-
【机器学习算法】支持向量机(support Vector Machine,SVM)
目录
我的主页:晴天qt01的博客_CSDN博客-数据分析师领域博主
目前进度:第四部分【机器学习算法】
支持向量机
支持向量机概述
支持向量机(support Vector Machine,SVM)是一种知名的二元线性/非线性分类方法,线性和非线性分类问题都可以处理,是俄罗斯的统计学家Vapink提出的。
非线性问题需要进行一个非线性的转化(Nonlinear Transformation),把原始数据映射到一个比较高维读的特征空间(Feature Space),
在高纬度的空间它就可以找出一个最佳的线性分割的超平面,3个维度的切割叫平面切割,3个维度以上的我们就叫超平面切割。来将这两类数据分割开来
线性可分及线性不可分的问题

线性可分问题:代表的就是数据可以用一条直线分割成2类
线性不可分,代表要利用曲线才能将数据进行一个分割
SVM会提供一个非线性的转化,(feature space)将非线性的问题装换为线性的问题,利用一条线将数据分隔
SVM的基本原理就是做这样的一件事,透过非线性的转化,让他能够线性可分。
举个例子

这是一个绝对的线性不可分,但是呢,我们通过一个多项式的转化,增加维度,这个空间就是将x的平方加y的平方得到z的维度,我们可以发现,蓝色的点都在(0,0)周围的地方,红色的点都在外围。通过一个平方之后,我们就可以找到一个平面,把两类的数据分开来
决策变量与支持向量
我们把可以分割两个平面的超平面,称为决策边界。
如果是非线性的问题,我们可以通过适当的非线性装换,可以将数据映射到足够的高维度的特征空间,这两个类别的数据在高纬度的特征空间通常能被一个超平面分割开来。
比如我们刚才说的案例,它可以通过增加一个z轴的特征,来产生超平面。
利用支持向量建构分割超平面的的重要数据,不是所有的训练数据都要被采用来建构超平面,它只采用其中一部分的数据。那一部分的数据,就被我们称为support Vector,它需要最佳的超平面系指边界(Margin)最大化的超平面。
我们那一个图来说明支持向量是什么:

我们其实需要考虑的只有3笔数据,也就是距离超平面最近的3笔数据,图中用灰色圆圈框起来了。支持向量就是在两类边界上最靠近的点,这个就是我们的支持向量。事实上我们训练support vector就是根据这3个点进行计算的。其他点会被我们全部丢掉。
最佳的线性分割超平面及决策边界
线性可分的支持向量机
我们从最简单的分两类且线性可分的问题开始。

灰色代表它不会买电脑,白色代表它会买电脑。白色我们叫+1,黑色我们叫-1.
这个就是线性可分的一个问题。实现我们要找到支持向量,图中最靠近边界的点有3个,我们就用这3个 支持向量来进行寻找最佳边界(margin)
我们发现如果寻找切割两类的线是有无数条的,可以横着切,可以竖着切,我们需要找到一个最佳分割线,有最小分类错误率的直线(目的是寻找最佳泛化能力的直线)
然而,那条的最佳分割线呢?
我们认为认为最佳分割线是具有最大边界的超平面(maximum marginal Hyper plane)这个就是我们需要的最佳分割平面
下面是我们切割的两种方案

这里要寻找到大边界的超平面,就是我们需要求得的部分,因为它能够提供最大的分割度,泛化能力一般也会比较强。通常就是最佳模型
支持向量(几笔样本)
支持向量落在边界的边缘上是最难被分类的样本,把它分对一般就没有问题了。

一旦我们利用支持向量找到最佳边界超平面(MMH),则此向量机就训练好了。
支持向量是关键并且重要的训练样本。因为它最难被分类正确,如果它都被分类正确,那其余的样本也会被正确分类。我们就是那它来训练我们的支持向量机
也就是说我们移除其他样本,重新进行SVM同样也会得到一样的超平面
线性svm
由于最大边界的超平面(SVM)是一个线性分解线,所以我们训练好的SVM分类器也叫线性SVM(linear SVM)
SVM所学习的分类器,复杂度取决于支持向量的数目,而不是数据维度,SVM通常不会有过拟合的问题。因为它会选择其中适当的样本(支持向量),建立模型。
一般一个支持向量数量稀少的SVM分类器,即使维度很高,泛化能力也会很好,说明问题比较简单。
新的测试数据进来,也不容易分错。
总结:
虽然SVM的训练时间可能会很久,但是由于它能构建复杂的非线性决策分界线,SVM通常具有极高的正确率
SVM可以同时应用与分类与数值型问题,
但是当数据为线性不可分,找不到一条直线来分开这两个类别,此时的线性SVM在训练时找不到一个可行解能线性的将两类数据分离。方法有两种
1.如果你还是坚持使用线性的SVM就要容忍些许的错误。
2.或者将线性SVM延伸为非线性SVM,通过特征转化,找到线性超平面。
来解决线性不可分的问题
线性不可分的支持向量机

