-
MySQL六脉神剑,SQL通关大总结
???
哈喽!大家好,我是【】,江湖人称jeames007,10年DBA工作经验
一位上进心十足的【大数据领域博主】!???
中国DBA联盟(ACDU)成员,目前从事DBA及程序编程
擅长主流数据Oracle、MySQL、PG 运维开发,备份恢复,安装迁移,性能优化、故障应急处理等。
如果有对【数据库】感兴趣的【小可爱】,欢迎关注【】???
感谢各位大可爱小可爱!文章目录
前言
应粉丝需求,近期总结了下MySQL篇的SQL通关总结,分享给给为,祝大家考试,日常工作得心应手
?? 1.什么是SQL
?? 1.1 SQL起源

?? SQL起源科普
SQL是由IBM公司在1974~1979年之间根据E.J.Codd发表的关系数据库理论为基础开发的,其前身是“SEQUEL”,后更名为SQL。由于SQL语言具有集数据查询、数据操纵、数据定义和数据控制功能于一体,类似自然语言、简单易用以及非过程化等特点,得到了快速的发展,并于1986年10月,被美国国家标准协会(American National Standards Institute,ANSI)采用为关系数据库管理系统的标准语言,后为国际标准化组织(International Organization for Standardization,ISO)采纳为国际标准。?? 1.2 SQL分类
SQL(Structured Query Language)是结构化查询语言的简称,它是一种数据库查询和程序设计语言,同时也是目前使用最广泛的关系型数据库操作语言。在数据库管理系统中,使用SQL语言来实现数据的存取、查询、更新等功能。SQL是一种非过程化语言,只需要提出“做什么”,而不需要指明“怎么做”。
?? SQL语言分为五个部分:

① 数据查询语言(Data Query Language,DQL):
DQL主要用于数据的查询,其基本结构是使用SELECT子句,
FROM子句和WHERE子句的组合来查询一条或多条数据。
② 数据操作语言(Data Manipulation Language,DML):
DML主要用于对数据库中的数据进行增加、修改和删除的操作,其主要包括:
INSERT:增加数据
UPDATE:修改数据
DELETE:删除数据
③ 数据定义语言(Data Definition Language,DDL):
DDL主要用针对是数据库对象(表、索引、视图、>触发器、存储过程、函数、表空间等)进行创建、修改和删除操作。其主要包括:
CREATE:创建数据库对象
ALERT:修改数据库对象
DROP:删除数据库对象
④ 数据控制语言(Data Control Language,DCL):
DCL用来授予或回收访问数据库的权限,其主要包括:
GRANT:授予用户某种权限
REVOKE:回收授予的某种权限
事务控制语言(Transaction Control Language,TCL):
⑤ TCL用于数据库的事务管理。其主要包括:
START TRANSACTION:开启事务
COMMIT:提交事务
ROLLBACK:回滚事务
SET TRANSACTION:设置事务的属性?? 2.DQL数据查询
?? 2.1 语法介绍
?? 语法格式:
?? 加中括号的部分可以省略
SELECT
[ALL|DISTINCT]
<目标列的表达式1> [别名],
<目标列的表达式2> [别名]…
FROM <表名或视图名> [别名], <表名或视图名> [别名]…
[WHERE <条件表达式>]
[GROUP BY <列名>]
[HAVING <条件表达式>]
[ORDER BY <列名> [ASC|DESC]]
[LIMIT <数字或列表>];?? 精简版格式:
SELECT *| 列名 FROM 表 WHERE 条件;
?? 2.2 简单查询
2.2.1 检索数据
我们需要通过下面的代码创建一个表,而后录入一些数据,示例代码及数据表示例如下:
DROP TABLE IF EXISTS
Customers;
CREATE TABLE IF NOT EXISTSCustomers(
cust_id VARCHAR(255) NOT NULL COMMENT ‘客户id’,
cust_name VARCHAR(255) NOT NULL COMMENT ‘客户姓名’
);
INSERTCustomers
VALUES (‘a1’,‘andy’),
(‘a2’,‘ben’),
(‘a3’,‘tony’),
(‘a4’,‘tom’),
(‘a5’,‘an’),
(‘a6’,‘lee’),
(‘a7’,‘hex’);案例 1 现在有Customers 表,返回所有列
?? 答案如下: mysql> select * from Customers; +---------+-----------+ | cust_id | cust_name | +---------+-----------+ | a1 | andy | | a2 | ben | | a3 | tony | | a4 | tom | | a5 | an | | a6 | lee | | a7 | hex | +---------+-----------+ 7 rows in set (0.00 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
案例 2 现在有Customers 表,只返回客户姓名(cust_name)列
?? 答案如下: mysql> select * from Customers; +-----------+ | cust_name | +-----------+ | andy | | ben | | tony | | tom | | an | | lee | | hex | +---------+-----------+ 7 rows in set (0.00 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2.2.2 别名查询
我们需要通过下面的代码创建一个表,而后录入一些数据,示例代码及数据表示例如下:
DROP TABLE IF EXISTS
Vendors;
CREATE TABLE IF NOT EXISTSVendors(
vend_idVARCHAR(255) NOT NULL COMMENT ‘供应商id’,
vend_nameVARCHAR(255) NOT NULL COMMENT ‘供应商名称’,
vend_addressVARCHAR(255) NOT NULL COMMENT ‘供应商地址’,
vend_cityVARCHAR(255) NOT NULL COMMENT ‘供应商城市’
);
INSERT INTOVendorsVALUES (‘a001’,‘tencent cloud’,‘address1’,‘shenzhen’),
(‘a002’,‘huawei cloud’,‘address2’,‘dongguan’),
(‘a003’,‘aliyun cloud’,‘address3’,‘alibaba’);案例 1 编写 SQL 语句,从 Vendors 表中检索vend_id、vend_name、vend_address 和 vend_city,
将 vend_name重命名为 vname,将 vend_city 重命名为 vcity,
将 vend_address重命名为 vaddress?? 答案如下: mysql> select vend_id, vend_name as vname, vend_address as vaddress, vend_city as vcity from Vendors; +---------+---------------+----------+----------+ | vend_id | vname | vaddress | vcity | +---------+---------------+----------+----------+ | a003 | aliyun cloud | address3 | alibaba | | a002 | huawei cloud | address2 | dongguan | | a001 | tencent cloud | address1 | shenzhen | +---------+---------------+----------+----------+ 3 rows in set (0.00 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
?? 说明:
1.别名的常见用法是在检索出的结果中重命名表的列字段
2.表别名,一般用于多表查询中
3.列使用别名后,如果做排序,一定概要用别名
例:SELECT pname AS ‘商品名称’, price ‘商品价格’ FROM product order by 商品名称;2.2.3 去重查询
我们需要通过下面的代码创建一个表,而后录入一些数据,示例代码及数据表示例如下:
DROP TABLE IF EXISTS
OrderItems;
CREATE TABLE IF NOT EXISTSOrderItems(
prod_id VARCHAR(255) NOT NULL COMMENT ‘商品id’
);
INSERTOrderItemsVALUES (‘a1’),(‘a2’),(‘a3’),(‘a4’),(‘a5’),(‘a6’),(‘a6’);案例 1 编写SQL 语句,检索并列出所有已订购商品(prod_id)的去重后的清单
