-
2.0、C语言——分支、循环语句
2.0、C语言——分支、循环语句
C#的分支语句 if 、 else 、 else if 和 Java 差不多,这里就不做过多的介绍了,直接上代码:
- #define _CRT_SECURE_NO_WARNINGS 1
- #include
- int main() {
- int age = 10;
- if (age > 0 && age < 18) {
- printf("未成年~");
- }else if (age >=18 && age < 30) {
- printf("青少年~");
- }else {
- printf("未知~");
- }
- return 0;
- }
在C#中 我们用 0 表示假,一切 非0 表示真(注意嗷~不只是 1 才能表示真)
对比学习 - 在Java中我们不能用0表示假,非0表示真,因为在Java中专门有一个boolean布尔类型,而布尔类型的值只有两个 -> 一个是true 一个是false
但是由于在C#中之前没有 bool类型 所以只能用 0 和 非0 来表示真假
if 和 else 的配对原则:
if() {}else {} 语句中 else 到底是如何与 if 配对的呢?比如以下代码 ->- #define _CRT_SECURE_NO_WARNINGS 1
- #include
- int main() {
- int a = 60;
- if (a < 100)
- if (a < 50)
- printf("0 < a < 50");
- else
- printf("50 < a < 100");
- return 0;
- }
这里的 else 看上去好像是与第一个 if 配对,但是其实不是;
else 的配对原则是离自己最近并且未配对的 if ,所以这个else配对的应该是第二个if;
当然这是没有写 {}花括号 的情况才会出现这种情况~if()条件判断语句中如果是一个常量和一个变量的比较,建议把常量放在左边,这样逻辑更加清晰、不容易出错
switch case语句
当我们遇到多分支的时候,如果用 if 和 else if 的话会很麻烦,这时候我们可以尝试用switch case 来解决这个问题(该语句常常用于多分支的情况)
switch 语句和 Java 中差不多所以这里就不过多介绍了,直接上代码:
- #define _CRT_SECURE_NO_WARNINGS 1
- #include
- int main() {
- int day;
- scanf("%d", &day);
- switch (day)
- {
- case 1:
- printf("星期1");
- break;
- case 2:
- printf("星期2");
- break;
- case 3:
- printf("星期3");
- break;
- case 4:
- printf("星期4");
- break;
- case 5:
- printf("星期5");
- break;
- case 6:
- printf("星期6");
- break;
- case 7:
- printf("星期7");
- break;
- default:
- printf("输入有误~");
- break;
- }
- return 0;
- }
这里要注意的是:
1、switch() 表达式中 必须是整型变量,不能是浮点型或者其他类型
2、case() 表达式中必须是 整型常量表达式(不能是变量)
3、在每个 case 结束的时候记得加上 break ,否则就会导致从该 case 开始以及在这个 case 以下的 case 都会执行一遍 ;
switch 决定入口,而 break 决定出口那其实也不是所有的情况每个 case 后面都需要加 break,上代码:
- #define _CRT_SECURE_NO_WARNINGS 1
- #include
- int main() {
- int day;
- scanf("%d", &day);
- switch (day)
- {
- case 1:
- case 2:
- case 3:
- case 4:
- case 5:
- printf("工作日~");
- break;
- case 6:
- case 7:
- printf("休息日~");
- break;
- default:
- printf("输入有误~");
- break;
- }
- return 0;
- }
那么像上面这种情况呢 -> 数字 1~5 都是输出工作日所以就可以直接省略掉 break 这么写,同理 6~7 是休息日也这么写。
那最后一个case还要不要加上 break 呢?
