-
JUC原子类详解
原子类API
AtomicInteger
以 AtomicInteger 为例,常用 API:
- public final int get():获取当前的值
- public final int getAndSet(int newValue):获取当前的值,并设置新的值
- public final int getAndIncrement():获取当前的值,并自增
- public final int getAndDecrement():获取当前的值,并自减
- public final int getAndAdd(int delta):获取当前的值,并加上预期的值
- void lazySet(int newValue): 最终会设置成newValue,使用lazySet设置值后,可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
相比 Integer 的优势,多线程中让变量自增:
- private volatile int count = 0;
- // 若要线程安全执行执行 count++,需要加锁
- public synchronized void increment() {
- count++;
- }
- public int getCount() {
- return count;
- }
使用 AtomicInteger 后:
- private AtomicInteger count = new AtomicInteger();
- public void increment() {
- count.incrementAndGet();
- }
- // 使用 AtomicInteger 后,不需要加锁,也可以实现线程安全
- public int getCount() {
- return count.get();
- }
延伸到所有原子类
原子更新基本类型
通过原子的方式更新数组里的某个元素,Atomic包提供了以下的4个类:
- AtomicBoolean: 原子更新布尔类型。
- AtomicInteger: 原子更新整型。
- AtomicLong: 原子更新长整型。
以上3个类提供的方法几乎一模一样,可以参考上面AtomicInteger中的相关方法。
原子更新数组
通过原子的方式更新数组里的某个元素,Atomic包提供了以下的4个类:
- AtomicIntegerArray: 原子更新整型数组里的元素。
- AtomicLongArray: 原子更新长整型数组里的元素。
- AtomicReferenceArray: 原子更新引用类型数组里的元素。 这三个类的最常用的方法是如下两个方法:
- get(int index):获取索引为index的元素值。
- compareAndSet(int i,E expect,E update): 如果当前值等于预期值,则以原子方式将数组位置i的元素设置为update值。
举个AtomicIntegerArray例子:
- import java.util.concurrent.atomic.AtomicIntegerArray;
- public class Demo5 {
- public static void main(String[] args) throws InterruptedException {
- AtomicIntegerArray array = new AtomicIntegerArray(new int[] { 0, 0 });
- System.out.println(array);
- System.out.println(array.getAndAdd(1, 2));
- System.out.println(array);
- }
- }
- [0, 0]
- 0
- [0, 2]
原子更新引用类型
Atomic包提供了以下三个类:
- AtomicReference: 原子更新引用类型。
- AtomicStampedReference: 原子更新引用类型, 内部使用Pair来存储元素值及其版本号。
- AtomicMarkableReferce: 原子更新带有标记位的引用类型。
这三个类提供的方法都差不多,首先构造一个引用对象,然后把引用对象set进Atomic类,然后调用compareAndSet等一些方法去进行原子操作,原理都是基于Unsafe实现AtomicReferenceFieldUpdater略有不同,更新的字段必须用volatile修饰。
- import java.util.concurrent.atomic.AtomicReference;
- public class AtomicReferenceTest {
- public static void main(String[] args){
- // 创建两个Person对象,它们的id分别是101和102。
- Person p1 = new Person(101);
- Person p2 = new Person(102);
- // 新建AtomicReference对象,初始化它的值为p1对象
- AtomicReference ar = new AtomicReference(p1);
- // 通过CAS设置ar。如果ar的值为p1的话,则将其设置为p2。
- ar.compareAndSet(p1, p2);
- Person p3 = (Person)ar.get();
- System.out.println("p3 is "+p3);
- System.out.println("p3.equals(p1)="+p3.equals(p1));
- }
- }
- class Person {
- volatile long id;
- public Person(long id) {
- this.id = id;
- }
- public String toString() {
- return "id:"+id;
- }
- }
结果输出:
- p3 is id:102
- p3.equals(p1)=false
结果说明:
- 新建AtomicReference对象ar时,将它初始化为p1。
- 紧接着,通过CAS函数对它进行设置。如果ar的值为p1的话,则将其设置为p2。
- 最后,获取ar对应的对象,并打印结果。p3.equals(p1)的结果为false,这是因为Person并没有覆盖equals()方法,而是采用继承自Object.java的equals()方法;而Object.java中的equals()实际上是调用"=="去比较两个对象,即比较两个对象的地址是否相等。
原子更新字段类
Atomic包提供了四个类进行原子字段更新:
这四个类的使用方式都差不多,是基于反射的原子更新字段的值。要想原子地更新字段类需要两步:
-
- AtomicIntegerFieldUpdater: 原子更新整型的字段的更新器。
- AtomicLongFieldUpdater: 原子更新长整型字段的更新器。
- AtomicReferenceFieldUpdater: 上面已经说过此处不在赘述。
- AtomicStampedFieldUpdater: 原子更新带有版本号的引用类型。
- class Room{
- public volatile Boolean flag = Boolean.FALSE;
- AtomicReferenceFieldUpdater<Room,Boolean> fieldUpdater =
- AtomicReferenceFieldUpdater.newUpdater(Room.class,Boolean.class,"flag");
- public boolean init(Room room){
- boolean result = fieldUpdater.compareAndSet(room, Boolean.FALSE, Boolean.TRUE);
- return result;
- }
- }
- @SneakyThrows
- @Test
- public void test1(){
- Room room = new Room();
- CountDownLatch countDownLatch = new CountDownLatch(10);
- for (int i = 0; i < 10; i++) {
- new Thread(() -> {
- boolean result = room.init(room);
- if (result){
- log.info("初始化成功");
- }else {
- log.info("初始化失败");
- }
- countDownLatch.countDown();
- },String.valueOf(i)).start();
- }
- countDownLatch.await();
- log.info("完成");
- }
- @Data
- class Bank{
- public volatile int money = 0;
- AtomicIntegerFieldUpdater
fieldUpdater = - AtomicIntegerFieldUpdater.newUpdater(Bank.class,"money");
- public void add(Bank bank){
- fieldUpdater.getAndIncrement(bank);
- }
- }
- @SneakyThrows
- @Test
- void contextLoads() {
- CountDownLatch countDownLatch = new CountDownLatch(10);
- Bank bank = new Bank();
- for (int i = 1; i <= 10; ++i) {
- new Thread(() -> {
- for (int j = 0; j < 1000; j++) {
- bank.add(bank);
- }
- countDownLatch.countDown();
- },String.valueOf(i)).start();
- }
- countDownLatch.await();
- log.info(String.valueOf(bank.getMoney()));
- log.info("完成");
- }
再说下对于AtomicIntegerFieldUpdater 的使用稍微有一些限制和约束,约束如下:
-
-
- 第一步,因为原子更新字段类都是抽象类,每次使用的时候必须使用静态方法newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。
- 第二步,更新类的字段必须使用public volatile修饰。
-
字段必须是volatile类型的,在线程之间共享变量时保证立即可见.eg:volatile int value = 3
-
字段的描述类型(修饰符public/protected/default/private)是与调用者与操作对象字段的关系一致。也就是说调用者能够直接操作对象字段,那么就可以反射进行原子操作。但是对于父类的字段,子类是不能直接操作的,尽管子类可以访问父类的字段。
-
只能是实例变量,不能是类变量,也就是说不能加static关键字。
-
只能是可修改变量,不能使final变量,因为final的语义就是不可修改。实际上final的语义和volatile是有冲突的,这两个关键字不能同时存在。
-
对于AtomicIntegerFieldUpdater和AtomicLongFieldUpdater只能修改int/long类型的字段,不能修改其包装类型(Integer/Long)。如果要修改包装类型就需要使用AtomicReferenceFieldUpdater。
-
-
LongAdder的引入、原理、能否代替AtomicLong
我们知道,AtomicLong是利用底层的CAS操作来提供并发性的,比如addAndGet方法:


