-
重读GPDB 和 TiDB 论文引发的 HTAP 数据库再思考
为什么要再思考?
大家好,我是阿福,之前我在社区 Paper Reading 活动中分享了 Greenplum 团队在 2021年 SIGMOD 上发表的论文:《Greenplum: A Hybrid Database for Transactional and Analytical Workloads》。

该篇论文,针对传统分析型数据库产品(OLAP RDBMS)Greenplum,通过解决一系列 TP 场景下的高代价计算问题,比如“分布式锁问题”、“资源隔离问题”、“两阶段提交代价过高问题”,来实现一款以 OLAP 能力为主,兼顾 OLTP 场景的 HTAP 数据库。整体来说团队的思路是尽量降低分布式环境下分析型场景对事务型场景的影响,分配出可用资源应对一些事务处理场景。经过一系列的改进,从下面两张对比测试图上也可以看出,GPDB 6 相对于 GPDB 5 还是在混合事务和更新场景下还是有了很大的性能提升。

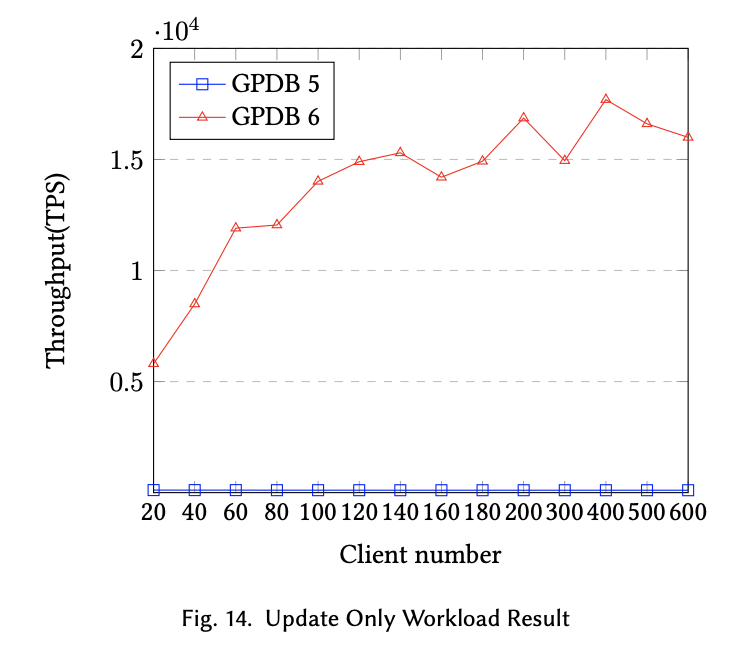
在 HTAP 的赛道上,
-
除了 Greenplum 等传统分析型数据库产品向 HTAP 的演进外
-
也有类似 TiDB 从 NewSQL 的高 TP 支持场景向 HTAP 的演进,
在同一赛道上也有
-
TP/AP 分而治之
-
TP+AP 统一处理
的不同处理方案。实现方法有很多,孰优孰劣也是各家众说纷纭。

莎士比亚说:一千个读者就有一千个哈姆雷特。我不是什么意见领袖,我的观点可能不一定对,但是一定能产生共鸣。自从上次做完分享后,我也收到了一些朋友的反馈,包括时间较短感觉分享的内容不够精彩,没有一些生动的例子只是干唠嗑感觉学习到的内容了了。总的来说,可能还是我的水平有限,对 HTAP 的理解也不够深入,但是不要紧,我们不是还有时间和机会吗?所以我最近又在仔细研读 TiDB 的论文 《TiDB: A Raft-based HTAP Database》,空余时间也有看到圈里大家针对 HTAP 的不同理解,我希望能够有机会再跟大家分享一下我对这两种不同的 HTAP 演进方式的理解,无论是 TiDB 还是 GP,都是很好的产品,希望大家也都能用的开心。