?? 答案如下: mysql> select distinct prod_id from OrderItems; +---------+ | prod_id | +---------+ | a1 | | a2 | | a3 | | a4 | | a5 | | a6 | +---------+ 6 rows in set (0.04 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2.2.4 运算查询
我们需要通过下面的代码创建一个表,而后录入一些数据,示例代码及数据表示例如下:
DROP TABLE IF EXISTS
Products;
CREATE TABLE IF NOT EXISTSProducts(
prod_idVARCHAR(255) NOT NULL COMMENT ‘产品 ID’,
prod_priceDOUBLE NOT NULL COMMENT ‘产品价格’
);
INSERT INTOProductsVALUES (‘a0011’,9.49),
(‘a0019’,600),
(‘b0019’,1000);案例 1 编写 SQL语句,从 Products 表中返回 prod_id、prod_price 和 sale_price。
sale_price 是一个包含促销价格的计算字段。
促销价格乘以 0.9,得到原价的 90%(即 10%的折扣)?? 答案如下: mysql> select prod_id, prod_price, prod_price*0.9 sale_price from Products; +---------+------------+------------+ | prod_id | prod_price | sale_price | +---------+------------+------------+ | a0011 | 9.49 | 8.541 | | a0019 | 600 | 540 | | b0019 | 1000 | 900 | +---------+------------+------------+ 3 rows in set (0.00 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
?? 说明:
通过MySQL运算符进行运算,就可以获取到表结构以外的另一种数据。
常用的算数运算符包括:加法、减法、乘法、除法及求余等
2.2.5 数据过滤
我们需要通过下面的代码创建一个表,而后录入一些数据,示例代码及数据表示例如下:
DROP TABLE IF EXISTS
Products;
CREATE TABLE IF NOT EXISTSProducts(
prod_idVARCHAR(255) NOT NULL COMMENT ‘产品 ID’,
prod_nameVARCHAR(255) NOT NULL COMMENT ‘产品名称’,
prod_priceDOUBLE NOT NULL COMMENT ‘产品价格’
);
INSERT INTOProductsVALUES (‘a0011’,‘egg’,3),
(‘a0019’,‘sockets’,4),
(‘b0019’,‘coffee’,15);案例 1 编写 SQL 语句,返回 Products 表中所有价格在 3 美元到 6 美元之间的产品的名称(prod_name)和价格(prod_price),然后按价格对结果进行排序
mysql> select prod_name,prod_price from Products where prod_price between 3 and 6 order by prod_price; +-----------+------------+ | prod_name | prod_price | +-----------+------------+ | egg | 3 | | sockets | 4 | +-----------+------------+ 2 rows in set (0.01 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
?? 说明:
数据过滤一般会用到比较运算符,常用的比较和逻辑运算符如下图所示
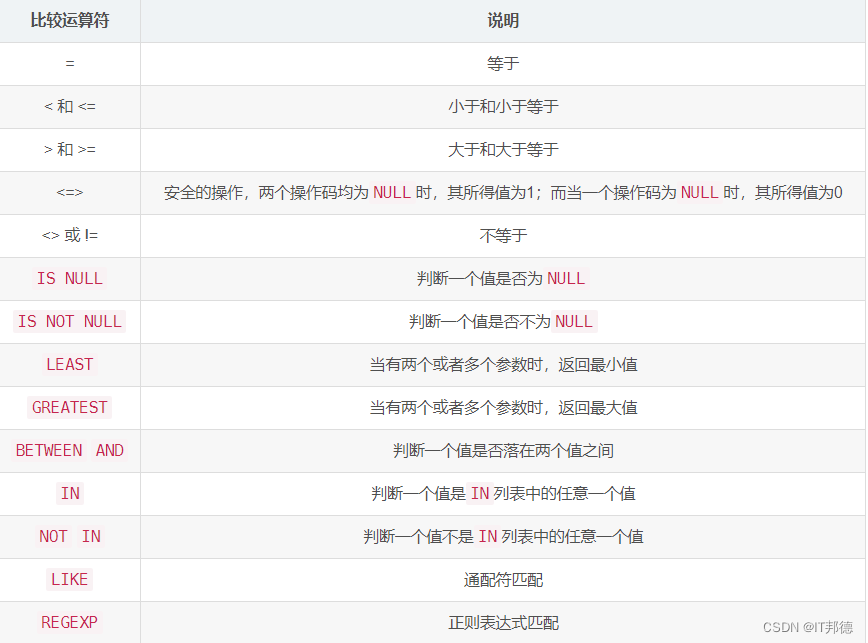
案例 2 列举常用的数据过滤?? 查询 score 表中成绩在 50-80 之间的所有行(区间查询和运算符查询)
SELECT * FROM score WHERE degree BETWEEN 50 AND 80;
SELECT * FROM score WHERE degree >= 60 AND degree <= 80;
?? 查询 student 表中 ‘95033’ 班或性别为 ‘女’ 的所有行
SELECT * FROM student WHERE class = ‘95033’ or sex = ‘女’;
?? 查询第二个字为’蔻’的所有商品
SELECT * FROM product WHERE pname like ‘_蔻%’;
?? 查询category_id 为 null 的商品
SELECT * FROM product WHERE category_id IS NULL;
?? 查询价格不是800的所有商品
SELECT * FROM product WHERE NOT(price = 800);2.2.6 排序查询
?? 语法格式:
SELECT
字段名1, 字段名2, …
FROM 表名
ORDER BY 字段名1 [asc|desc], 字段名2 [asc|desc]…我们需要通过下面的代码创建一个表,而后录入一些数据,示例代码及数据表示例如下:
CREATE TABLE student (
no VARCHAR(20) PRIMARY KEY,
name VARCHAR(20) NOT NULL,
sex VARCHAR(10) NOT NULL,
birthday DATE, – 生日
class VARCHAR(20) – 所在班级
);
INSERT INTO student VALUES(‘101’, ‘曾华’, ‘男’, ‘1977-09-01’, ‘95033’);
INSERT INTO student VALUES(‘102’, ‘匡明’, ‘男’, ‘1975-10-02’, ‘95031’);
INSERT INTO student VALUES(‘103’, ‘王丽’, ‘女’, ‘1976-01-23’, ‘95033’);
INSERT INTO student VALUES(‘104’, ‘李军’, ‘男’, ‘1976-02-20’, ‘95033’);
INSERT INTO student VALUES(‘105’, ‘王芳’, ‘女’, ‘1975-02-10’, ‘95031’);
INSERT INTO student VALUES(‘106’, ‘陆军’, ‘男’, ‘1974-06-03’, ‘95031’);
INSERT INTO student VALUES(‘107’, ‘王飘飘’, ‘男’, ‘1976-02-20’, ‘95033’);
INSERT INTO student VALUES(‘108’, ‘张全蛋’, ‘男’, ‘1975-02-10’, ‘95031’);
INSERT INTO student VALUES(‘109’, ‘赵铁柱’, ‘男’, ‘1974-06-03’, ‘95031’);案例 1 以 class 降序的方式查询 student 表的所有行
SELECT * FROM student ORDER BY class DESC;
案例 2 以class 降序、birthday 升序查询 student 表的所有行
SELECT * FROM student ORDER BY birthday ASC, class DESC;
?? 说明:
① asc 代表升序,desc 代表降序,不声明默认为升序;
② order by 用于子句可以支持单个字段,多个字段,表达式,函数,别名;
③ order by 子句放在查询语句最后面,LIMIT 子句除外。
④ 常用LIMIT使用如下:
SELECT s_no, c_no FROM score order by degree desc limit 1;
LIMIT r, n: 表示从第 r 行开始,查询 n 条数据
SELECT s_no, c_no, degree FROM score ORDER BY degree DESC LIMIT 0, 1;
LIMIT n offset r: 表示查询 n 条数据,从第 r 行开始
SELECT s_no, c_no, degree FROM score ORDER BY degree DESC LIMIT 1 offset 0;2.2.6 分组查询
?? 语法格式:
分组查询是指使用 group by 子句对查询信息进行分组。
相当于根据 group by 子句后的分组字段对表进行切分,相同字段的为一张表
SELECT 字段1, 字段2… FROM 表名 GROUP BY 分组字段 HAVING 分组条件;我们需要通过下面的代码创建一个表,而后录入一些数据,示例代码及数据表示例如下:
DROP TABLE IF EXISTS
Products;
CREATE TABLE IF NOT EXISTSProducts(
vend_idVARCHAR(255) NOT NULL COMMENT ‘供应商ID’,
prod_priceDOUBLE NOT NULL COMMENT ‘产品价格’
);
INSERT INTOProductsVALUES (‘a0011’,100),
(‘a0019’,0.1),
(‘b0019’,1000),
(‘b0019’,6980),
(‘b0019’,20);
DROP TABLE IF EXISTSOrderItems;