-
LongAdder:
LongAdder在无竞争的情况,跟AtomicLong一样,对同一个base进行操作,当出现竞争关系时则采用化整为零的做法,从空间换时间,用一个数组cells,将一个value拆分进这个数组cells。多个线程需要同时对value进行操作时候,可以对线程id进行hash得到hash值,再根据hash值映射到这个数组cells的某个下标,再对该下标所对应的值进行自增操作。当所有线程操作完毕,将数组cells的所有值和无竞争值base都加起来作为最终结果(分散热点)


LongAdder与Striped64的关系:
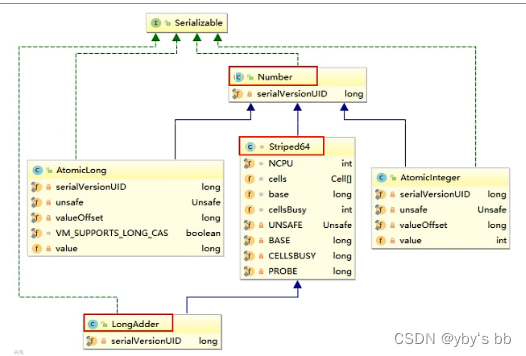

Striped64有几个比较重要的成员函数

Striped64中一些变量或者方法的定义

Cell:是java.util.concurrent.atomic下Striped64下的一个内部类
LongAdder为什么这么快呢?(分散热点)


