-
五、Jvm调优
Jvm调优调什么
这个疑问必须要有,当对一个技术或者系统调优的时候 ,我们一定要知道去调什么,这样有一个出发点,有一个目标。不能胡乱的调对吧。
那么Jvm调优,主要调以下
1)减少Full GC
2)解决OOM
3)
总的来说就是:使用较小的内存占用来获得较高的吞吐量或较低的延迟
windows 系统下 我们可以通过 jps 命令查看程序进程ID
linux 系统我们通过 ps -ef | grep java 来找到要调整的程序的进程ID (jps在linux下一样可以用,不过部署的服务很多,不知道那个是我们要调的程序进程ID)
有了进程ID我们就可以对他做各种事情了
命令行
jmap
- // 查看当前系统的实例
- jmap -histo 进程ID
- // 查看当前存活的实例 执行时可能会出发FGC
- jmap -histo:live 进程ID
- // 导出系统实例
- jmap -histo 进程ID >log.txt
打开导出的文件

num:序号
instances:实例数量
bytes:占用空间大小
class name:类名称(C=char[],S=short[],I=int[],B=byte[])
通过这些信息我们能看出程序在运行中,导出的那个瞬间,那个实例数最多,如果有我们自己写的,那就得好好分析分析了。
通过命令 【 jmap -heap 进程ID】 查看堆信息

通过 【jmap -dump:format=b,file=test2021.hprof 进程ID】 导出堆内存 dump,如果内存很大会导不出来,或者时间很长。
通过参数 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./ 设置在内存溢出自动导出dump文件。
jstack
1)查找CPU较高的线程堆栈信息(Linux系统)
通过 top 命令查看正在运行的所有进程情况,实时的一个状态

找出%CPU最高的那个进程ID,也就是PID,通过命令【top -p 进程ID】锁定它,大写状态下的 H 字母,可以查看该进程下的所有线程状态

最上面的也是CPU最高的,找到线程ID,也就是PID,将其转换成16进制(19518>4c3e),执行命令【jstack 进程ID | grep -A 10 4c3e】就可以看到那些造成CPU高的代码

2)查找程序死锁代码
通过命令 【jstack 进程ID】
- "Thread-1":线程名
- prio=5:线程优先级5
- tid=0x000000001fa9e000:线程ID
- nid=0x2d64:线程对应的本地线程标识nid
- java.lang.Thread.State: BLOCKED:线程当前的状态
这个就随便找个运行中的应用程序,试一下,看代码有没有死锁
jinfo
通过命令【jinfo -flags 进程ID】查看正在运行的这个Java应用程序的扩展参数

jstat
可以查看堆内存各部分的使用情况
通过命令 【jstat -gc 进程ID】可以评估程序内存使用及GC压力整体情况,也是最常用的
或者 【jstat -gc 进程ID 打印频率毫秒 打印次数】

