-
近邻搜索算法浅析
简介
随着深度学习的发展和普及,很多非结构数据被表示为高维向量,并通过近邻搜索来查找,实现了多种场景的检索需求,如人脸识别、图片搜索、商品的推荐搜索等。另一方面随着互联网技术的发展及5G技术的普及,产生的数据呈爆发式增长,如何在海量数据中精准高效的完成搜索成为一个研究热点,各路前辈专家提出了不同的算法,今天我们就简单聊下当前比较常见的近邻搜索算法。
主要算法
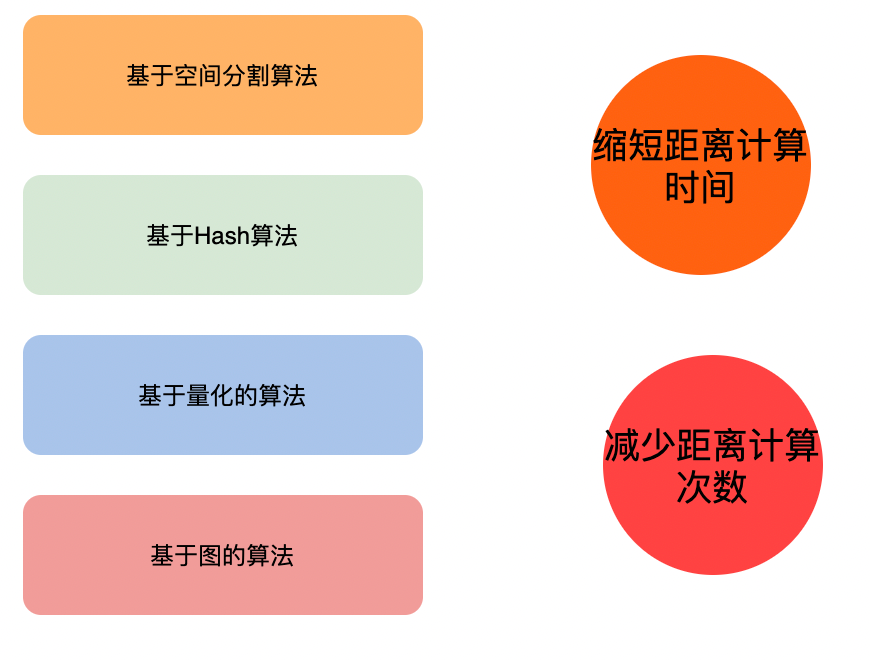
Kd-Tree
K-dimension tree,二叉树结构,对数据点在k维空间(如二维 (x,y),三维(x,y,z),k维(x,y,z..))中划分。
构建过程
确定split域的值(轮询 or 最大方差) 确定Node-data的域值(中位数 or 平均值) 确定左子空间和右子空间 递归构造左右子空间查询过程
进行二叉搜索,找到叶子结点 回溯搜索路径,进入其他候选节点的子空间查询距离更近的点 重复步骤2,直到搜索路径为空性能
理想情况下的复杂度是O(K log(N)) 最坏的情况下(当查询点的邻域与分割超平面两侧的空间都产生交集时,回溯的次数大大增加)的复杂度为维度比较大时,直接利用K-d树快速检索(维数超过20)的性能急剧下降,几乎接近线性扫描。改进算法
Best-Bin-First:通过设置优先级队列(将“查询路径”上的结点进行排序,如按各自分割超平面与查询点的距离排序)和运行超时限定(限定搜索过的叶子节点树)来获取近似的最近邻,有效地减少回溯的次数。采用了BBF查询机制后Kd树便可以有效的扩展到高维数据集上 。Randomized Kd tree:通过构建多个不同方向上的Kd tree,在各个Kd tree上并行搜索部分数量的节点来提升搜索性能(主要解决BBF算法随着Max-search nodes增长,收益减小的问题)
Hierarchical k-means trees
类似k-means tree,通过聚类的方法来建立一个二叉树来使得每个点查找时间复杂度是O(log n) 。
构建过程 :
随机选择两个点,执行k为2的聚类,用垂直于这两个聚类中心的超平面将数据集划分 在划分的子空间内进行递归迭代继续划分,直到每个子空间最多只剩下K个数据节点 最终形成一个二叉树结构。叶子节点记录原始数据节点,中间节点记录分割超平面的信息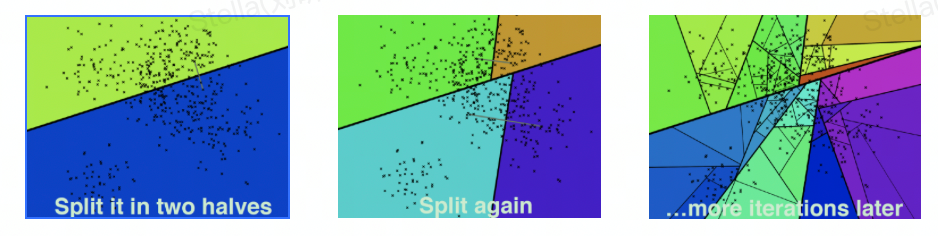
搜索过程
- 从根节点开始比较,找到叶子节点,同时将路径上的节点记录到优先级队列中
- 执行回溯,从优先级队列中选取节点重新执行查找
- 每次查找都将路径中未遍历的节点记录到优先级队列中
- 当遍历节点的数目达到指定阈值时终止搜索
性能
- 搜索性能不是特别稳定,在某些数据集上表现很好,在有些数据集上则有些差
- 构建树的时间比较长,可以通过设置kmeans的迭代次数来优化