CREATE TABLE IF NOT EXISTSOrderItems(
order_num VARCHAR(255) NOT NULL COMMENT ‘商品订单号’,
quantity INT(255) NOT NULL COMMENT ‘商品数量’
);
INSERTOrderItemsVALUES (‘a1’,105),(‘a2’,200),(‘a4’,1121),(‘a5’,10),(‘a7’,5);案例 1 编写 SQL 语句,返回名为 cheapest_item 的字段,该字段包含每个供应商成本最低的产品(使用 Products 表中的 prod_price),然后从最低成本到最高成本对结果进行升序排序。
mysql> select vend_id,min(prod_price) cheapest_item from Products group by vend_id order by cheapest_item; 返回供应商id vend_id和对应供应商成本最低的产品cheapest_item。 +---------+---------------+ | vend_id | cheapest_item | +---------+---------------+ | a0019 | 0.1 | | b0019 | 20 | | a0011 | 100 | +---------+---------------+ 3 rows in set (0.00 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
案例 2 请编写 SQL 语句,针对表OrderItems,返回订单数量总和不小于100的所有订单号,
最后结果按照订单号升序排序?? 答案如下: mysql> select order_num from OrderItems group by order_num having sum(quantity)>=100 order by order_num; 返回order_num订单号。 +-----------+ | order_num | +-----------+ | a1 | | a2 | | a4 | +-----------+ 3 rows in set (0.00 sec) 示例解析 订单号a1、a2、a4的quantity总和都大于等于100,按顺序为a1、a2、a4。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
?? 说明:
①分组之后的条件筛选使用 having 实现:
SELECT 字段1, 字段2… FROM 表名 GROUP BY 分组字段 HAVING 分组条件;
②.where 子句用来筛选 from 子句中指定的操作所产生的行;
③.group by 子句用来分组 where 子句的输出;
④.having 子句用来从分组的结果中筛选行。
⑤ 分组查询常会用到一些聚合函数,如下所示
2.2.7 正则表达式
?? 语法介绍:
正则表达式描述了一种字符串匹配的规则, 正则表达式本身就是一个字符串,使用这个字符串来描述、用来定义匹配规则,匹配一系列符合某个句法规则的字符串。
在 MySQL 中通过 REGEXP 关键字进行正则表达式字符串匹配。
案例 1 实用的字符匹配
?? 患者信息表: Patients +--------------+---------+ | Column Name | Type | +--------------+---------+ | patient_id | int | | patient_name | varchar | | conditions | varchar | +--------------+---------+ patient_id (患者 ID)是该表的主键。 'conditions' (疾病)包含 0 个或以上的疾病代码,以空格分隔。 这个表包含医院中患者的信息。 写一条 SQL 语句,查询患有 I 类糖尿病的患者 ID (patient_id)、患者姓名(patient_name)以及其患有的所有疾病代码(conditions)。 I 类糖尿病的代码总是包含前缀 DIAB1 。 按 任意顺序 返回结果表。 查询结果格式如下示例所示。 ?? 需求 示例 1: 输入: Patients表: +------------+--------------+--------------+ | patient_id | patient_name | conditions | +------------+--------------+--------------+ | 1 | Daniel | YFEV COUGH | | 2 | Alice | | | 3 | Bob | DIAB100 MYOP | | 4 | George | ACNE DIAB100 | | 5 | Alain | DIAB201 | +------------+--------------+--------------+ 输出: +------------+--------------+--------------+ | patient_id | patient_name | conditions | +------------+--------------+--------------+ | 3 | Bob | DIAB100 MYOP | | 4 | George | ACNE DIAB100 | +------------+--------------+--------------+ 解释:Bob 和 George 都患有代码以 DIAB1 开头的疾病。 ???? 答案 # Write your MySQL query statement below SELECT select * FROM Patients WHERE conditions REGEXP '^DIAB1|\sDIAB1' /* Write your PL/SQL query statement below */ select patient_id "patient_id", patient_name "patient_name", conditions "conditions" from Patients where regexp_like(conditions,'^DIAB1| s*DIAB1')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
?? 2.3 子查询
?? 语法格式:
某些情况下,当进行一个查询时,需要的条件或数据要用另外一个 select 语句的结果,
这个时候,就要用到子查询。
常用子查询语法如下:
select * from xxx where col in (select * from xxxx);我们需要通过下面的代码创建一个表,而后录入一些数据,示例代码及数据表示例如下:
DROP TABLE IF EXISTS
Products;
CREATE TABLE IF NOT EXISTSProducts(
prod_idVARCHAR(255) NOT NULL COMMENT ‘产品 ID’,
prod_nameVARCHAR(255) NOT NULL COMMENT ‘产品名称’
);
INSERT INTOProductsVALUES (‘a0001’,‘egg’),
(‘a0002’,‘sockets’),
(‘a0013’,‘coffee’),
(‘a0003’,‘cola’);
DROP TABLE IF EXISTSOrderItems;
CREATE TABLE IF NOT EXISTSOrderItems(
prod_id VARCHAR(255) NOT NULL COMMENT ‘产品id’,
quantity INT(16) NOT NULL COMMENT ‘商品数量’
);
INSERTOrderItemsVALUES (‘a0001’,105),
(‘a0002’,1100),(‘a0002’,200),
(‘a0013’,1121),(‘a0003’,10),
(‘a0003’,19),(‘a0003’,5);案例 1 编写 SQL 语句,从 Products 表中检索所有的产品名称(prod_name),
以及名为 quant_sold 的计算列,
其中包含所售产品的总数(在 OrderItems 表上使用子查询和 SUM(quantity)检索)。?? 答案如下: mysql> SELECT p.prod_name, tb.quantity FROM ( SELECT prod_id, SUM(quantity) quantity FROM OrderItems GROUP BY prod_id ) tb, Products p WHERE tb.prod_id = p.prod_id; 返回产品名称prod_name和产品售出数量总和 +-----------+----------+ | prod_name | quantity | +-----------+----------+ | egg | 105 | | sockets | 1300 | | coffee | 1121 | | cola | 34 | +-----------+----------+ 4 rows in set (0.01 sec) 示例解析: prod_name是cola的prod_id为a0003,quantity总量为34,返回结果无需排序。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
案例 2 请列举常用子查询
?? where型子查询
where型子查询即把内层sql语句查询的结果作为外层sql查询的条件.