每个标识代表的含义
- S0C:第一个幸存区的大小,单位KB
- S1C:第二个幸存区的大小
- S0U:第一个幸存区的使用大小
- S1U:第二个幸存区的使用大小
- EC:年轻代的大小
- EU:年轻代的使用大小
- OC:老年代大小
- OU:老年代使用大小
- MC:方法区、元空间大小
- MU:方法区、元空间使用大小
- CCSC:压缩类空间大小
- CCSU:压缩类空间使用大小
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间,单位s
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间,单位s
- GCT:垃圾回收消耗总时间,单位s
通过命令【jstat -gccapacity 进程ID】或者 【jstat -gc 进程ID 打印频率毫秒 打印次数】来统计堆内存的一个使用情况
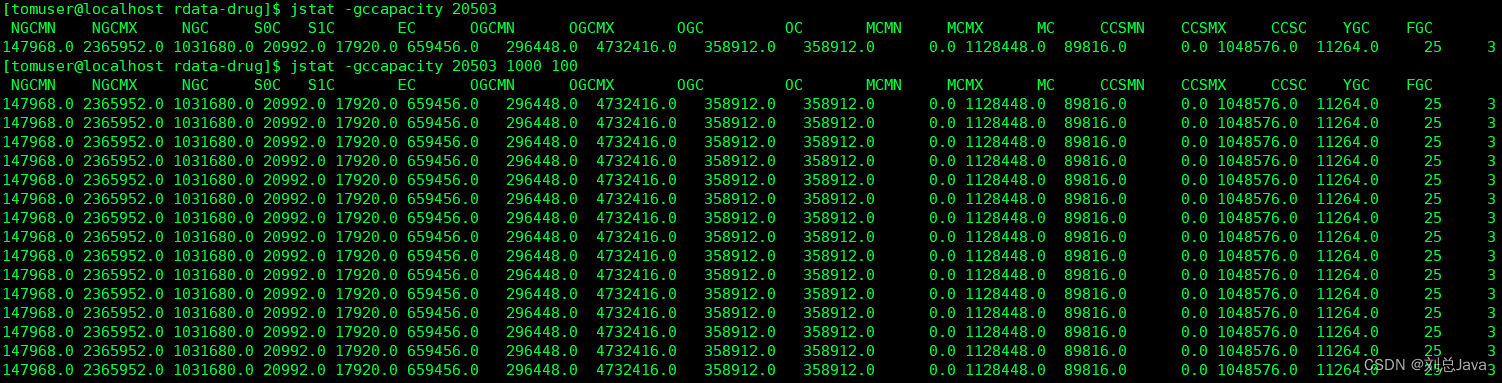
每个标识代表的含义
- NGCMN:新生代最小容量
- NGCMX:新生代最大容量
- NGC:当前新生代容量
- S0C:第一个幸存区大小
- S1C:第二个幸存区的大小
- EC:年轻代的大小
- OGCMN:老年代最小容量
- OGCMX:老年代最大容量
- OGC:当前老年代大小
- OC:当前老年代大小
- MCMN:最小元数据容量
- MCMX:最大元数据容量
- MC:当前元数据空间大小
- CCSMN:最小压缩类空间大小
- CCSMX:最大压缩类空间大小
- CCSC:当前压缩类空间大小
- YGC:年轻代gc次数
- FGC:老年代GC次数
还可以针对特定的需求进行统计查看
年轻代GC统计:jstat -gcnew 进程ID
唯一有区别的就是,只统计了年轻代的情况,加了这么几个参数
TT:对象在新生代存活的次数
MTT:对象在新生代存活的最大次数
DSS:期望的幸存区大小
年轻代内存统计:jstat -gcnewcapacity 进程ID
老年代GC统计:jstat -gcold 进程ID
老年代内存统计:jstat -gcoldcapacity 进程ID
元数据空间统计:jstat -gcmetacapacity 进程ID
这几个就是从上面全部的里面单独拆解出来的,可单独对某个代进行分析。
通过上面的一些命令,我们能得到一些JVM的关键数据,有了这些数据就可以采用一些优化手段,先给自己的系统设置一些初始性的JVM参数,比如堆内存大小,年轻代大小,Eden和Survivor的比例,老年代的大小,大对象的阈值,大龄对象进入老年代的阈值等。
调优方式
1)观察年轻代对象增长的速率
可以执行命令 jstat -gc pid 1000 10,通过观察EU(eden区的使用情况)来估算每秒eden大概新增多少对象,如果系统负载不高,可以把频率1秒换成1分钟,甚至10分钟来观察整体情况。但是系统一般有高峰期和日常期,所以需要在不同的时间分别估算不同情况下对象增长速率。
2)观察Young GC的触发频率和耗时
知道年轻代对象增长速率我们就能推根据eden区的大小推算出Young GC大概多久触发一次,Young GC的平均耗时可以通过 YGCT/YGC 公式算出,根据结果我们大概就能知道系统大概多久会因为Young GC的执行而卡顿多久。
3)统计Young GC后有多少对象存活和进入老年代
这个因为之前已经大概知道Young GC的频率,假设是每5分钟一次,那么可以执行命令 jstat -gc pid 300000 10 ,观察每次结果eden,survivor和老年代使用的变化情况,在每次gc后eden区使用一般会大幅减少,survivor和老年代都有可能增长,这些增长的对象就是每次Young GC后存活的对象,同时还可以看出每次Young GC后进去老年代大概多少对象,从而可以推算出老年代对象增长速率。
4)观察Full GC的触发频率和耗时
知道了老年代对象的增长速率就可以推算出Full GC的触发频率了,Full GC的每次耗时可以用公式 FGCT/FGC 计算得出。
其实整体的优化思路其实简单来说就是尽量让每次Young GC后的存活对象小于Survivor区域的50%,都留存在年轻代里,别让对象进入老年代。减少Full GC的频率,避免频繁Full GC对JVM性能的影响
工具分析
上面介绍的都是一些命令行,来查看分析系统的参数,也有很多工具,图形化界面,辅助我们进行分析JVM的运行情况。比如:JDK自带的 jvisualvm、阿里巴巴的 Arthas,这些工具就是对基础命令的封装,做成了可视化;
jvisualvm
该工具主要是导入一些 dump文件 或者 hprof文件 或一些快照文件进行分析
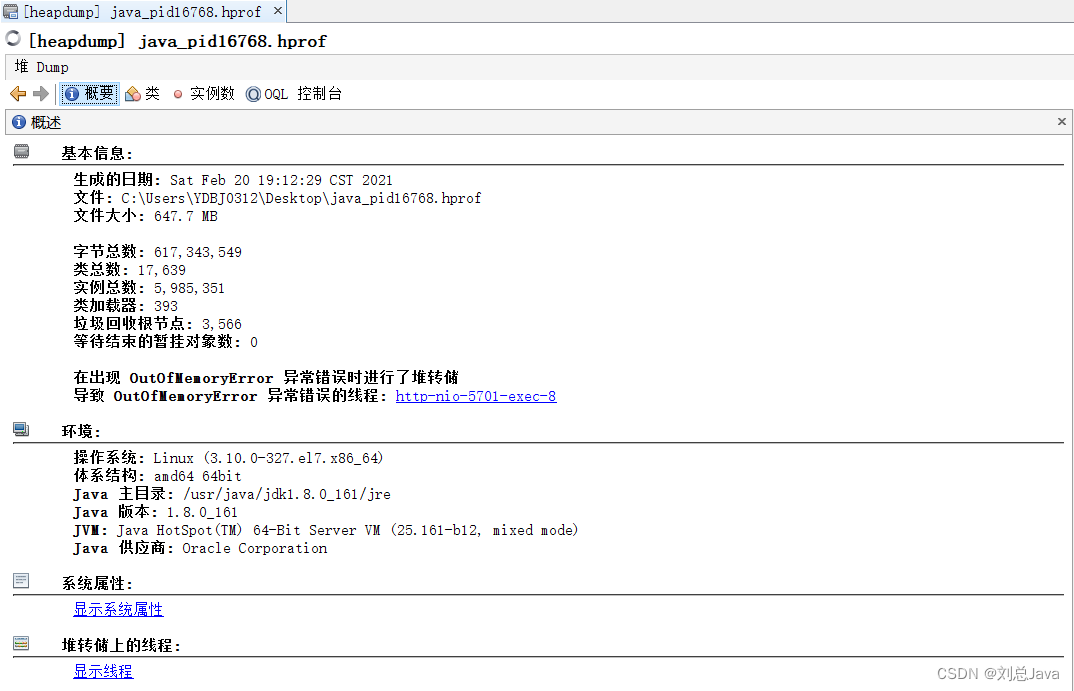
在导出的瞬间,实例数的占比

