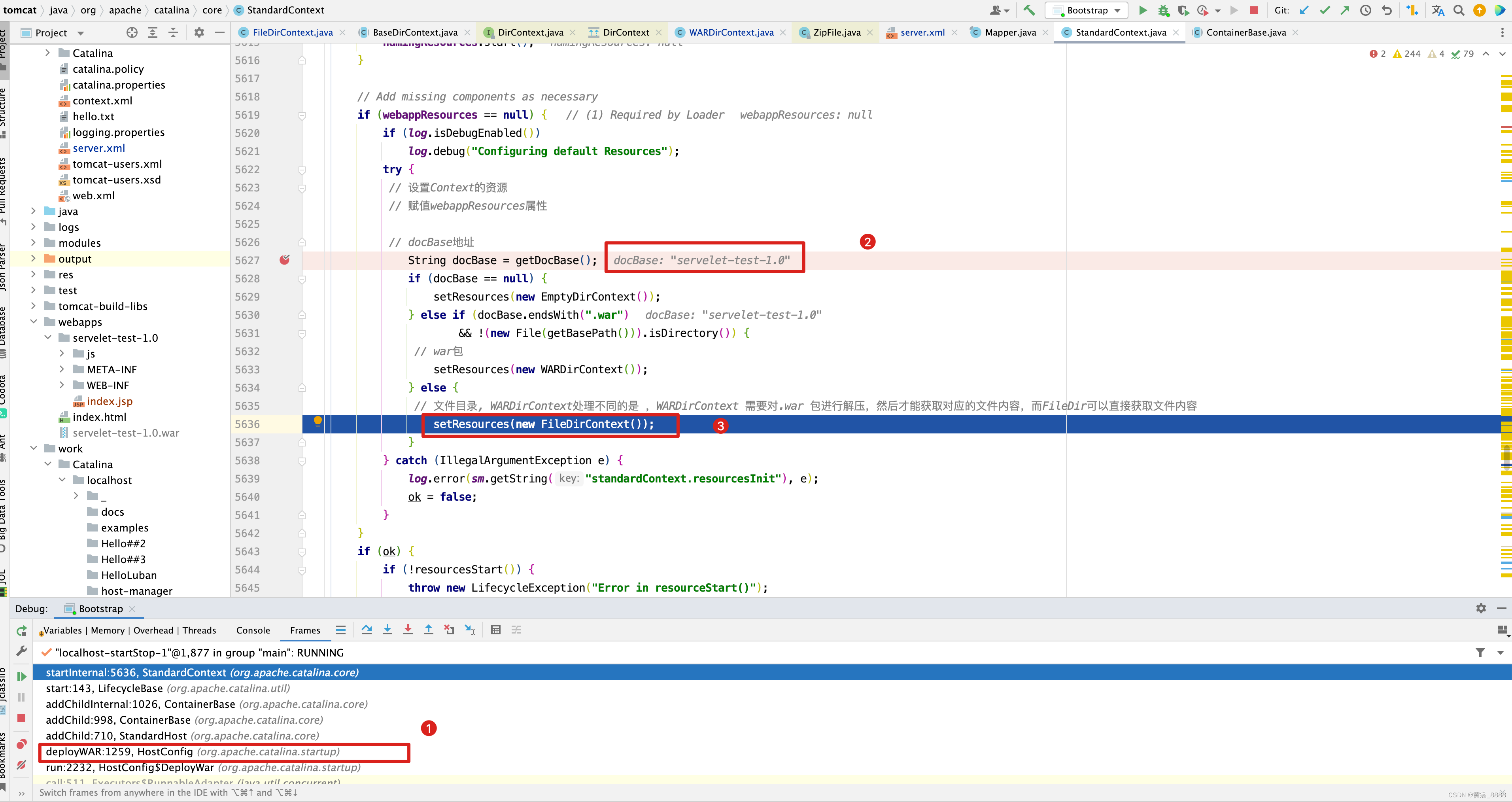
在Tomcat deploy WAR 包的时候,如果是一个目录,则设置当前webappResources为FileDirContext,在server.xml中设置
unpackWARs=“false” autoDeploy=“true” >
unpackWARs为false,则此时docBase = servelet-test-1.0.war ,因此会设置 StandardContext的 webappResources为WARDirContext,接下来进入setResources()方法,设置webappResources做了哪些事情 。public synchronized void setResources(DirContext resources) { if (getState().isAvailable()) { throw new IllegalStateException (sm.getString("standardContext.resourcesStart")); } DirContext oldResources = this.webappResources; // 如果新旧webappResources是一样的,则不再设置 if (oldResources == resources) return; if (resources instanceof BaseDirContext) { // Caching // 设置FileDirContext或WARDirContext的缓存参数,是否允许缓存、缓存过期时间、缓存空间的最大限制,缓存对象的最大限制 ((BaseDirContext) resources).setCached(isCachingAllowed()); ((BaseDirContext) resources).setCacheTTL(getCacheTTL()); ((BaseDirContext) resources).setCacheMaxSize(getCacheMaxSize()); ((BaseDirContext) resources).setCacheObjectMaxSize( getCacheObjectMaxSize()); // Alias support // Context的别名 ((BaseDirContext) resources).setAliases(getAliases()); } // FileDirContext其实也是BaseDirContext的一种,如果是文件目录,设置一下是否允许软链接 if (resources instanceof FileDirContext) { filesystemBased = true; ((FileDirContext) resources).setAllowLinking(isAllowLinking()); } this.webappResources = resources; // The proxied resources will be refreshed on start super.setResources(null); support.firePropertyChange("resources", oldResources, this.webappResources); }
上方法的实现逻辑也很简单,将我们设置在StandardContext中的缓存参数,是否允许缓存、缓存过期时间、缓存空间的最大限制,缓存对象的最大限制这些配置设置到webappResources属性中 。
既然是查找资源,肯定会用到lookup方法,我们在FileDirContext的lookup方法打一个断点,但是遗憾的是并没有lookup方法, 只有一个doLookup方法,凡是研究过Spring源码的小伙伴肯定发现一个规率,在Spring中真正做事情的都是doXXX()方法,其他的parse啊,find()这些方法都是虚张声势的方法,而真正做事情的可能是doFind(),doParse()这些方法,那我们在doLookup方法中打一个断点 。
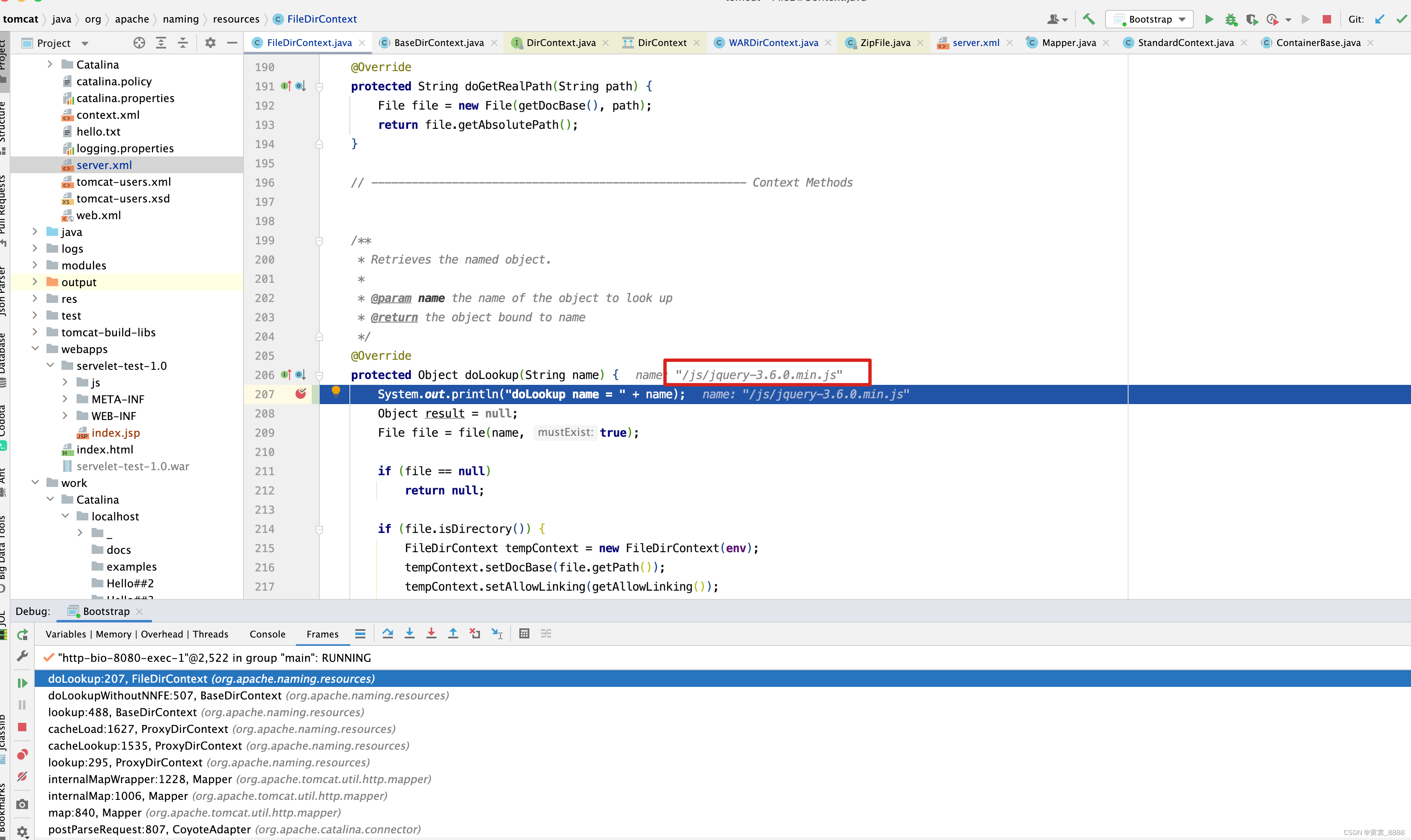
终于看到关键信息了。 但是小伙伴需要注意,项目启动后只有第一次访问http://localhost:8080/servelet-test-1.0/js/jquery-3.6.0.min.js时才会进入到这个方法,后面的访问不会再进入doLookup方法,因为Tomcat帮我们做了优化,使用了缓存功能,查找资源只会做一次,当查找到后,将资源存储到缓存中,下次再访问时,直接从缓存中获取即可 。
关于如何从经过哪些过滤器,再经过哪些阀门,再到我们的servlet这一块先不讨论,因为这一块确实太大了,后面的博客再来分析,我们先从servlet分析 。

我们看到,本次请求中最重要的就是调用contextVersion.resources.lookup(pathStr);这一行代码的lookup方法,那么contextVersion又是什么,而resources又是什么,这两个对象又是哪里来的呢?
