-
深度学习实战(1):花的分类任务
写在前面:
实验目的:通过建立Alexnet神经网络建立模型并根据训练数据来训练模型 以达到可以将一张花的类别进行分类
Python版本:Python3
IDE:VSCode
系统:MacOS
数据集以及代码的资源放在文章末尾了 有需要请自取~

目录
前言
本文仅作为学习训练 不涉及任何商业用途 如有错误或不足之处还请指出
数据集
数据集一共有五种花的类别 但本次实验模型仅用了rose和sunflower两种类别进行分类测试
五种花的类别:

Rose:

Sunflower:

训练模型代码 (附有注释)
- import os , glob
- from sklearn.model_selection import train_test_split
- import tensorflow as tf
- from tensorflow import keras
- from tensorflow.keras import layers
- import matplotlib.pyplot as plt
- # 变量
- resize = 224 # 图片尺寸参数
- epochs = 8 # 迭代次数
- batch_size = 5 # 每次训练多少张
- #——————————————————————————————————————————————————————————————————————————————————
- # 训练集路径
- train_data_path = '/Users/liqun/Desktop/KS/MyPython/DataSet/flowers/Training'
- # 玫瑰花文件夹路径
- rose_path = os.path.join(train_data_path,'rose')
- # 太阳花文件夹路径
- sunflower_path = os.path.join(train_data_path,'sunflower')
- # 将文件夹内的图片读取出来
- fpath_rose = [os.path.abspath(fp) for fp in glob.glob(os.path.join(rose_path,'*.jpg'))]
- fpath_sunflower = [os.path.abspath(fp) for fp in glob.glob(os.path.join(sunflower_path,'*.jpg'))]
- #文件数量
- num_rose = len(fpath_rose)
- num_sunflower = len(fpath_sunflower)
- # 设置标签
- label_rose = [0] * num_rose
- label_sunflower = [1] * num_sunflower
- # 展示
- print('rose: ', num_rose)
- print('sunflower: ', num_sunflower)
- # 划分为多少验证集
- RATIO_TEST = 0.1
- num_rose_test = int(num_rose * RATIO_TEST)
- num_sunflower_test = int(num_sunflower * RATIO_TEST)
- # train
- fpath_train = fpath_rose[num_rose_test:] + fpath_sunflower[num_sunflower_test:]
- label_train = label_rose[num_rose_test:] + label_sunflower[num_sunflower_test:]
- # validation
- fpath_vali = fpath_rose[:num_rose_test] + fpath_sunflower[:num_sunflower_test]
- label_vali = label_rose[:num_rose_test] + label_sunflower[:num_sunflower_test]
- num_train = len(fpath_train)
- num_vali = len(fpath_vali)
- # 展示
- print('num_train: ', num_train)
- print('num_label: ', num_vali)
- # 预处理函数
- def preproc(fpath, label):
- image_byte = tf.io.read_file(fpath) # 读取文件
- image = tf.io.decode_image(image_byte) # 检测图像是否为BMP,GIF,JPEG或PNG,并执行相应的操作将输入字节string转换为类型uint8的Tensor
- image_resize = tf.image.resize_with_pad(image, 224, 224) #缩放到224*224
- image_norm = tf.cast(image_resize, tf.float32) / 255. #归一化
- label_onehot = tf.one_hot(label, 2)
- return image_norm, label_onehot
- dataset_train = tf.data.Dataset.from_tensor_slices((fpath_train, label_train)) #将数据进行预处理
- dataset_train = dataset_train.shuffle(num_train).repeat() #打乱顺序
- dataset_train = dataset_train.map(preproc, num_parallel_calls=tf.data.experimental.AUTOTUNE)
- dataset_train = dataset_train.batch(batch_size).prefetch(tf.data.experimental.AUTOTUNE) #一批次处理多少份
- dataset_vali = tf.data.Dataset.from_tensor_slices((fpath_vali, label_vali))
- dataset_vali = dataset_vali.shuffle(num_vali).repeat()
- dataset_vali = dataset_vali.map(preproc, num_parallel_calls=tf.data.experimental.AUTOTUNE)
- dataset_vali = dataset_vali.batch(batch_size).prefetch(tf.data.experimental.AUTOTUNE)
