-
Java-Day15 常用类解析 (包装类、Junit测试单元、Object类、String类及StringBuffer和StringBuilder)
目录
4.2 StringBuffer和StringBuilder
1. 基本数据类型包装类
1.1 什么是包装类
Java是强类型的语言,我们已经知道,Java的数据类型分两种:
-
基本类型:
byte,short,int,long,boolean,float,double,char,8种 -
引用类型:所有
class和interface类型
引用类型可以赋值为
null,表示空,但基本类型不能赋值为null:- String s = null;
- int n = null; // compile error!
那么,如何把一个基本类型视为对象(引用类型)?
比如,想要把
int基本类型变成一个引用类型,我们可以定义一个Integer类,它只包含一个实例字段int,这样,Integer类就可以视为int的包装类(Wrapper Class):- public class Integer {
- private int value;
- public Integer(int value) {
- this.value = value;
- }
- public int intValue() {
- return this.value;
- }
- }
定义好了
Integer类,我们就可以把int和Integer互相转换:- Integer n = null;
- Integer n2 = new Integer(99);
- int n3 = n2.intValue();
1.2 Java中的包装类
实际上,因为包装类型非常有用,Java核心库为每种基本类型都提供了对应的包装类型,在java.lang包中存在我们8种基本数据类型对应的包装类,Number是所有的包装类的父类。
基本数据类型 对应包装类 byte Byte short Short int Integer long Long float Float double Double boolean Boolean char Character 有了包装类,基本数据类型的功能得的了非常大强化和扩展。
我们可以直接使用,并不需要自己再去定义了。
所有的包装类型都是不变类,被final修饰,因此,一旦创建了
Integer对象,该对象就是不变的。1.3 装箱和拆箱功能
1.3.1 装箱
所谓装箱,就是基本数据类型包装成包装类的实例
⭐1. 通过包装类的构造器实现: jdk9以及之后版本过时了,不建议使用该方法
- int i = 500;
- Integer t = new Integer(i);
⭐2. 还可以通过字符串参数构造包装类对象:
- Float f = new Float(“4.56”);
- Long l = new Long(“asdf”); //NumberFormatException
⭐3. 通过静态工厂方法实现(推荐使用):
我们把能创建“新”对象的静态方法称为静态工厂方法。
Integer.valueOf()就是静态工厂方法,它尽可能地返回缓存的实例以节省内存。因为
Integer.valueOf()可能始终返回同一个Integer实例,所有可以通过静态工厂方法实现Integer n = Integer.valueOf(100);1.3.2 拆箱
所谓拆箱,就是获得包装类对象中包装的基本类型变量
⭐调用包装类的.xxxValue()方法:
boolean b = bObj.booleanValue();JDK1.5之后,支持自动装箱,自动拆箱。但类型必须匹配。
注意:
包装类是对象,基本数据类型是常量
对两个
Integer实例进行比较要特别注意:绝对不能用==比较,因为Integer是引用类型,必须使用equals()比较:- public class WrapperTest {
- public static void main(String[] args) {
- Integer i1 = 1234;
- Integer i2 = 1234;
- Integer i3 = 127;
- Integer i4 = 127;
- System.out.println(i1 == i2); // false
- System.out.println(i1.equals(i2)); // true
- System.out.println(i3 == i4); // true
- System.out.println(i3.equals(i4)); // true
- }
- }