在代码中寻寻觅觅,在Mapper中的addContextVersion()方法中打断点,得到resources实际上是在MapperListener的registerContext()方法中private void registerContext(Context context) { String contextPath = context.getPath(); if ("/".equals(contextPath)) { contextPath = ""; } Container host = context.getParent(); javax.naming.Context resources = context.getResources(); String[] welcomeFiles = context.findWelcomeFiles(); Listwrappers = new ArrayList (); // 该List里面存储的就是Servlet的URL映射关系 // 循环Wrapper节点,将mapping关系解析到wrappers中 for (Container container : context.findChildren()) { prepareWrapperMappingInfo(context, (Wrapper) container, wrappers); if(log.isDebugEnabled()) { log.debug(sm.getString("mapperListener.registerWrapper", container.getName(), contextPath, connector)); } } mapper.addContextVersion(host.getName(), host, contextPath, context.getWebappVersion(), context, welcomeFiles, resources, wrappers, context.getMapperContextRootRedirectEnabled(), context.getMapperDirectoryRedirectEnabled()); if(log.isDebugEnabled()) { log.debug(sm.getString("mapperListener.registerContext", contextPath, connector)); } } 上面加粗代码 javax.naming.Context resources = context.getResources() 而来。细心的小伙伴肯定会发现,之前setResources()方法中不是设置了,如果当前是目录,则设置resources是FirDirContext,如果是war包,则设置resources为WARDirContext,但为什么此时变成了ProxyDirContext了呢?通过类名称一看就知道是一个代理类,先找到在哪里替换的resources 。 又在代码中寻寻觅觅,发现调用了setResources()方法之后,又紧接着调用了resourcesStart()方法,这个方法做了哪些事情呢?
public boolean resourcesStart() { boolean ok = true; Hashtable
在StandardContext中,加粗代码是我们着重要看的代码 首先ProxyDirContext proxyDirContext =
new ProxyDirContext(env, webappResources); 一个proxyDirContext对象,对缓存参数,是否允许缓存、缓存过期时间、缓存空间的最大限制,缓存对象的最大限制再次设置了一遍,为什么这么做?想了很久,我也不知道,如果有小伙伴知道,帮我留言一下哈。 最后再通过super.setResources(proxyDirContext);设置this.resources为proxyDirContext,同时需要注意的是在ProxyDirContext的构造函数中,创建了缓存对象。public ProxyDirContext(Hashtable
有了这些基础知识以后,我们再回头来看之前的doLookup()方法 ,我们知道此时此刻contextVersion.resources = ProxyDirContext,进入其lookup方法。
public Object lookup(String name) throws NamingException { // 通过DirContext中查找,如果查找到对象,缓存到cache对象中,并返回 CacheEntry entry = cacheLookup(name); if (entry != null) { if (!entry.exists) { throw NOT_FOUND_EXCEPTION; } if (entry.resource != null) { return entry.resource; } else { return entry.context; } } // 大家可能疑惑,为什么在cacheLookup()方法内部有如下代码, // 为什么这里再次通过dirContext.lookup(parseName(name)) 来查找对象呢? // 不过细心的小伙伴发现,cacheLookup()方法可能返回空 // 返回空的原因并不是资源不存在,而是缓存过期了,对于缓存过期情况,需要通过下面代码进行补偿 Object object = dirContext.lookup(parseName(name)); // 如果返回的对象是一个inputStream,则构建成Resource返回 if (object instanceof InputStream) { return new Resource((InputStream) object); // 如果返回的对象是DirContext或Resource 直接返回即可 } else if (object instanceof DirContext) { return object; } else if (object instanceof Resource) { return object; } else { // 否则用object.toString() 构建成一个包装类ByteArrayInputStream ,再封装成Resource返回 return new Resource(new ByteArrayInputStream (object.toString().getBytes(Charset.defaultCharset()))); } }从上面代码来分析,如果能从缓存中查找到CacheEntry对象,则直接返回即可,但需要注意的是,CacheEntry 存在,要么resource中有值,要么context 中有值,我们进入cacheLookup()方法 。