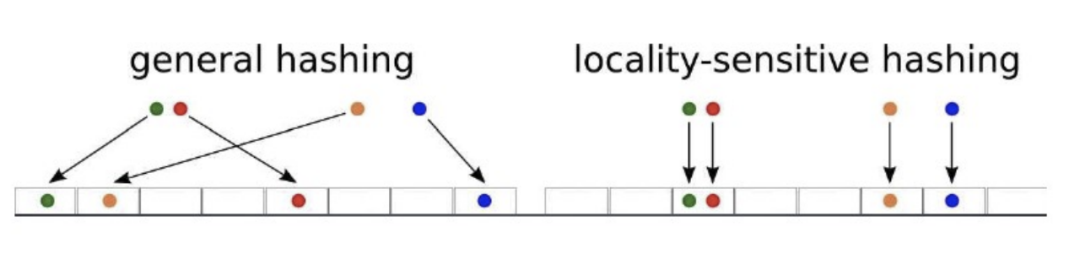
LSH
Locality-Sensitive Hashing 高维空间的两点若距离很近,他们哈希值有很大概率是一样的;若两点之间的距离较远,他们哈希值相同的概率会很小.
一般会根据具体的需求来选择满足条件的hash函数,(d1,d2,p1,p2)-sensitive 满足下面两个条件(D为空间距离度量,Pr表示概率):
- 若空间中两点p和q之间的距离D(p,q)
- 若空间中两点p和q之间的距离D(p,q)>d2,则Pr(h(p)=h(q))
离线构建索引
选择满足(𝑅,𝑐𝑅,𝑃1,𝑃2)-sensive的哈希函数; 根据对查找结果的准确率(即相邻的数据被查找到的概率)确定哈希表的个数𝐿, 每个table内的hash functions的个数(也就哈希的键长𝐾),以及跟LSH hash function 自身有关的参数 ;利用上面的哈希函数组,将集合中的所有数据映射到一个或多个哈希表中,完成索引的建立。
在线查找
将查询向量𝑞通过哈希函数映射,得到相应哈希表中的编号 将所有哈希表中相应的编号的向量取出来,(保证查找速度,通常只取前2𝐿) 对这2𝐿个向量进行线性查找,返回与查询向量最相似的向量。
查询耗时主要为:
计算q的hash值(table id)+ 计算q与table中点的距离查询效果方面由于损失了大量原始信息从而降低检索精度 。
PQ
product quantization,把原来的向量空间分解为若干个低维向量空间的笛卡尔积,并对分解得到的低维向量空间分别做量化(quantization),这样每个向量就能由多个低维空间的量化code组合表示。
需要选取最优的量化算法,我们熟知的k-means算法就是一个接近最优化的量化算法。
量化
使用k-means进行量化的过程
- 将原始向量切分为m组,每组内使用k-means聚类,产出m组,每组多个聚类中心
- 将原始向量编码为m维向量,向量中每个元素代表所在组聚类中心的id
查询过程
- 将搜索query划分子向量,计算子向量和对应段的所有簇心的距离,得到距离表(m×k*矩阵)
- 遍历样本库中的向量,根据距离表,计算每个样本与查询向量的距离和返回k个距离最接近的样本

距离计算
SDC(symmetric distance computation),对称的距离计算方法,对query向量和样本库中的向量都进行PQ量化,同时会在构建阶段会计算出每组向量各个聚类中心的距离,生成k*k的距离表,在查询阶段计算query向量和样本库中的向量时,通过查表即可,减少计算过程,但放大了误差。
ADC(Asymmetric distance computation),非对称的距离计算方案,只对样本库中的向量进行PQ量化,在查询阶段计算query向量和m组聚类中心的距离,生成m*k的距离表,然后查表计算与样本库中向量的距离,由于需要每次对查询向量实时计算,增加计算开销,但误差小。