原因:Java中存在一个整数缓冲区,取值范围:-128 ~ 127
因为jdk中存在-128 ~ 127 之间的对象,所以在自动装箱的过程中,如果被装箱的数据在此范围内,那么直接将jdk中创建的对象直接的赋值给栈中的引用,所以为true。否则,当数组过大时,会重新创建包装类的对象,此时就是为false。编译器把
Integer x = 127;自动变为Integer x = Integer.valueOf(127);,为了节省内存,Integer.valueOf()对于较小的数,始终返回相同的实例,因此,==比较“恰好”为true,但我们绝不能因为Java标准库的Integer内部有缓存优化就用==比较,必须用equals()方法比较两个Integer对象。1.4 基本数据类型、包装类、String类之间的转化
基本数据类型、包装类、Sting类之间的转换,如下图:
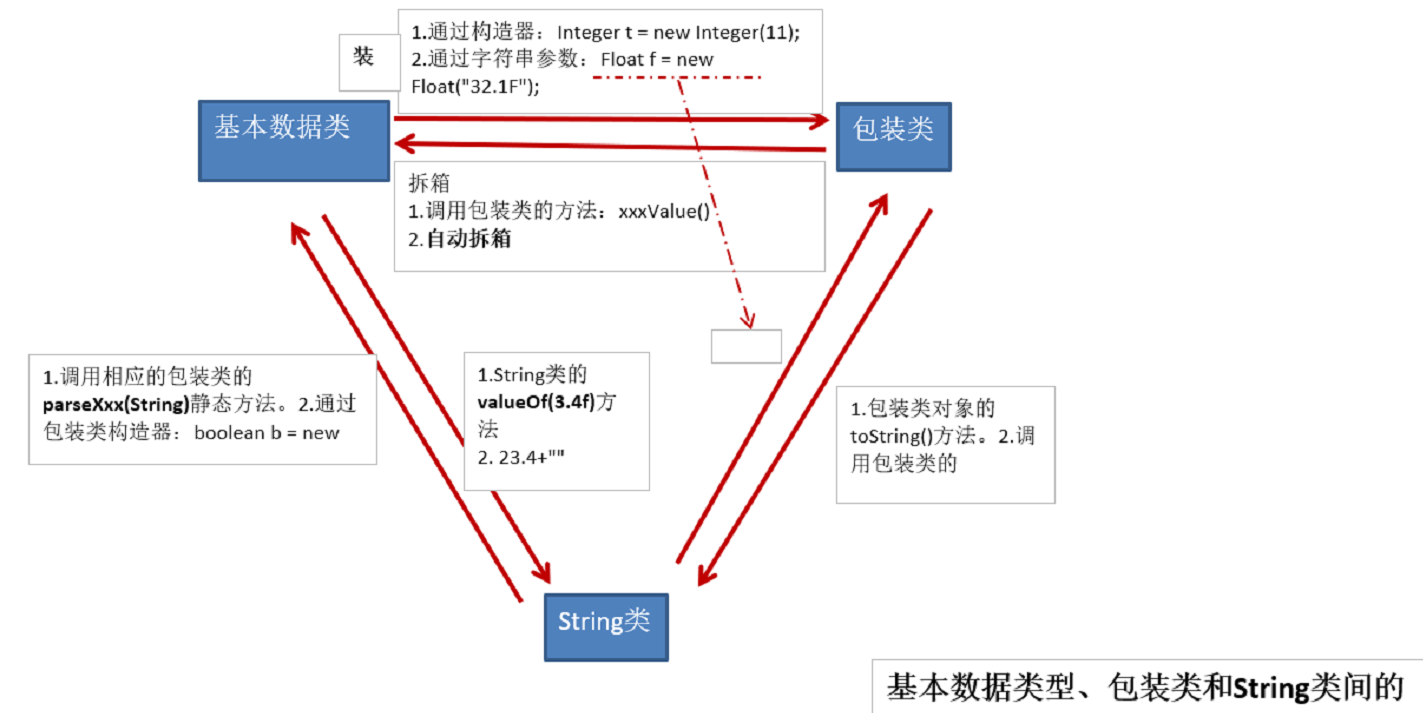
1.4.1 字符串转和基本数据类型之间的转换
字符串转换成基本数据类型
- 通过包装类的构造器实现: int i = new Integer("12");
- 通过包装类的parseXxx(String s)静态方法: Float f = Float.parseFloat("12.1");
int 变量名 = Integer.parseInt(要转换的字符串);
注意:要转换的字符串必须是整形字符串double 变量名 = Double.parseDouble(要转换的字符串);
注意:要转换的字符串必须是纯数字组成的字符串boolean 变量名 = Boolean.parseBoolean(要转换的字符串);
注意:除了"true"字符串转换完是true ,其余的都是false基本数据类型转换成字符串
- 调用字符串重载的valueOf()方法: String fstr = String.valueOf(2.34f);
- 更直接的方式: String intStr = 5 + ""
1.4.2 进制转换
String str = Intrger.toHexString(十进制);
String str = Intrger.toBinaryString(十进制);
2. Junit单元测试
2.1 什么是Juni单元测试
JUnit是一个开源的Java语言的单元测试框架,专门针对Java设计,使用最广泛。JUnit是事实上的单元测试的标准框架,任何Java开发者都应当学习并使用JUnit编写单元测试。
使用JUnit编写单元测试的好处在于,我们可以非常简单地组织测试代码,并随时运行它们,JUnit就会给出成功的测试和失败的测试,还可以生成测试报告,不仅包含测试的成功率,还可以统计测试的代码覆盖率,即被测试的代码本身有多少经过了测试。对于高质量的代码来说,测试覆盖率应该在80%以上。
此外,几乎所有的IDE工具都集成了JUnit,这样我们就可以直接在IDE中编写并运行JUnit测试。JUnit目前最新版本是5。
简单来说,Juni单元测试就是基于某一个方法的测试。
2.2 配置Junit (eclipse)
以Eclipse为例,当我们已经编写了一个
.java文件后,我们想对其进行测试,需要编写一个main()主函数,才能运行。而我们不想编写main函数时,可使用JUnit单元测试,在
Project-Properties-Java Build Path-Libraries中添加JUnit 5的库: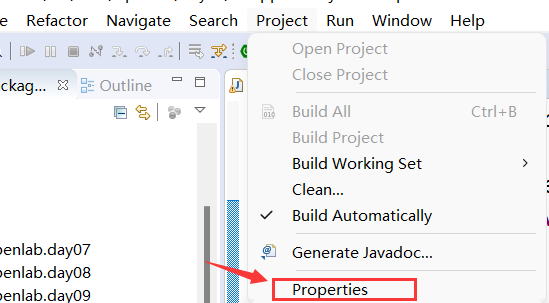
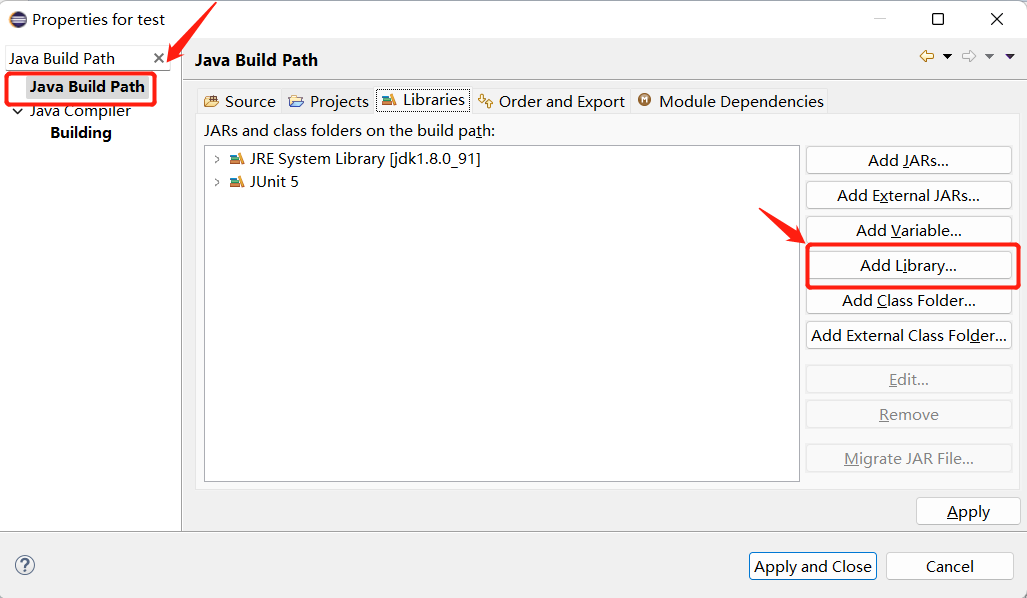
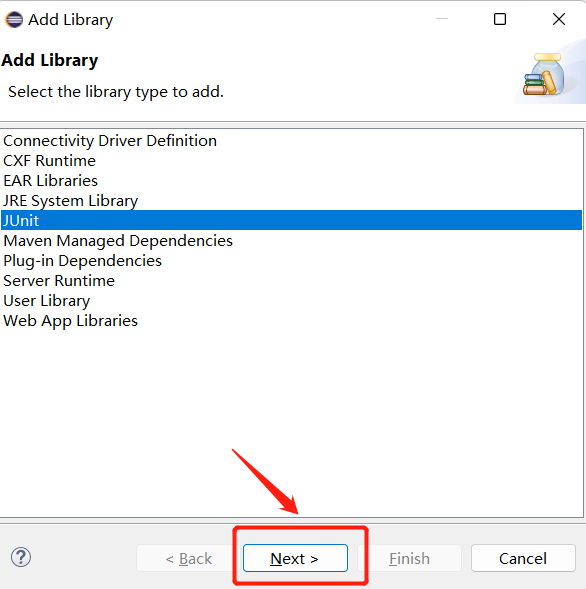
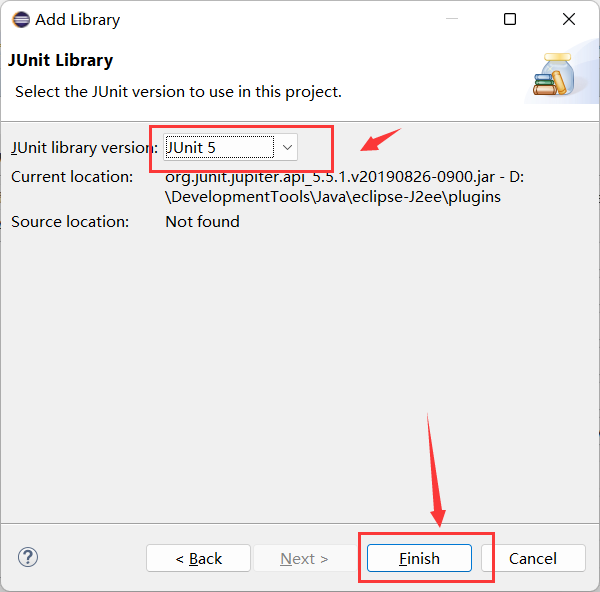
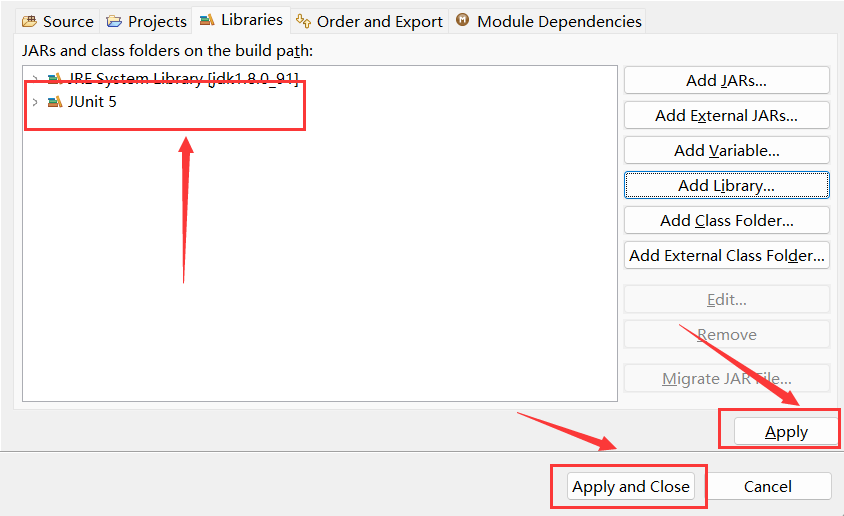
如下图,项目结构中出现JUnit,说明我们就配置完成了。

2.3 使用JUnit单元测试
- import org.junit.jupiter.api.Test; // 导入JUnit单元测试的包
- public class JunitTest {
- @Test // 添加测试的注解
- public void name() {
- System.out.println("Hello");
- }
- }
最后选择JUnit Test进行运行
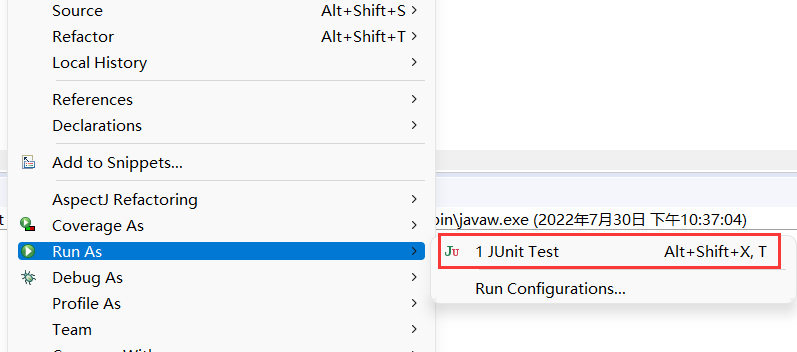
2.4 单元测试的好处