我还是建议大家加上,一个是因为代码书写的规范性可读性,另一个就是考虑到代码的可维护性(因为如果有一天我们需要加上case 8 : 的时候漏看漏加可能会出现问题)循环语句:
while循环语句:while(表达式)
循环语句;判断表达式是否为真 -> 为真则执行循环语句 -> 再次判断表达式是否为真 -> 若为假则循环结束
while循环流程图如下:

如果在循环体中遇到 break 则直接跳出该循环,
如果遇到 continue 则会跳过循环体中剩下的语句然后直接重新判断表达式是否为真,若为真则继续循环,为假则结束循环getchar() 和 putchar() 函数:
getchar() 函数他能够接收键盘输入的字符(getchar函数一次只能接收用户输入的一个字符);
putchar() 能够输出之前输入函数输入的字符(putchar函数一次只能输出用户输入的一个字符),代码如下所示:
- #define _CRT_SECURE_NO_WARNINGS 1
- #include
- int main() {
- char ch = getchar();
- putchar(ch);
- return 0;
- }
那比如说我们输入 information ,那么如果我们想用putchar()打印出这个单词就必须要写 11 个putchar();
什么是 -> 输入缓冲区?
先上一段代码 如下所示:
- #define _CRT_SECURE_NO_WARNINGS 1
- #include
- int main() {
- char password[20];
- printf("请输入密码\n");
- scanf("%s",password);
- printf("请确认你的密码 ->(Y/N)\n");
- int flag = getchar();
- if (flag == "Y") {
- printf("确认成功~");
- }else {
- printf("无效确认~");
- }
- return 0;
- }
这段代码按道理应该是先等待输入密码,然后等待输入Y/N,但是实际执行的时候却是输入完密码后直接跳过了输入 Y/N 的语句,这是为什么呢 -> 因为像 scanf() 和 getchar() 这种输入函数在接受我们输入的数据的时候,会先到 输入缓冲区 中查看是否有数据,查看后如果没有数据则会等待用户输入数据,如果查看后发现有数据则会将数据取出然后继续执行下面的语句;
由于我们在输入密码123456后敲了回车键(因为不敲回车键代码不会向下执行 -> 所以必须敲回车),所以缓冲区中存放的数据就是:123456\n,那么这时候有数据了scanf()函数会拿走他需要的一部分数据也就是123456,那么这时候缓冲区中只剩下 \n 这个数据,然后到了执行 getchar()函数 的时候他也会先去输入缓冲区看看有没有数据,那么这时候他发现缓冲区中有一个 \n 那么就会直接取走(由于缓冲区中有数据所以他不会停下来等待用户输入数据),然后继续向下执行。
那怎么解决这个问题呢?
问题:由于上一个输入函数输入数据后,必须敲一下回车才能往下继续执行,所以在输入缓冲区中会残留有一个 \n 数据,那么现在要想一个办法将这个 \n 数据删掉;
解决方案:在第一个输入函数之后加一个getchar()输入函数,那么这个 getchar() 会将缓冲区中的 \n 读掉,然后再到了确认密码的输入函数去查看缓冲区是否有数据就会发现缓冲区无数据,自然就会停下来等待用户输入 Y/N 了解决之后发现又出现一个新问题,当我们输入123456 ABCD,敲回车后发现又出现了和刚刚一样的问题,这是什么情况呢?
这是因为我们输入的是123456空格ABCD\n,这时候第一个 scanf() 拿走了123456,然后 getchar() 拿走了空格,然后到去人密码输入函数的时候又发现缓冲区中有数据,所以又直接跳过了用户输入的步骤。
那这个问题又该如何解决的呢?
