-
java源码系列:HashMap源码验证,自己写的HashMap性能高吗?为什么在JDK8中新增红黑树?
自己手写一个HashMap,测试10亿数据
已经用源码给大家进行实现,好,那现在呢,我有一个问题,那我们既然已经把这个代码实现了,
那同学们我想问一下,我们写的这个HashMap代码跟java提供的那个HashMap,
你觉得哪一个HashMap的性能更好呢?
来我在这里呢,我给大家测试一下啊,看一下咱们这个代码到底OK不OK? 到底管不管用?
有很多同学说我这个性能一定很慢,其实也不会很慢,那这里呢,
我就把它定义为10亿的数据循环,太多臣妾受不了,这么多0对吧,臣妾就来这么多,
好,我们看一下咱们这10亿的数据能不能运行成功?

我们象征性的跑 1百万数据就行啦。在整个的过程中杠杠的数据,没有任何问题,对不对?
这个数据正常运行,是完全没有问题的!但确实啊,我承认我们的这个代码呢,
确实是没有java提供的那个HashMap,性能那么高,那原因你们知道是为什么吗?
自己写的HashMap跟java提供的HashMap,哪个性能高?
来,我们不用循环这么多,我只要在这个地方,我把这个map输出来给你看一下,
你就知道,我在这里给个1000,我在这里设置个断点,我给你看一下这个HashMap,
你就明白为什么,这是我们今天的一个高潮的部分,大家一定要注意这个
咱们 debug 运行,运行到断点位置,然后右键 Evaluate Expression
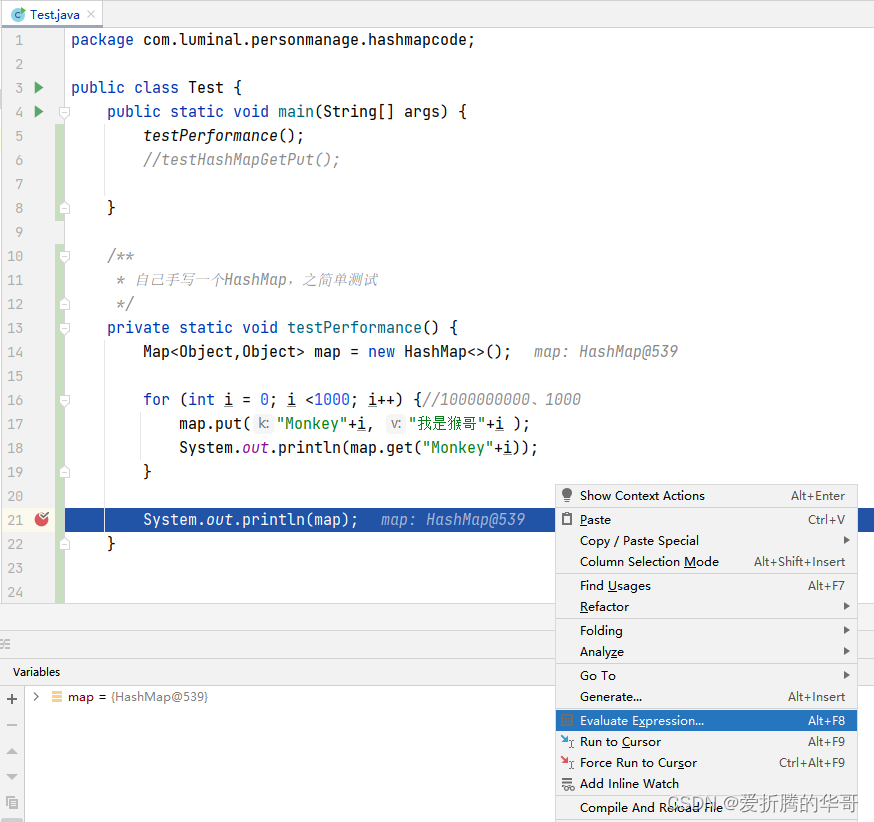
输入 map,我们可以看到 map 的存储值(当然我们在控制台也是可以看到的)
我们发现,table 里面只有16条数据,而我们存储输出的map,明明有1000条数据,
我们点进去看,会发现1000条数据,其实都存储了,它都存储在我们的 链表next域 上面,
那我们知道,我们链表有什么特点?查询慢,插入删除快
它需要从头节点开始依次去查询,如果我们这个链表长度比较长,会非常的耗时耗性能!
链表有关介绍详细可参考:
java源码系列:链表是什么?数组和它有何不同?(2022-07-28更新完毕)

我们想象一下,如果我们的链表都这么长,如果我们要去查找的是最后这个元素,
但是呢,我们要都是要从第一个元素来进行查找,那么你们想象一下,
这样的一个性能是不是非常下降非常明显,
所以也就是我们写的这个代码,插入是没有问题的,但是呢,它的这个查询有很大的问题!
如果大家不能理解链表它为什么会这么慢?
来,我在这里给大家去看一下,这就是一个线性链表的一个结构,你看从001到007,
那我现在在这里的,就是我有7个元素对吧,那现在同学们我要去查第7个元素,
同学们你们说我要查多少次?查7次
如下图,查看链表查询演示:
看一次,两次,三次,四次,五次,六次和七次。

那我们可以发现我们这个链表它什么,我们只有七个节点需要查七次,
那同样我们想象一下,如果我这个节点它的这个数据是70万,那我就要查70万的数据。
对不对?那我们可以发现这个链表它永远都是查询效率非常慢。
也就说我们这个链表的慢的原因是:因为我们这个链表的数据过长。
如果假设我们现在只有两到三个数据的话,那我们可以发现他查询会很快,
原因就在这里,大家这个应该能理解。
如上图,是不平衡的二叉树,其实它也是一个线性链表。
这个是可以在线给大家进行演示的,更多数据结构在线演示,如红黑树等等,
可进入下面的网址。
数据结构可视化网址
这个链表它查询会非常慢,所以在JDK8之后为什么用红黑树的原因,
大家应该清楚了吧,就是因为我们链表,查询会非常慢,它的效率会比较低。
你就用这几个字回答面试官就可以了,在JDK8之后为什么用红黑树的原因?
因为链表的查询比较慢。
如果你要详细的,给大家来讲解的话,就是因为我们插入的链表过长之后,
我们的链表都是从头部开始进行查询,所以它会比较慢。
-
相关阅读:
typename关键字详解(消除歧义)
MoneyPrinterPlus:AI自动短视频生成工具,详细使用教程
一个关于 i++ 和 ++i 的面试题打趴了所有人
SharePoint 非365版本接入简要笔记
中华传统文化题材网页设计主题:基于HTML+CSS设计放飞青春梦想网页【学生网页设计作业源码】
关于安卓SVGA浅尝(一)svgaplayer库的使用
在Android studio上开发APP之后,找不到应用图标,但是手机管家显示已经安装
精心整理了超详细的Linux入门笔记,零基础也能看懂,一学就会
查看、关闭端口命令
使用命令行cli脚手架创建uniapp项目(微信小程序、H5、APP)
- 原文地址:https://blog.csdn.net/YuDBL/article/details/126178223