单元测试可以确保单个方法按照正确预期运行,如果修改了某个方法的代码,只需确保其对应的单元测试通过,即可认为改动正确。此外,测试代码本身就可以作为示例代码,用来演示如何调用该方法。
使用JUnit进行单元测试,我们可以使用断言(
Assertion)来测试期望结果,可以方便地组织和运行测试,并方便地查看测试结果。此外,JUnit既可以直接在IDE中运行,也可以方便地集成到Maven这些自动化工具中运行。在编写单元测试的时候,我们要遵循一定的规范:
-
一是单元测试代码本身必须非常简单,能一下看明白,决不能再为测试代码编写测试;
-
二是每个单元测试应当互相独立,不依赖运行的顺序;
-
三是测试时不但要覆盖常用测试用例,还要特别注意测试边界条件,例如输入为
0,null,空字符串""等情况。
3. Object类
Java Object 类是所有类的父类,也就是说 Java 的所有类都继承了 Object,子类可以使用 Object 的所有方法。
Object 类位于 java.lang 包中,编译时会自动导入,我们创建一个类时,如果没有明确继承一个父类,那么它就会自动继承 Object,成为 Object 的子类。
Object 类可以显式继承,也可以隐式继承 (默认不写) ,以下两种方式是一样的。所以:
-
如果一个类没有写继承类,那么默认继承于Object类
-
所有类的对象都可以转换成 Object类
3.1 常用方法
1. protected Object clone():创建并返回一个对象的拷贝,如果要使用这个方法拷贝对象,一定要实现Cloneable接口。在Object类中是被native修饰的,是可以不用我们实现的
2. String toString():返回对象的字符串表示形式
3. public final native Class getClass():获取对象的运行时对象的类,即获取类的字节码文件
4. public native int hashCode:获取对象的哈希码值
5. protected void finalize():当 GC (垃圾回收器)确定不存在对该对象的有更多引用时,由对象的垃圾回收器调用此方法。在当前对象被GC前,会自动触发,适合于做一些垃圾回收前的各种工作,jdk9之后过时了。
6. boolean equals(Object obj):比较对象是否一致,默认比较的对象的内存地址,如果需要比较对象中的属性的值,那么要重写equals方法,如String中。
7. void notify():唤醒在该对象上等待的某个线程
8. void notifyAll():唤醒在该对象上等待的所有线程
9. void wait():让当前线程进入等待状态。直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法。
10. void wait(long timeout):让当前线程处于等待(阻塞)状态,直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法,或者超过参数设置的timeout超时时间。
11. void wait(long timeout, int nanos):与 wait(long timeout) 方法类似,多了一个 nanos 参数,这个参数表示额外时间(以纳秒为单位,范围是 0-999999)。 所以超时的时间还需要加上 nanos 纳秒。
clone()和Cloneable接口:
通过源码注释,我们可以了解到:
1. 对于实现了
Cloneable接口的对象,可以调用Object的clone()来进行属性的拷贝2. 如果没有实现
Cloneable接口,直接调用clone()方法则会抛出CloneNotSupportedException异常3. jdk建议我们实现
Cloneable接口时,以public修饰符重写Object的clone()方法4.Cloneable是一个空接口,如果只实现了该接口,没有重写Object的clone()方法也不会调用成功。示例:
- package com.openlab.day15;
- /**
- * 在java中,如果需要拷贝对象,一定要去该类实现Cloneable接口
- */
- public class Master implements Cloneable{
- private Integer id;
- private String name;
- private String gender;
- private Integer age;
- private Dog dog;
- public Integer getId() {