子查询要包含在括号内。
建议将子查询放在比较条件的右侧
① 查询比“孙红雷”的工资高的员工编号
SELECT * FROM t_salary
WHERE basic_salary > (SELECT basic_salary FROM t_employee INNER JOIN t_salary ON t_employee.eid=t_salary.eid WHERE t_employee.ename=‘孙红雷’);
② 查询和孙红雷,李晨在同一个部门的员工
SELECT * FROM t_employee
WHERE dept_id IN(SELECT dept_id FROM t_employee WHERE ename=‘孙红雷’ OR ename = ‘李晨’);
SELECT * FROM t_employee
WHERE dept_id = ANY(SELECT dept_id FROM t_employee WHERE ename=‘孙红雷’ OR ename = ‘李晨’);
③ 查询全公司工资最高的员工编号,基本工资
SELECT eid,basic_salary FROM t_salary
WHERE basic_salary = (SELECT MAX(basic_salary) FROM t_salary);
SELECT eid,basic_salary FROM t_salary
WHERE basic_salary >= ALL(SELECT basic_salary FROM t_salary);
?? from型子查询
from型子查询即把内层sql语句查询的结果作为临时表供外层sql语句再次查询
① 找出比部门平均工资高的员工编号,基本工资
SELECT t_employee.eid,basic_salary
FROM t_salary INNER JOIN t_employee INNER JOIN (
SELECT emp.dept_id AS did,AVG(s.basic_salary) AS avg_salary
FROM t_employee AS emp,t_salary AS s
WHERE emp.eid = s.eid
GROUP BY emp.dept_id) AS temp
ON t_salary.eid = t_employee.eid AND t_employee.dept_id = temp.did
WHERE t_salary.basic_salary > temp.avg_salary;
?? exists型子查询
① 查询部门信息,该部门必须有员工
SELECT * FROM t_department
WHERE EXISTS (SELECT * FROM t_employee WHERE t_employee.dept_id = t_department.did);?? ANY和ALL用法说明:
① ANY 表示至少一个
查询课程 3-105 且成绩至少高 3-245 的 score 表,DESC ( 降序 )
ANY: 符合 SQL 语句中的任意条件
也就是说,3-105成绩中,只要有一个大于从3-245筛选出来的任意行就符合条件
最后根据降序查询结果
SELECT * FROM score WHERE c_no = ‘3-105’ AND degree > ANY(
SELECT degree FROM score WHERE c_no = ‘3-245’
) ORDER BY degree DESC;
②ALL的用法
查询课程 3-105 且成绩高于 3-245 的 score 表
ALL: 符合 SQL 语句中的所有条件。
也就是说,在3-105成绩中,都要大于从3-245筛选出来全部行才算符合条件
SELECT * FROM score WHERE c_no = ‘3-105’ AND degree > ALL(
SELECT degree FROM score WHERE c_no = ‘3-245’);?? 2.4 多表连接
?? 语法介绍:
MySQL六种关联查询
1.交叉连接(CROSS JOIN)
2.内连接(INNER JOIN)
3.外连接(LEFT JOIN/RIGHT JOIN)
4. 联合查询(UNION与UNION ALL)
5.全连接(FULL JOIN)
6.自连接(Self JOIN)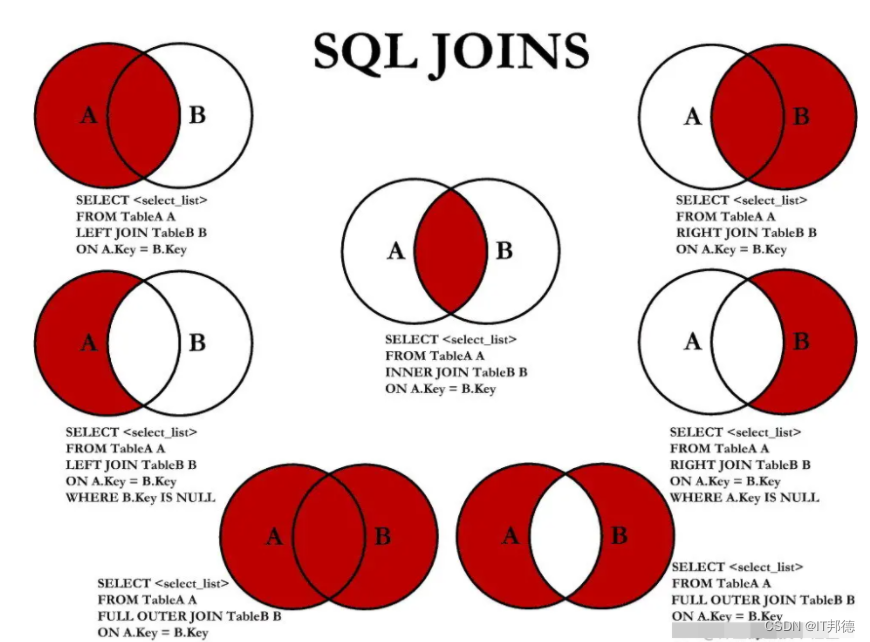
我们需要通过下面的代码创建一个表,而后录入一些数据,示例代码及数据表示例如下:DROP TABLE IF EXISTS
Orders;
CREATE TABLE IF NOT EXISTSOrders(
order_num VARCHAR(255) NOT NULL COMMENT ‘商品订单号’,
cust_id VARCHAR(255) NOT NULL COMMENT ‘顾客id’
);
INSERTOrdersVALUES (‘a1’,‘cust10’),(‘a2’,‘cust1’),(‘a3’,‘cust2’),(‘a4’,‘cust22’),(‘a5’,‘cust221’),(‘a7’,‘cust2217’);
DROP TABLE IF EXISTSCustomers;
CREATE TABLE IF NOT EXISTSCustomers(
cust_id VARCHAR(255) NOT NULL COMMENT ‘客户id’,
cust_name VARCHAR(255) NOT NULL COMMENT ‘客户姓名’
);
INSERTCustomersVALUES (‘cust10’,‘andy’),(‘cust1’,‘ben’),(‘cust2’,‘tony’),(‘cust22’,‘tom’),(‘cust221’,‘an’),(‘cust2217’,‘hex’);案例 1 编写 SQL 语句,返回 Customers 表中的顾客名称(cust_name)和Orders 表中的相关订单号(order_num),并按顾客名称再按订单号对结果进行升序排序。
