-
Python Lambda 常用使用方法汇总(结合fliter\map\reduce等函数)
Lambda表达式
Lambda 表达式可以简化函数的使用,比如,需要在基础数值上增加5再返回结果。如果使用def, 如下
def add_20(a): return a+20- 1
- 2
可以直接使用lambda更加简洁。
var = lambda a : a + 20 print('With argument value 5 : ',var(5)) print('With argument value 10 : ',var(10)) # 可以传多个参数 lambda_add = lambda a, b : a+b print('The value of 5+3 = ',lambda_add(5,3)) print('The value of 7+2 = ',lambda_add(7,2))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
字符串拼接
首先将传入的参数定义为first 和last,然后打印出来
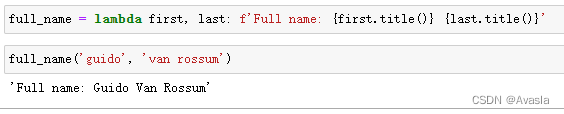
full_name = lambda first, last: f'Full name: {first.title()} {last.title()}' full_name('guido', 'van rossum')- 1
- 2
筛选过滤:lambda+filter
将满足条件(不可以被2整除)的数字留下
original_list = [5, 17, 32, 43, 12, 62, 237, 133, 78, 21] # filter the odd numbers from the list filtered_list = list(filter(lambda x: (x%2 != 0) , original_list)) print('The odd numbers are : ',filtered_list)- 1
- 2
- 3
- 4
- 5
- 6

修改变量、字符串内容: lambda+Map
修改变量、字符串内容
#所有数字乘以2 original_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] # double each number in the original list mapped_list = list(map(lambda x: x*2 , original_list)) print('New List : ',mapped_list)- 1
- 2
- 3
- 4
- 5
#首字母大写 original_list = ['analytics','vidhya','king','south','east'] # capatilize first letter of each word in the original list mapped_list = list(map(lambda x: x[0].upper()+x[1:] , original_list)) print('New List : ',mapped_list)- 1
- 2
- 3
- 4
- 5
*Map 函数简介:
map是python内置函数,会根据提供的函数对指定的序列做映射。格式是
map(function,iterable,...)
第一个参数接受一个函数名,后面的参数接受一个或多个可迭代的序列,返回的是一个集合。把函数依次作用在list中的每一个元素上,得到一个新的list并返回。注意,map不改变原list,而是返回一个新list。
比如:del square(x): return x ** 2 map(square,[1,2,3,4,5]) # 结果如下: [1,4,9,16,25]- 1
- 2
- 3
- 4
- 5
- 6
- 7
还可以实现类型转换 ,比如
map(int,(1,2,3)) # 结果如下: [1,2,3] #字符串转list map(int,'1234') # 结果如下: [1,2,3,4]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
判断内容并输出指定结果 : lambda+Map+if
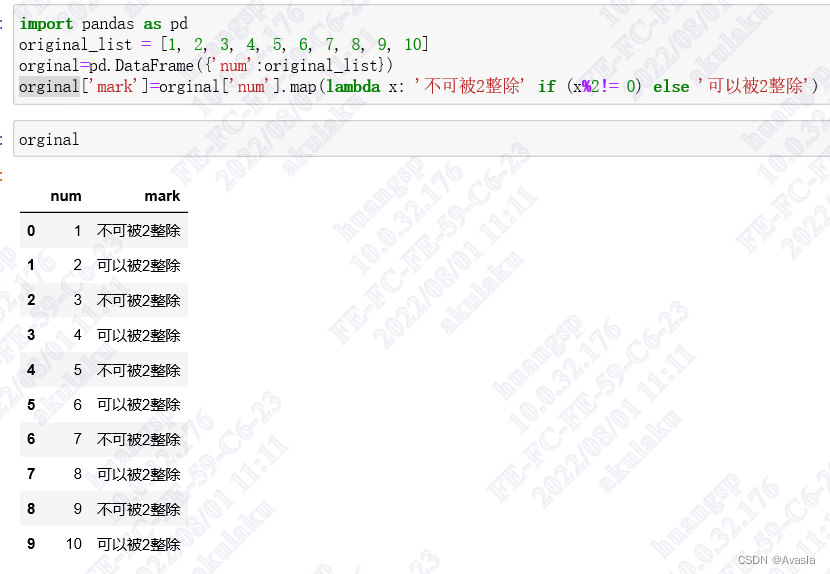
import pandas as pd original_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] orginal=pd.DataFrame({'num':original_list}) orginal['mark']=orginal['num'].map(lambda x: '不可被2整除' if (x%2!= 0) else '可以被2整除')- 1
- 2
- 3
- 4
累计、迭代运算:lambda + Reduce
# 求累加之和 from functools import reduce original_list = [1, 2, 3, 4, 5, 6, 7, 8, 9] # use reduce function to find the sum of numbers in the original list sum_of_list = reduce((lambda x, y : x + y), original_list) print ('Sum of Numbers in the original list is : ',sum_of_list) #找出最大值 original_list = [110, 53, 3, 424, 255, 16, 42, 256] # use reduce function to find the largest number in the original list largest_number = reduce((lambda x, y: x if (x > y) else y ), original_list) print ('Largest Number in the original list is : ',largest_number)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
*Reduce函数简介:
Reduce语法:
reduce(function,sequence[,initial]Print(help(reduce) ) 说明:
Help on built-in function reduce in module _functools:
reduce(…)
reduce(function, sequence[, initial]) -> value
Apply a function of two arguments cumulatively to the items of a sequence,
from left to right, so as to reduce the sequence to a single value.
For example, reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) calculates
((((1+2)+3)+4)+5). If initial is present, it is placed before the items
of the sequence in the calculation, and serves as a default when the
sequence is empty.(渣翻文本意思)根据传入的函数式子,按数列从左到右的顺序,不断迭代两个参数的累积值,直到最终输出单一值作为结果。
比如reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]), 就是计算((((1+2)+3)+4)+5).
第一轮:x=1,y=2 下一轮迭代结果:1+2=3
第二轮:x=3,y=3 下一轮迭代结果:3+3=6
第三轮:x=6,y=4 下一轮迭代结果:6+4=10
第四轮:x=10,y=5 下一轮迭代结果:10+5=15
第五轮:x=15, y 没有数了, 输出唯一值 :15

删除逗号、空格:map+lambda+replace
#删除逗号 df['column_name'] = df['column_name'].apply(lambda x: str(x).replace(",","")) ##删除空格 df[i] = df[i].apply(lambda x: str(x).replace(" ","")) #批量删除空格 c=['收/支', '支付方式', '当前状态', '交易类型', '账户'] #需要批量删除的列名 for i in c: df[i] = df[i].apply(lambda x: str(x).replace(" ",""))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
拆分单元格 :map+lambda+split
df['日期']=df['时间'].map(lambda x: x.split(' ')[0]) df['小时']=df['时间'].map(lambda x: x.split(' ')[1])- 1
- 2
-
相关阅读:
HarmonyOS开发(四):UIAbility组件
debian apt安装mysqlodbc
Linux 装机必备
Web自动化测试理解
TiDB x 北京银行丨新一代分布式数据库的探索与实践
基于restful页面数据交互(前端页面访问处理)
【datawhale202206】pyTorch推荐系统:多任务学习 ESMM&MMOE
虚拟DOM的发展趋势和潜在创新
【接口测试】Postman(二)-Postman Echo
字符串方法+ES6中字符串的方法
- 原文地址:https://blog.csdn.net/WHYbeHERE/article/details/125675632