-
flink cep
1.cep适合做什么
CEP: Complex Event Processing缩写,复杂事件处理。
CEP是一种事件流上的模式匹配技术,与传统的先存储后查询数据的方式不同:CEP预先设置查询条件,然后让实时数据通过这些查询条件,引擎抓取符合条件的数据,这种查询是连续不断的,连续到达的事件与提前定义好的复杂模式进行匹配,然后输出满足复杂模式的事件。
CEP用于分析低延迟、频繁产生的不同来源的事件流,可以做到感知(实时事件的检测)、分析(聚合各类事件)、响应(更新预期);
2.flink cep基本概念与使用流程:
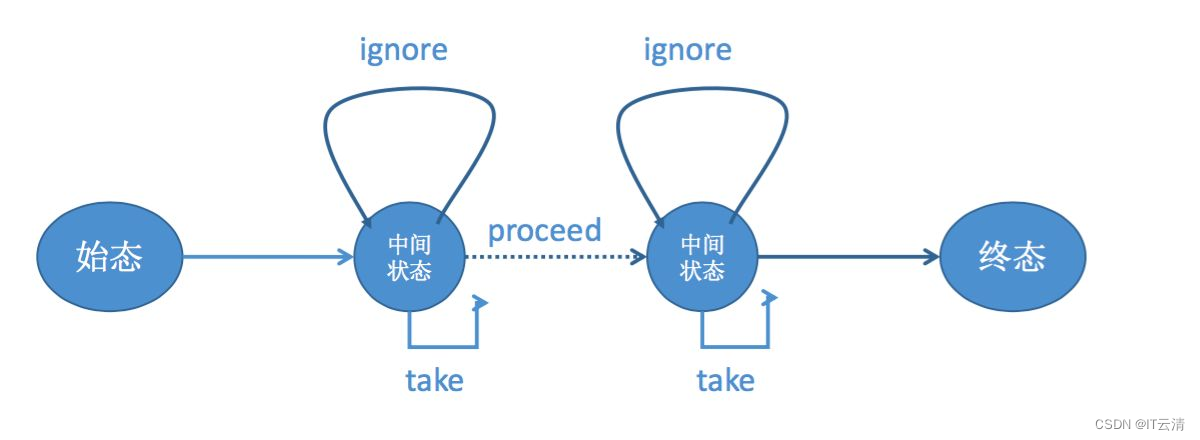
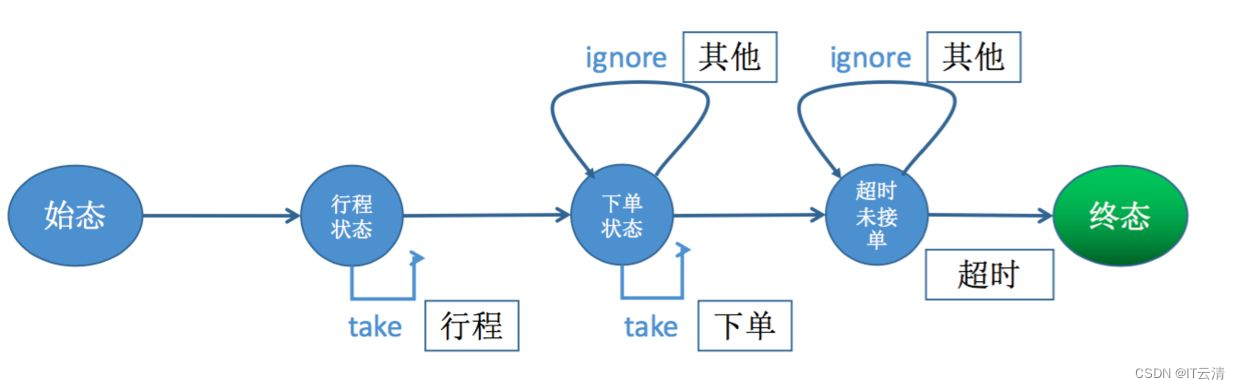
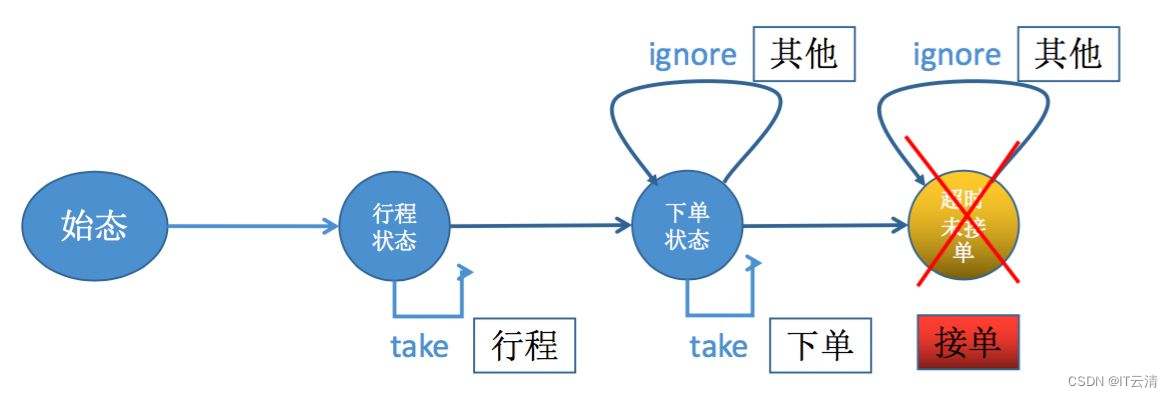
Flink CEP内部是用NFA(非确定有限自动机)来实现的,由点和边组成的一个状态图,以一个初始状态作为起点,经过一系列的中间状态,达到终态。
点分为起始状态、中间状态、最终状态三种,边分为take、ignore、proceed三种。
take:必须存在一个条件判断,当到来的消息满足take边条件判断时,把这个消息放入结果集,将状态转移到下一状态。
ignore:当消息到来时,可以忽略这个消息,将状态自旋在当前不变,是一个自己到自己的状态转移。
proceed:又叫做状态的空转移,当前状态可以不依赖于消息到来而直接转移到下一状态。
flink cep的使用,核心分为2个部分:定义事件模式,匹配结果处理;1.模式pattern
模式可以理解为,事件流中,某个事件具有的某个特征,或者某种行为模式,或者处理事件的规则。
模式定义好后用来提取事件流中符合模式规则的事件序列。当源源不断的事件流经过时,只有符合我们定义的复杂模式的事件,才会被提取处理。
个体模式:一个单独的模式定义,即为一个个体模式。
组合模式:多个个体模式组合起来形成一个组合模式。也叫模式序列;模式序列必须以一个初始序列开始;
模式组:将一个模式序列作为条件嵌套在个体模式里;待定。
个体模式又分为:单例(singleton)模式,循环(looping)模式
单例模式接收单个事件,循环模式可以接收多个事件。
每个模式,可以有一个或者多个条件,模式基于条件接受事件。
2.条件condition
1.个体模式条件
每个模式都要指定触发条件,作为模式是否接受事件进入结果集的判断依据。
当事件进入模式进行匹配时,如果事件不满足当前模式的条件,则事件会被丢弃,否则会加入到当前模式对应的缓存结果集中,或者流入下一个模式,进行后续匹配。
单个模式条件主要通过:.where() .or() .until来指定条件
Pattern<TradeEvent, TradeEvent> pattern = Pattern.<TradeEvent>begin("start") .where(new SimpleCondition<TradeEvent>() { //where 可以有多个,相当于and @Override public boolean filter(TradeEvent tradeEvent) throws Exception { return tradeEvent.getAccountName().equals("张三") ; } }).or(new SimpleCondition<TradeEvent>() { //or @Override public boolean filter(TradeEvent tradeEvent) throws Exception { return