-
机器学习基本概念
基本概念
机器学习就是去寻找一个复杂的函数
深度学习:找一个函数,这个函数用类神经网络表示函数的输入可以是一个向量、矩阵(images)、序列(语音)
输出可以是一个数(regression)、可以是一个类别(分类)、文本、画图等课程任务
- Supervised Learning (监督学习)
- Self-supervised Learning (自监督学习)
- Generative Adversarial Network (生成对抗网络)
- Reinforcement Learning (强化学习)
- Anomaly Detection (异常检测)
- Explainable AI (可解释性 AI)
- Model Attack (模型攻击)
- Domain Adaptation (域自适应)
- Network Compression (让模型变小)
- Life-long Learning (终身学习)
- Meta learning (学习如何学习)
机器学习的步骤
1. Function with Unknown Parameters
y = b + w x 1 y = b + wx_1 y=b+wx1
y y y:预测的值
x x x:feature
w w w:weight
b b b:bias
Model:在机器学习里面就是指带参数的函数2. Define Loss from Training Data
Loss:是一个带参函数
输入: b b b 和 w w w
输出:代表某一组 b b b 和 w w w 好还是不好
L ( b , w ) L(b, w) L(b,w)例:求 L ( 0.5 k , 1 ) L(0.5k, 1) L(0.5k,1)
y = b + w x 1 y = b + wx_1 y=b+wx1 = = > ==> ==> y = 0.5 k + 1 x 1 y = 0.5k + 1x_1 y=0.5k+1x1
假如带入后求得的 y = 5.3 k y=5.3k y=5.3k 而实际的 y ^ = 4.9 k \hat{y} = 4.9k y^=4.9k (label)
e 1 = ∣ y − y ^ ∣ = 0.4 k e_1 = |y - \hat{y}| = 0.4k e1=∣y−y^∣=0.4k
e 2 , e 3 , . . . e n e_2, e_3,...e_n e2,e3,...en都可以这样计算