你可以尝试用两个不同的写法,一个使用简单的等联结语法,另外一个使用 INNER JOIN。?? 答案如下: 等联结语法: mysql> select cust_name,order_num from Customers,Orders where Customers.cust_id=Orders.cust_id order by cust_name,order_num; 使用内联结 mysql> select cust_name,order_num from Customers INNER JOIN Orders ON Orders.cust_id=Customers.cust_id order by cust_name,order_num; +-----------+-----------+ | cust_name | order_num | +-----------+-----------+ | an | a5 | | andy | a1 | | ben | a2 | | hex | a7 | | tom | a4 | | tony | a3 | +-----------+-----------+ 6 rows in set (0.00 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
案例 2 关联查询大全
准备用于测试连接查询的数据:CREATE TABLE person (
id INT,
name VARCHAR(20),
cardId INT
);
CREATE TABLE card (
id INT,
name VARCHAR(20)
);
INSERT INTO card VALUES (1, ‘饭卡’), (2, ‘建行卡’), (3, ‘农行卡’), (4, ‘工商卡’), (5, ‘邮政卡’);
INSERT INTO person VALUES (1, ‘张三’, 1), (2, ‘李四’, 3), (3, ‘王五’, 6);
SELECT * FROM card;
SELECT * FROM person;
?? 内连接:
要查询这两张表中有关系的数据,可以使用 INNER JOIN ( 内连接 ) 将它们连接在一起。
– INNER JOIN: 表示为内连接,将两张表拼接在一起。
– on: 表示要执行某个条件。
SELECT * FROM person INNER JOIN card on person.cardId = card.id;
– 将 INNER 关键字省略掉,结果也是一样的
SELECT * FROM person JOIN card on person.cardId = card.id;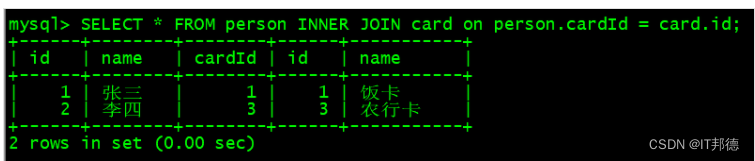
?? 左外连接:
–完整显示左边的表 ( person ) ,右边的表如果符合条件就显示,不符合则补 NULL
– LEFT JOIN 也叫做 LEFT OUTER JOIN,用这两种方式的查询结果是一样的
SELECT * FROM person LEFT JOIN card on person.cardId = card.id;
?? 右外链接:
–完整显示右边的表 ( card ) ,左边的表如果符合条件就显示,不符合则补 NULL
SELECT * FROM person RIGHT JOIN card on person.cardId = card.id;??全外链接:
完整显示两张表的全部数据
–MySQL 不支持这种语法的全外连接
SELECT * FROM person FULL JOIN card on person.cardId = card.id;
– 出现错误:
– ERROR 1054 (42S22): Unknown column ‘person.cardId’ in ‘on clause’
–MySQL 全连接语法,使用 UNION 将两张表合并在一起
SELECT * FROM person LEFT JOIN card on person.cardId = card.id
UNION
SELECT * FROM person RIGHT JOIN card on person.cardId = card.id;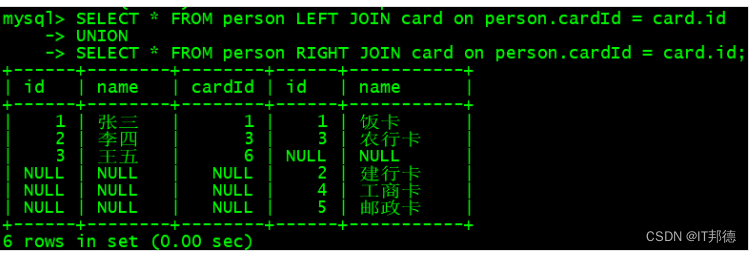
?? 2.5 组合查询
?? 语法介绍:
① UNION ALL (并集 不去重)
select * from test01
UNION ALL
select * from test02
② UNION (并集 去重)
select * from test01
UNION
select * from test02我们需要通过下面的代码创建一个表,而后录入一些数据,示例代码及数据表示例如下:
DROP TABLE IF EXISTS
OrderItems;
CREATE TABLE IF NOT EXISTSOrderItems(
prod_id VARCHAR(255) NOT NULL COMMENT ‘产品id’,
quantity VARCHAR(255) NOT NULL COMMENT ‘商品数量’
);
INSERTOrderItemsVALUES (‘a0001’,105),(‘a0002’,100),(‘a0002’,200),
(‘a0013’,1121),(‘a0003’,10),(‘a0003’,19),(‘a0003’,5),(‘BNBG’,10002);案例 1 将两个 SELECT 语句结合起来,以便从 OrderItems表中检索产品 id(prod_id)和 quantity。
其中,一个 SELECT 语句过滤数量为 100 的行,
另一个 SELECT 语句过滤 id 以 BNBG 开头的产品,最后按产品 id 对结果进行升序排序。mysql> select prod_id,quantity from OrderItems where quantity=100 union select prod_id,quantity from OrderItems where prod_id like 'BNBG%' order by prod_id; 返回产品id prod_id和产品数量quantity +---------+----------+ | prod_id | quantity | +---------+----------+ | a0002 | 100 | | BNBG | 10002 | +---------+----------+ 2 rows in set (0.01 sec) 示例解析: 产品id a0002因为数量等于100被选取返回;BNBG因为是以 BNBG 开头的产品所以返回; 最后以产品id进行排序返回。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
?? 2.6 函数用法
?? 常用聚合函数一览表

?? 常用数学函数一览表

?? 常用字符串函数一览表
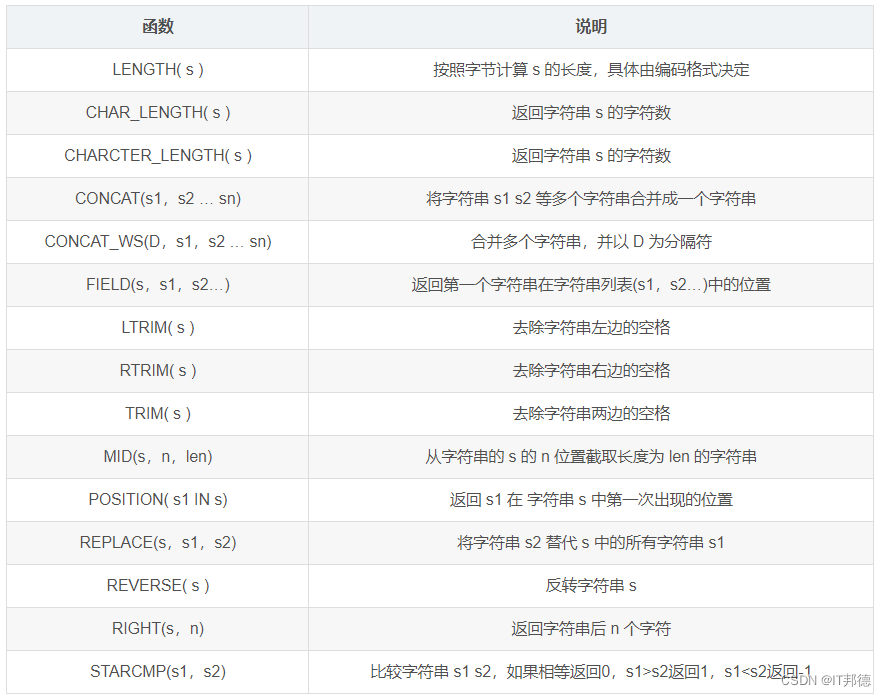
?? 常用日期函数一览表
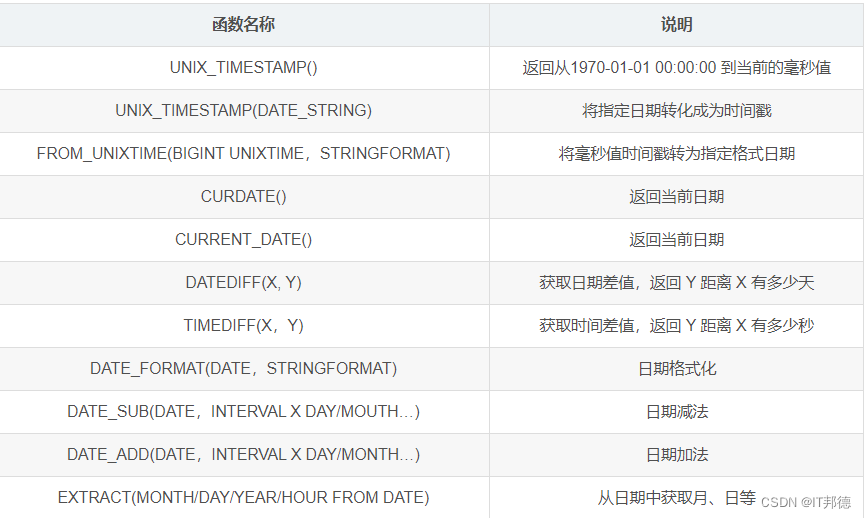
具体函数实用方法参考以下博客
史上最硬核的Mysql函数大全,还不收藏?
