-
1. 获取数据-requests.get()
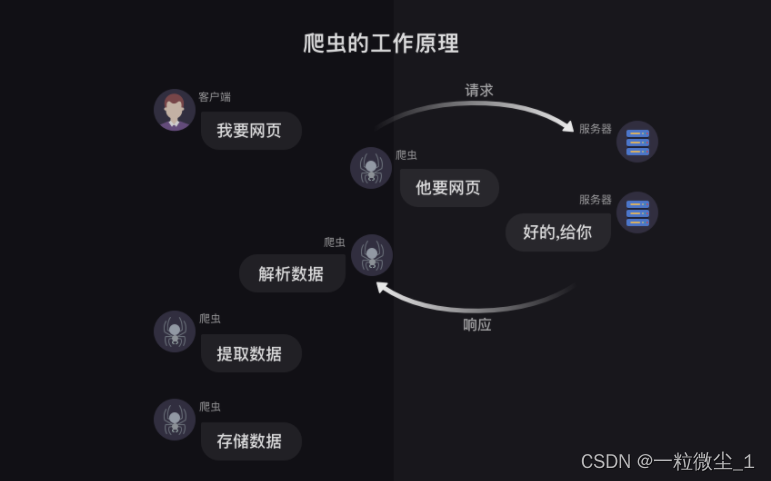
1、爬虫的工作原理
获取数据–解析数据–提取数据–存储数据
2、获取数据
本质就是通过URL去向服务器发出请求,服务器再把相关内容封装成一个Response对象返回给我们,这是通过requests.get()实现的。而我们获取到的Response对象下有四个常用的方法(status_code、content、text、encoding)。
3、requests.get()
import requests #引入requests模块
res = requests.get(‘url’) # 向服务器请求数据,服务器返回的结果是个Response对象
print(type(res)) # 终端显示:
这代表着res是一个对象,属于requests.models.Response类。
3、response.status_code
用法:print(变量.status_code),
用来检查请求是否正确响应,如果响应状态码为200,即代表请求成功。
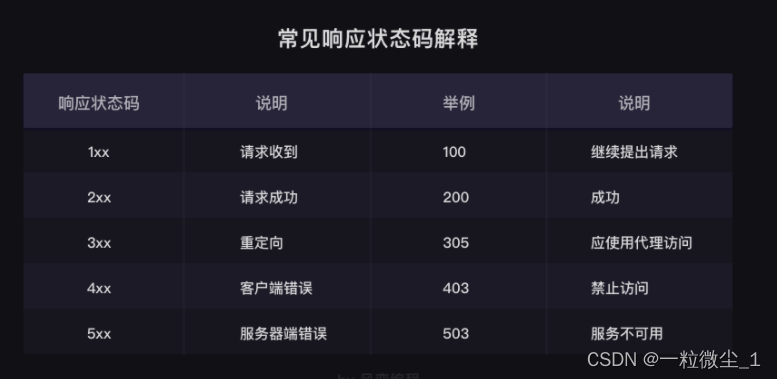
响应状态码表示服务器对请求的响应结果。例如,200代表服务器响应成功,403代表禁止访问,404代表页面未找到,408代表请求超时。浏览器会根据状态码做出相应的处理。在爬虫中,可以根据状态码来判断服务器的状态,如果状态码为200,则继续处理数据,否则直接忽略。
4、response.content
response.content能把Response对象的内容以二进制数据的形式返回,适用于图片、音频、视频的下载,示例:
import requests
#图片地址
URL=‘‘https://img1.baidu.com/it/u=2076064484,1314795796&fm=253&fmt=auto&app=120&f=JPEGw=531&h=309’’发出请求,并把返回的结果放在变量res中
res = requests.get(url)
# 把Reponse对象的内容以二进制数据的形式返回
pic = res.content# 下载一个图片文件并命名为picture.jpg, 图片内容需要以二进制wb只写。
with open(r’C:UsersAveryDesktop estpicture.jpg’, ‘wb’) as f:获取pic的二进制内容,写入f
f.write(pic)
这样我们图片就下载成功了!
5、response.text
response.text这个方法可以把Response对象的内容以字符串的形式返回,适用于文字、网页源代码的下载。示例如下:
import requests
文章地址
url = ‘https://localprod.pandateacher.com/python-manuscript/crawler-html/sanguo.md’
发出请求,并把返回的结果放在变量res中
res = requests.get(url)
# 把Response对象的内容以字符串的形式返回
novel = res.text
#打印变量
print(novel[0:170])6、response.encoding
response.encoding方法,它能帮我们定义Response对象的编码,示例如下:
import requests
文章地址
url = ‘https://localprod.pandateacher.com/python-manuscript/crawler-html/sanguo.md’
发出请求,并把返回的结果放在变量res中
res = requests.get(url)
# 定义response对应的编码为utf-8
res.encoding = ‘utf-8’把Response对象的内容以字符串的形式返回
novel = res.text
打印变量
print(novel[0:170])
先自我介绍一下,小编13年上师交大毕业,曾经在小公司待过,去过华为OPPO等大厂,18年进入阿里,直到现在。深知大多数初中级java工程师,想要升技能,往往是需要自己摸索成长或是报班学习,但对于培训机构动则近万元的学费,着实压力不小。自己不成体系的自学效率很低又漫长,而且容易碰到天花板技术停止不前。因此我收集了一份《java开发全套学习资料》送给大家,初衷也很简单,就是希望帮助到想自学又不知道该从何学起的朋友,同时减轻大家的负担。添加下方名片,即可获取全套学习资料哦
-
相关阅读:
麦芽糖-链霉亲和素maltose-Streptavidins链霉亲和素-PEG-麦芽糖
【无标题】
数据推荐 | 自然场景OCR文字识别数据集一览
Vue 3 父子组件互调方法 - setup 语法糖写法
“远程“操作oracle数据泵impdp、expdp导入导出
如何开手续费最低且正规的期货帐户
Day 50 | 123. 买卖股票的最佳时机 III & 188. 买卖股票的最佳时机 IV
无监督学习的集成方法:相似性矩阵的聚类
echarts实现横轴刻度名倾斜展示,并且解决文字超出部分消失问题
人工智能AI 全栈体系(三)
- 原文地址:https://blog.csdn.net/m0_54861649/article/details/126069843