-
- 下面方法调用了Unsafe类的getAndAddLong方法,该方法是一个native方法,它的逻辑是采用自旋的方式不断更新目标值,直到更新成功。(也即乐观锁的实现模式)
- 在并发量比较低的情况下,线程冲突的概率比较小,自旋的次数不会很多。但是,高并发情况下,N个线程同时进行自旋操作,N-1个线程失败,导致CPU打满场景,此时AtomicLong的自旋会成为瓶颈
- 这就是LongAdder引入的初衷------解决高并发环境下AtomictLong的自旋瓶颈问题
- base变量:非竞争状态条件下,直接累加到该变量上
- Cell[ ]数组:竞争条件下(高并发下),累加各个线程自己的槽Cell[i]中
-
①. 最初无竞争时,直接通过casBase进行更新base的处理
-
②. 如果更新base失败后,首次新建一个Cell[ ]数组(默认长度是2)
-
③. 当多个线程竞争同一个Cell比较激烈时,可能就要对Cell[ ]扩容
-

-
源码解析 longAdder.increment( )
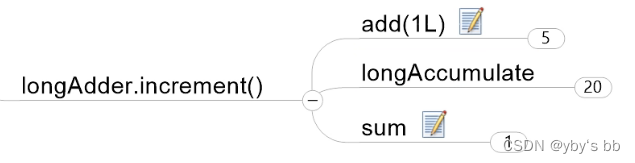
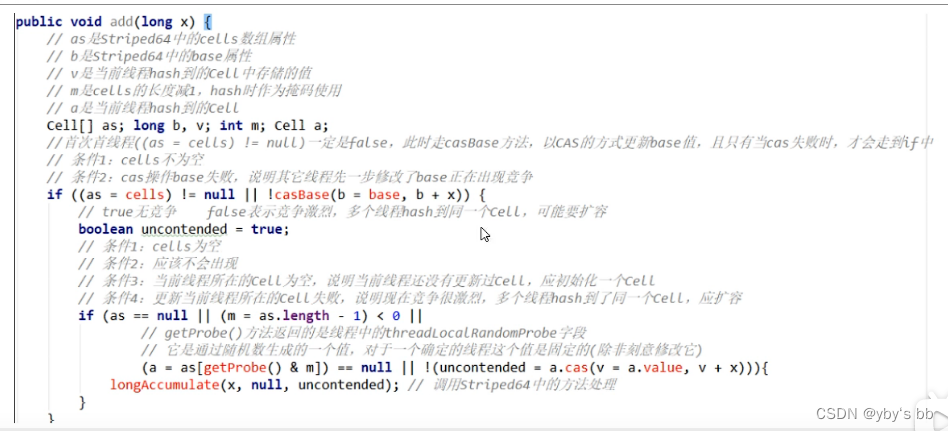
add(1L)
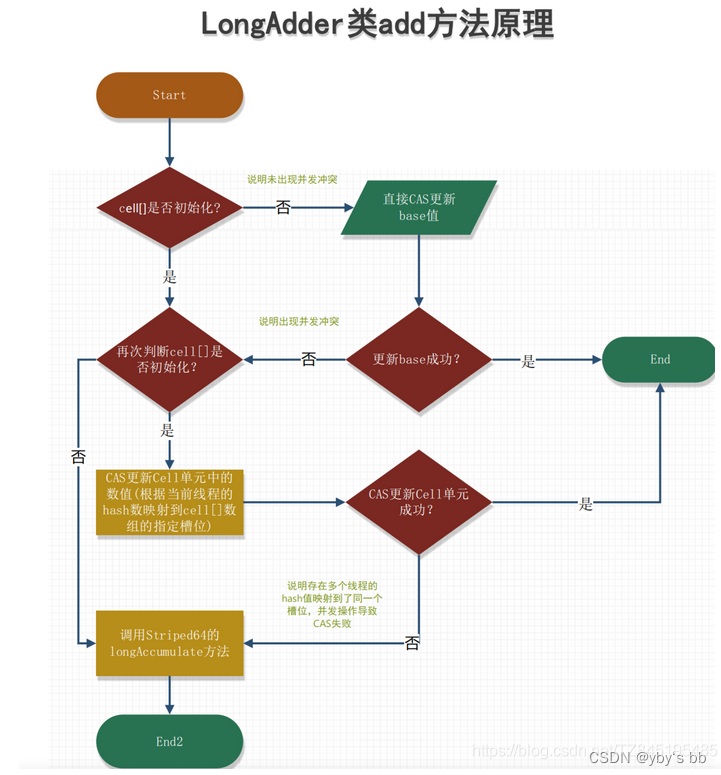


longAccumulate(x, null, uncontended)