https://jeames.blog.csdn.net/article/details/120031303?? 2.7 开窗函数
?? 语法介绍:
① 含义:窗口函数也叫OLAP函数(Online Anallytical Processing,联机分析处理),
可以对数据进行实时分析处理。
② 作用:
解决排名,排顺序 问题,分组后的操作
③ 按照功能划分,可以把MySQL支持的窗口函数分为如下几类:
序号函数:row_number() / rank() / dense_rank()
分布函数:percent_rank() / cume_dist()
前后函数:lag() / lead()
头尾函数:first_val() / last_val()
其他函数:nth_value() / nfile()案例 1 MySQL8.0 增加了窗口函数,使用内置函数可以轻松实现上述排名
MySQL8.0 中可以利用 ROW_NUMBER(),DENSE_RANK(),RANK() 三个窗口函数实现上述三种排名, 需要注意的一点是 as 后的别名,千万不要与前面的函数名重名,否则会报错, 下面给出这三种函数实现排名的案例: ## 按分数高低直接排名,从 1 开始,往下排,类似于 row number select xuehao,score, ROW_NUMBER() OVER(order by score desc) as row_r from scores_tb; ## 分数相同,名次相同,排名无间隔: select xuehao,score, DENSE_RANK() OVER(order by score desc) as dense_r from scores_tb; ## 并列排名,排名有间隔: select xuehao,score, RANK() over(order by score desc) as r from scores_tb; -- 一条语句也可以查询出不同排名 SELECT xuehao,score, ROW_NUMBER() OVER w AS 'row_r', DENSE_RANK() OVER w AS 'dense_r', RANK() OVER w AS 'r' FROM `scores_tb` WINDOW w AS (ORDER BY `score` desc);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
?? 3.DML数据操纵
?? 3.1 插入INSERT
?? 按照图1的内容向tb_class表中插入记录

INSERT INTO tb_class(classNo,department,className) VALUES('AC1301', '会计学院', '会计 13-1 班'); INSERT INTO tb_class(classNo,department,className) VALUES('AC1302', '会计学院', '会计 13-2 班'); INSERT INTO tb_class(classNo,department,className) VALUES('CS1401', '计算机学院', '计算机 14-1 班'); INSERT INTO tb_class(classNo,department,className) VALUES('IS1301', '信息学院', '信息系统 13-1 班'); INSERT INTO tb_class(classNo,department,className) VALUES('IS1401', '信息学院', '信息系统 14-1 班');- 1
- 2
- 3
- 4
- 5
?? 使用批量插入记录的方法,一次性向tb_student表中插入如图2所示的记录

INSERT INTO tb_student values ('2013110101', '张晓勇', '男', '1977-12-11','山西','汉','AC1301'), ('2013110103', '王一敏', '女', '1996-03-25','河北','汉','AC1301'), ('2013110201', '江山', '女', '1996-09-17','内蒙','锡伯','AC1302'), ('2013110202', '李明', '男', '1996-01-14','广西','壮','AC1302'), ('2013310101', '黄菊', '女', '1995-09-30','北京','汉','IS1301'), ('2013310102', '林海', '男', '1996-01-18','北京','满','IS1301'), ('2013310103', '吴昊', '男', '1995-11-18','河北','汉','IS1301'), ('2014210101', '刘涛', '男', '1997-04-03','湖南','侗','CS1401'), ('2014210102', '郭志坚', '男', '1997-04-03','上海','汉','CS1401'), ('2014210103', '王玲', '女', '1998-02-21','安徽','汉','CS1401'), ('2014310101', '王林', '男', '1996-10-09','河南','汉','IS1401'), ('2014310102', '李怡然', '女', '1996-12-31','辽宁','汉','IS1401');- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
?? 向tb_student表中插入一条新的记录,
学号为’2015310103’,姓名为’李彤’,性别为’男’,民族为‘傣’,班级编号为’IS1401’
(注意,这是部分字段的值)。INSERT INTO tb_student(studentNo,studentName,sex,nation,classNo) values('2015310103','李彤','男','傣','IS1401');- 1
- 2
?? 向tb_student1表中插入tb_student表中所有汉族学生的信息。
insert into tb_student1 select * from tb_student where nation='汉';- 1
?? 3.2 更新UPDATE
?? 在tb_student表中,使用replace 语句把学号为“2014310102”的学生姓名替换为李怡。
select * from tb_student where studentNo='2014310102'; update tb_student set studentName=replace(studentName,'然','') where studentNo='2014310102';- 1
- 2
?? 使用update语句,把tb_student表中学号为’2014210101’的学生姓名更改为’黄涛’.