tradeEvent.getAccountName().equals("李四"); } }).where(new IterativeCondition<TradeEvent>() { //迭代条件 @Override public boolean filter(TradeEvent tradeEvent, Context<TradeEvent> context) throws Exception { Iterable<TradeEvent> start = context.getEventsForPattern("start"); //能够对模式之前所接受的所有事件进行处理 return tradeEvent.getDealTime().before(new Date(tradeEvent.getOpenDate().getTime() + 30 * ONE_DAY_LONG)); } }).until(new SimpleCondition<TradeEvent>() { //终止条件 @Override public boolean filter(TradeEvent tradeEvent) throws Exception { return tradeEvent.getTradeType().equals("扣息"); } }).within(Time.hours(1));//1小时以内 为模式指定事件约束,在多久内匹配有效。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
2.模式序列条件
模式序列的条件有3种:
严格临近 Strict Contiguity:要求一个event之后必须紧跟下一个符合条件的event,中间不允许有其他事件。对应.next();
宽松临近Relaxed Contiguity:和上一种不同的是,该模式允许中间有其他无关的event,会对他们进行忽略。对应.followedBy();
非确定性宽松临近 Non-Deterministic Relaxed Contiguity:非确定性宽松连续性,可以对已经匹配的事件就行忽略,对接下来的事件继续匹配。对应.followedByAny()
3.匹配之后的跳过策略
在给定的pattern中,当同一事件符合多种模式条件组合之后,需要执行AfterMatchSkipStrategy来确定到底输出哪种匹配。主要有4中策略:1 NO_SKIP 输出所有可能匹配的事件进行输出,不忽略任何一条
2 SKIP_PAST_LAST_EVENT. 忽略开始触发到当前触发pattern的所有部分匹配。只保留最近的匹配
3 SKIP_TO_FIRST[patternName]。忽略第一个匹配指定patternName的pattern之前的所有部分匹配。保留第一个匹配 和 第一个能够匹配patternName之后的所有匹配,
4 SKIP_TO_LAST[patternName]。忽略第一个匹配和 最后一个匹配PatternName 之间的所有部分匹配。 保留第一个匹配 和最后一个能匹配PatternName的匹配,只保留2个
5 SKIP_TO_NEXT. 忽略所有部分和第一个匹配有同样开始的匹配。保留第一个匹配,以后后面不和第一个匹配有同样开始的匹配
3.模式检测
当定义好模式和事件流后,指定输入流和模式,当有事件到达时,即可开始匹配。
PatternStream<TradeEvent> patternStream = CEP.pattern(source, pattern);//给定的输入流指定模式- 1
4.匹配事件提取
创建了PatternStream后,就可以从符合模式序列的事件序列中提取事件了。