其实出现这个问题的本质还是因为在第一个 scanf() 输入函数后接下来的 getchar()函数 没有将缓冲区残留的数据读完,那我们只需要想个办法将残留的数据读完就可以解决了,先来看看以下代码:- #define _CRT_SECURE_NO_WARNINGS 1
- #include
- int main() {
- char password[20];
- printf("请输入密码\n");
- scanf("%s",password);
- while (getchar() != '\n') {
- ;
- }
- printf("请确认你的密码 ->(Y/N)\n");
- int flag = getchar();
- if (flag == 'Y') {
- printf("确认成功~");
- }else {
- printf("无效确认~");
- }
- return 0;
- }
可以利用 while 循环中的表达式一直不断的去读缓冲区的数据一直读到 '\n' 就停止循环,因为读到 '\n' 则表示缓冲区中的数据已经全部读完,然后跳出循环继续往下执行即可(这里while循环体中只写了一个分号 ; 表示这是一条空语句,循环体中不需要做任何事情只要不断的执行表达式即可)
EOF文件结束标志:
这里顺便说一下 EOF(end of file)文件结束标志,来看看以下代码,当我们 getchar() 输入任何字符的时候显然会将该字符打印出来,但是我们输入 字符EOF 的时候发现程序也不会结束,因为getchar() 是一个个字符打印的 -> 先打印了 E 然后打印 O 然后打印 F,这时候程序依然无法结束仍然在跑;
这时候我们需要按下 Ctrl + z 即可让getchar()接收到输入EOF,然后结束程序
- #define _CRT_SECURE_NO_WARNINGS 1
- #include
- int main() {
- int ch = 0;
- while ((ch = getchar()) != EOF) {
- putchar(ch);
- }
- return 0;
- }
再看下以下代码:
- #define _CRT_SECURE_NO_WARNINGS 1
- #include
- int main() {
- int ch = 0;
- while ((ch = getchar()) != EOF) {
- if (ch < '0' || ch > '9') {
- continue;
- }
- putchar(ch);
- }
- return 0;
- }
运行之后会不断的让用户去输入字符,如果是0~9的字符则会输出,否则直接continue,
for循环:
我们已经知道了 while 循环,但是我们为什么还要一个 for 循环呢?首先来看看 for 循环的语法:
语法:
for (表达式1;表达式2;表达式3) {
循环语句;
}表达式1 表达式1为初始化部分,用于初始化循环变量。表达式2 表达式2位条件判断部分,用于判断循环终止,表达式3为 调整部分,用于循环条件的调整。
下面是for循环的结构图:

流程大概就是:表达式1 -> 表达式2 -> 循环体中的语句 -> 表达式3 -> 表达式2 -> 循环体中的语句 ->表达式3 -> .........-> 循环结束
for循环的用法和Java差不多,在这里就不过多介绍了,直接上代码:
- #define _CRT_SECURE_NO_WARNINGS 1
- #include
- int main() {
- for (int i = 0;i<=100;i++) {
- printf("i = %d\n",i);
- }
- return 0;
- }
break和continue在for循环中的用法和在while中是一样的,在这里就不多说了~
使用for循环的一些建议:
1、不可在for循环体内修改循环变量,防止for循环失去控制,因为有可能导致死循环的产生
2、建议for语句的循环控制变量的取值采用 “ 前闭后开区间 ” 写法(就是表达式1从0开始 -> i=0,表达式2写成 i
【当然这只是建议,不是绝对,我们写代码的时候还是要灵活一点】
关于 for循环 的变种用法:
变种1:for(;;){} ,
for循环中初始化、判断、调整 三者都可以省略,但是如果判断条件表达式被省略了,那么判断条件就是恒为真,会导致死循环的出现~
- #define _CRT_SECURE_NO_WARNINGS 1
- #include
- int main() {
- for (;;) {
- printf("for循环变种1");
- }
- return 0;
- }
所以说大家如果不是很熟练了,建议不要随意的省略,避免出错
变种2:
- #define _CRT_SECURE_NO_WARNINGS 1
- #include
- int main() {
- for (int x = 0, y = 0;x < 10 && y < 15;++x,y++) {
- printf("for循环变种2");
- }
- return 0;