protected CacheEntry cacheLookup(String lookupName) { if (cache == null) return (null); String name; if (lookupName == null) { name = ""; } else { name = lookupName; } // /WEB-INF/lib/ 和 /WEB-INF/classes/ 开头的资源是不允许访问 for (int i = 0; i < nonCacheable.length; i++) { if (name.startsWith(nonCacheable[i])) { return (null); } } CacheEntry cacheEntry = cache.lookup(name); if (cacheEntry == null) { cacheEntry = new CacheEntry(); cacheEntry.name = name; cacheLoad(cacheEntry); } else { // 如果资源不存在或缓存过期 if (!validate(cacheEntry)) { // 如果资源不存在,则将其从缓存中移除 // 或缓存过期,并且资源被修改过 if (!revalidate(cacheEntry)) { // 将缓存资源从cache中移除 cacheUnload(cacheEntry.name); return (null); } else { // 如果资源存在,并且期间没有被修改过,修改缓存时间 cacheEntry.timestamp = System.currentTimeMillis() + cacheTTL; } } // 缓存命中次数 + 1 cacheEntry.accessCount++; } return (cacheEntry); }
其实上面的逻辑还是很清楚的
- 从缓存中查找,如果查找到了 ,看资源是否存在或是否过期,如果资源不存在了,则将其直接为cache对象中移除掉,如果资源过期,看期间是否被修改过,如果被修改过,将资源从cache对象中移除,如果没有被修改过,修改缓存时间 。
- 如果从缓存中查不到资源,则调用cacheLoad()方法继续查找 。
我们进入cacheLoad()方法 。
protected void cacheLoad(CacheEntry entry) { final String name = entry.name; boolean exists = true; if (entry.attributes == null) { try { // 获取文件的lastModified ,creation ,也就是创建时间,修改时间等属性 // 用于缓存过期判断,如果缓存过期,但是修改时间没有改变,则不需要重新查找资源 // 仍然可以用缓存中的对象返回,只需要修改缓存时间即可 Attributes attributes = dirContext.getAttributes(name); if (!(attributes instanceof ResourceAttributes)) { entry.attributes = new ResourceAttributes(attributes); } else { entry.attributes = (ResourceAttributes) attributes; } } catch (NamingException e) { exists = false; } } // 如果resource 并且context为空,则需要从 // FileDirContext或WARDirContext中查找 if ((exists) && (entry.resource == null) && (entry.context == null)) { try { Object object = dirContext.lookup(name); if (object instanceof InputStream) { entry.resource = new Resource((InputStream) object); } else if (object instanceof DirContext) { entry.context = (DirContext) object; } else if (object instanceof Resource) { entry.resource = (Resource) object; } else { entry.resource = new Resource(new ByteArrayInputStream (object.toString().getBytes(Charset.defaultCharset()))); } } catch (NamingException e) { exists = false; } } // 如果从FileDirContext或WARDirContext中查找到资源 if ((exists) && (entry.resource != null) // 并且资源的content为空,而且资源属性显示资源长度大于 0 && (entry.resource.getContent() == null) && (entry.attributes.getContentLength() >= 0) // 如果资源太大了,大于设置大小的1024倍,为了节省内存 // 也就不需要缓存了 && (entry.attributes.getContentLength() < (cacheObjectMaxSize * 1024))) { int length = (int) entry.attributes.getContentLength(); entry.size += (entry.attributes.getContentLength() / 1024); // 读取文件,转化为byte,存储到资源的content中 InputStream is = null; try { is = entry.resource.streamContent(); int pos = 0; byte[] b = new byte[length]; while (pos < length) { int n = is.read(b, pos, length - pos); if (n < 0) break; pos = pos + n; } entry.resource.setContent(b); } catch (IOException e) { // Ignore } finally { try { if (is != null) is.close(); } catch (IOException e) { // Ignore } } } // 设置资源存在 entry.exists = exists; // 设置缓存时间 entry.timestamp = System.currentTimeMillis() + cacheTTL; // 使用同步锁,一次只能缓存一个资源 synchronized (cache) { // 如果资源在缓存中不存在,并且没有超过允许分配的最大内存 if ((cache.lookup(name) == null) && cache.allocate(entry.size)) { cache.load(entry); } } }