- return id;
- }
- public void setId(Integer id) {
- this.id = id;
- }
- public String getName() {
- return name;
- }
- public void setName(String name) {
- this.name = name;
- }
- public String getGender() {
- return gender;
- }
- public void setGender(String gender) {
- this.gender = gender;
- }
- public Integer getAge() {
- return age;
- }
- public void setAge(Integer age) {
- this.age = age;
- }
- public Dog getDog() {
- return dog;
- }
- public void setDog(Dog dog) {
- this.dog = dog;
- }
- @Override
- public String toString() {
- return "Master [id=" + id + ", name=" + name + ", gender=" + gender + ", age=" + age + ", dog=" + dog + "]";
- }
- public Master(Integer id, String name, String gender, Integer age, Dog dog) {
- super();
- this.id = id;
- this.name = name;
- this.gender = gender;
- this.age = age;
- this.dog = dog;
- }
- public Master() {
- }
- @Override
- protected Object clone() throws CloneNotSupportedException {
- return super.clone();
- }
- @Override
- protected void finalize() throws Throwable {
- System.out.println("我觉得我还可以挽救下");
- }
- }
- class Dog {
- private Integer id;
- private String name;
- private String gender;
- @Override
- public String toString() {
- return "Dog [id=" + id + ", name=" + name + ", gender=" + gender + "]";
- }
- public Dog(Integer id, String name, String gender) {
- super();
- this.id = id;
- this.name = name;
- this.gender = gender;
- }
- public Integer getId() {
- return id;
- }
- public void setId(Integer id) {
- this.id = id;
- }
- public String getName() {
- return name;
- }
- public void setName(String name) {
- this.name = name;
- }
- public String getGender() {
- return gender;
- }
- public void setGender(String gender) {
- this.gender = gender;
- }
- }
- package com.openlab.day15;
- import org.junit.jupiter.api.Test;
- public class MasterTest {
- @Test
- void test() {
- Dog dog = new Dog(1, "小汪", "公");
- // 将小汪交给了主人
- Master master = new Master(1, "zhang", "男", 18, dog);
- System.out.println(master);