SingleOutputStreamOperator<Object> process = patternStream.process(new PatternProcessFunction<TradeEvent, Object>() { @Override public void processMatch(Map<String, List<TradeEvent>> map, Context context, Collector<Object> collector) throws Exception { for (Map.Entry<String, List<TradeEvent>> entry : map.entrySet()) { //key是模式的名称,value是此模式下接收的所有的事件 logger.info("##########结果为 key={},value={}",entry.getKey(),entry.getValue().toString()); } } });- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
由于模式中可以指定超时时间,部分事件序列可能会因为超过时间窗口长度而被丢弃。这一部分根据具体业务可能还需要指定超时时间处理程序。
5.案例
1.事件序列
new TradeEvent(2,"张三","一类账户","充值",40.00,openDate1,dateFormat.parse("2022-04-04 12:03:00")), new TradeEvent(3,"张三","一类账户","购买",30.00,openDate1,dateFormat.parse("2022-04-04 12:04:00")), new TradeEvent(6,"李四","一类账户","登陆",0.00,openDate1,dateFormat.parse("2022-04-04 13:00:00")), new TradeEvent(7,"李四","一类账户","充值",40.00,openDate1,dateFormat.parse("2022-04-04 13:02:00")), new TradeEvent(8,"李四","一类账户","充值",21.00,openDate1,dateFormat.parse("2022-04-04 13:03:00")), new TradeEvent(9,"王二","一类账户","充值",60.00,openDate1,dateFormat.parse("2022-04-04 13:03:00")), new TradeEvent(10,"王二","一类账户","购买",60.00,openDate1,dateFormat.parse("2022-04-04 13:03:00")), new TradeEvent(11,"李四","一类账户","购买",30.00,openDate1,dateFormat.parse("2022-04-04 13:04:00")), new TradeEvent(12,"李四","一类账户","送礼",30.00,openDate1,dateFormat.parse("2022-04-04 13:06:00")), new TradeEvent(13,"李四","一类账户","送礼",10.00,openDate1,dateFormat.parse("2022-04-04 13:08:00")), new TradeEvent(4,"张三","一类账户","送礼",30.00,openDate1,dateFormat.parse("2022-04-04 12:06:00")), new TradeEvent(5,"张三","一类账户","送礼",10.00,openDate1,dateFormat.parse("2022-04-04 12:08:00")), new TradeEvent(14,"张三","一类账户","退出",0.00,openDate1,dateFormat.parse("2022-04-04 12:10:00"))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2.基础配置
