-
带你了解数据分布式存储原理
数据分布式存储原理,数据分布式规则?就这?怎么就数据分布式了。现在我们把MDC对应OSD数量生成的数据分布式规则交给VBS模块。
VBS是安装在用户系统中的一个代理,当用户需要存放数据在分布式存储中时,VBS会先接收用户的数据,然后对用户数据进行切块分区(一般会把数据分成1MB大小的数据分片。
例如一个1GB的视频文件需要存放在分布式存储中,则会被VBS接收后分割为1024个1MB大小的数据分片),接着对每个数据分片带有的SCSI标识进行格式转化,使之成为分布式存储系统使用的Key标识。然后对key进行哈希计算,算出每个数据分片的哈希值。
可以这样理解,其实每个数据在操作系统下发存储的时候都会带着一个介绍信(SCSI标识),操作系统告诉数据拿着这个介绍信去找大V哥开房间存放数据。
分布式存储的VBS模块就是这个大V哥,当大V哥看到这个介绍信(SCSI标识)后就告诉数据,你的这个介绍信(SCSI标识)现在用不了了,必须重新登记一下,然后VBS就根据介绍信(SCSI标识)又开了一张票(Key)给数据,然后数据拿着这张票(Key)去找大V哥的小弟,小弟就根据票(key)来分配房卡(key带入哈希函数进行计算算出哈希值),开房间存放数据(如图)。

(图 数据分片逻辑图)
数据被VBS接收后,最终数据会变成多个1MB的小数据分片,并且每一个1MB的小数据块都会带着最终的哈希值 。哈希值可以在0-232之间取整,很巧的是,MDC生成的哈希路由圆环也刚好是232份个分区,那么哈希值取整是多少,该1MB数据分片就归属于哪一个分区。
由于MDC通过对应OSD和哈希路由圆环的分区生成了一个分区对应磁盘的关系(数据分布式规则),那么最终这个数据就存放在该分区对应的磁盘中,该磁盘的OSD会将数据持久化存放在磁盘介质中。(如图)若上文假设中提到分区1-分区3对应OSD1,刚好现在有一个数据分片对应的哈希值取整后为3,则该1MB数据归属在分区3,分区3对应OSD1,则由OSD1将该1MB数据存放到该OSD对应的磁盘中,完成数据落盘。
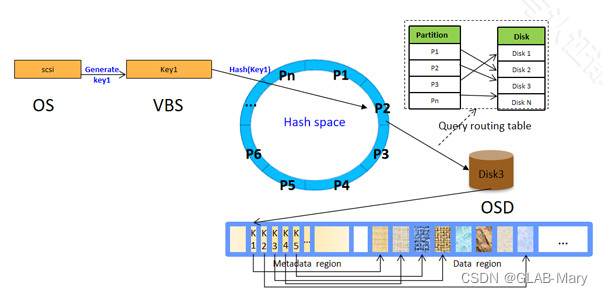
(图 哈希全流程图)
由于哈希路由圆环所生成的分区是均分对应到OSD上的,所以当大量数据存储时,由于概率,最终数据基本会均分到各个OSD对应的磁盘中存放起来。所有磁盘是并发工作的,都可以接收数据就等同于所有磁盘对应所在的服务器都是并发且相对均衡地接收数据,最终完成数据的分布式存储。
-
相关阅读:
云计算基础知识
python爬虫 - 爬取html中的script数据(zum.com新闻信息 )
为什么重写 equals() 就一定要重写 hashCode() 方法
RabbitMQ工作方式
什么是 JVM ?
Elasticsearch搜索功能的实现(五)-- 实战
java-php-python-ssm学校旧书交易网站计算机毕业设计
【自考必看】你能学会的《信息资源管理》,计算机科学与基础(本科)
动态规划思想
网络电视机顶盒怎么样?内行揭晓网络电视机顶盒排名
- 原文地址:https://blog.csdn.net/mengmeng_921/article/details/126158761