我想分享的观点
如果大家对 TiDB 的论文还没有详细的读过,可以参考以下内容补补课:
从我的观点出发,我主要想从以下几个方面进行分享。
1. TiDB 架构方面的思考
架构方面来说,因为 TiDB 出生解决的主要是单机数据库(OLTP)遇到的一些问题,所以从设计方面考虑的话,整体是高并发和分布式扩展能力的支持。不像 Greenplum 专门为分析而生的,并不能支持到高并发。所以大家其实面临的问题是不一样的,比如:
1)处理 HTAP 的整体思路不同
Greenplum 属于改造当前存储引擎,实际上 GP 在设计之初已经考虑了分析型场景中的一些频繁更新和频繁删除掉的场景,所以一直保留有 HEAP 和 AO 两种表,但是开始的 HEAP 表的锁机制、资源隔离是不太友好的;当前向 HTAP 的进化,多是针对堆表的优化,以解决原来堆表上对 TP 支持不太好的一些问题。经过优化后的 GPDB 6 在数据库模型设计时,仍然要求大家提前做好规划,分析型场景下,还是使用 AO 表列存压缩的效率更好,事务型场景下推荐使用堆表;那么同时也会产生一些问题,最主要的就是,同一张表,并不能同时提供最好的 TP 和 AP 能力(相对于 AO 表来说),以下是一张分区表 ‘SALES’ 的多分区模型,虽然使用了多种存储技术,但针对同样的数据,仍然只有一种存储格式。也许有人会说真正的数据也是分热度的,热数据可以使用 HEAP、温数据可以使用 AO、冷数据可以放到 HDFS,这也是以前我们经常会引导客户去采用的处理方式,对于这种数据的划分方式,数据库本身是没有控制能力的,需要业务规则的入侵,这也是需要大家在做产品选型时需要注意的地方。

TiDB 属于在原有架构中新增一个分析型存储引擎 TiFlash,由于基于 RocksDB 的 TiKV 本身已经在多年发展中经过了验证,能够很好的承担事务型场景,所以现在要做的就是在现有架构稳定的基础上,扩展 OLAP 的能力。此时,团队仍然采用与 TiKV 一样的思路,复用了另一款在分析领域的黑马软件 ClickHouse 的能力,而没有去重复造轮子。