优化
IVFPQ,基于倒排的乘积量化算法,增加粗量化阶段,对样本进行聚类,划分为较小的region ,减少候选集数据量(之前是需要遍历全量的样本,时间复杂度为O(N*M))。
HNSW
在NSW算法之上进行改进的基于图的算法,使用分层的结构,在每层通过启发式方法来选择某节点的邻居(保证全局连通性),使其构成一张连通的图。

建图流程
- 计算节点的最大层次l;
- 随机选择初始入口点ep,L为ep点所在的最大层;
- 在L~l+1层,每层执行操作:在当前层找到距离待 插节点最近的节点ep,并作为下一层的输入;
- l层以下为待插元素的插入层,从ep开始查找距离待插元素 最近的ef个节点,从中选出M个与待插节点连接,并将这M 个节点作为下一层的输入;
- 在l-1~0层,每层执行操作:从M个节点开始搜索,找到距离与待插节点最近的ef个节点,并选出M个与待插元素连接
查询流程
- 从顶层到倒数第二层,循环执行操作:在当前层寻找距离查询节点最近的一个节点放入候选集中,从候选集中选取出距离查询节点最近的一个节作为下一层的入口点;
- 从上层得到的最近点开始搜索最底层,获取ef个近邻点放入候选集中;
- 从候选集中选取出topk 。
实现
当前有比较成熟的库实现了各种主流的近邻搜索算法,在项目中可以通过这些基础库来构建对应的近邻搜索服务,其中使用比较广泛的是faiss库,由Fackbook开源,在支持不同算法的同时,也支持在超大规模数据集上构建k近邻搜索以及支持GPU来加速索引构建和查询,同时社区活跃,在考虑到性能和可维护性,faiss库是构建近邻检索服务的比较好的选择。
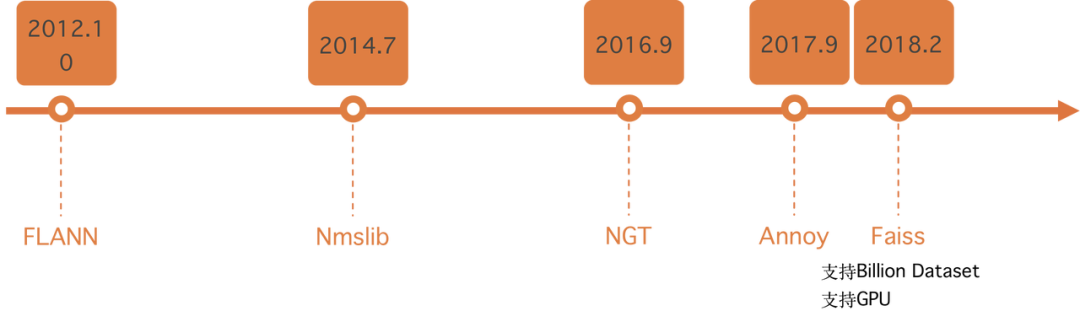
总结
本文展示了当前比较常见的几种近邻搜索算法,并简单分析了各算法的原理;随着深度学习的不断发展,不同场景对近邻搜索的需求越来越多,必定会有新的算法不断地涌现,每种算法有它适合的场景,在选择不同算法时需要结合业务的需求,如数据量的大小,召回的效果,性能,资源消耗等各方面的因素,通过了解不同算法的实现,可以选择更适合当前业务的算法。
*文/张林
-
相关阅读:
计算机专业突然不香了?会成为下一个土木工程吗?
【C语言】写入访问权限冲突
SonarQube介绍和安装
Ext JS之Ext Direct快速入门
YOLO_v6讲解
使用java 实现mqtt两种方式
【Matplotlib绘制图像大全】(二十七):Matplotlib将数组array保存为图像
如何写好软件任务书
2023最新ELK日志平台(elasticsearch+logstash+kibana)搭建
高并发系统架构设计之实战派篇:计数系统之未读数系统
- 原文地址:https://blog.csdn.net/SmartCodeTech/article/details/126124939