- // 引用传递
- Master m2 = master;
- System.out.println(m2 == master); // true
- Master m3 = null;
- try {
- m3 = (Master) master.clone();
- } catch (CloneNotSupportedException e1) {
- e1.printStackTrace();
- }
- System.out.println(m3 == master); // false
- dog.setName("大黄");
- System.out.println(master);
- System.out.println(m3);
- String result = master.getDog() == m3.getDog() ? "clone是浅拷贝的" : "clone是深拷贝的";
- System.out.println(result); // clone是浅拷贝的
- }
- @Test
- void testFinalize() {
- Master u = new Master();
- u = null;
- System.gc(); // 手动调用下gc();
- // 在当前对象调用gc之后会自动调用finalize(), 所以这里输出:我觉得我还可以挽救下
- try {
- Thread.sleep(3000);
- System.out.println("1");
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
面试题:final、finally、finalize() 这三者的区别与联系
答:final、finally、finalize都是Java中的关键字。
final可以用来修饰类、方法、变量;
finally是java保证重点代码一定要被执行的一种机制,只能出现在异常处理的代码块中,且不能单独使用,必须搭配try;
finalize设计的目的是保证对象在被垃圾收集前完成特定资源的回收,需要注意的是finalize()在jdk9之后过时了。3.2 native关键字
被它修饰的方法,叫做本地方法,都是没有实现体。
使用 native 关键字说明这个方法是原生函数,也就是这个方法是用 C/C++等非 Java 语言实现的,并且被编译成了 DLL,由 java 去调用
有时 java 应用需要与 java 外面的 环境交互。这是本地方法存在的主要原因
native 声明的方法,对于调用者,可以当做和其他 Java 方法一样使用,一个 native method 方法可以返回任何 java 类型,包括非基本类型,而且同样可以进行异常控制。如果一个含有本地方法的类被继承,子类会继承这个本地方法并且可以用 java 语言重写这个方法(如果需要的话)
3.3 引用传递和对象拷贝
3.3.1 引用传递
将栈引用进行复制,堆中的对象始终是一个,protected Object clone()
对象拷贝:堆对象会进行复制
在java中,如果需要拷贝对象,一定要去该类实现Cloneable接口
3.3.2 对象的深浅拷贝
浅拷贝:将对象的第一层完成拷贝,是的两个对象完成了基本的分离,有可能还存在着藕断丝连
基本数据类型的话,值直接拿来,对象引用的话,拿到该对象的内存地址,所以当对象深层改变,拷贝和被拷贝的对象都会改变
- 优点:内存占有较少
- 缺点:如果存在底对象,则子对象没有拷贝,还是指向同一个。
深拷贝:将两个对象完成分离,彼此之间将无任何关系。如:递归拷贝
和浅拷贝不同的是,在深拷贝时,有多层对象的,每个对象都需要实现 Cloneable 并重写 clone()方法,进而实现了对象的串行层层拷贝。
深拷贝相比于浅拷贝速度较慢并且花销较大。
java实现深拷贝有两种方法。
1、所有相关对象都是实现浅拷贝
2、通过序列化对象实现深拷贝:① 对象 <==> 字节数据;② 对象 <==> 字符串数据(如JSON)
因为序列化拷贝是把对象转换为字节序列,再把字节序列恢复成对象,不是属性的拷贝,所以使用序列化拷贝可以不实现
Cloneable接口,但要实现序列化接口4. String类及相关的类
4.1 String字符串
String类:代表字符串。
Java 程序中的所有字符串字面值(如 "abc" )都作为此类的实例实现。
String是一个final类,代表不可变的字符序列。
字符串是常量,用双引号引起来表示。它们的值在创建之后不能更改。存放在字符串常量池中
字符串缓冲池:字符串常量池
面试题:Java中字符串常量池在什么地方?