在分析lookup()方法之前,先来看一看allocate()方法,我觉得加入缓存的策略很有意思的。
public boolean allocate(int space) { // 计算当前空闲内存 int toFree = space - (cacheMaxSize - cacheSize); // 如果本次占用的内存大于 空闲内存 ,则直接返回true if (toFree <= 0) { return true; } // 将当前资源加入缓存中, 留一定的空闲空间, // 而不是当前对象加入到缓存中后,其他对象加入,又需要立即来清理 // 缓存,而这个空闲空间为 cacheMaxSize的20分之一 toFree += (cacheMaxSize / 20); // 如我们访问/js/jquery-3.6.0.min.jsxxx // 这个资源不存在,但是避免下次再次访问这个uri,而带来不必要的查询 // 因此会将 /js/jquery-3.6.0.min.jsxxx 封装成CacheEntry,只是将其存储在notFoundCache对象中 // 当下次再次访问时,就可以从notFoundCache 中查找,如果有值,则直接返回,就不需要无用的通过dirContext.lookup()方法查找 // 方便提升性能 ,当超过最大内存限制时,首先清除notFoundCache的内容不扩容 int size = notFoundCache.size(); if (size > spareNotFoundEntries) { // spareNotFoundEntries = 500 notFoundCache.clear(); cacheSize -= size; toFree -= size; } // 如果清除掉notFoundCache的内容后空闲空间够了 // 则直接返回 if (toFree <= 0) { return true; } int attempts = 0; int entriesFound = 0; long totalSpace = 0; // 定义默认清除缓存中的对象为20个, maxAllocateIterations默认值为20 int[] toRemove = new int[maxAllocateIterations]; // maxAllocateIterations = 20 while (toFree > 0) { // 如果偿试20次后还没有空闲空间,则直接返回 if (attempts == maxAllocateIterations) { // maxAllocateIterations = 20 return false; } // 从缓存数组中随机选择一个对象 int entryPos = -1; boolean unique = false; while (!unique) { unique = true; entryPos = random.nextInt(cache.length) ; // 这里利用巧妙的算法。cache[entryPos] 为本次 // 选中可能要删除的对象,toRemove[i] = entryPos // 如果 toRemove[i] == entryPos,则表示这个随机数之前出现过 // 为了不重复指向同一个缓存对象,这里需要新一轮的生成随机数 for (int i = 0; i < entriesFound; i++) { if (toRemove[i] == entryPos) { unique = false; } } } long entryAccessRatio = ((cache[entryPos].accessCount * 100) / accessCount); // 如果缓存命中次数 * 100 / 总的缓存命中次数 < desiredEntryAccessRatio // 而desiredEntryAccessRatio 默认值为3 ,则缓存对象需要被移除掉 // 也就是当缓存对象命中次数不够时,即标记为 可能被移出掉 if (entryAccessRatio < desiredEntryAccessRatio) { // desiredEntryAccessRatio = 3 toRemove[entriesFound] = entryPos; totalSpace += cache[entryPos].size; toFree -= cache[entryPos].size; entriesFound++; } attempts++; } // toRemove[i] 指向需要被移除的对象已经标记好了 // 按照命中次数从低到高排序 ,命中率越低的,越先被除掉掉 // 接下来就是真正的移除对象 ,当然移除就是将之前未被标记的对象 // 拷贝过来而已 java.util.Arrays.sort(toRemove, 0, entriesFound); CacheEntry[] newCache = new CacheEntry[cache.length - entriesFound]; int pos = 0; int n = -1; if (entriesFound > 0) { n = toRemove[0]; for (int i = 0; i < cache.length; i++) { if (i == n) { if ((pos + 1) < entriesFound) { n = toRemove[pos + 1]; pos++; } else { pos++; n = -1; } } else { newCache[i - pos] = cache[i]; } } } cache = newCache; cacheSize -= totalSpace; return true; }
分配内存的策略我相信大家已经很清楚了,来总结一下。
- 如果剩余内存足够,则允许分配内存。
- 如果剩余内存不够,则先增加需要的内存空间为cacheMaxSize的20分之一,避免刚清理完内存后,当有新的内存需要缓存时,又马上需要清理内存。
- 从已经缓存对象的数组中随机的选出n个,直到空闲内存够用为止,n 不能大于 maxAllocateIterations, maxAllocateIterations的默认值为20,这点很像redis清除过期缓存策略。
- 对需要清理的缓存的命中次数排序,为什么要排序呢?将命中次数低的排在前面,命中次数高的排在后面,如果在清除过程中有新的请求进来,命中次数高的可能被命中的概率更大,也就是在被清除前尽量的提供缓存命中。 从而提升性能 。
- 将未被标记清除的缓存对象拷贝到新数组中。
大家看到没有,框架级的源码,在处理上极其的细腻,周到。接下来,我们进入lookup()方法的分析 。