//账户在登录后,马上进行充值(5分钟),充值后立马买礼物(5分钟),买完立即送人(5分钟),且充值金额与送礼金额接近。 DataStream<TradeEvent> source = env.fromElements(eventList) .assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<TradeEvent>(Time.milliseconds(500L)) { @Override public long extractTimestamp(TradeEvent payEvent) { //时间戳,这里选择了TradeEvent对象内部的时间字段,则状态机接收事件时,时间的先后顺序以TradeEvent中的dealTime判断 return payEvent.getDealTime().getTime(); } }).keyBy(new KeySelector<TradeEvent, Object>() { @Override public Object getKey(TradeEvent value) throws Exception { //用accountName分区 每个accountName都会有一个自己的NFA实例 return value.getAccountName(); } });- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3.模式定义
登陆->充值->购买->送礼 松散匹配,忽略之间不符合的事件。
超时之前/完全匹配之前,符合部分条件的数据,会常驻状态的结果集中(内存)。直到超时或者序列满足,才会被拿出处理/清理;
private static Pattern<TradeEvent, TradeEvent> getPattern() { Pattern<TradeEvent, TradeEvent> pattern = Pattern.<TradeEvent>begin("登陆").where(new SimpleCondition<TradeEvent>() { @Override public boolean filter(TradeEvent tradeEvent) throws Exception { return tradeEvent.getTradeType().equals("登陆") ; } }).followedBy("充值").where(new SimpleCondition<TradeEvent>() { @Override public boolean filter(TradeEvent tradeEvent) throws Exception { return tradeEvent.getTradeType().equals("充值"); } }).followedBy("购买").where(new SimpleCondition<TradeEvent>() { @Override public boolean filter(TradeEvent tradeEvent) throws Exception { return