- #——————————————————————————————————————————————————————————————————————————————————
- # 建立模型 卷积神经网络
- model = tf.keras.Sequential(name='Alexnet')
- # 第一层
- model.add(layers.Conv2D(filters=96, kernel_size=(11,11),
- strides=(4,4), padding='valid',
- input_shape=(resize,resize,3),
- activation='relu'))
- model.add(layers.BatchNormalization())
- # 第一层池化层:最大池化层
- model.add(layers.MaxPooling2D(pool_size=(3,3),
- strides=(2,2),
- padding='valid'))
- #第二层
- model.add(layers.Conv2D(filters=256, kernel_size=(5,5),
- strides=(1,1), padding='same',
- activation='relu'))
- model.add(layers.BatchNormalization())
- #第二层池化层
- model.add(layers.MaxPooling2D(pool_size=(3,3),
- strides=(2,2),
- padding='valid'))
- #第三层
- model.add(layers.Conv2D(filters=384, kernel_size=(3,3),
- strides=(1,1), padding='same',
- activation='relu'))
- #第四层
- model.add(layers.Conv2D(filters=384, kernel_size=(3,3),
- strides=(1,1), padding='same',
- activation='relu'))
- #第五层
- model.add(layers.Conv2D(filters=256, kernel_size=(3,3),
- strides=(1,1), padding='same',
- activation='relu'))
- #池化层
- model.add(layers.MaxPooling2D(pool_size=(3,3),
- strides=(2,2), padding='valid'))
- #第6,7,8层
- model.add(layers.Flatten())
- model.add(layers.Dense(4096, activation='relu'))
- model.add(layers.Dropout(0.5))
- model.add(layers.Dense(4096, activation='relu'))
- model.add(layers.Dropout(0.5))
- model.add(layers.Dense(1000, activation='relu'))
- model.add(layers.Dropout(0.5))
- # Output Layer
- model.add(layers.Dense(2, activation='softmax'))
- # Training 优化器 随机梯度下降算法
- model.compile(loss='categorical_crossentropy',
- optimizer='sgd', #梯度下降法
- metrics=['accuracy'])
- history = model.fit(dataset_train,
- steps_per_epoch = num_train//batch_size,
- epochs = epochs, #迭代次数
- validation_data = dataset_vali,
- validation_steps = num_vali//batch_size,
- verbose = 1)
- # 评分标准
- scores_train = model.evaluate(dataset_train, steps=num_train//batch_size, verbose=1)
- print(scores_train)
- scores_vali = model.evaluate(dataset_vali, steps=num_vali//batch_size, verbose=1)
- print(scores_vali)
- #保存模型
- model.save('/Users/liqun/Desktop/KS/MyPython/project/flowerModel.h5')
- '''
- history对象的history内容(history.history)是字典类型,
- 键的内容受metrics的设置影响,值的长度与epochs值一致。
- '''
- history_dict = history.history
- train_loss = history_dict['loss']
- train_accuracy = history_dict['accuracy']
- val_loss = history_dict['val_loss']
- val_accuracy = history_dict['val_accuracy']
- # Draw loss
- plt.figure()
- plt.plot(range(epochs), train_loss, label='train_loss')
- plt.plot(range(epochs), val_loss, label='val_loss')
- plt.legend()
- plt.xlabel('epochs')
- plt.ylabel('loss')
- # Draw accuracy
- plt.figure()
- plt.plot(range(epochs), train_accuracy, label='train_accuracy')
- plt.plot(range(epochs), val_accuracy, label='val_accuracy')
- plt.legend()
- plt.xlabel('epochs')
- plt.ylabel('accuracy')
- # Display
- plt.show()
- print('Train has finished')
训练集数据量展示