Loss: L = 1 N ∑ n e n L = \frac{1}{N}\sum_{n}e_n L=N1n∑en越小代表这一组参数越好。
有多种计算方式:
MAE(mean absolute error): e = ∣ y − y ^ ∣ e = |y - \hat{y}| e=∣y−y^∣
MSE(mean square error): e = ( y − y ^ ) 2 e = (y - \hat{y})^2 e=(y−y^)2
cross-entropy根据 w w w 和 b b b 画出的 L o s s Loss Loss 的等高线图叫做 Error Surface(二维)
3. Optimization
目的:找最好的 w w w 和 b b b
Optimization的方法:Gradient Descent
先给出 L o s s Loss Loss 与 w w w 的变化图 (Error Surface 一维)
步骤:
- Pick an initial value W 0 W^0 W0
- 对此时的 w w w 求导(算微分):计算切线斜率
- 更新 w w w
- 反复上面的操作
可能出现局部最优解(Local minima)
切线斜率负的:切线左高右低,所以如果应该向右边前进(w = w - 学习率 * 斜率)
决定步长的因素有两个:
- 斜率(斜率越大步长越大)
- 学习率(自己设置的一个参数)
hyperparameters:需要自己设定的参数

推广到 w w w 和 b b b

二维图上:
可以发现
点击量y y y 的波动具有周期性,所以可以对函数进行推广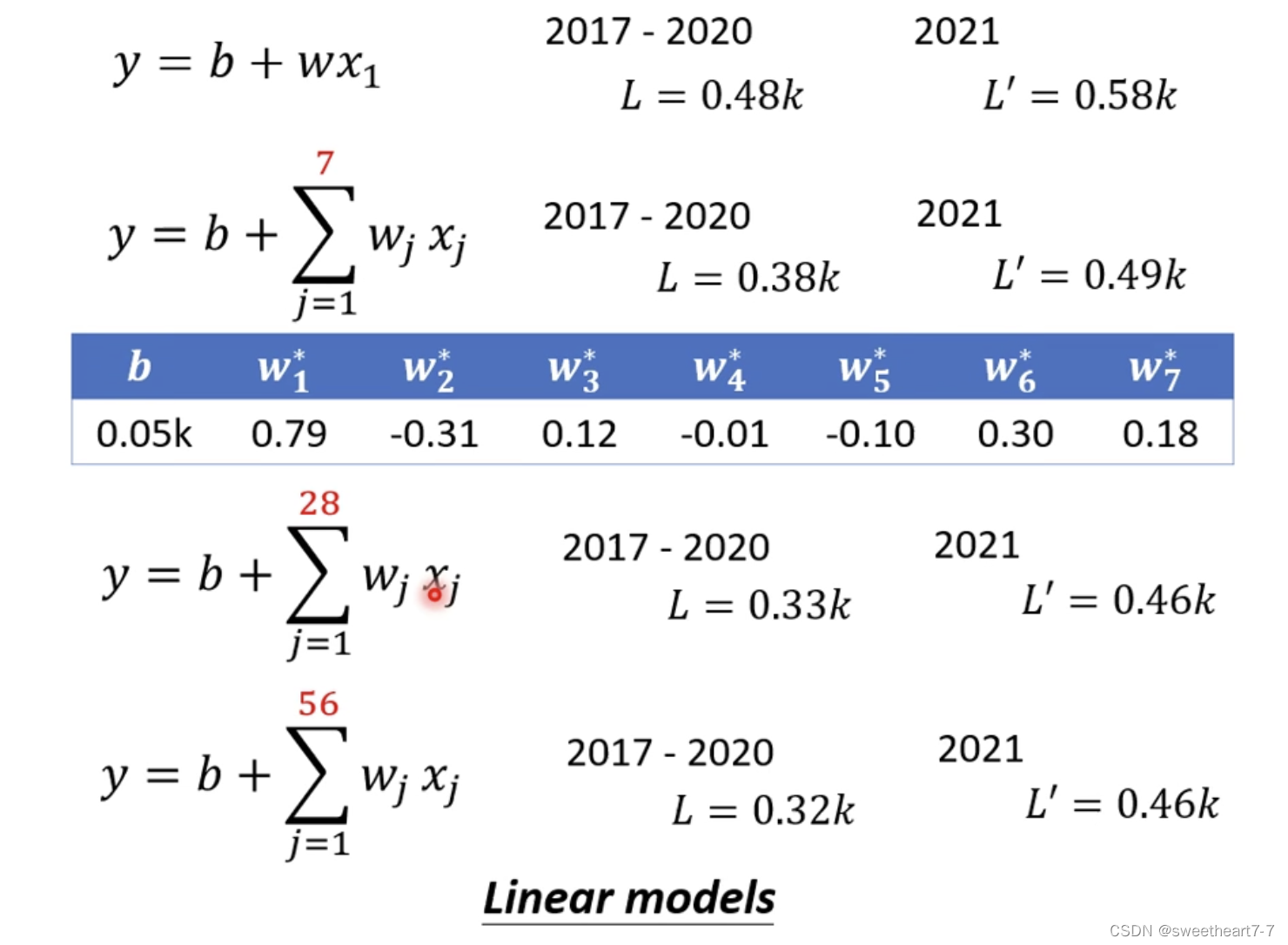
上面这些模型统称为 Linear models
-
相关阅读:
远程过程调用RPC 5:Dubbo路由
pyinstaller打包教程及问题处理
奔跑的大学生
【Pandas数据处理100例】(九十六):Pandas使用cumsum()函数计算某列的累计和
c++之常量引用
VoLTE端到端业务详解 | S1AP协议
三星大规模生产3nm芯片?预计明年就能流通各大手机厂商手中
软考 系统架构设计师 简明教程 | 软件开发模型
GBase8s数据库INTO TEMP 子句创建临时表来保存查询结果。
Typora收费?搭建VS Code MarkDown写作环境
- 原文地址:https://blog.csdn.net/qq_46456049/article/details/126058785