tradeEvent.getTradeType().equals("购买"); } }).followedBy("送礼1").where(new SimpleCondition<TradeEvent>() { @Override public boolean filter(TradeEvent tradeEvent) throws Exception { return tradeEvent.getTradeType().equals("送礼"); } }).followedBy("送礼2").where(new IterativeCondition<TradeEvent>(){ @Override public boolean filter(TradeEvent value, Context<TradeEvent> ctx) throws Exception { Iterable<TradeEvent> charge = ctx.getEventsForPattern("充值"); //关联处理 可以获取充值阶段的数据 return false; } }).times(1).within(Time.minutes(7)); return pattern; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
4.结果处理
1.打印出符合模式的事件序列中送礼的详细数据;
2.组装简单指标数据存储
SingleOutputStreamOperator<Object> outputStreamOperator = patternStream.process(new PatternProcessFunction<TradeEvent, Object>() { /** * 结果集数据获取 * @param match * @param ctx * @param out * @throws Exception */ @Override public void processMatch(Map<String, List<TradeEvent>> match, Context ctx, Collector<Object> out) throws Exception { //把符合模式序列的结果集中,送礼模式的结果集打印出来 List<TradeEvent> songli = match.get("送礼"); logger.info("##########送礼结果为:{}", songli.toString()); songli.stream().forEach(event -> insertIndex(event.getAccountName()+"_登陆_充值_送礼_5min内",1)); logger.info("--------------------\r\r\r"); } }); env.execute("execute"); System.out.println("==============================="); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
2022-04-26 17:58:19.573 INFO --- [pOperator (1/1)] com.java4all.mycep.pattern.BasicPattern : ##########送礼结果为:[TradeEvent{id=4, accountName='张三', accountType='一类账户', tradeType='送礼', tradeMoney=30.0, openDate=Fri Jan 01 00:00:00 CST 2021, dealTime=Mon Apr 04 00:06:00 CST 