jdk7之前,字符串常量池在方法区
jdk7之后,字符串常量池被设计到堆中
String对象的字符内容是存储在一个字符数组value[]中的。

4.1.1 String对象的创建
- String str = "hello";
- //本质上this.value = new char[0];
- String s1 = new String();
- //this.value = original.value;
- String s2 = new String(String original);
- //this.value = Arrays.copyOf(value, value.length);
- String s3 = new String(char[] a);
- String s4 = new String(char[] a,int startIndex,int count);
字符串各种创建方式的图解:
- String s;
- String s = null;
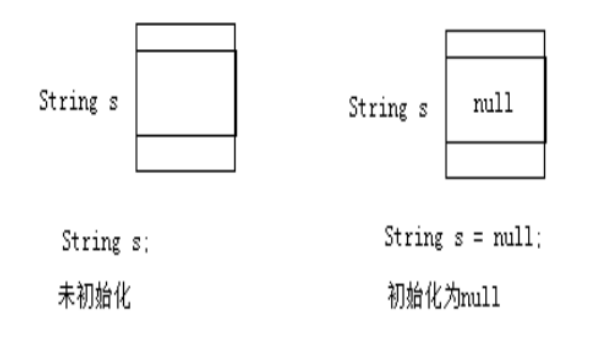
String s = "";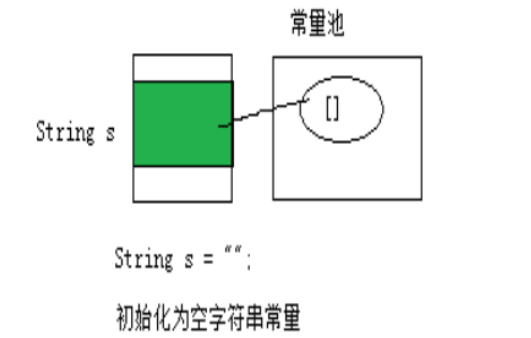
String s = new String();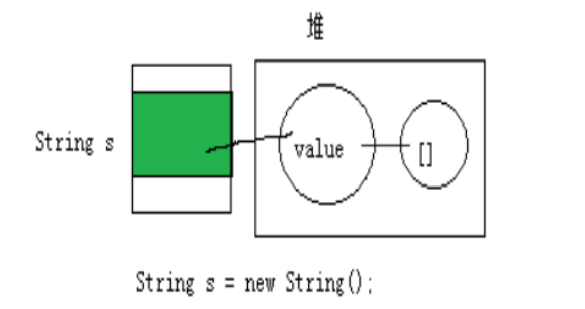
String s = new String("");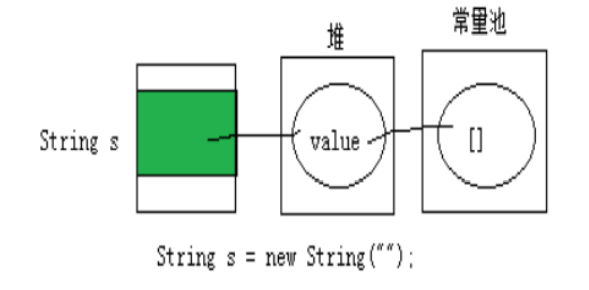
String s = "abc";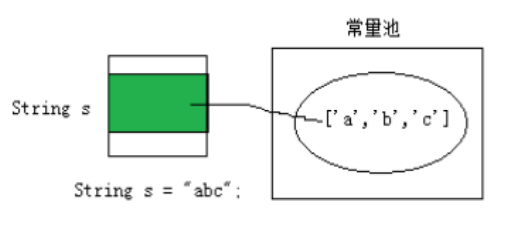
String s = new String("abc");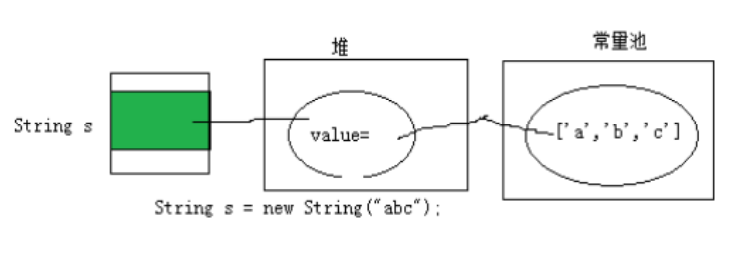
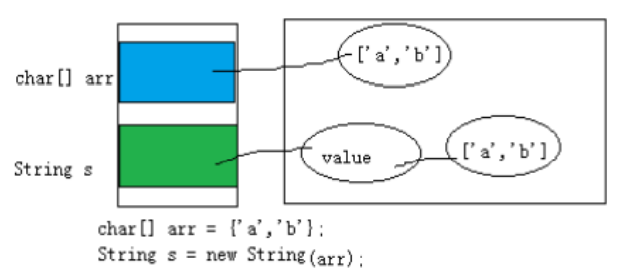
- char[] arr = {'a', 'b'};
- String s = new String(arr);
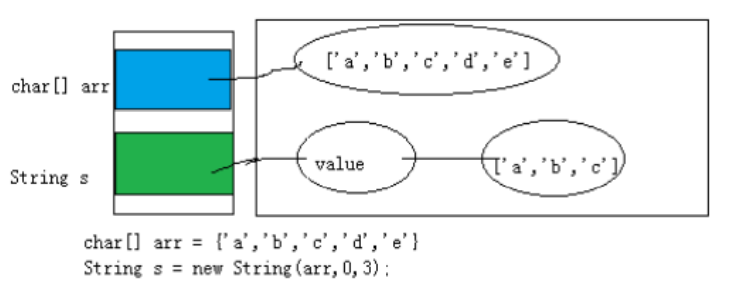
- char[] arr = {'a', 'b', 'c', 'd', 'e'};
- String s = new String(arr, 0, 3);
面试题:String str1 = "abc";与String str2 = new String("abc");的区别?