public final Object lookup(String name) throws NamingException { Object obj = doLookupWithoutNNFE(name); if (obj != null) { return obj; } throw new NameNotFoundException( sm.getString("resources.notFound", name)); } private Object doLookupWithoutNNFE(String name) throws NamingException { // 通过别名查找 if (!aliases.isEmpty()) { AliasResult result = findAlias(name); if (result.dirContext != null) { return result.dirContext.lookup(result.aliasName); } } Object obj = doLookup(name); //找到name对应的对象,比如文件目录就是一个FileDirContext if (obj != null) { return obj; } // 如果资源是.class文件结尾,不允许访问 if (name.endsWith(".class")) { return null; } String resourceName = "/META-INF/resources" + name; for (DirContext altDirContext : altDirContexts) { if (altDirContext instanceof BaseDirContext) { obj = ((BaseDirContext) altDirContext) .doLookupWithoutNNFE(resourceName); } else { try { obj = altDirContext.lookup(resourceName); } catch (NamingException ex) { // ignore } } if (obj != null) { return obj; } } // Return null instead return null; }
FileDirContext的doLookup方法实现还是很简单的,如果是一个文件,则返回FileResource对象,如果是一个目录,则返回FileDirContext对象 。
protected Object doLookup(String name) { Object result = null; File file = file(name, true); if (file == null) return null; // 如果是一个目录,返回Context if (file.isDirectory()) { FileDirContext tempContext = new FileDirContext(env); tempContext.setDocBase(file.getPath()); tempContext.setAllowLinking(getAllowLinking()); result = tempContext; } else { // 如果是一个文件,返回FileResource对象 result = new FileResource(file); } return result; } protected File file(String name, boolean mustExist) { if (name.equals("/")) { name = ""; } // 默认情况下base是 // /Users/quyixiao/gitlab/tomcat/webapps/servelet-test-1.0 // 因此file对象就是/Users/quyixiao/gitlab/tomcat/webapps/servelet-test-1.0/js/jquery-3.6.0.min.js了 File file = new File(base, name); // 验证文件的可读性,如果是window系统的处理 // 以及allowLinking 较验等等 return validate(file, name, mustExist, absoluteBase, canonicalBase); }
如果我们访问的不是一个文件,而是一个目录会怎么样呢?http://localhost:8080/servelet-test-1.0/js/,
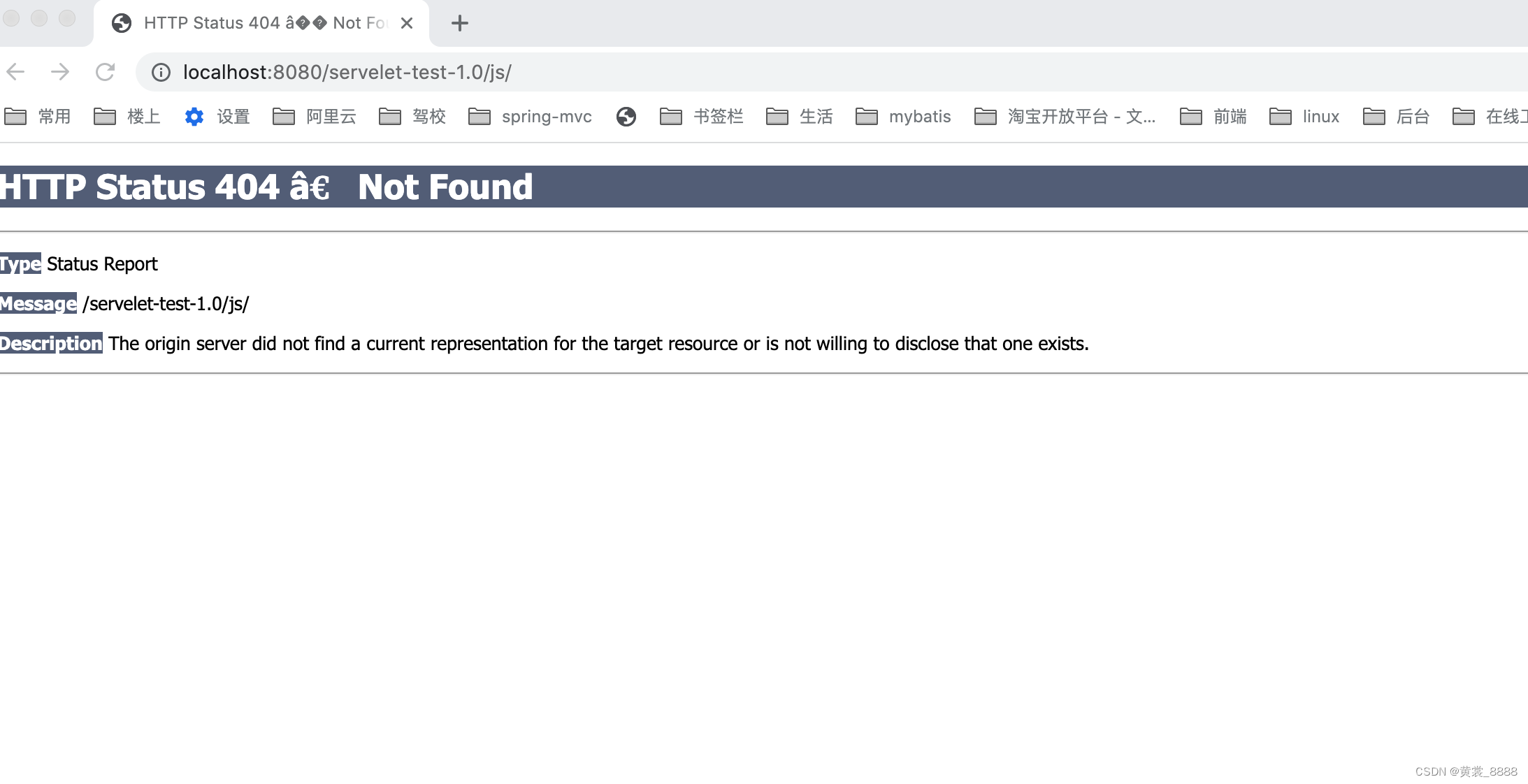
显然程序抛出异常,抛出异常的原因是listings=false,如果想让listings为true,是不是就可以访问目录了。

因此在代码中又寻寻觅觅。
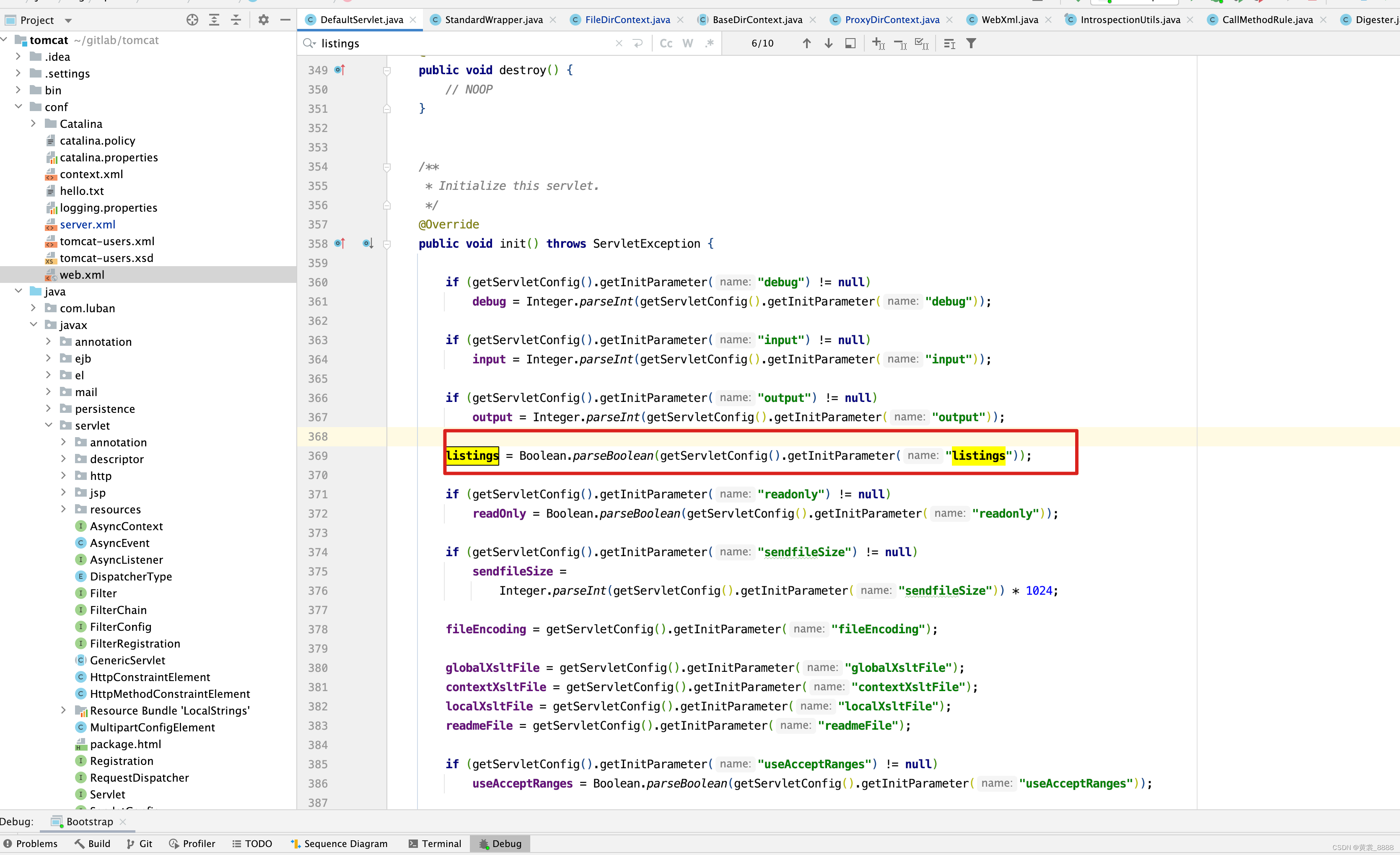
发现在DefaultServlet 初始化过程中会设置listings的值,因此我们想办法修改listings的值为true即可。
通过代码中寻寻觅觅,最终在解析tomcat/config/web.xml时设置listings的值。
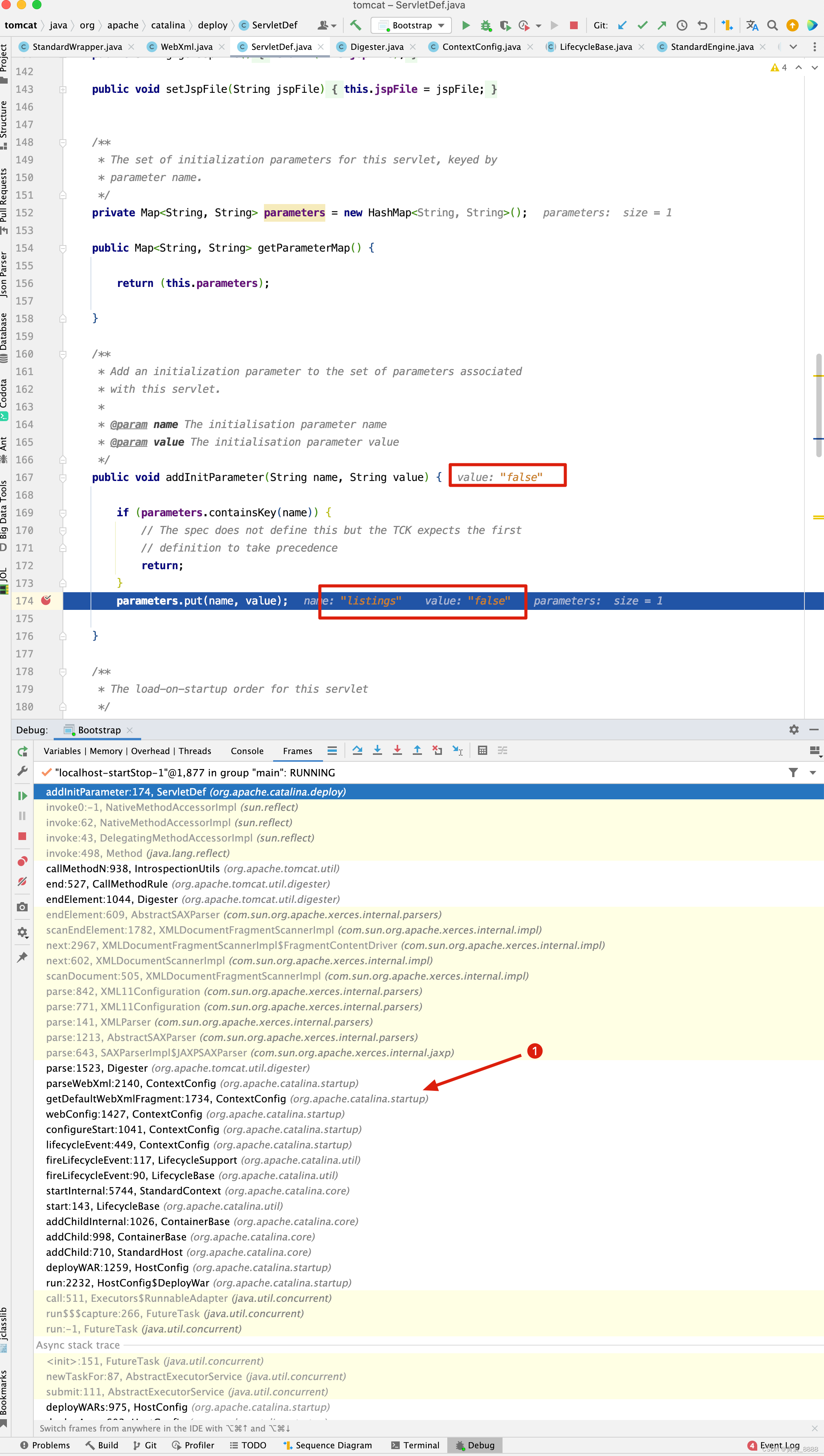

因此我们将listings的值设置为true
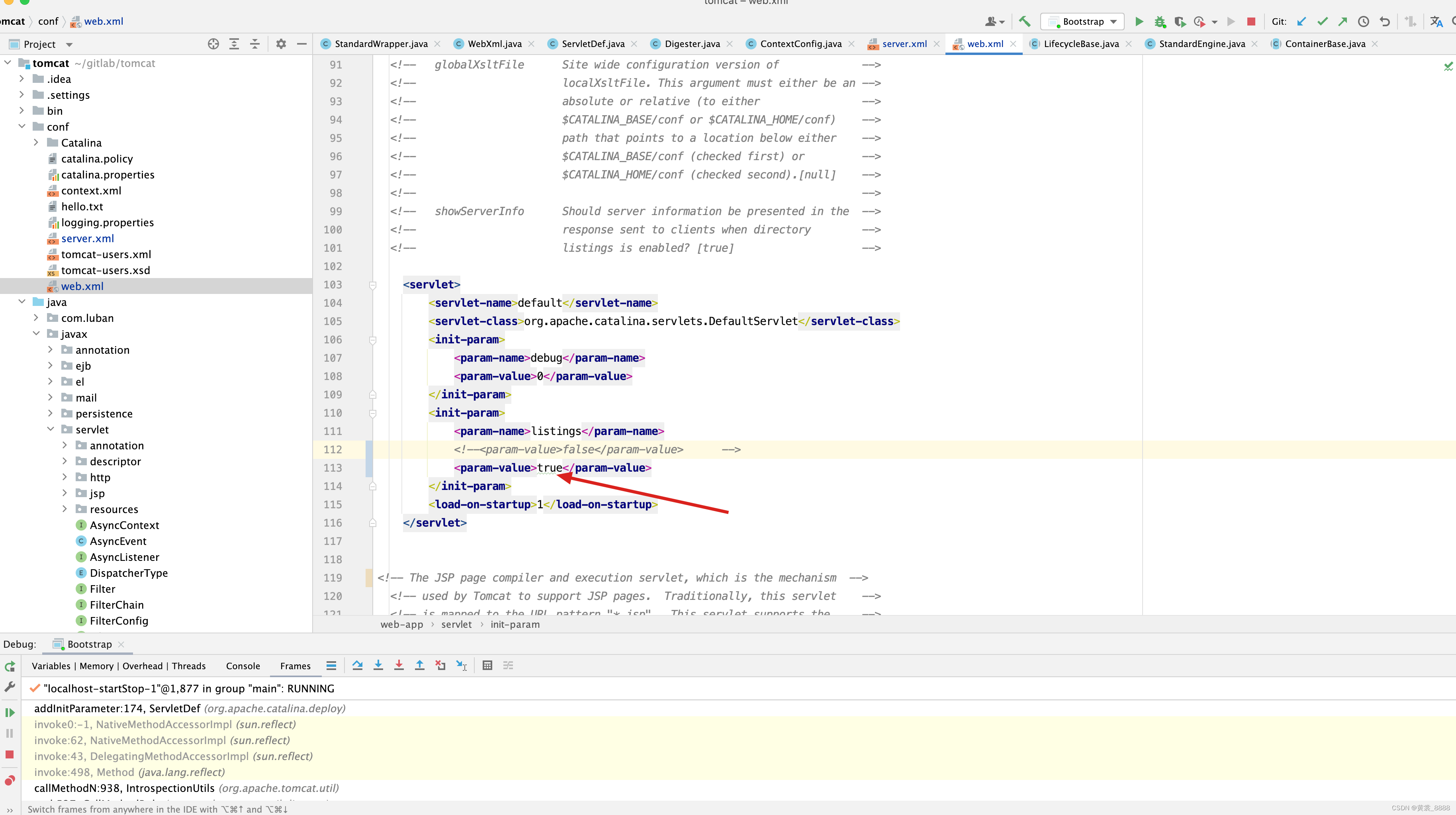
重新启动,再次访问 。
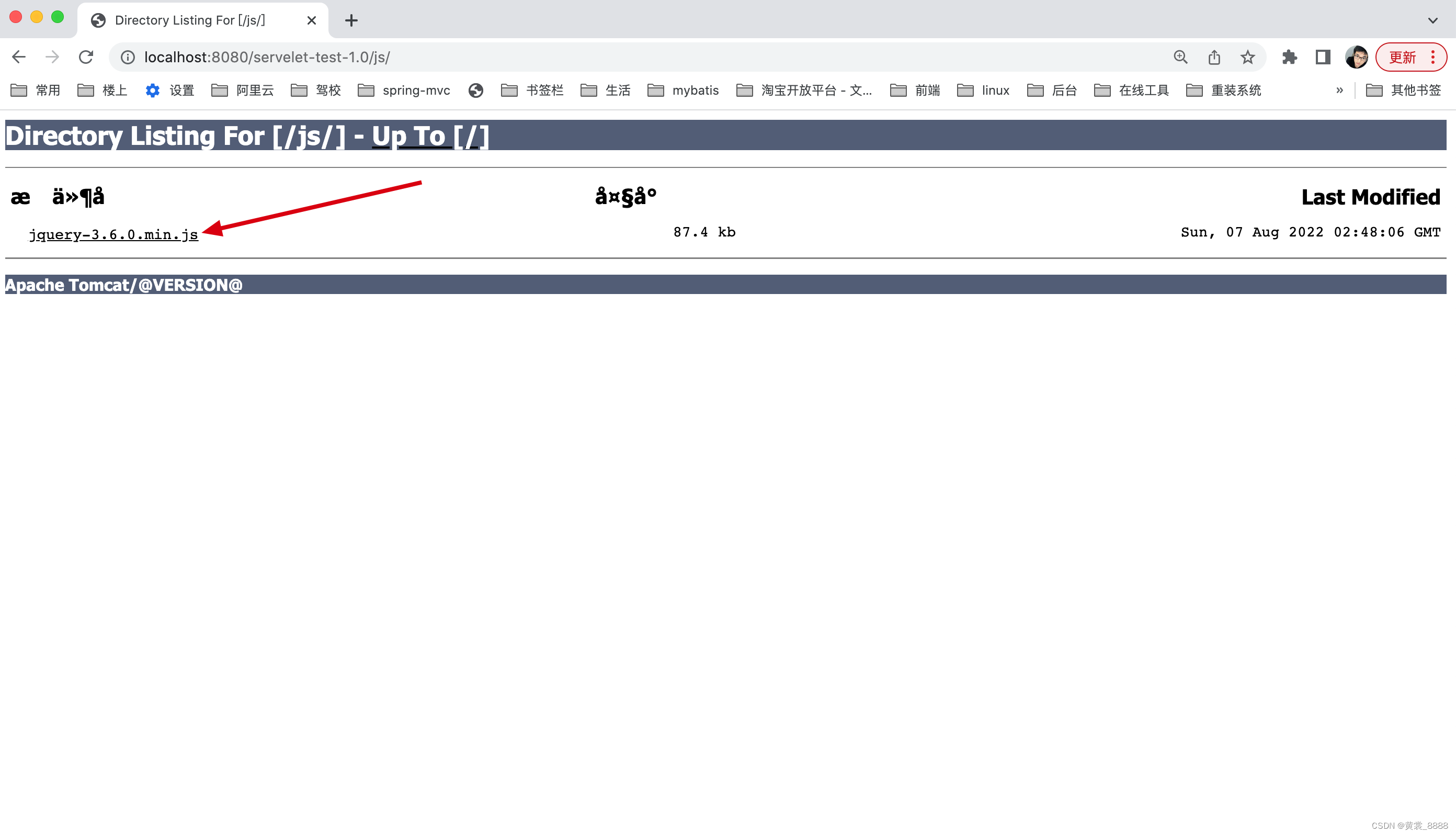
jquery-3.6.0.min.js终于可以访问了。
在doLookupWithoutNNFE()方法中,我们还有一段代码没有分析。... String resourceName = "/META-INF/resources" + name; for (DirContext altDirContext : altDirContexts) { if (altDirContext instanceof BaseDirContext) { obj = ((BaseDirContext) altDirContext) .doLookupWithoutNNFE(resourceName); } else { try { obj = altDirContext.lookup(resourceName); } catch (NamingException ex) { } } if (obj != null) { return obj; } } ...这段代码什么意思呢? 感觉又用了递归,Tomcat帮我们做了另外一层的考虑,我们不仅可以访问我们web 项目下的资源,而且还可以访问我们引入的jar包的资源,但是资源必须放在/META-INF/resources下。 我们来看个例子。
-
新创建一个项目 ,将js 拷贝到新项目的/resources/META-INF/resources/目录下,项目的github地址为
https://github.com/quyixiao/test-resource.git
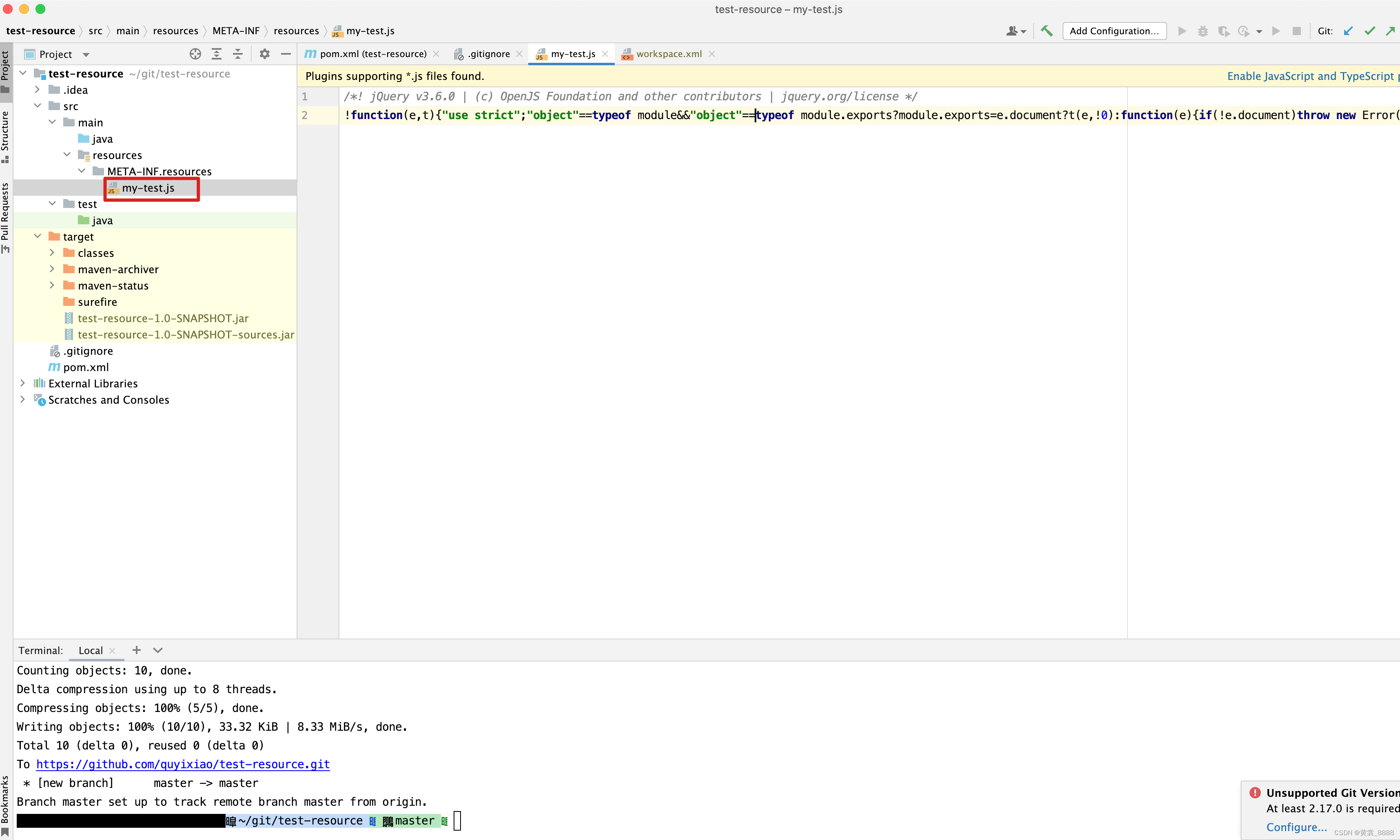
-
项目打包并添加依赖。
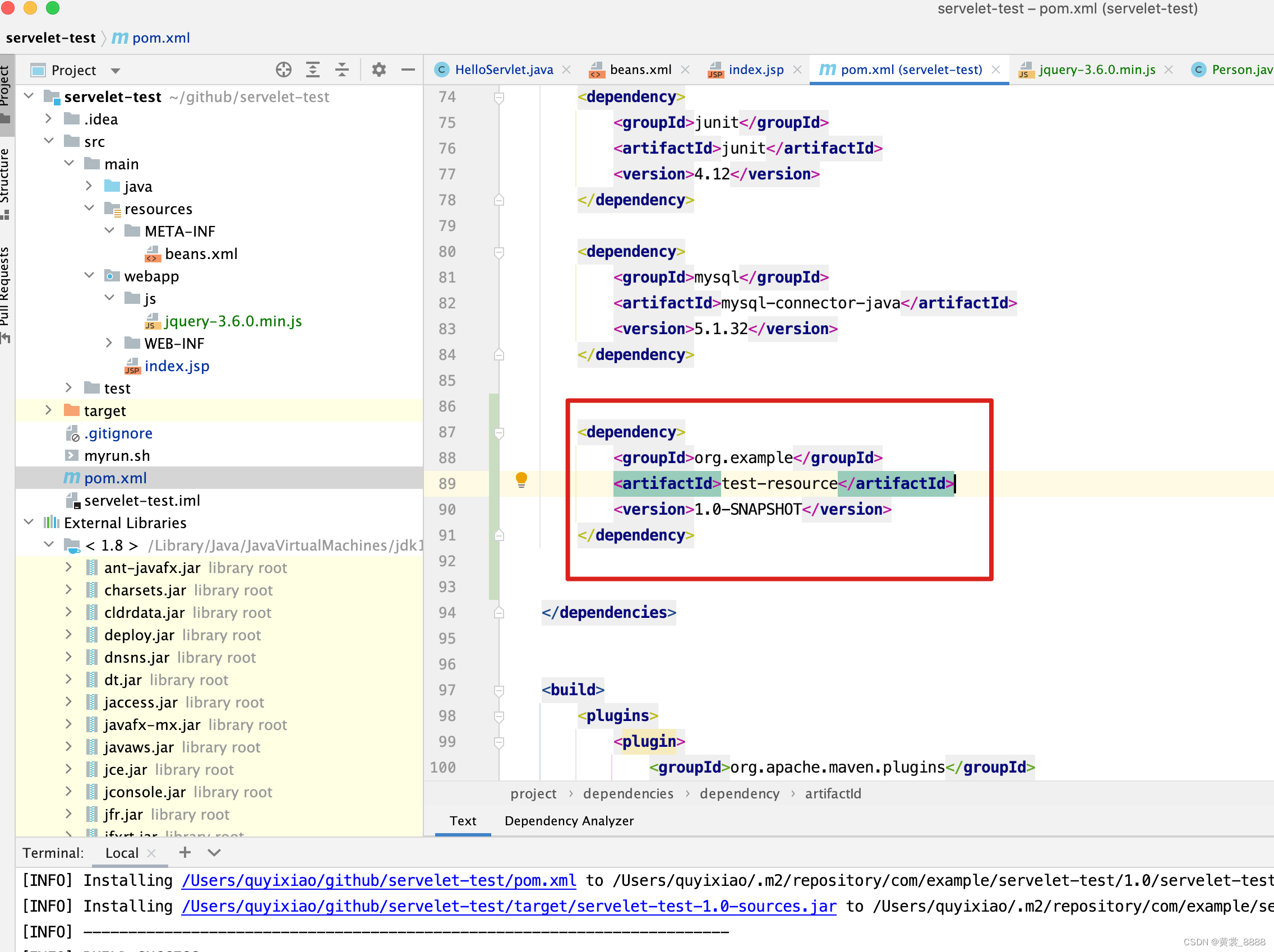
-
将项目导入到tomcat 的webapps目录下
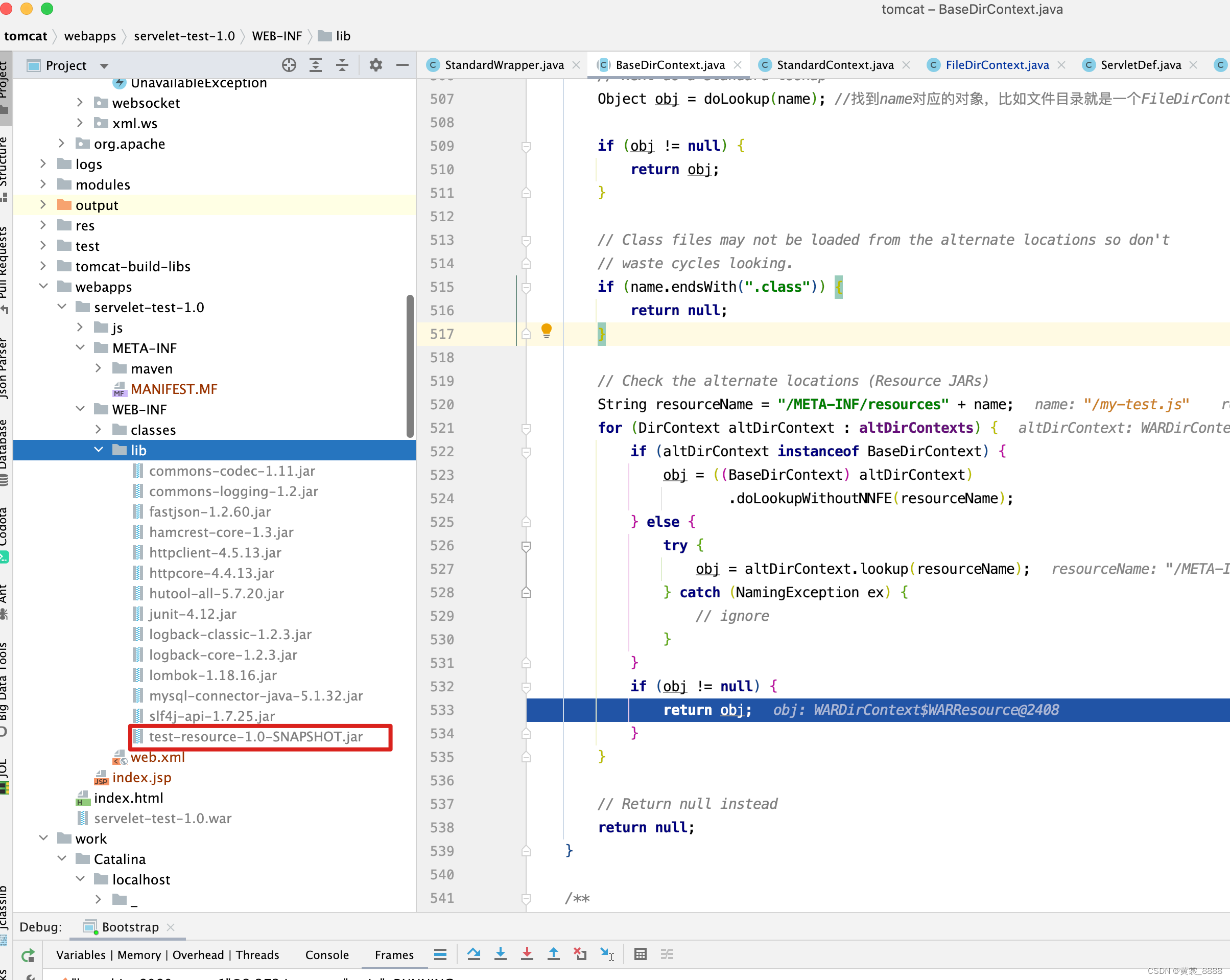
-
反编译看test-resource-1.0-SNAPSHOT.jar的结构
