-
python爬虫 - 爬取html中的script数据(zum.com新闻信息 )
1. 分析页面内容数据格式
(1)打开 https://zum.com/
(2)按F12(或 在网页上右键 --> 检查(Inspect))
(3)找到网页上的Network(网络)部分
(4)鼠标点击网页页面,按 Ctrl + R 刷新网页页面,可以看到 NetWork(网络)部分会刷新出很多的网络信息
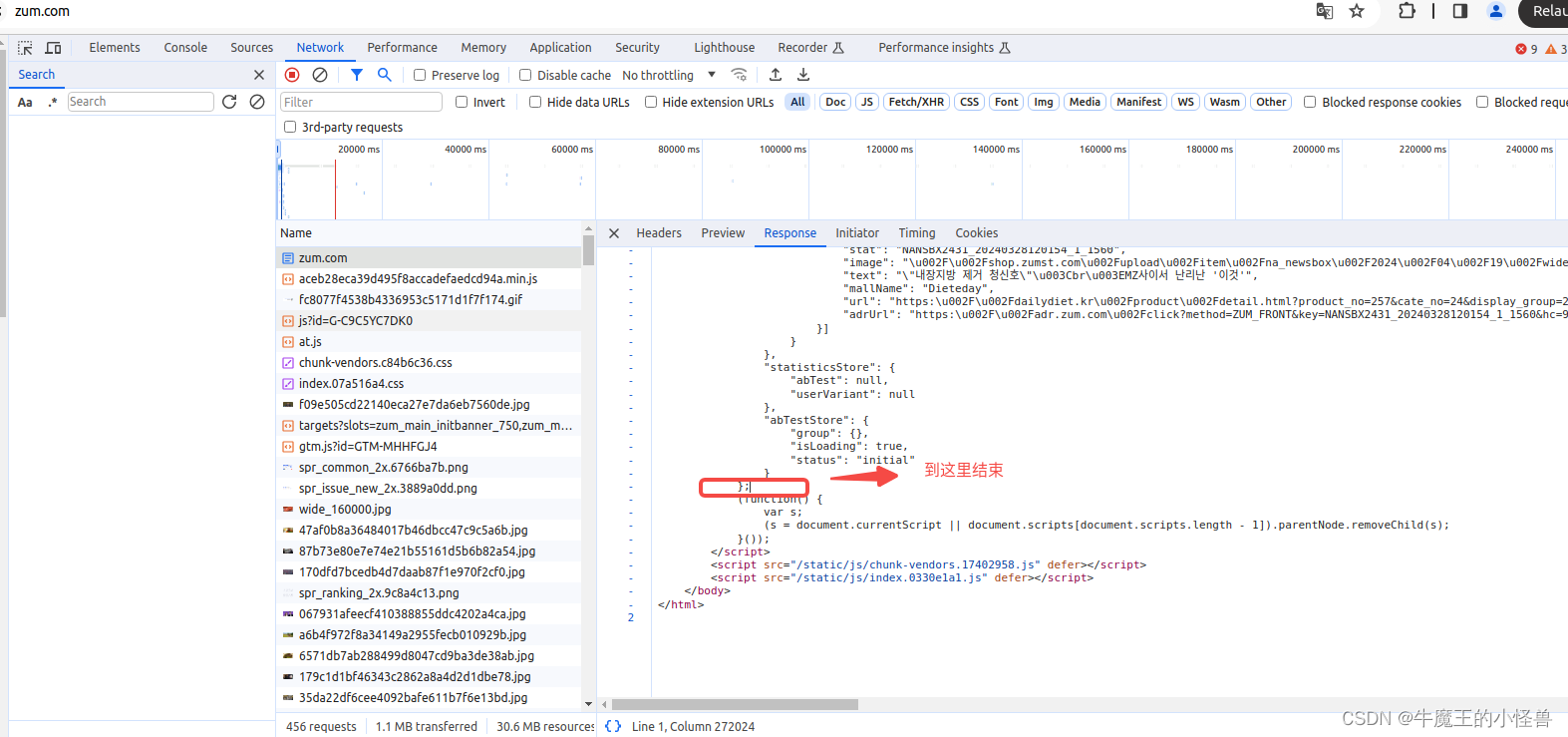
(5)在Name 列,找到 zum.com 条目,右侧自动显示网页的相关内容:Headers, Preview, Response … …
(6)分析Response内容,所需要关心的内容,位于整个html页面的下面

2. 使用re.findall方法,编写爬虫代码
要点:从window.INITIAL_STATE=到;之间的数据都是json数据。 json.loads会自动将false转为False, true转为True
import re import requests import json url = "https://zum.com/" response = requests.get(url) str1 = response.content.decode() result = re.findall(r"window\.__INITIAL_STATE__=(.*?}});", str1) json_result = json.loads(result[0]) print(f"json_result = [{json_result}]") print(f'data.fetchedCommonResponse = {json_result["fetchedCommonResponse"]}') print(f'data.isDarkTheme = {json_result["isDarkTheme"]}') for item in json_result["headerStore"]["gnb"]["gnbItems"]: print(f'idx = {item["idx"]}, ' f'title = {item["title"]} ')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
运行结果:


使用工具格式化后数据内容:

3. 使用re.search 方法,编写爬虫代码
要点:从window.INITIAL_STATE=到;之间的数据都是json数据。 json.loads会自动将false转为False, true转为True
import re import json import requests url = "https://zum.com/" html_doc = requests.get(url).text data = re.search(r"window\.__INITIAL_STATE__=(.*?}});", html_doc) print(f"data = {data}") data = json.loads(data.group(1)) print(data) # pretty print the data: print(json.dumps(data, indent=4)) print(f'data.fetchedCommonResponse = {data["fetchedCommonResponse"]}') print(f'data.isDarkTheme = {data["isDarkTheme"]}') for item in data["headerStore"]["gnb"]["gnbItems"]: print(f'idx = {item["idx"]}, ' f'title = {item["title"]} ')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
运行结果如下,其中 json.dumps() 对数据格式进行了美化:

-
相关阅读:
11、Microsoft Visual Studio 2022 Installer Projects踩坑一
7. 迭代器iterator
【洛谷 P1449】后缀表达式 题解(栈+分支)
JAVA基础实现对日期的常用操作
仿真1. 什么是仿真系统
基于ssm的计算机类考研资源平台管理系统(idea+spring+springmvc+mybatis+jsp)(前端+后端)
FoFa 查询工具(fofax)
CSS day_13(6.28) Boot常用组件(nav、tab、分页)Sass介绍
【chatglm3】(4):如何设计一个知识库问答系统,参考智谱AI的知识库系统,
js将图片或者文件转成base64格式的两种方法
- 原文地址:https://blog.csdn.net/BullKing8185/article/details/138110506