-
spark:热门品类中每个品类活跃的SessionID统计TOP10(案例)
目录
介绍
session:服务器为了保存用户状态而创建的一个特殊的对象。
浏览器第一次访问服务器时,服务器创建一个session对象,该对象有一个唯一的id,一般称之为sessionId,服务器会将sessionId以cookie的方式发送给浏览器。当浏览器再次访问服务器时,会将sessionId发送过来,服务器依据sessionId就可以找到对应的session对象。
sessionID:用来判断是同一次会话。
服务器端的session只要还在同一个生命期内就还是同一次会话。
数据准备
点击链接下载数据(免费下载)
14万条用户行为数据,搜索、点击、下单、支付-spark文档类资源-CSDN下载
数据说明:
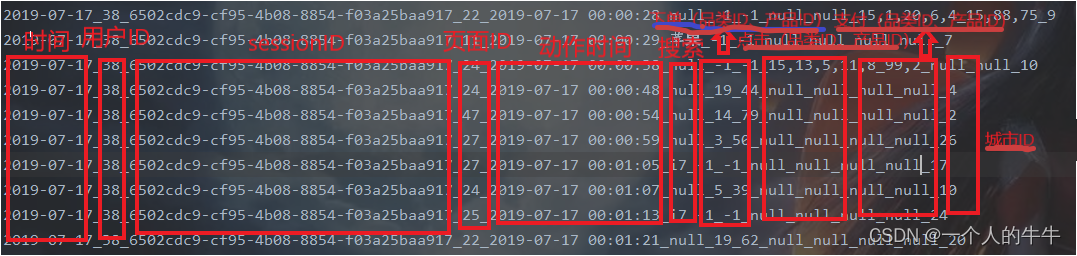
时间_用户ID_sessionID_页面ID_动作时间_搜索_点击(品类ID、产品ID)_下单(品类ID、产品ID)_支付(品类ID、产品ID)_城市ID
代码实现
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object TopTwo {
def main(args: Array[String]): Unit = {// TODO : 热门品类中每个品类的Session TOP10统计
val sparConf = new SparkConf().setMaster("local[*]").setAppName("TOP")
val sc = new SparkContext(sparConf)val actionRDD = sc.textFile("datas/action.txt")
actionRDD.cache()
val top10Ids: Array[String] = top10Category(actionRDD)//过滤原始数据,保留点击和前10品类ID
val filterActionRDD = actionRDD.filter(
action => {
val datas = action.split("_")
if ( datas(6) != "-1" ) {
top10Ids.contains(datas(6))
} else {
false
}
}
)
//根据品类ID和sessionid进行点击量的统计
val reduceRDD: RDD[((String, String), Int)] = filterActionRDD.map(
action => {
val datas = action.split("_")
((datas(6), datas(2)), 1)
}
).reduceByKey(_ + _)
//将统计的结果进行结构的转换
// (( 品类ID,sessionId ),sum) => ( 品类ID,(sessionId, sum) )
val mapRDD = reduceRDD.map{
case ( (cid, sid), sum ) => {
( cid, (sid, sum) )
}
}
//相同的品类进行分组
val groupRDD: RDD[(String, Iterable[(String, Int)])] = mapRDD.groupByKey()
//将分组后的数据进行点击量的排序,取前10名
val resultRDD = groupRDD.mapValues(
iter => {
iter.toList.sortBy(_._2)(Ordering.Int.reverse).take(10)
}
)resultRDD.collect().foreach(println)
sc.stop()
}
def top10Category(actionRDD:RDD[String]) = {
val flatRDD: RDD[(String, (Int, Int, Int))] = actionRDD.flatMap(
action => {
val datas = action.split("_")
if (datas(6) != "-1") {
// 点击的场合
List((datas(6), (1, 0, 0)))
} else if (datas(8) != "null") {
// 下单的场合
val ids = datas(8).split(",")
ids.map(id => (id, (0, 1, 0)))
} else if (datas(10) != "null") {
// 支付的场合
val ids = datas(10).split(",")
ids.map(id => (id, (0, 0, 1)))
} else {
Nil
}
}
)val analysisRDD = flatRDD.reduceByKey(
(t1, t2) => {
( t1._1+t2._1, t1._2 + t2._2, t1._3 + t2._3 )
}
)analysisRDD.sortBy(_._2, false).take(10).map(_._1)
}
}本文为学习笔记的记录
-
相关阅读:
web概述08
悟了!阿里p9专家强推的《java虚拟机并发编程》后悔没早看到!
vant的NavBar导航栏可以自定义背景图片吗
机器人连续位姿同步插值轨迹规划—对数四元数、b样条曲线、c2连续位姿同步规划
java开发工具MyEclipse 中实体关系设计器介绍
python之字典的用法
Crossover2022最新版虚拟机Mac和Linux系统兼容软件
Zorin OS 16.3 发布:无缝升级和卓越改进
xml转换成txt (VOC转换为YOLO)
Flutter 最佳实践 - 01
- 原文地址:https://blog.csdn.net/qq_55906442/article/details/126087838