训练迭代过程展示

训练结果 Accuracy展示

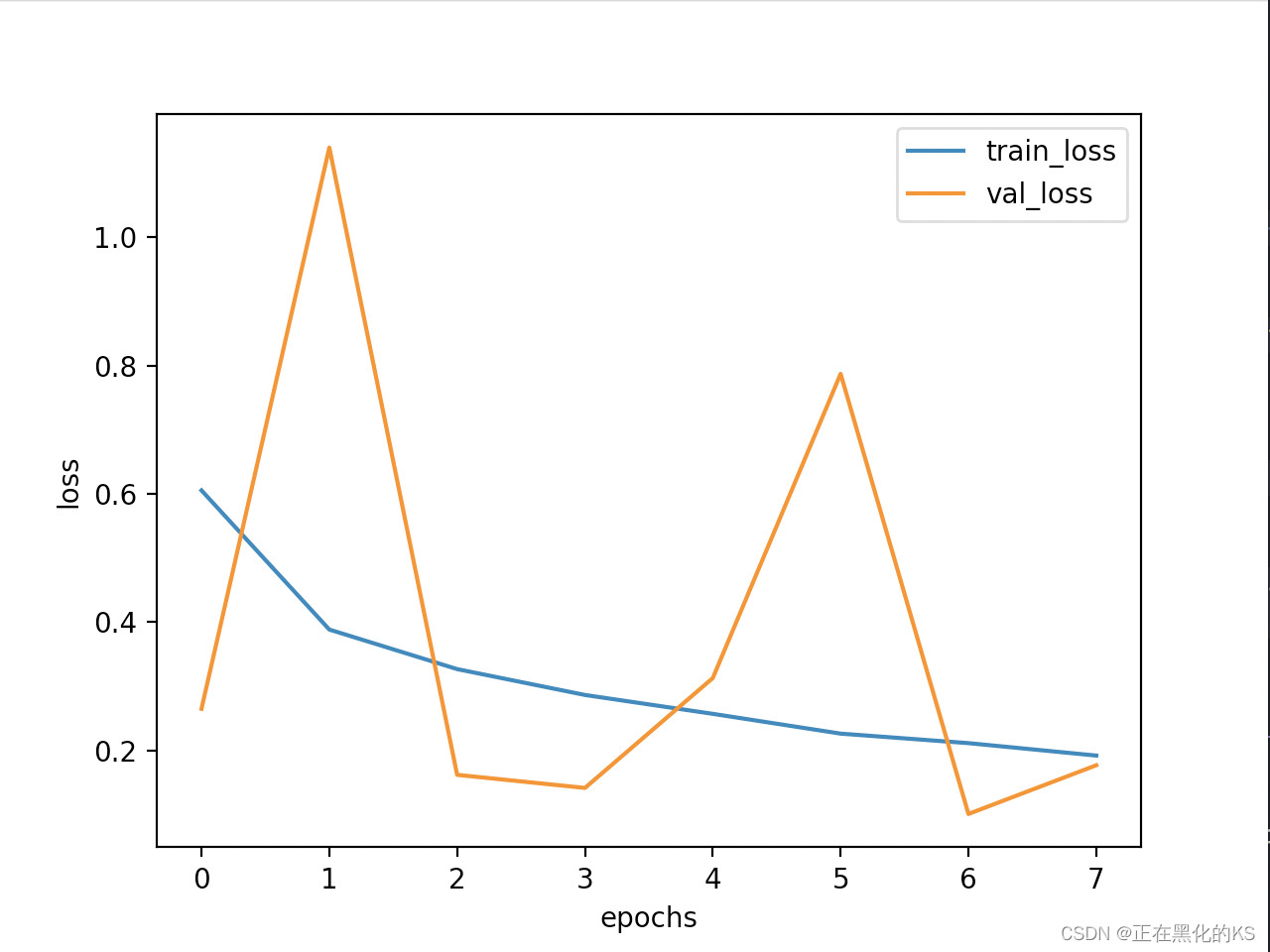
训练结果 Loss展示
测试集


预测结果代码
- import cv2
- from tensorflow.keras.models import load_model
- resize = 224
- label = ('rose', 'sunflower')
- image = cv2.resize(cv2.imread('/Users/liqun/Desktop/KS/MyPython/DataSet/flowers/Training/sunflower/23286304156_3635f7de05.jpg'),(resize,resize))
- image = image.astype("float") / 255.0 # 归一化
- image = image.reshape((1, image.shape[0], image.shape[1], image.shape[2]))
- # 加载模型
- model = load_model('/Users/liqun/Desktop/KS/MyPython/project/flowerModel.h5')
- predict = model.predict(image)
- i = predict.argmax(axis=1)[0]
- # 展示结果
- print('——————————————————————')
- print('Predict result')
- print(label[i],':',max(predict[0])*100,'%')
预测结果展示

结语
模型到这里就训练并检测完毕了 如有需要的小伙伴可以下载下方的数据集测试集及源代码
链接: https://pan.baidu.com/s/1OJfwcF1PvX9qkZwT7MXd_Q?pwd=i0bt 提取码: i0bt
如果我的文章对你有帮助 麻烦点个赞再走呀
-
相关阅读:
算法训练 第八周
3.1_2 覆盖与交换
【vue】牛客专题训练01
MySql安全加固:无关或匿名帐号&是否更改root用户&避免空口令用户&是否加密数据库密码
【前端】CSS
园子开店记:被智能的淘宝处罚,说是“预防性的违规”
易基因|RNA m6A甲基化测序(MeRIP-seq)技术介绍
vscode终端npm install报错
创建个人github.io主页(基础版)//吐槽:很多国内教程已经失效了
Eureka: Netflix开源的服务发现框架
- 原文地址:https://blog.csdn.net/m0_54689021/article/details/126075918