2022}] 2022-04-26 17:58:19.583 INFO --- [pOperator (1/1)] com.java4all.mycep.pattern.BasicPattern : 写入指标:key=张三_登陆_充值_送礼_5min内,value=1 2022-04-26 17:58:19.587 INFO --- [pOperator (1/1)] com.java4all.mycep.pattern.BasicPattern : ##########送礼结果为:[TradeEvent{id=12, accountName='李四', accountType='一类账户', tradeType='送礼', tradeMoney=30.0, openDate=Fri Jan 01 00:00:00 CST 2021, dealTime=Mon Apr 04 13:06:00 CST 2022}] 2022-04-26 17:58:19.588 INFO --- [pOperator (1/1)] com.java4all.mycep.pattern.BasicPattern : 写入指标:key=李四_登陆_充值_送礼_5min内,value=1- 1
- 2
- 3
- 4
- 5
6.状态的结果集
NFA运行时,状态数据是保存在内存中的,通过内存队列存放半匹配和已匹配数据。源码如下,目前,未发现支持对接外部存储的拓展方式。
由于数据较多时,可能内存数据集较大,flinkcep 基于论文实现了一套数据结构。

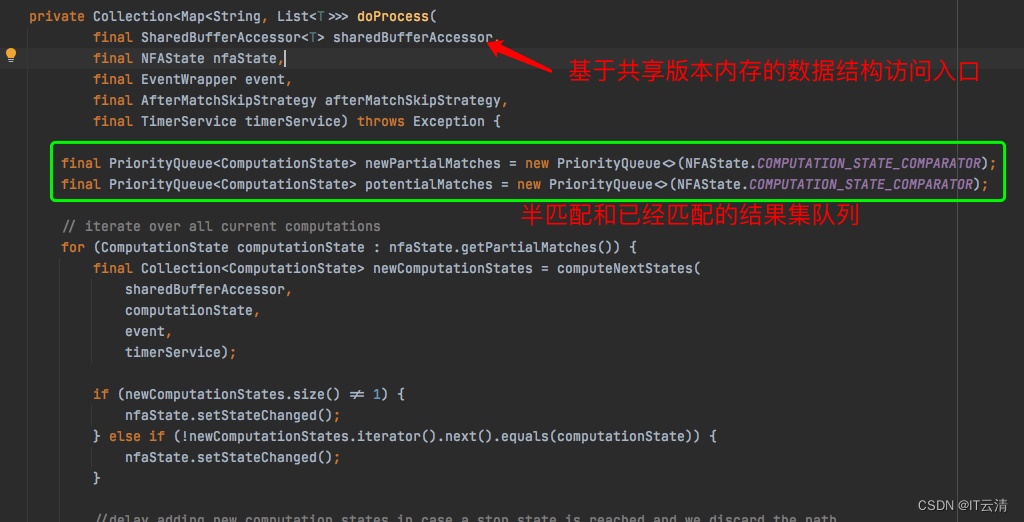
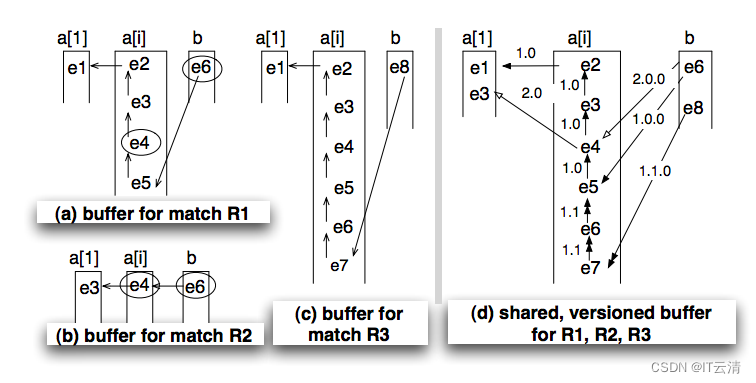
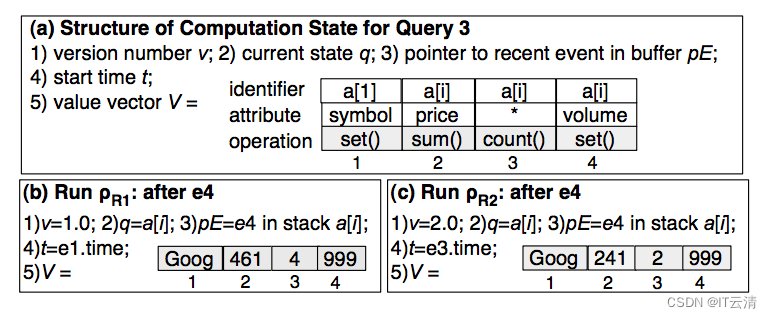
其中图a、b、c是原始的R1、R2、R3缓存,图d则是整合在一起的共享版本缓存。它会将所有序列的前向指针附加上一个版本号(采用杜威十进制法,点号分隔),并且遵循以下两个规则:
迁移到下一个状态时,版本号增加一位,如a[1]状态的版本号是1(为了符合习惯写作1.0),a[i]状态的版本号是1.0、1.1,b状态的版本号是1.0.0、1.1.0……以此类推;
当序列发生分裂时,处于当前状态的版本号位加1。例如e3事件产生了2.0版本,e6事件产生了1.1版本。
依照这种规则,就可以根据前向指针上版本号的递增规律和前缀来回溯出正确的序列了。Flink CEP中将此缓存设计为SharedBuffer类,但是版本的设计有些不同。
7.总结:
优点:
1.模式定义较为灵活,丰富的java api,方便开发;
2.量词,组合模式,连续策略,跳过策略等语义支持丰富;
缺点:
1.一个模式中不支持多个不同的时间窗口;
2.由于状态的结果集在内存中,难以支持超长时间窗口数据处理;
3.对标准的事件序列数据处理较好,其他回溯统计类难以处理;
4.无不发生算子;
5.新增模式困难;需要自研某种机制;
-
相关阅读:
DataWhale - 吃瓜教程学习笔记(一)
【高项笔记】No.2 网络和网络协议
力扣练习——67 森林中的兔子
Go 学习笔记(89) — 接口类型变量的等值比较操作(nil 接口变量、空接口类型变量、非空接口类型变量)
Ubuntu22.04 安装Mongodb提示dpkg-deb: 错误
超简单的vue实现生成二维码并下载为图片(可直接复制使用)
Spark SQL 的总体工作流程
Vue组件和Vue脚手架
算法笔记(二)
ROS 话题通信理论模型
- 原文地址:https://blog.csdn.net/weixin_39800144/article/details/126184600