CK 的话,我们这里就不重复讨论了,网上很多文章都有介绍,在单表分析场景下,能够秒杀各大传统分析引擎。团队这样做的好处也显而易见,在保持整体架构完整性和稳定性的前提下,复用经过行业验证的成熟产品,对于产品化和迭代都是友好的;另外架构上可以灵活的选择是否增加 TiFlash。 当然也会引入一些别的问题,我认为这里面最主要的问题有两点:一是在 TiDB Server 层如何有效的处理和分发 TP 和 AP 查询;二是在存储层引入了多一份列存储数据冗余的代价,数据冗余问题也是产品选型时需要着重关注的点。

简单总结:不同的架构,促使大家尝试不同的处理思路,对比来看,能说谁更好吗?我说不好,留给大家自行评判。我个人认为业务痛点不一样,产品选型就不一样,没有一款产品可以把 TP 和 AP 都做到极致,只能说大家更侧重于哪一方面。
2)副本处理方式的不同
下面的这些观点,都是整体下的细节讨论了,比如这个点我们要谈副本处理方式。
GP 采用的是 PostgreSQL 最朴素的基于 WAL 日志同步的方式,将日志同步写出一份到镜像节点,形成一份 Mirror 数据,Mirror 数据是热备,不能提供只读能力;这样看的话,所有的读写请求,都只能在主副本上进行,压力还是蛮大的,所以做 HTAP 过程中,当前精力还是放在如何减少锁争用问题、如何将两阶段提交降级为一阶段提交,以期减少 TP 事务执行的代价。当然,后面在新版本计划中,会放出 WAL 日志同步的接口,这样也能实现多副本,通过这种方式,可以拆分读请求到另一套集群(配合应用读写分离)。
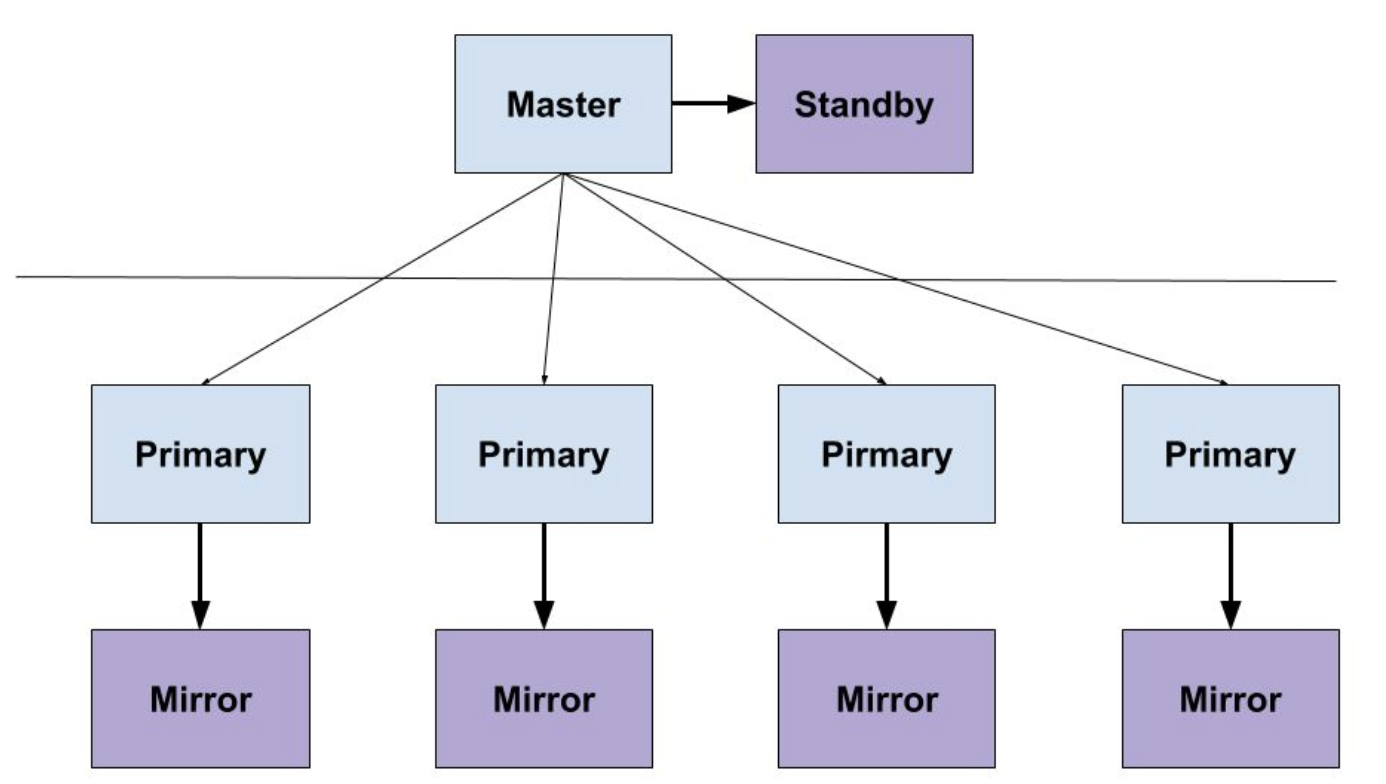
TiDB 采用的是 Raft 共识协议,要达到共识,最低就要 3 副本, TiDB 的这种整体架构,是可以做到灵活的读写分离的;并且也很容易实现多中心部署和容灾,相对来说对 HTAP 还是要友好一些;如果想要支持分析场景,再增加 TiFlash,那就是 4 个副本,因为 TiFlash 只能以 Learner 的角色加入,另外列存引擎会引入一些数据同步和行列转换的代价问题,这些问题在论文中也都有提到如何去解决,大家可以详细看一看。