update tb_student set studentName='黄涛' where studentNo='2014210101';- 1
?? 3.3 删除DELETE
?? 删除tb_student表中姓名为“王一敏“的学生信息。
delete from tb_student where studentName='王一敏';- 1
?? 4.DDL数据定义
?? 4.1 表的创建、修改、删除
##创建表 create table if not exists tb_student ( studentNo CHAR(10) not NULL primary key comment '学号', studentName VARCHAR(10) NOT null comment '姓名', sex CHAR(2) comment '性别', birthday date comment '出生日期', native VARCHAR(20) comment '籍贯', nation VARCHAR(10) DEFAULT '汉' comment '民族', classNo CHAR(6) comment '所属班级' ) ENGINE=InnoDB comment '学生表'; desc tb_student; show columns from tb_student;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
?? 用命令show tables查看当前数据库中的所有表
?? 将tb_student的表结构复制到tb_student2,并向tb_student2中添加一个INT型字段id,
要求其不能为NULL,取值唯一且自动增加,并将该字段添加到表的第一个字段create table tb_student2 select * from tb_student where 1=3; alter table tb_student2 add id int Alter table tb_student2 add primary key(id); -先创建主键 ALTER TABLE tb_student2 MODIFY id int not null AUTO_INCREMENT; --自增- 1
- 2
- 3
- 4
- 5
?? 向tb_student表中添加一个varchar(16)类型的字段department,用于描述学生所在院系,要求设置其默认值为“城市学院”,并将该字段添加到原表nation之后
alter table tb_student add department varchar(16) DEFAULT '城市学院' comment '院系' after nation;- 1
- 2
?? 将tb_student中的字段birthday重命名为age,并将其数据类型更改为TINYINT,
允许其为NULL,默认值为18。用DESC 查看tb_student alter table tb_student change birthday age TINYINT DEFAULT 18; --给字段重命名- 1
- 2
?? 将tb_student表中的字段department的默认值删除
ALTER TABLE tb_student ALTER COLUMN department DROP DEFAULT;- 1
?? 将tb_student表中的字段department的默认值改为’环化学院’
ALTER TABLE tb_student ALTER COLUMN department SET DEFAULT '环化学院';- 1
?? 将tb_student表中的字段department的数据类型更改为varchar(20),
取值不允许为空,并将此字段移至字段studentName之后。用desc tb_student命令查看结果 ALTER TABLE tb_student MODIFY department varchar(20) not null after studentName;- 1
- 2
?? 删除数据表tb_student2中的字段id
ALTER TABLE tb_student2 MODIFY id int not null; //删除自增长 Alter table tb_student2 drop primary key;//删除主建 ALTER TABLE tb_student2 DROP id;- 1
- 2
- 3
- 4
?? 使用RENAME [TO]子句将数据库db_school中的数据表tb_student2
重新命名为backup_tb_studentalter table tb_student2 rename to backup_tb_student;- 1
?? 使用RENAME TABLE语句将数据库db_school中的表
backup_tb_student再重新命名为tb_student2RENAME TABLE backup_tb_student TO tb_student2,new_table TO old_table; drop table tb_student,tb_student2;- 1
- 2
?? 4.2 数据完整性约束
?? 重新按照表1创建tb_student数据表,要求以表级完整性约束方式定义主键,
并指定主键约束名为pk_student。CREATE TABLE tb_student ( studentNo CHAR(10) NOT NULL, studentName VARCHAR(10) NOT NULL, sex CHAR(2), birthday DATE, native VARCHAR(20), nation VARCHAR(20) default '汉', classNo CHAR(6), constraint pk_student primary key(studentNo) ) engine=InnoDB default charset=gb2312;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
?? 在数据库db_school中,按照表2的结构创建tb_class。要求:使用InnoDB存储引擎,gb2312字符集,主键约束为列级完整性约束,唯一约束为表级完整性约束其约束名为uq_class

CREATE TABLE tb_class ( classNo CHAR(6) PRIMARY KEY NOT NULL, className VARCHAR(20) NOT NULL, department VARCHAR(20), grade ENUM('1','2','3','4'), classNum TINYINT, constraint uq_class unique(className) ) engine=InnoDB default charset=gb2312;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
?? 首先删除数据表tb_student,按照表1重新创建tb_student,在创建的同时建立tb_student到tb_class的外键约束(两个表相同含义的属性是classNo,因此classNo是tb_student的外键),约束名为fk_student,并定义相应的参照动作,更新操作为级联(cascade),删除操作为限制(restrict),数据表引擎为InnoDB,字符集为gb2312
drop table tb_student; CREATE TABLE tb_student ( studentNo CHAR(10) NOT NULL, studentName VARCHAR(10) NOT NULL, sex CHAR(2), birthday DATE, native VARCHAR(20), nation VARCHAR(20) default '汉', classNo CHAR(6), constraint fk_student FOREIGN KEY (classNo) references tb_class(classNo) on delete restrict on update cascade ) engine=InnoDB default charset=gb2312;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
?? 在数据库db_school中按照表3创建tb_course表,
要求:外键名字为fk_course,引擎为InnoDB,默认字符集为gb2312。
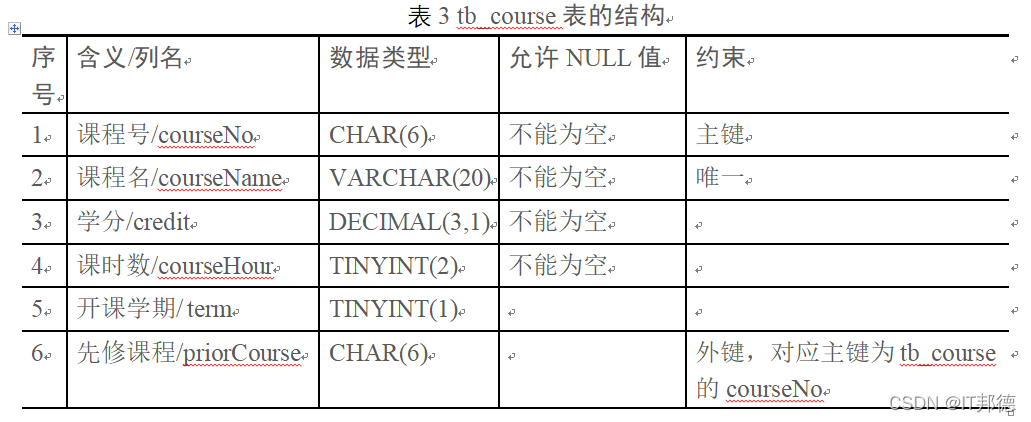
CREATE TABLE tb_course ( courseNo CHAR(6) NOT NULL primary key comment '课程号', courseName VARCHAR(20) unique not NULL comment '课程名', credit DECIMAL(3,1) not NULL comment '学分', courseHour TINYINT(2) not NULL comment '课时数', term TINYINT(2) comment '开课学期', priorCourse CHAR(6) comment '先修课程', constraint fk_course FOREIGN KEY(priorCourse) REFERENCES tb_course(courseNo) ) engine=InnoDB default charset=gb2312;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
?? 在数据库db_school中定义数据表tb_score,
表结构如表4所示, 引擎为InnoDB,默认字符集为gb2312。

CREATE TABLE tb_score( CREATE TABLE tb_score( studentNo CHAR(10) NOT NULL comment '学号', courseNo CHAR(6) NOT NULL comment '课程号', credit DECIMAL(4,1) not NULL comment '成绩', constraint fk_score_stuNo FOREIGN KEY(studentNo) REFERENCES tb_student(studentNo), constraint fk_score_courNo FOREIGN KEY(courseNo) REFERENCES tb_course(courseNo), constraint pk_score PRIMARY KEY(studentNo,courseNo) ) engine=InnoDB default charset=gb2312; 注:外键约束对应的主键(在表里是主键才可以)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
?? 4.3 更新完整性约束条件
?? 删除在表tb_score中定义的外键约束fk_score_stuNo
alter table tb_score drop foreign key fk_score_stuNo;- 1
?? 删除在表tb_student中定义的主键约束。
Alter table tb_student drop primary key;- 1
?? 添加主键约束,用alter table语句在tb_student对studentNo重新添加主键。
Alter table tb_student add primary key(studentNo);- 1
?? 添加外键约束,用alter table语句在tb_score表对studentNo重新添加外键,
对应的主键为tb_student表的studentNo,外键名称为fk_score_stuNo。ALTER TABLE tb_score ADD CONSTRAINT fk_score_stuNo FOREIGN KEY(studentNo) REFERENCES tb_student(studentNo);- 1
- 2
?? 4.4 索引的创建