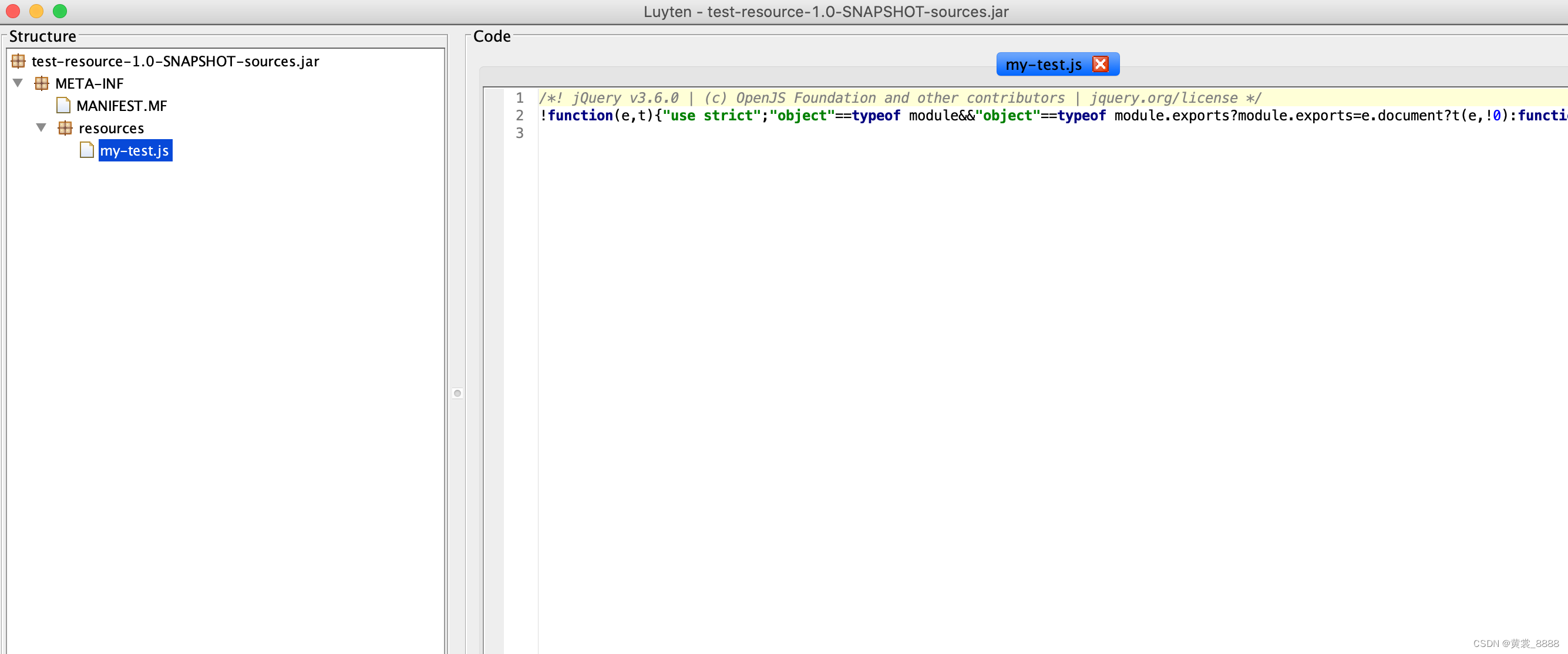
-
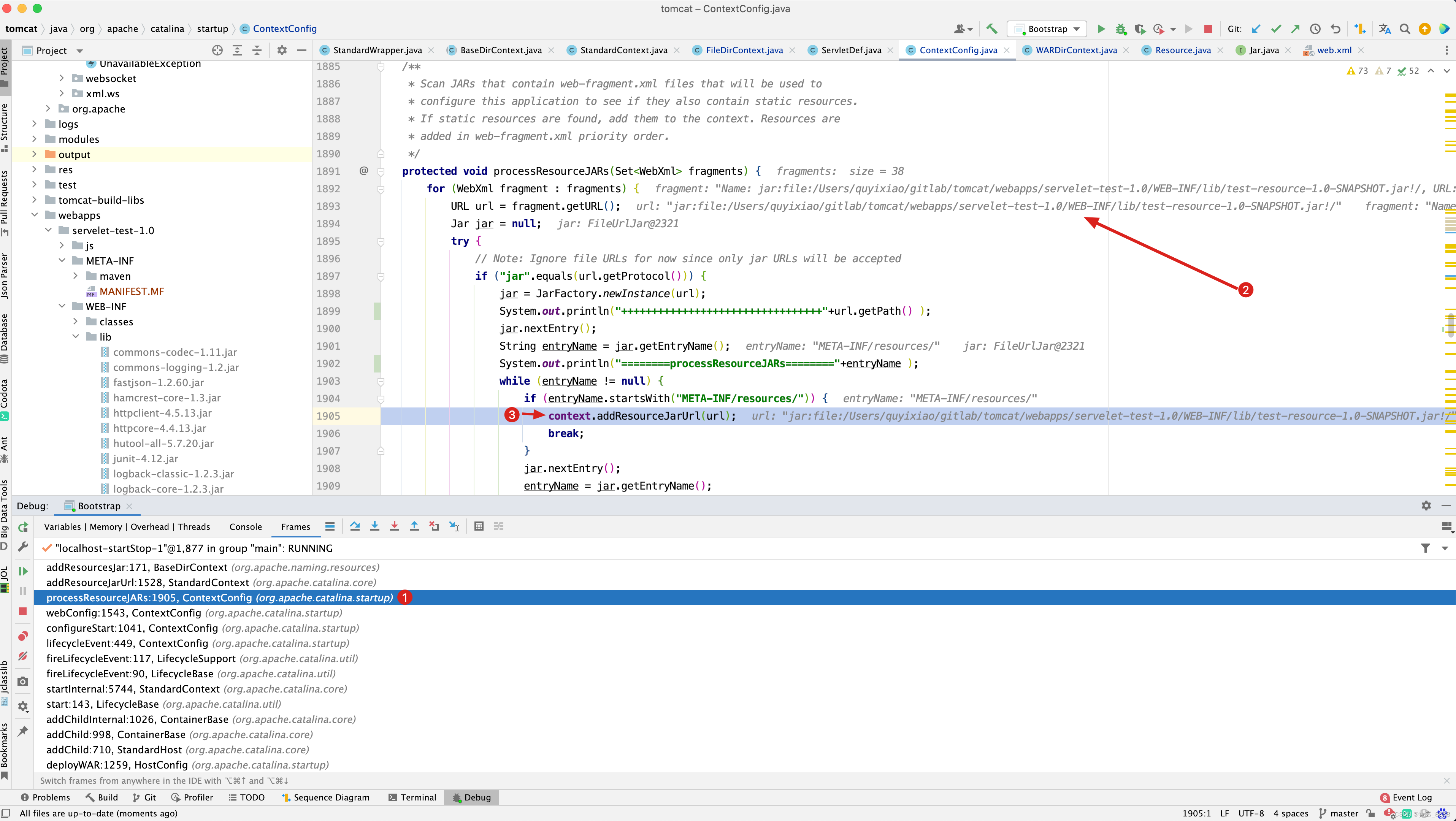
启动项目,在ContextConfig启动是会调用configureStart()方法,在processResourceJARs()方法中将jar包下有META-INF/resources/资源的添加到Context中。
-
构建成WARDirContext添加到altDirContexts中
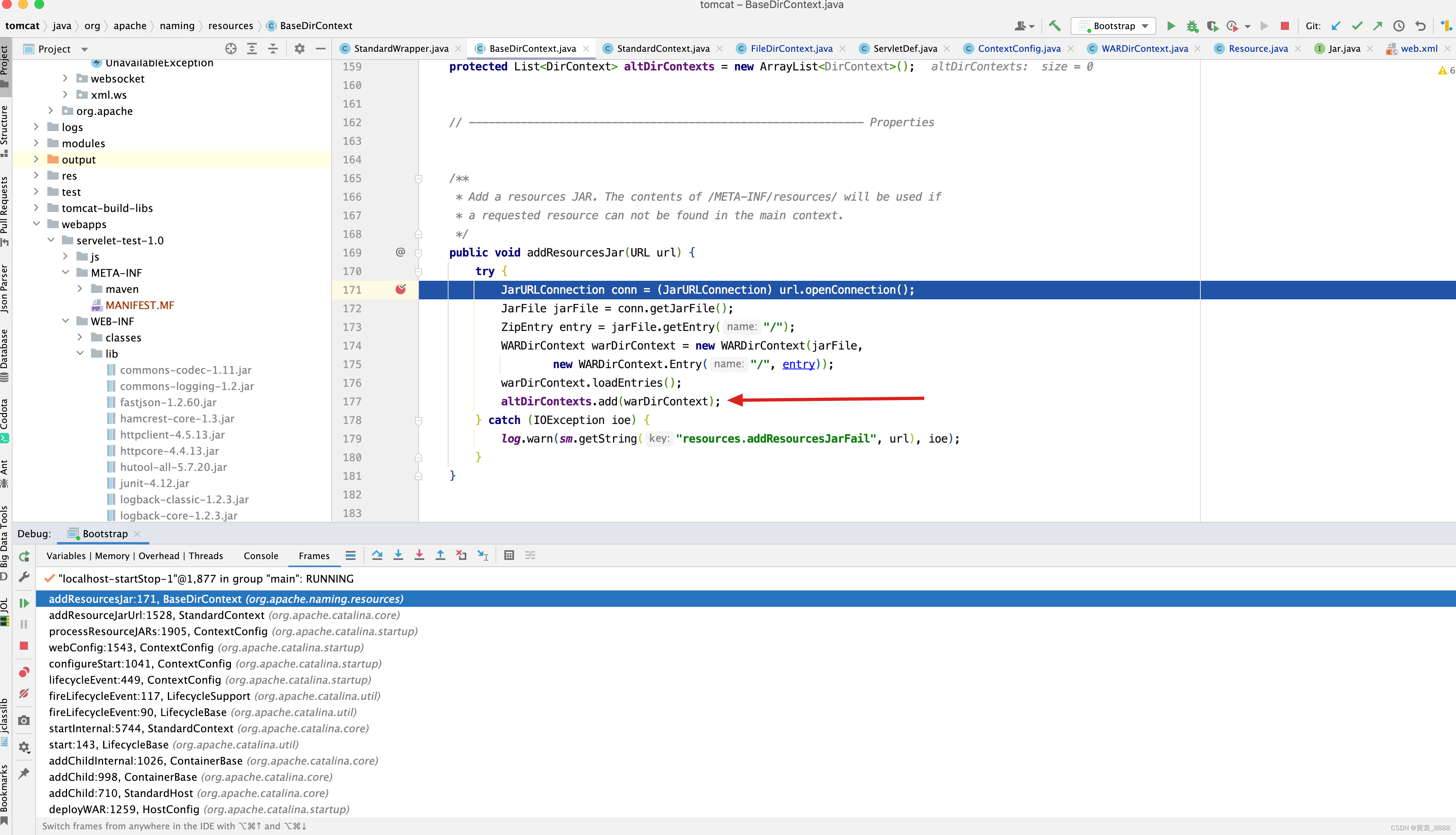
当在web项目中找不到资源时,会遍历altDirContexts,调用其doLookupWithoutNNFE()方法,从而找到资源 。
- 执行结果,访问http://localhost:8080/servelet-test-1.0/my-test.js,一样能访问到js资源
不知道此时此刻,大家有没有被源码绕晕了,庆幸的是,我还没有晕,我们只讲过,如果从缓存中查找,没有找到,则从FileDirContext中或WARDirContext中查找,那么从缓存中的查找算法是怎样子的呢?我们进入cache.lookup()方法 。
public CacheEntry lookup(String name) { CacheEntry cacheEntry = null; CacheEntry[] currentCache = cache; // 访问次数 + 1 accessCount++; // 通过find方法查找 int pos = find(currentCache, name); if ((pos != -1) && (name.equals(currentCache[pos].name))) { cacheEntry = currentCache[pos]; } if (cacheEntry == null) { try { // 如果没有找到,则从notFoundCache中查找 cacheEntry = notFoundCache.get(name); } catch (Exception e) { // Ignore: the reliability of this lookup is not critical } } if (cacheEntry != null) { // 缓存命中次数 + 1 hitsCount++; } return cacheEntry; }
从缓存中查找分为两步,find()方法实际上是查找之前在web 项目下找到file资源或目录资源的缓存中查找,如果找不到,则从notFoundCache中查找,而之前在allocate()方法中分析过, notFoundCache存储的实际上是没有在web项目下找到资源的CacheEntry,这样做的好处是,如用户恶意访问/my-test.jsaaa,这个资源在web项目中不存在,如果将查找结果缓存起来,下次用户再恶意访问/my-test.jsaaa资源时,直接从缓存中就能返回,避免不必要的CPU资源的浪费,从而提升性能 。 接下来我们继续看find()方法如何实现。
private static final int find(CacheEntry[] map, String name) { int a = 0; int b = map.length - 1; if (b == -1) { return -1; } if (name.compareTo(map[0].name) < 0) { return -1; } if (b == 0) { return 0; } int i = 0; while (true) { i = (b + a) >>> 1; int result = name.compareTo(map[i].name); if (result > 0) { a = i; } else if (result == 0) { return i; } else { b = i; } if ((b - a) == 1) { int result2 = name.compareTo(map[b].name); if (result2 < 0) { return a; } else { return b; } } } }
>>> 1 无符号右移一位,之前在HashMap源码解析时已经分析过很多次了,当了解了这个符号的意思,我相信大家再来看代码是不是很简单了, (b + a) >>> 1 = (b + a ) / 2 的意思, 这不就是一个字符串的二分查找法不? 自己理解一下的哈。如果还不理解,自己写一个方法,打断点测试一下即可 。
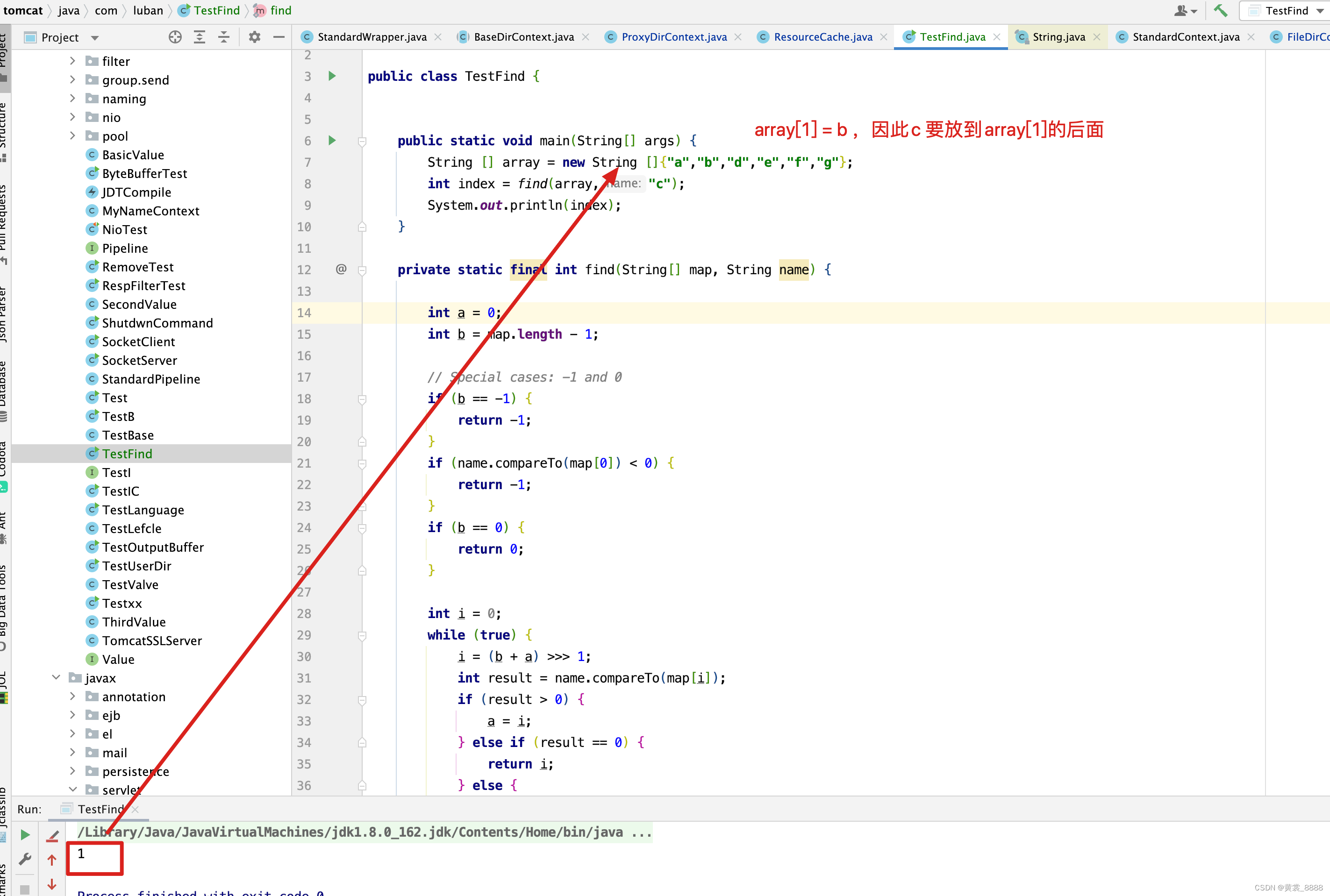
接下来,我们继续分析之前没有分析完的代码,在cacheLoad()中有一行蓝色的代码,
entry.resource.setContent(b);,我们将文件转化为byte[]数组存储到了content()中,但又是在哪里返回给前端的呢?
在DefaultServlet类的serveResource方法中,有一行
copy(cacheEntry, renderResult, ostream);方法。 我们进入copy()方法 。
我们进入copy()方法 。protected void copy(CacheEntry cacheEntry, InputStream is, ServletOutputStream ostream) throws IOException { IOException exception = null; InputStream resourceInputStream = null; if (cacheEntry.resource != null) { byte buffer[] = cacheEntry.resource.getContent(); if (buffer != null) { ostream.write(buffer, 0, buffer.length); return; } resourceInputStream = cacheEntry.resource.streamContent(); } else { resourceInputStream = is; } InputStream istream = new BufferedInputStream (resourceInputStream, input); // Copy the input stream to the output stream exception = copyRange(istream, ostream); // Clean up the input stream istream.close(); // Rethrow any exception that has occurred if (exception != null) throw exception; }上面加粗代码就是将file的byte写回给前端的代码 ,但是需要注意,当项目启动后,第二次访问http://localhost:8080/servelet-test-1.0/js/jquery-3.6.0.min.js时,会进入checkIfHeaders()方法较验。