线程hash值:probe
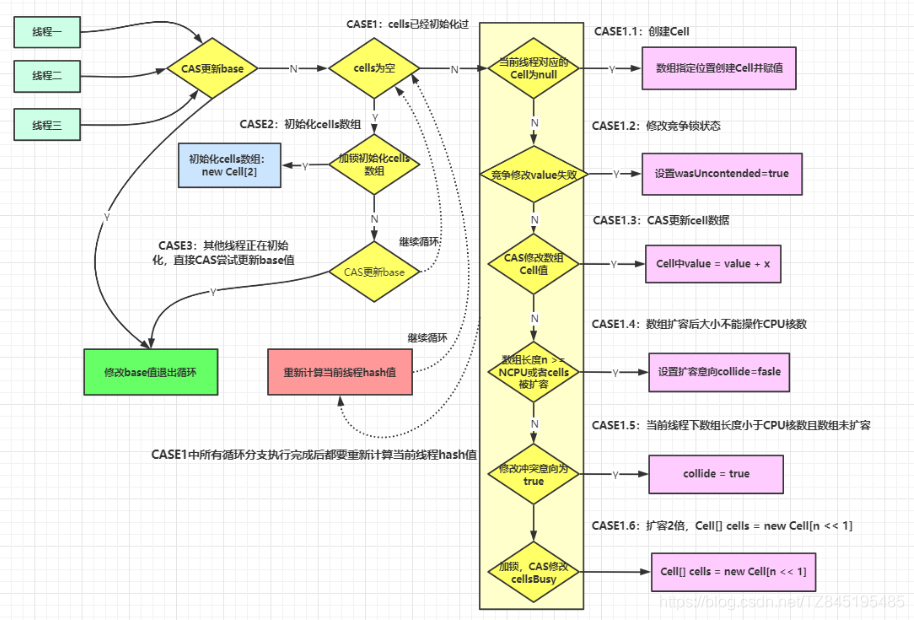
- final void longAccumulate(long x, LongBinaryOperator fn,
- boolean wasUncontended) {
- //存储线程的probe值
- int h;
- //如果getProbe()方法返回0,说明随机数未初始化
- if ((h = getProbe()) == 0) { //这个if相当于给当前线程生成一个非0的hash值
- //使用ThreadLocalRandom为当前线程重新计算一个hash值,强制初始化
- ThreadLocalRandom.current(); // force initialization
- //重新获取probe值,hash值被重置就好比一个全新的线程一样,所以设置了wasUncontended竞争状态为true
- h = getProbe();
- //重新计算了当前线程的hash后认为此次不算是一次竞争,都未初始化,肯定还不存在竞争激烈
- //wasUncontended竞争状态为true
- wasUncontended = true;
- }