?? 创建新表的同时创建普通索引:要求按照实验一第5题表1的结构创建tb_student1表,
要求在创建的同时在studentName字段上建立普通索引,索引名为idx_studentName。create table if not exists tb_student1 ( studentNo CHAR(10) not NULL primary key comment '学号', studentName VARCHAR(10) NOT null comment '姓名', sex CHAR(2) comment '性别', birthday date comment '出生日期', native VARCHAR(20) comment '籍贯', nation VARCHAR(10) DEFAULT '汉' comment '民族', classNo CHAR(6) comment '所属班级', INDEX idx_studentName(studentName) ) ENGINE=InnoDB comment '学生表';- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
?? 创建新表时创建唯一索引:按照实验一第20题表2的结构创建tb_class1表,
要求在创建的同时在className字段上建立唯一索引,索引名为uqidx_className。CREATE TABLE tb_class1 ( classNo CHAR(6) PRIMARY KEY NOT NULL, className VARCHAR(20) NOT NULL, department VARCHAR(20), grade ENUM('1','2','3','4'), classNum TINYINT, constraint uq_class unique(className), UNIQUE INDEX uqidx_className(className) ) engine=InnoDB default charset=gb2312;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
?? 在创建新表的同时创建主键索引:
按照第4部分表3的结构创建tb_course1,
要求创建的同时在courseNo字段上建立主键索引。CREATE TABLE tb_course1 ( courseNo CHAR(6) primary key comment '课程号', courseName VARCHAR(20) unique not NULL comment '课程名', credit DECIMAL(3,1) not NULL comment '学分', courseHour TINYINT(2) not NULL comment '课时数', term TINYINT(2) comment '开课学期', priorCourse CHAR(6) comment '先修课程' ) engine=InnoDB default charset=gb2312;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
?? 使用create index语句创建索引:
按照第4部分表4的结构创建tb_score1,
要求使用create index 语句对studentNo建立普通降序索引,索引名为idx_studentNo,
对courseNo建立普通升序索引,索引名为idx_courseNo.CREATE TABLE tb_score1( studentNo CHAR(10) NOT NULL comment '学号', courseNo CHAR(6) NOT NULL comment '课程号', credit DECIMAL(4,1) not NULL comment '成绩' ) engine=InnoDB default charset=gb2312; alter table tb_score1 add index idx_studentNo(studentNo desc); alter table tb_score1 add index idx_courseNo(courseNo);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
?? 使用create index语句创建基于字段值前缀字符的索引:
在tb_course上建立一个索引,要求按课程名称courseName字段值的前三个字符建立降序索引。--函数要再加个括号 alter table tb_course add index idx_courseName1((left(courseName,3)) desc); DROP INDEX idx_courseName1 on tb_course;- 1
- 2
- 3
?? 使用alter table语句建立普通索引:在tb_score上建立普通索引,
要求使用alter table语句对courseNo字段建立普通索引,索引名为idx_courseNo.alter table tb_score add index idx_courseNo(courseNo);- 1
?? 5.DCL数据控制
?? 语法格式:
DCL 数据控制语言 (Data Control Language ) 在SQL语言中,是一种可对数据访问权进行控制的指令,
它可以控制特定用户账户对数据表、查看表、存储程序、用户自定义函数等数据库对象的控制权,
由 GRANT 和 REVOKE 两个指令组成。?? 5.1 创建用户
create user ‘用户名’@‘IP地址’ identified WITH mysql_native_password by ‘密码’;
flush privileges;?? 5.2 修改用户名
rename user ‘用户名’@‘IP地址’ to ‘新用户名’@‘IP地址’;
?? 5.3 修改密码
#切换到mysql库
use mysql;
#更新密码
UPDATE user SET password=password(‘新密码’) WHERE user=‘用户名’ AND host=‘IP地址’;
#刷新权限
FLUSH PRIVILEGES;?? 5.4 删除用户
#注意这里的IP地址,一个用户可能会有多个
drop user ‘用户名’@‘IP地址’;
#比如
drop user ‘Alian’@‘192.168.0.100’;?? 5.5 权限管理
?? 查看权限
mysql> create user jea@‘%’ identified with mysql_native_password by ‘jea’;
mysql> show grants for jea@‘%’;?? 赋权
grant 普通数据用户,查询、插入、更新、删除某数据库中所有表数据的权限
mysql> grant select, insert, update, delete on db_school.* to jea@‘%’;
mysql> flush privileges;
##grant 创建、修改、删除 MySQL 数据表结构权限
grant create on testdb.* to developer@‘192.168.0.%’;
grant alter on testdb.* to developer@‘192.168.0.%’;
grant drop on testdb.* to developer@‘192.168.0.%’;
##grant 操作 MySQL 外键权限。
grant references on testdb.* to developer@‘192.168.0.%’;
##grant 操作 MySQL 临时表权限。
grant create temporary tables on testdb.* to developer@‘192.168.0.%’;
##grant 操作 MySQL 索引权限。
grant index on testdb.* to developer@‘192.168.0.%’;
##grant 操作 MySQL 视图、查看视图源代码 权限。
grant create view on testdb.* to developer@‘192.168.0.%’;
grant show view on testdb.* to developer@‘192.168.0.%’;
##grant 操作 MySQL 存储过程、函数 权限
grant create routine on testdb.* to developer@‘192.168.0.%’;
grant alter routine on testdb.* to developer@‘192.168.0.%’;
grant execute on testdb.* to developer@‘192.168.0.%’;?? 回收权限
mysql> revoke select, insert, update, delete on db_school.* from jea@‘%’;
?? 6.TCL事务控制
在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务
默认情况下 MySQL 开启了自动提交
事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行
事务用来管理 insert,update,delete 语句
一般情况下建议开启自动提交
如果是大批量的数据插入,建议关闭自动提交,分批来提交
mysql> show variables like ‘autocommit’;
mysql> show engines ; --显示所有的存储引擎
关闭自动提交
mysql> set autocommit = off;
mysql> show variables like ‘autocommit’;SQL入门到高手推荐学习资源
① 牛客题霸刷题-SQL必知必会50道
https://jeames.blog.csdn.net/article/details/125021153
②初学者怎样快速学会 SQL
https://jeames.blog.csdn.net/article/details/124834268
③一份热乎乎的MySQL实训真题,让你成为SQL高手
https://jeames.blog.csdn.net/article/details/123144444
④重温SQL行转列,性能又双叒提升了
https://jeames.blog.csdn.net/article/details/122891838
⑤LeetCode刷题SQL专项
https://blog.csdn.net/weixin_41645135/category_11826559.html
先自我介绍一下,小编13年上师交大毕业,曾经在小公司待过,去过华为OPPO等大厂,18年进入阿里,直到现在。深知大多数初中级java工程师,想要升技能,往往是需要自己摸索成长或是报班学习,但对于培训机构动则近万元的学费,着实压力不小。自己不成体系的自学效率很低又漫长,而且容易碰到天花板技术停止不前。因此我收集了一份《java开发全套学习资料》送给大家,初衷也很简单,就是希望帮助到想自学又不知道该从何学起的朋友,同时减轻大家的负担。添加下方名片,即可获取全套学习资料哦
-
相关阅读:
机器学习笔记:Huber Loss & smooth L1 loss
在集成使用华为移动服务的时候会出现 java.security.InvalidParameterException: url is null
快手616战报首发,次抛精华引新浪潮,快品牌跃入热榜top3
LeetCode-组合总和(C++)
以为很熟悉CountDownLatch的使用了,居然在生产环境翻车了
IDEA07:Mybatis和Springboot操作数据库
从零玩转人脸识别
git设置并记忆用户名密码
springboot冬奥会竞赛项目知识网站的设计与实现毕业设计源码152337
[ 数据结构进阶 - C++ ] 二叉搜索树
- 原文地址:https://blog.csdn.net/m0_67391270/article/details/126062190