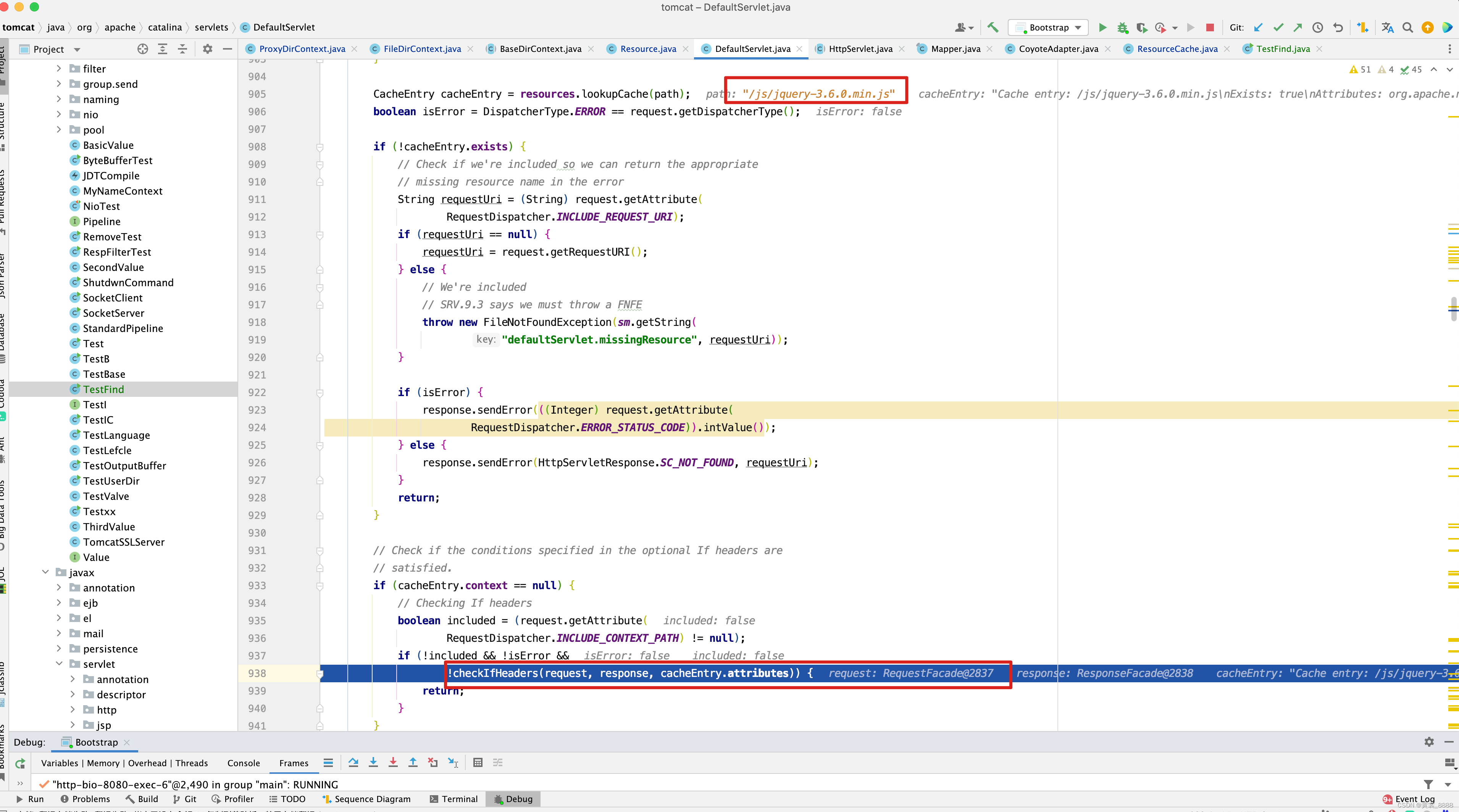
此时可能就不会进入到copy()方法,将content的byte数据返回给前端了,如果想每次访问都通过服务器返回怎么办, 如google浏览器,【清除浏览器数据】即可。 那checkIfHeaders方法较验了哪些内容呢?protected boolean checkIfHeaders(HttpServletRequest request, HttpServletResponse response, ResourceAttributes resourceAttributes) throws IOException { // headers 中的 If-Match , If-Match HTTP 请求报头使得所述请求为条件。 // 对于GET和HEAD方法,服务器将只在与请求的资源匹配时发回请求的资源ETags。对于PUT和其他非安全方法 // 在这种情况下它只会上传资源。 return checkIfMatch(request, response, resourceAttributes) // headers 中的If-Modified-Since , If-Modified-Since请求的HTTP标头发出请求的条件: // 服务器会发送回所请求的资源,用200状态,只有当它已经给定的日期之后被最后修改。如果请求没有被修改, // 那么响应将是304没有任何主体的;Last-Modified头将包含最后一次修改的日期。不同于If-Unmodified-Since // If-Modified-Since只能与GET或HEAD一起使用。 && checkIfModifiedSince(request, response, resourceAttributes) // headers中的 If-None-Match , If-None-Match HTTP 请求报头使得所述请求为条件。对于GET和HEAD方法,200只有服务器没有ETag与给定资源匹配的情况下 // 服务器才会返回具有状态的请求资源。对于其他方法,仅当最终现有资源ETag不符合任何列出的值时才会处理该请求。当条件GET和HEAD方法失败时 // 服务器必须返回 HTTP 状态码304(未修改)。对于应用服务器端更改的方法,将使用状态码412( Precondition Failed )。 // 请注意,生成304响应的服务器必须生成以下头域中的任何一个头域,这些域头域应该发送到同一个请求的200(OK)响应中: // Cache-Control,Content-Location,Date,ETag,Expires 和 Vary。 && checkIfNoneMatch(request, response, resourceAttributes) // headers 中的 If-Unmodified-Since , If-Unmodified-Since请求的HTTP标头发出请求的条件:服务器会发送回所请求的资源 // 或者接受它的情况下POST或其他非安全的方法,只要它没有被最后给定的日期之后修改。如果请求在给定日期之后被修改 // 则该响应将是412(先决条件失败)错误。 && checkIfUnmodifiedSince(request, response, resourceAttributes); }上面4个方法的原理也是很简单的,对着注释,再看一下源码,秒懂,随便看一个方法的源码吧。 看最后一个。
protected boolean checkIfUnmodifiedSince(HttpServletRequest request, HttpServletResponse response, ResourceAttributes resourceAttributes) throws IOException { try { // 文件的最后修改时间 long lastModified = resourceAttributes.getLastModified(); // 客户端保存的文件最后修改时间 long headerValue = request.getDateHeader("If-Unmodified-Since"); if (headerValue != -1) { // 如果服务器文件的最后修改时间 > 客户端保存的最后修改时间 + 1 秒,则返回402 if ( lastModified >= (headerValue + 1000)) { response.sendError(412); return false; } } } catch(IllegalArgumentException illegalArgument) { return true; } return true; }
在本例中,当请求了http://localhost:8080/servelet-test-1.0/js/jquery-3.6.0.min.js后,再次请求,则返回了304状态码,对于GET 或HEAD方法,如果资源没有被修改,则返回304 ,因此你会发现服务器并没有将byte再次写到response中。
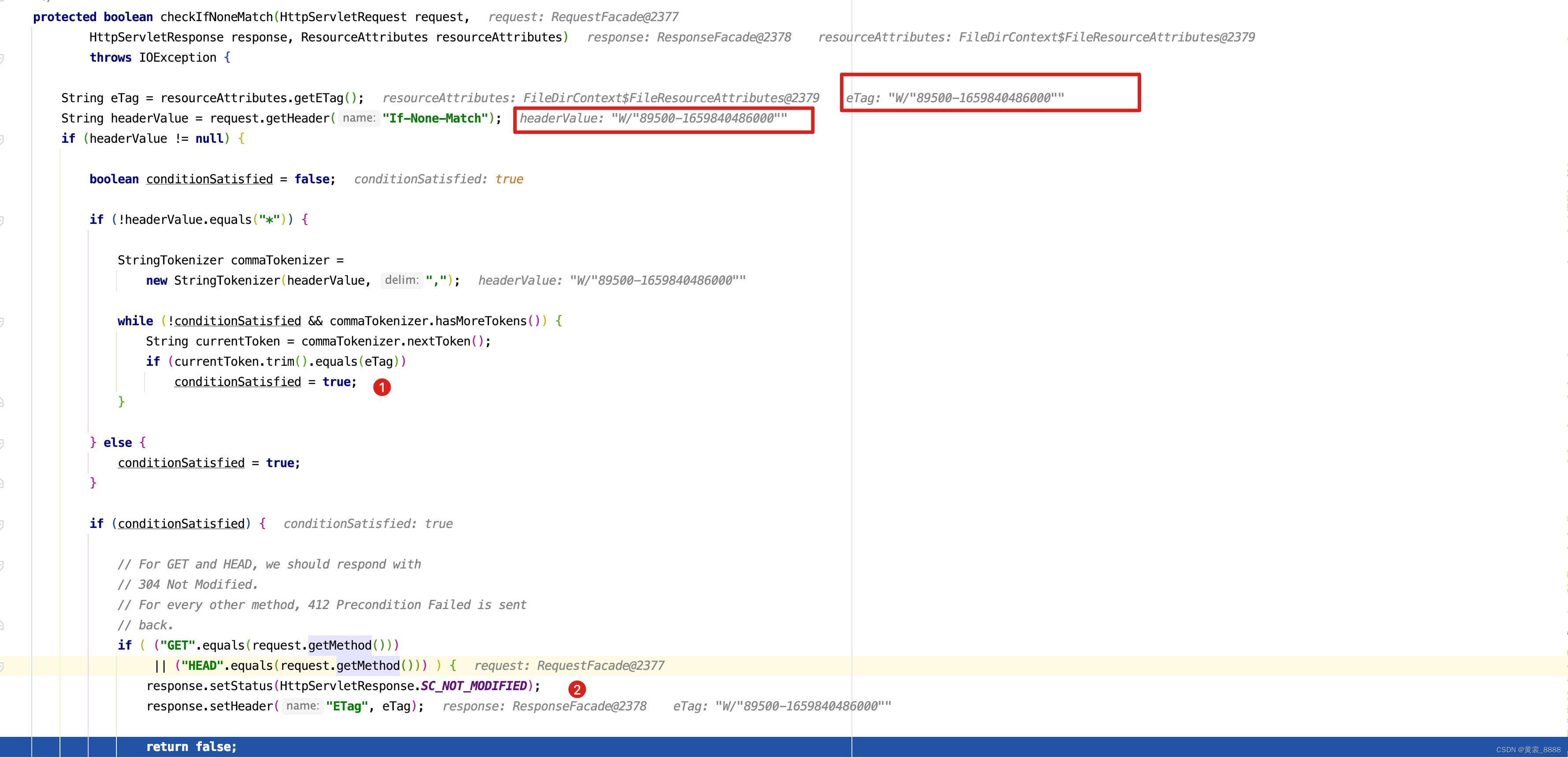
我们之前测试过,将listings改成true时,是可以访问目录的,结果又是怎样封装返回的呢?default org.apache.catalina.servlets.DefaultServlet debug 0 listings true 1 依然是代码中寻寻觅觅,最终进入了render方法。
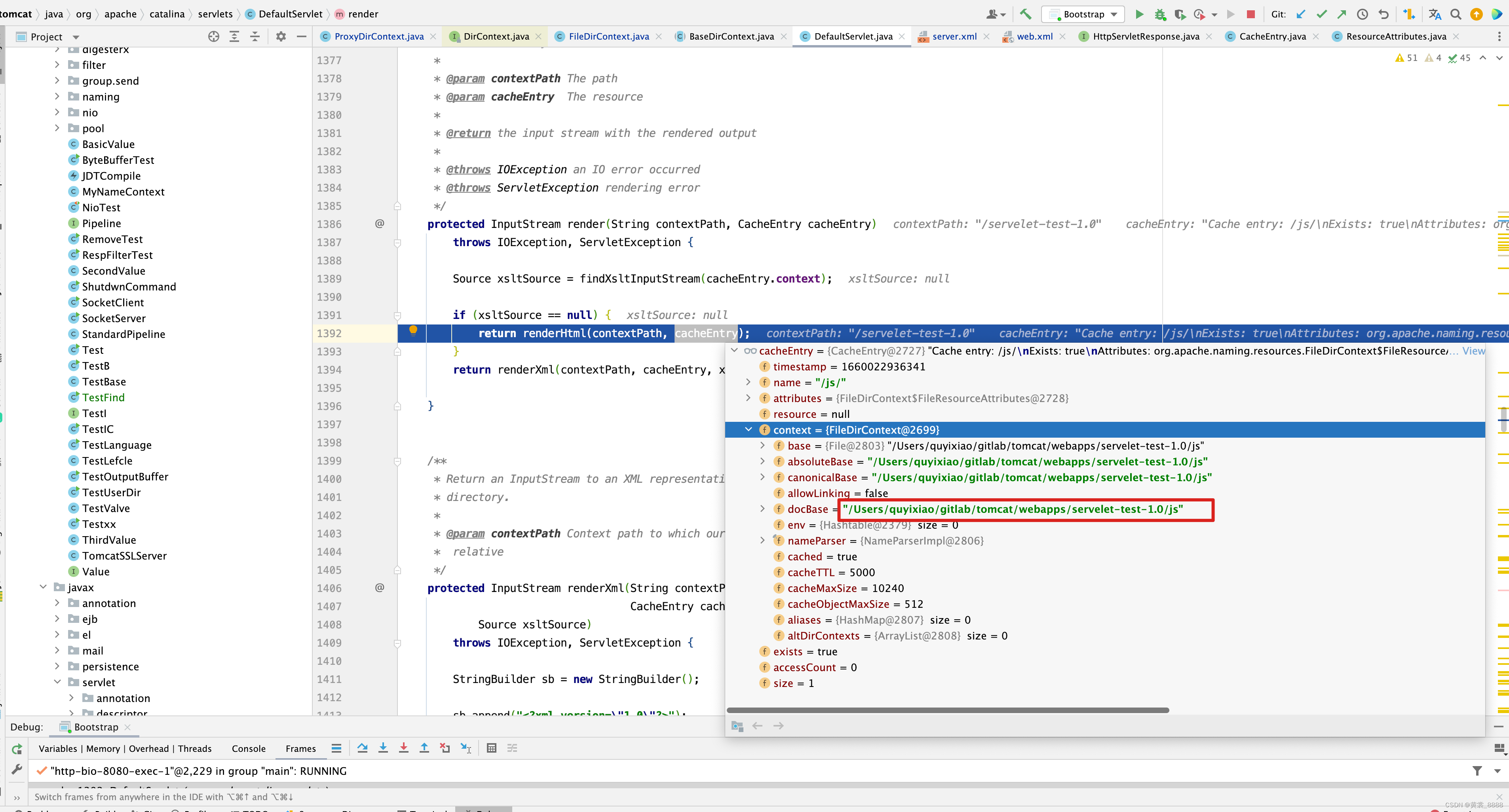
进入render方法()protected InputStream render(String contextPath, CacheEntry cacheEntry) throws IOException, ServletException { Source xsltSource = findXsltInputStream(cacheEntry.context); if (xsltSource == null) { return renderHtml(contextPath, cacheEntry); } return renderXml(contextPath, cacheEntry, xsltSource); }protected InputStream renderHtml(String contextPath, CacheEntry cacheEntry) throws IOException, ServletException { String name = cacheEntry.name; ByteArrayOutputStream stream = new ByteArrayOutputStream(); OutputStreamWriter osWriter = new OutputStreamWriter(stream, "UTF-8"); PrintWriter writer = new PrintWriter(osWriter); StringBuilder sb = new StringBuilder(); String rewrittenContextPath = rewriteUrl(contextPath); sb.append("\r\n"); sb.append("\r\n"); sb.append("