也可以远程连接到指定服务程序,只需要在启动程序,进行JMX端口配置
- java
- -Dcom.sun.management.jmxremote.port=8888
- -Djava.rmi.server.hostname=127.0.0.1
- -Dcom.sun.management.jmxremote.ssl=false
- -Dcom.sun.management.jmxremote.authenticate=false
- -jar aio-test-server.jar
-Dcom.sun.management.jmxremote.port 为远程机器的JMX端口
-Djava.rmi.server.hostname 为远程机器IP
连接时的主要问题就是端口不通,可以临时关闭下防火墙。
还有生产环境不会给你这么暴露机器端口的。
如果是Tomcat容器,在catalina.sh文件里的最后一个JAVA_OPTS的赋值语句下一行增加如下配置:
- JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote.port=8888
- -Djava.rmi.server.hostname=127.0.0.1
- -Dcom.sun.management.jmxremote.ssl=false
- -Dcom.sun.management.jmxremote.authenticate=false"
也可以实时监控查看程序

Arthas
Arthas 是 Alibaba 在 2018 年 9 月开源的 Java 诊断工具。
支持 JDK6+, 采用命令行交互模式,可以方便的定位和诊断线上程序运行问题。
Arthas 官方文档十分详细:arthas 就不过多介绍了。
Arthas使用场景
得益于 Arthas 强大且丰富的功能,让 Arthas 能做的事情超乎想象。仅列举
1)这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?
2)我改的代码为什么没有执行到?难道是我没 commit?分支搞错了?
3)遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
4)线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!
5)是否有一个全局视角来查看系统的运行状况?
6)有什么办法可以监控到JVM的实时运行状态?
7)怎么快速定位应用的热点,生成火焰图?
8)......
Arthas使用示例
1)下载资源包
- github下载arthas
- wget https://alibaba.github.io/arthas/arthas-boot.jar
下载完之后,直接使用 java -jar 命令启动jar包就行,运行过程,会找出当前机器的Java程序,输入想要看的服务编号,回车便进入了。
同样也是命令行的操作
- // 查看整个程序的运行情况,线程、内存、CPU、运行环境等信息
- dashboard
- // 查看线程情况
- thread
- // 查看线程的堆栈情况
- thread 线程ID
- // 查看线程死锁的情况
- thread -b
更多命令,去官网文档查看:https://alibaba.github.io/arthas/commands.html#arthas
所有的命令行命令都支持 -h 或者 -help 就是该命令的一个帮助文档吧。
例如 java 命令的帮助 java -h 即可,学会灵活运用。
-
相关阅读:
麒麟移动运行环境(KMRE)——国内首个开源的商用移固融合“Android生态兼容环境”正式开源
从 Google 离职,前Go 语言负责人跳槽小公司
7000字详解Spring Boot项目集成RabbitMQ实战以及坑点分析
小程序中的事件处理
Leetcode刷题详解——扫雷游戏
基础工具类Joiner的使用
C++中虚继承时的构造函数
php简单商城小程序系统源码
[油猴脚本] Image To Ascii 快速转换审计网站图片中敏感信息插件
【ELM预测】基于极限学习机进行正弦波预测附matlab代码
- 原文地址:https://blog.csdn.net/weixin_46129103/article/details/126150299