str1是一个字符串常量,字符串常量存储在字符串常量池,目的是共享;
str2是一个字符串非常量对象,字符串非常量对象存储在堆中。
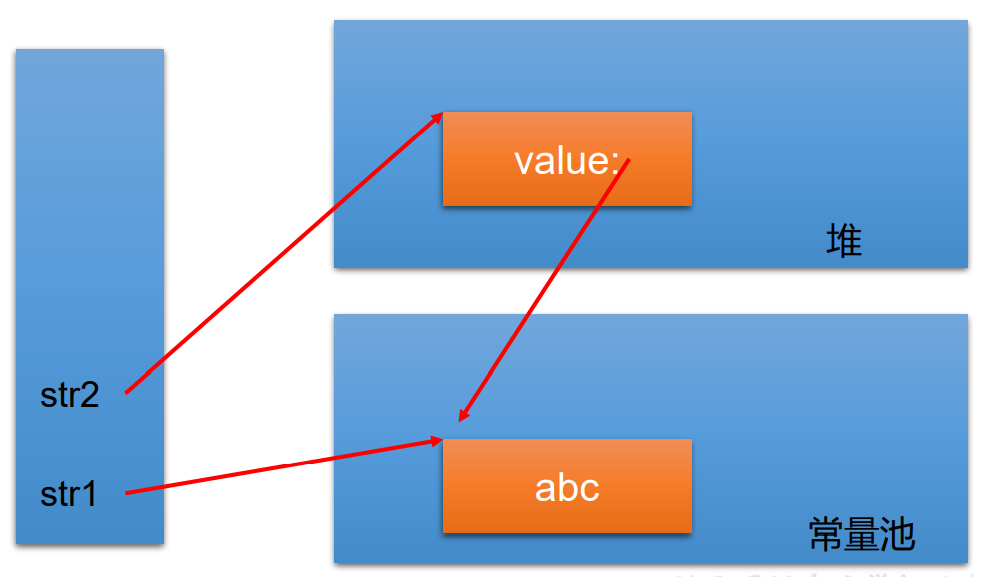
通过上图我们看到,字符串str1和str2两个对象的值都是指向常量池中的"abc",而str1是直接指向常量值,而str2是指向堆空间中的new String()对象,所以我们如果通过==比较,结果为fasle,原因是两个对象的内存地址不一样,当然==的结果就为fasle了。
- String str1 = "abc";
- String str2 = new String("abc");
- // String中重写了hashCode方法,其hashCode值是由常量池中内容决定的,而不是内存地址决定的
- System.out.println(str1.hashCode()); // 96354
- System.out.println(str2.hashCode()); // 96354
- // System.identityHashCode(o) 获取对象的内存地址
- System.out.println(System.identityHashCode(str1)); // 926370398
- System.out.println(System.identityHashCode(str2)); // 1181869371
- System.out.println(str1 == str2); // false
注意:String中重写了hashCode方法,其hashCode值是由常量池中内容决定的,而不是内存地址决定的,如果要字符串对象的内存地址可以通过:System.identityHashCode(o)
4.1.2 字符串对象是如何存储的
字符串常量存储在字符串常量池,目的是共享;字符串非常量对象存储在堆中,堆中的对象再指向字符串常量中的字符串常量。
- String s1 = "javaEE";
- String s2 = "javaEE";
- String s3 = new String("javaEE");
- String s4 = new String("javaEE");
- System.out.println(s1 == s2);//true
- System.out.println(s1 == s3);//false
- System.out.println(s1 == s4);//false
- System.out.println(s3 == s4);//false
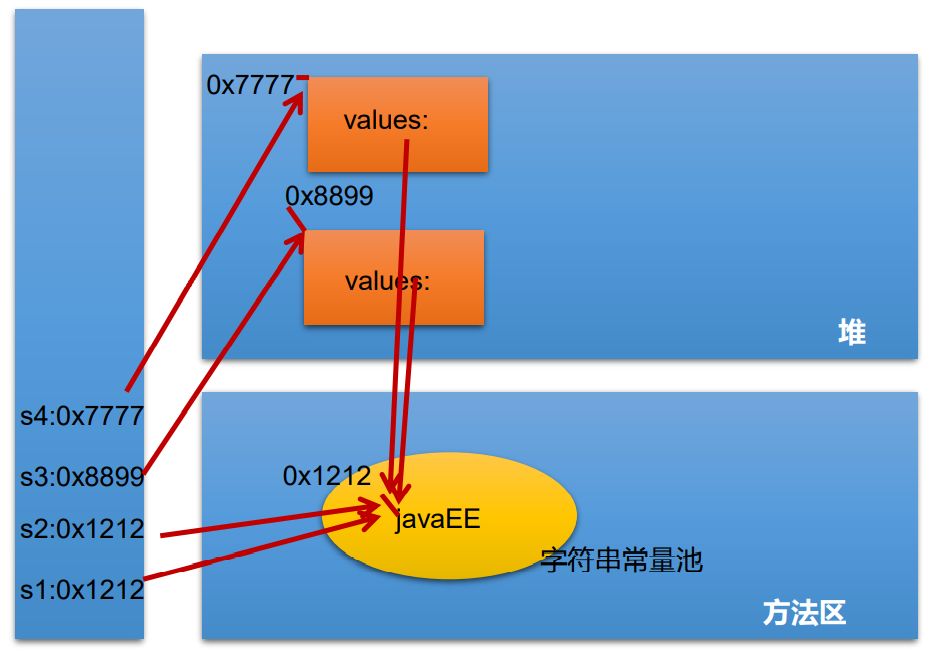
面试题:根据以下代码,判断输出结果
- @Test
- void test05() {
- String s1 = "hello";
- final String s2 = "hello";
- String ss = new String("hello");
- String s3 = "hello2";
- String s4 = s1 + 2; // s1是变量, 变量 + 常量,结果就在堆中
- String s5 = s2 + 2; // s2是常量, 常量 + 常量 = 常量
- String s6 = (s1 + 2).intern(); // 调用intern()方法,返回值就在常量池中
- System.out.println(s1 == s2); // true
- System.out.println(s1 == ss); // false
- System.out.println(s2 == ss); // false
- System.out.println(s3 == s4); // false
- System.out.println(s3 == s5); // true
- System.out.println(s3 == s6); // true
- System.out.println(s3 == getString() + 2); // false
- }
- String getString() {
- return "hello";
- }
字符串拼接时,如何判断拼接后的结果是否相等(==)
结论:
1. 常量与常量的拼接结果在常量池。且常量池中不会存在相同内容的常量。
2. 只要其中有一个是变量,结果就在堆中。编译时,如果结果确定,则会相等
3. 如果拼接的结果调用intern()方法,返回值就在常量池中。原因是拼接产生在堆空间的字符串对象在调用intern()之后,会将常量池中已经存在的字符串常量,赋值给栈中的变量