- }
这里给大家分享一道笔试题,判断一下该for循环会执行多少次呢,如下所示:
- #define _CRT_SECURE_NO_WARNINGS 1
- #include
- int main() {
- for (int i = 0, k = 0;k=0;j++,k++) {
- k++;
- }
- return 0;
- }
答案是 0 次,由于判断表达式中不是判断语句而是赋值语句 -> k = 0 那么由于是 0 所以该表达式为假,所以最终结果就是无法进入该 for 循环
do while循环:
do while循环语句和Java中的用法没什么区别,所以也不过多介绍了,直接上代码:
- #define _CRT_SECURE_NO_WARNINGS 1
- #include
- int main() {
- int i = 1;
- do {
- printf("i = %d\n", i);
- i++;
- }
- while (i<11);
- }
do whlie循环的执行流程图如下:
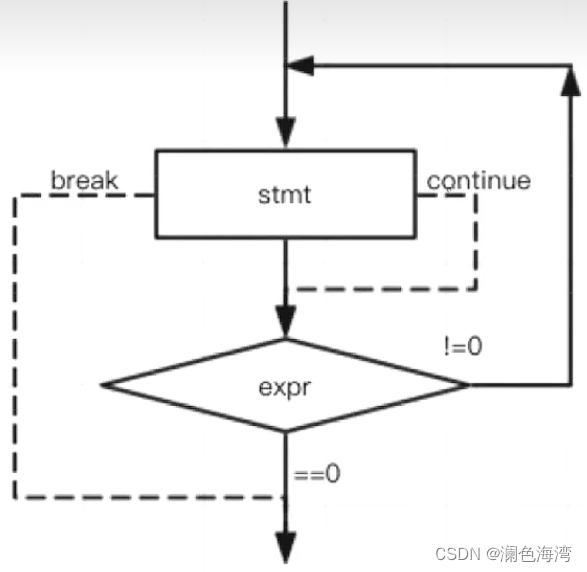
可以看到 do while 循环语句至少会执行一次,他是先执行了 do 代码块内的代码,再去判断条件是否为真,为真就继续执行 do,为假就结束循环体
do while循环结构中 break 和 continue 关键字使用方法与在其他循环语句中相同
二分查找法 代码如下:
- #define _CRT_SECURE_NO_WARNINGS 1
- #include
- int main() {
- int arr[] = { 1,2,3,4,5,6,7,8,9 };
- int sz = sizeof(arr) / sizeof(arr[0]);
- int k = 11; //要查找的值
- int left = 0; //左指针
- int right = sz - 1; //有指针
- int mid = (left + right) / 2; //每次比较的中间值
- while (left <= right) {
- if (arr[mid] > k) {
- right = mid - 1;
- }
- else if (arr[mid] < k) {
- left = mid + 1;
- }
- else {
- printf("找到k了,k的下标为:%d", mid);
- break;
- }
- mid = (right + left) / 2;
- }
- if (left > right) {
- printf("该元素不在arr数组中");
- }
- return 0;
- }
在引入 #include
头文件后可以使用 Sleep(1000); 休眠函数 在引入 #include
头文件后 可以使用 system("cls"); 在比较两个字符串是否相同的时候不能用 == 来判断,要用 strcmp(字符串A,字符串B)库函数去比较【如果A大于B则会返回一个正整数,如果 A == B 返回0,如果 A < B 返回一个负整数】
题目1:找出 a,b 两个正整数的最大公约数,我们可以用辗转相除法,那什么是辗转相除法呢?
辗转相除法:
比如 a = 24; b = 6;
如果a%b == 0 说明 b 就是最大公约数,
如果a%b != 0
那么将 b 的值赋给 a,将模的值赋给 b,然后再次 a%b
循环不断取模,直到模等于 0 为止,这时 b 就是最大公约数~
【注意:第一次取模一定要用大的数字除小的数字】代码如下 ->- #define _CRT_SECURE_NO_WARNINGS 1
- #include
- int main() {
- int a = 6;
- int b = 7;
- int yushu = 0;
- int max = a > b ? a : b;
- int min = a < b ? a : b;
- while (1) {
- if ((yushu = max % min) == 0) {
- printf("a和b的最大公约数 = %d", min);
- break;
- }
- else {
- max = min;
- min = yushu;
- }
- }
- return 0;
- }
-
相关阅读:
记一次排除ulimit限制.
git log 统计自己代码提交量报错 awk No such file or directory
Hive及Sqoop的表操作
[ vulhub漏洞复现篇 ] struts2远程代码执行漏洞s2-013(CVE-2013-1966)
文件讲解—【C语言】
k8s报错的解决办法: kubelet的日志出现 Error getting node的报错。
概率论的学习整理3: 概率的相关概念
算法:经典贪心算法--跳一跳[2]
PyTorch训练RNN, GRU, LSTM:手写数字识别
C++中使用嵌套循环遍历多维数组
- 原文地址:https://blog.csdn.net/m0_52433668/article/details/126106661