简单总结:不同架构引出不同副本处理方式,其实本身走的不是一个路子,也没必要强拉硬拽的去联系和对比,大家只要明白各自的出发点不一样即可。3)SQL 处理方式的不同
在这个点上,其实 GP 没有什么可讨论的,因为本身一条 SQL 从 Master 节点进来,针对某个表只有一条存储的路可走,简单说表建成什么样,就怎样去查。
但是 TiDB 这边就有意思了,开启 TiFlash 的前提下,一条 SQL 从 TiDB 进来,是要先判断一下走哪条路更合适的,是 TiKV 还是 TiFlash ?这个问题上面也有提到,会引入一个不确定因素,就是代价判断不合理,走错了路导致查询效率变低,比如本来应该是偏分析的场景,偏偏走了 TiKV。但是 TiDB 论文中也特别介绍了他们在优化器上所作的工作,同时引入了 RBO 和 CBO,基于自身的架构逻辑做了很多 Rules 等等,以更合理的引导优化器去找到最合理的路径。大家可以到论文的 5.2 章节去详细了解一下。

简单总结:我记得很久之前给客户做架构建议时提到过一个方案,采用 PG + GP 的方式分别支持 TP + AP 场景,这里面最难的不就是前端 SQL 的转发和后端数据的同步,现在回看 TiDB 这篇论文的 HTAP 实现,结合上面第2点提到的副本处理方式的不同和本观点,我感觉 TiDB 的 HTAP 探索其实也是一种水到渠成、自然而然的事,后面要做的,可能就是产品更精细化的打磨了。
2. 一些不同场景下的代价问题
在第一点中,简单提了一下资源使用和代价的问题。这里单独拎出来跟大家讨论一下。还是那个观点:并不存在一款数据库 TP 和 AP 都能做到极致,诚如 Oracle 这么强大,在大数据量的 AP 处理场景下,都不是 GP 的对手;MySQL 简单易用到小学生都会用,还不是需要 TiDB 来解决扩展性难题?
在 TiDB 言 TiDB,通过 TiDB 的论文,我们可以考虑以下几个问题:
1)对存储容量的牺牲,值不值得?
上来我们就直奔主题,1份数据有4个副本,能不能接受?
我在无数个项目中,已经被客户问到过一个问题:
-
Greenplum 是几副本?
-
为什么不能提供三副本?
-
Hadoop 多少年前都是三副本,这很难吗?
如果我愿意抬杠,我会直接告诉客户,一个实时分析的系统要三副本干什么?难道主副本挂了不赶紧修,还要等到镜像也挂掉吗?
当然,我这里列举上面的几个问题是想说明,现在多副本已经不是什么新鲜事了,很多人都能接受。所以如果更看重 TP 和 AP 的强隔离(这里指 TiKV 和 TiFlash 存储引擎分别部署在不同的硬件上,互不干扰),更看重容错和多中心特性。牺牲一些存储容量是值得的。下图是在混合事务场景下,与专门的分析型数据库的简单对比(TiSpark),性能上很值得肯定。
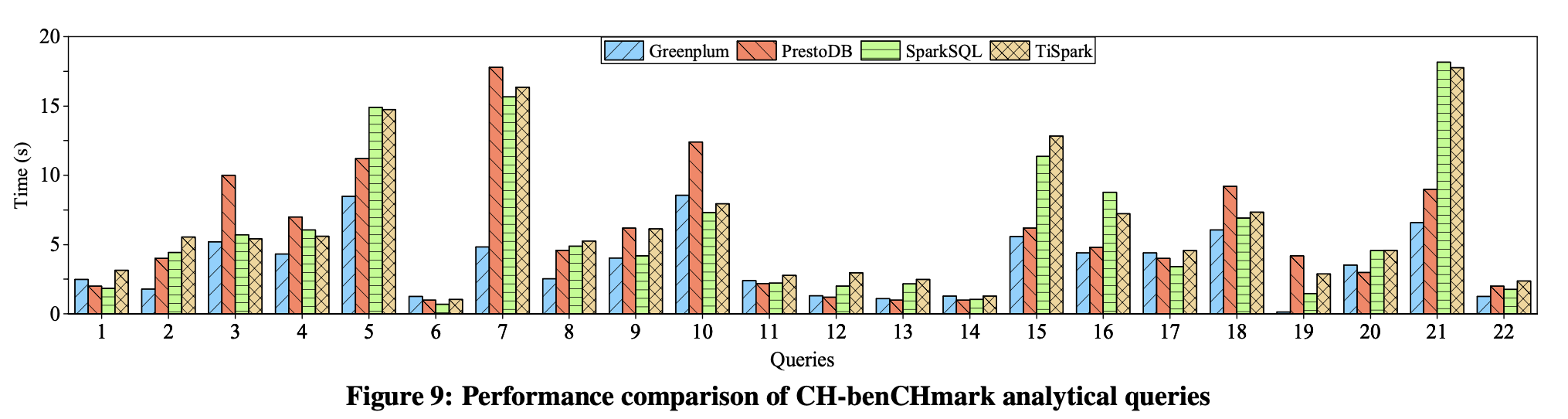

2)错误的执行计划,会带来什么伤害?
这个问题还是引发自一些生产上遇到问题的思考,现有的优化器如果生成了错误的执行计划,导致走了错误的引擎怎么办?一个分析型的查询,走了 TiKV,影响到了现有的 TP 业务怎么办?会不会把集群拖垮?相信大家也都有这样的担心吧,尤其是在一些关键业务场景下,没有人愿意接受这种情况发生。
从 TiDB 的角度出发,这个问题好就好在是 TiDB 在做,而不是什么不知名的小公司。从社区开放性、参与性上来说,TiDB 做的都不错,这个大家应该都认可。带来的好处就是:经过了无数的经验积累和生产验证,错误发生的概率就会小很多,问题的修复也会快很多。也有很多手段可以去干预错误,比如主动增加 HINT,增加熔断参数等等,尽量减小问题出现时对整体业务的影响。
大家眼中的 HTAP
最后一节,留给自己,感谢大家耐心看完我的帖子和观点。我的观点可能受限于知识面,讲的有些片面。
送给大家,如果您对 HTAP 或 GP 或 TiDB 还有什么想法,欢迎关注后期的分享,大家一起来聊聊自己眼中的 HTAP。
-
-
相关阅读:
SLAM第11讲
【C++】泛型编程 ③ ( 函数模板 与 普通函数 调用规则 | 类型匹配 | 显式指定函数模板泛型类型 )
现在的发票有发票专用章吗?如何验证发票真伪?百望云为您详解!
技术选型思考:分库分表和分布式DB(TiDB/OceanBase) 的权衡与抉择
养老服务系统设计与实现-计算机毕业设计源码+LW文档
JNI的介绍
秒懂数据结构之Map _ Set ,竟如此简单
空运知识之常用空运名词
malloc如何分配内存
角速度变化时四元数和旋转矩阵微分方程的证明
- 原文地址:https://blog.csdn.net/chrisy521/article/details/126179200