"); sb.append(sm.getString("directory.title", name)); sb.append(" \r\n"); sb.append(" "); sb.append("\r\n"); sb.append(""); sb.append(""); sb.append(sm.getString("directory.title", name)); // Render the link to our parent (if required) String parentDirectory = name; if (parentDirectory.endsWith("/")) { parentDirectory = parentDirectory.substring(0, parentDirectory.length() - 1); } int slash = parentDirectory.lastIndexOf('/'); if (slash >= 0) { String parent = name.substring(0, slash); sb.append(" - "); sb.append(""); sb.append(sm.getString("directory.parent", parent)); sb.append(""); sb.append(""); } sb.append("
"); sb.append("
"); sb.append("\r\n"); // Render the column headings sb.append("
\r\n"); sb.append("\r\n"); sb.append(" "); try { // Render the directory entries within this directory NamingEnumeration"); sb.append(sm.getString("directory.filename")); sb.append(" \r\n"); sb.append(""); sb.append(sm.getString("directory.size")); sb.append(" \r\n"); sb.append(""); sb.append(sm.getString("directory.lastModified")); sb.append(" \r\n"); sb.append("enumeration = resources.list(cacheEntry.name); boolean shade = false; while (enumeration.hasMoreElements()) { NameClassPair ncPair = enumeration.nextElement(); String resourceName = ncPair.getName(); String trimmed = resourceName/*.substring(trim)*/; if (trimmed.equalsIgnoreCase("WEB-INF") || trimmed.equalsIgnoreCase("META-INF")) continue; CacheEntry childCacheEntry = resources.lookupCache(cacheEntry.name + resourceName); if (!childCacheEntry.exists) { continue; } sb.append("\r\n"); sb.append("sb.append(resourceName); if (childCacheEntry.context != null) sb.append("/"); sb.append("\">"); sb.append(RequestUtil.filter(trimmed)); if (childCacheEntry.context != null) sb.append("/"); sb.append(" \r\n"); sb.append(""); if (childCacheEntry.context != null) sb.append(" "); else sb.append(renderSize(childCacheEntry.attributes.getContentLength())); sb.append(" \r\n"); sb.append(""); sb.append(childCacheEntry.attributes.getLastModifiedHttp()); sb.append(" \r\n"); sb.append("\r\n"); } } catch (NamingException e) { // Something went wrong throw new ServletException("Error accessing resource", e); } // Render the page footer sb.append("
"); String readme = getReadme(cacheEntry.context); if (readme!=null) { sb.append(readme); sb.append("
"); } if (showServerInfo) { sb.append("").append(ServerInfo.getServerInfo()).append("
"); } sb.append("\r\n"); sb.append("\r\n"); // Return an input stream to the underlying bytes writer.write(sb.toString()); writer.flush(); return new ByteArrayInputStream(stream.toByteArray()); }sm.getString(“directory.filename”),directory.filename的相关配置如下。
directory.filename=Filename
directory.lastModified=Last Modified
directory.parent=Up To [{0}]
directory.size=Size
directory.title=Directory Listing For [{0}]通过renderHtml得到的html为
Directory Listing For [/js/] Directory Listing For [/js/] - Up To [/]
Filename Size Last Modified jquery-3.6.0.min.js 87.4 kb Sun, 07 Aug 2022 02:48:06 GMT
Apache Tomcat/@VERSION@
