-
【Transformer专题】一、Attention is All You Need(Transformer)
前言
一直都想好好整理下Transformer系列论文,刚好最近找工作,自己整理了一下。
Transformer最开始的论文来自这篇链接: Attention Is All You Need。这篇论文首次将Transformer用在NLP任务中的,而在下一篇的Vision Transformer会首次将Transformer用在视觉任务当中。我主要是想看如何将Transformer用在视觉任务中的,但是在这之前还是需要学习下什么是Transformer?Transformer怎么引入自注意力机制?
本文我不会按照论文里那样,将一堆的NLP知识,我会结合一些其他的博客和视频(结尾全部引用),尽量只讲原理,把模型讲清楚。
一、整体架构

可以看到整体架构:左边Encoder + 右边Decoder,且都包含N个(自己定义)模块,Encoder负责编码,Decoder负责解码。论文中更细节的结构:
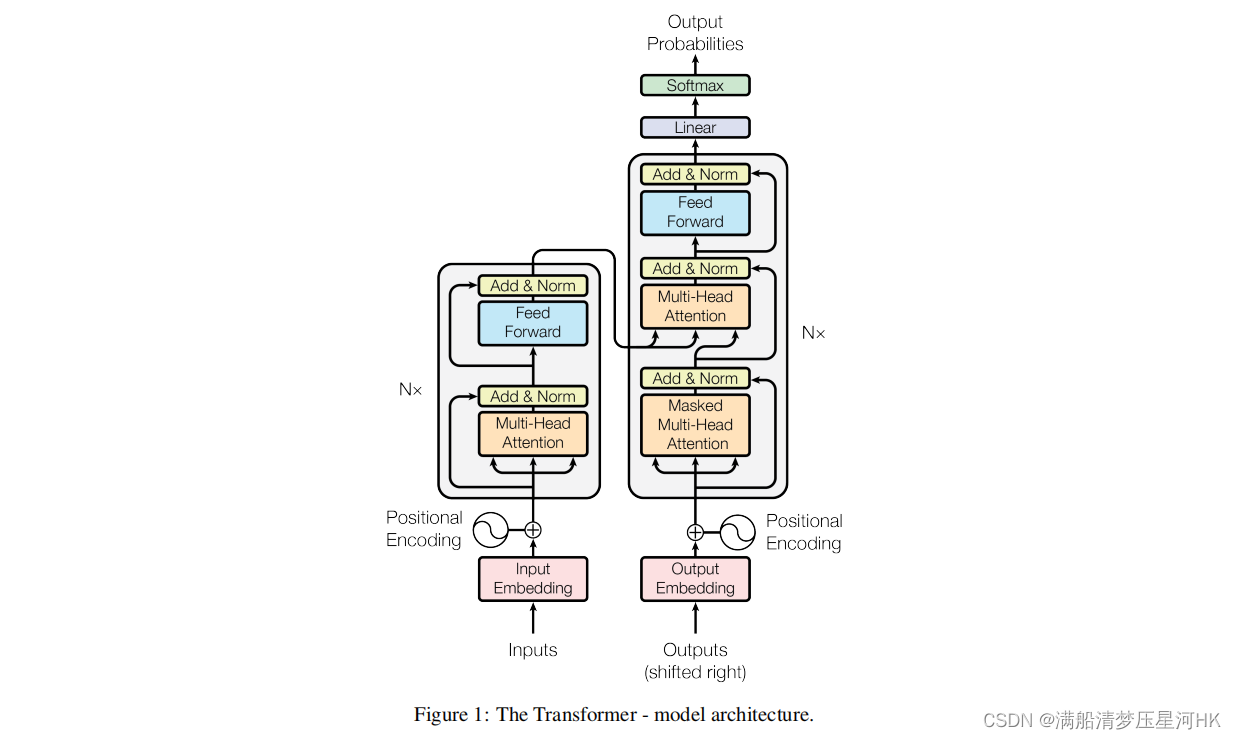
整体的工作流程:
- 将输入单词转为Embedding向量(每个单词转为512维度的Embedding向量)再和单词的位置信息的Embedding进行相加,得到Encoder的输入。
- 将输入的向量信息 X 传入Encoder中,通过6个encoder block得到句子中所以单词的编码信息矩阵 C 。
- 将Encoder输出的编码信息矩阵 C 传入Decoder模块,Decoder会根据当前翻译的位置1-i的单词,并掩盖(Mask)掉i+1后面的单词,来翻译位置i+1的单词。
二、Transfomer输入
把每个单词Embedding(512维)和位置Embedding(512维)相加起来,得到最终的Transformer的输入(512维)。
2.1、单词Embedding
单词Embedding:Word2Vec等方法将每个单词转为512维的向量;
2.2、位置Embedding
位置Embedding:因为Transformer不采用RNN的结构,而是采样全局的信息,需要并行进行计算,不是像RNN那样一个个单词依次计算,所以我们不光要知道每个单词的信息,还要知道每个单词的位置。所以Transformer还需要输入每个单词的位置信息。这里是使用Embedding来保存每个单词在序列中的相对或绝对位置。
Transformer中是使用正余弦公式来得到每个单词的位置信息(512维)的:

三、Self-Attention结构
3.1、Self-Attention QKV

Self-Attention的输入是Transformer的输入或者是上一个Encoder的输入 X ,X经过不同的线性变换得到矩阵Q(查询)、K(键值)、V(值)。得到Q、K、V之后就可以计算Self-Attention的输出值了。
-
计算QKV:将输入X分别乘以线性矩阵 W q W^q Wq、 W k W^k Wk、 W v W^v Wv得到Q、K、V,这里X、Q、K、V每一行都表示一个单词的信息。

-
计算Self-Attention输出:先计算Q和K的内积(Q乘以K的转置),得到Q K T K^T KT这个向量表示单词之间的attention强度,再除以 d k d_k dk的平方根,再softmax处理得到每个单词对于其他单词的attention系数。最后再和V相乘得到最终的输出Z。

补充几个问题:
A)点乘表示一个向量在另一个向量的投影长度,可以反应两个向量的相似度,两个向量越相似,他的点乘结果越大,而且点乘计算速度非常快。
B)除以 d k d_k dk的平方根,一个是为了防止内积过大,输入softmax导致梯度消失;另一个是为了让输入softmax的数是方差为1的;
3.2、Multi-Head Attention
多头注意力机制:

得到QKV之后再经过多个注意力机制,得到多套注意力结果Z1-Z8,再对其进行Concat,然后传入一个线性层,得到最终的多头注意力机制的输出结果Z。

原因:将输入映射到多个空间上,可以捕获单词之间多个维度上的相关系数 attention score四、Encoder

一个Encode:多头注意力机制 + Add & Norm + Feed Forward + Add & Norm上面已经介绍完了多头注意力部分,下面介绍下Add & Norm 和 Feed Forward部分
4.1、Add & Norm
Add:指 X+MultiHeadAttention(X),是一种残差连接,通常用于解决多层网络训练退化问题;
Norm:指 Layer Normalization,通常用于 RNN 结构,Layer Normalization 会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛;

4.2、Feed Forward
Feed Forward 层比较简单,是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,对应的公式如下:
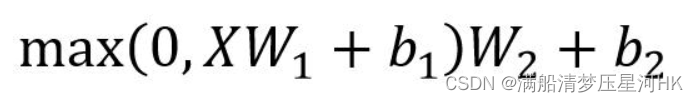
五、Decoder
Decoder是机器翻译的内容,我们视觉的Transformer主要是取了Transformer的Encoder部分,所以下面的内容我没看的多仔细,随便看了下。
Decoder也是由6个decoder block组成,如下图:

和Encoder相比有两个不同点:- Multi-Head Attention 变成了 Masked Multi-Head Attention:在翻译第i个单词的时候,要遮盖Masked第i个单词之后的所有单词,防止第i个单词知道后面的代词的信息。防止训练和测试存在gap。
- 中间多了一个交互层:Multi-Head Attention + Add & Norm

最后的部分是接一个Softmax 预测单词。
Reference
-
相关阅读:
进制转换.
5.zigbee的开发,串口putchar重定向(使用print),单播实验,usb抓包实验
英语四六级高频核心词(故事版)
接口测试是什么?怎样做接口测试?(测试人必看,讲的超详细)
C#开发的OpenRA游戏之金钱系统(4)
springboot基于itextpdf将html生成pdf
想要精通算法和SQL的成长之路 - 滑动窗口和大小根堆
【硬件架构的艺术】学习笔记(2)同步和复位
好奇喵 | Tor浏览器——层层剥开洋葱
微信小程序uniapp+django+python的酒店民宿预订系统ea9i3
- 原文地址:https://blog.csdn.net/qq_38253797/article/details/126075200