刚刚初始化Cell[ ]数组(首次新建)
- //CASE2:cells没有加锁且没有初始化,则尝试对它进行加锁,并初始化cells数组
- /*
- cellsBusy:初始化cells或者扩容cells需要获取锁,0表示无锁状态,1表示其他线程已经持有了锁
- cells == as == null 是成立的
- casCellsBusy:通过CAS操作修改cellsBusy的值,CAS成功代表获取锁,
- 返回true,第一次进来没人抢占cell单元格,肯定返回true
- **/
- else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
- //是否初始化的标记
- boolean init = false;
- try { // Initialize table(新建cells)
- // 前面else if中进行了判断,这里再次判断,采用双端检索的机制
- if (cells == as) {
- //如果上面条件都执行成功就会执行数组的初始化及赋值操作,Cell[] rs = new Cell[2]标识数组的长度为2
- Cell[] rs = new Cell[2];
- //rs[h & 1] = new Cell(x)表示创建一个新的cell元素,value是x值,默认为1
- //h & 1 类似于我们之前hashmap常用到的计算散列桶index的算法,
- //通常都是hash&(table.len-1),同hashmap一个意思
- //看这次的value是落在0还是1
- rs[h & 1] = new Cell(x);
- cells = rs;
- init = true;
- }
- } finally {
- cellsBusy = 0;
- }
- if (init)
- break;
- }
兜底(多个线程尝试CAS修改失败的线程会走这个分支)
- //CASE3:cells正在进行初始化,则尝试直接在基数base上进行累加操作
- //这种情况是cell中都CAS失败了,有一个兜底的方法
- //该分支实现直接操作base基数,将值累加到base上,
- //也即其他线程正在初始化,多个线程正在更新base的值
- else if (casBase(v = base, ((fn == null) ? v + x :
- fn.applyAsLong(v, x))))
- break;
Cell数组不再为空且可能存在Cell数组扩容
- for (;;) {
- Cell[] as; Cell a; int n; long v;
- if ((as = cells) != null && (n = as.length) > 0) { // CASE1:cells已经初始化了
- // 当前线程的hash值运算后映射得到的Cell单元为null,说明该Cell没有被使用
- if ((a = as[(n - 1) & h]) == null) {
- //Cell[]数组没有正在扩容
- if (cellsBusy == 0) { // Try to attach new Cell
- //先创建一个Cell
- Cell r = new Cell(x); // Optimistically create
- //尝试加锁,加锁后cellsBusy=1
- if (cellsBusy == 0 && casCellsBusy()) {
- boolean created = false;
- try { // Recheck under lock
- Cell[] rs; int m, j; //将cell单元赋值到Cell[]数组上
- //在有锁的情况下再检测一遍之前的判断
- if ((rs = cells) != null &&
- (m = rs.length) > 0 &&
- rs[j = (m - 1) & h] == null) {
- rs[j] = r;
- created = true;
- }
- } finally {
- cellsBusy = 0;//释放锁
- }
- if (created)
- break;
- continue; // Slot is now non-empty
- }
- }
- collide = false;
- }
- /**
- wasUncontended表示cells初始化后,当前线程竞争修改失败
- wasUncontended=false,表示竞争激烈,需要扩容,这里只是重新设置了这个值为true,
- 紧接着执行advanceProbe(h)重置当前线程的hash,重新循环
- */
- else if (!wasUncontended) // CAS already known to fail
- wasUncontended = true; // Continue after rehash
- //说明当前线程对应的数组中有了数据,也重置过hash值
- //这时通过CAS操作尝试对当前数中的value值进行累加x操作,x默认为1,如果CAS成功则直接跳出循环
- else if (a.cas(v = a.value, ((fn == null) ? v + x :
- fn.applyAsLong(v, x))))
- break;
- //如果n大于CPU最大数量,不可扩容,并通过下面的h=advanceProbe(h)方法修改线程的probe再重新尝试
- else if (n >= NCPU || cells != as)
- collide = false; //扩容标识设置为false,标识永远不会再扩容
- //如果扩容意向collide是false则修改它为true,然后重新计算当前线程的hash值继续循环
- else if (!collide)
- collide = true;
- //锁状态为0并且将锁状态修改为1(持有锁)
- else if (cellsBusy == 0 && casCellsBusy()) {
- try {
- if (cells == as) { // Expand table unless stale
- //按位左移1位来操作,扩容大小为之前容量的两倍
- Cell[] rs = new Cell[n << 1];
- for (int i = 0; i < n; ++i)
- //扩容后将之前数组的元素拷贝到新数组中
- rs[i] = as[i];
- cells = rs;
- }
- } finally {
- //释放锁设置cellsBusy=0,设置扩容状态,然后进行循环执行
- cellsBusy = 0;
- }
- collide = false;
- continue; // Retry with expanded table
- }
- h = advanceProbe(h);
- }

sum( )
sum( )会将所有Cell数组中的value和base累加作为返回值
- public long sum() {
- Cell[] as = cells; Cell a;
- long sum = base;
- if (as != null) {
- for (int i = 0; i < as.length; ++i) {
- if ((a = as[i]) != null)
- sum += a.value;
- }
- }
- return sum;
- }
核心的思想就是将之前AtomicLong一个value的更新压力分散到多个value中去,从而降级更新热点
- 为啥高并发下sum的值不精确?
- 首先,最终返回的sum局部变量,初始被赋值为base,而最终返回时,很可能base已经被更新了,而此时局部变量sum不会更新,造成不一致
- 其次,这里对cell的读取也无法保证是最后一次写入的值。所以,sum方法在没有并发的情况下,可以获得正确的结果
- sum执行时,并没有限制对base和cells的更新(一句要命的话)。所以LongAdder不是强一致性,它是最终一致性的
-
相关阅读:
mysql 问题解决 4
Python基础入门篇【32】--面向对象:装饰器与类的常用装饰器
Android 的Memory Profiler详解
双十一游戏党必备的数码好物有哪些?2022双11游戏党必备外设清单
Zig、C、Rust的Pk1
XGBoost+LR融合
如何在Vue3.2的setup中设置组件名、在vben-admin中实现页面缓存?
求解代码题!这个怎么做啊
海康Visionmaster-环境配置:MFC 二次开发环境配置方法
Python(10)列表例题重写<1>
- 原文地址:https://blog.csdn.net/weixin_63566550/article/details/126064473