字符串中的方法请见:Java-Day06 Java中的几个内置类(对象):Math类、Random类、Scanner类、String类(字符串对象)超详细_不会敲代码的HZ的博客-CSDN博客
因为字符串是常量,字符串在大量拼接时,会导致大量副本字符串对象存留在内存中,降低效率。如果这样的操作放到循环中,会极大影响程序的性能。所以Java为解决这一问题,在底层设计了专门解决字符串大量拼接问题的类,StringBuffer和StringBuilder
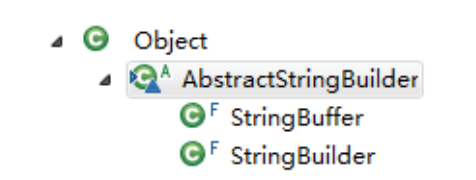
4.2 StringBuffer和StringBuilder
StringBuffer和StringBuilder代表可变的字符序列,在java.lang包下,可以对字符 串内容进行增删,此时不会产生新的对象。很多方法与String相同。作为参数传递时,方法内部可以改变值。
这两个对象都是jdk底层提供用来拼接大量字符串对象的,不会产生产生大量无用常量,替代字符串的大量拼接,提高效率。

继承树:
4.2.1 StringBuffer类
JDK1.0中声明
StringBuffer类不同于String,其对象必须使用构造器生成。有三个构造器:
StringBuffer():初始容量为16的字符串缓冲区
StringBuffer(int size):构造指定容量的字符串缓冲区
StringBuffer(String str):将内容初始化为指定字符串内容
- String s = new String("我喜欢学习");
- StringBuffer buffer = new StringBuffer("我喜欢学习");
- buffer.append("数学");

所有操作方法上加上了同步锁,所以是线程安全的
常用方法:
StringBuffer append(xxx):提供了很多的append()方法,用于进行字符串拼接
StringBuffer delete(int start,int end):删除指定位置的内容
StringBuffer replace(int start, int end, String str):把[start,end)位置替换为str
StringBuffer insert(int offset, xxx):在指定位置插入xxx
StringBuffer reverse() :把当前字符序列逆转
当append和insert时,如果原来value数组长度不够,可扩容。 如上这些方法支持方法链操作。
方法链的原理:

此外,还定义了如下的方法:
- public int indexOf(String str)
- public String substring(int start,int end)
- public int length()
- public char charAt(int n )
- public void setCharAt(int n ,char ch)
4.2.2 StringBuilder类
StringBuilder 和 StringBuffer 非常类似,均代表可变的字符序列,而且提供相关功能的方法也一样。
没有加同步锁,因此非线程安全的!!!
面试题:对比String、StringBuffer、StringBuilder
String(JDK1.0):不可变字符序列
StringBuffer(JDK1.0):可变字符序列、效率低、线程安全
StringBuilder(JDK 5.0):可变字符序列、效率高、线程不安全
注意:作为参数传递的话,方法内部String不会改变其值,StringBuffer和StringBuilder 会改变其值。因为String是常量,而StringBuffer和StringBuilder是对象。
效率:String < StringBuffer < StringBuilder
具体情况需要具体分析,如较少字符串进行拼接时使用String效率更高,多线程时使用StringBuffer
-
-
相关阅读:
风哥PG-DBA培训15:PostgreSQL集群解决方案与流复制项目实战
异常与错误处理高级用法
蓝桥杯算法 一.
这是我见过最牛逼的滑动加载前端框架
日 志
js基础笔记学习199正则表达式简介2
CTFHUB JWT(Json Web Token)
lv3 嵌入式开发-4 linux shell命令(文件搜索、文件处理、压缩)
HT4344 2通道 立体声 DAC转换器的特性
Java程序设计(五)作业
- 原文地址:https://blog.csdn.net/weixin_51612062/article/details/126078025