这就是一个线性不可分的问题,没法得到线性模型。
方法1容许一些错误。

会出现错误率,我们画圈的地方,我们容许他们错误,支持向量采用另外两个。
这样,我们就把它分为右上和左下。牺牲6笔数据的错误,支持向量的错误率就是这么来的,没法让他完全正确,如果让他错的越多,边界就会越来越大,边界大一般与错误率是成平衡的,边界大,错误率就高,边界小,错误率就低,我们需要作出取舍。在错误率不是很高的情况下,最大化它的边界。
如果一定要用线性SVM的话。就是要这样。
非线性转化
将线性SVM延伸为非线性SVM。
要将线性SVM延伸为非线性SVM,主要有两个步骤
1.用一个非线性装换,将原始数据映射到一个比较高纬度的空间,有一些常见的非线性装换方式,这个方式是需要我们人为选择,不像深度学习,它是可以自动学到的。事先定义好的
2.在高纬度的空间找到最佳分割超平面。 在此处我们同样使用线性SVM,如果把这个超平面投影到原来空间,就是一个非线性分割的超曲面(Nonlinear Seprating Hypersurface)
比如我们选择有输入向量(x1,x2,x3)映射到6维的特征空间z,映射方式如下。

那么我们3个维度就变成6个维度,我们可能就可以得到最佳的线性分割超平面
它在特征空间里可能是一个线性超平面为z=wz+b
然而当它对应到原始3D空间时,它是一个非线性二次多项式的决策函数,如下

第二个函数就是我们原始坐标空间的非线性的模型。
案例:

这个就是一个线性不可分的问题。可以通过多项式的装换,蓝色的点就是0,红色的点是1。
我们把坐标维度进行装换,x轴用(x-avg)^2,y轴用(x-avg)^2
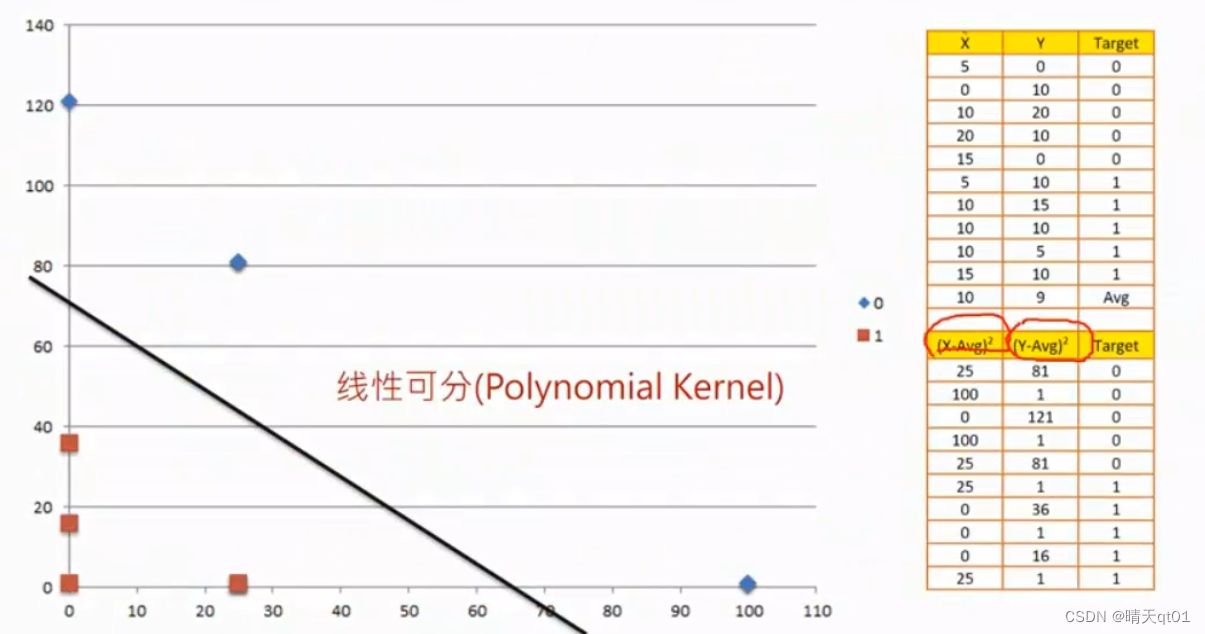
我们就可以找到一条直线找到一条多项式的函数。
案例2:XOR

蓝色点代表1.红色点代表0,当x和Y相同时,才会输出1,否则都是0
那么我们如何对它进行分割呢,我们看看BP神经网络的结果:

这是500次之后,神经网络学到的权重值。,

预测结果就可以说百分百分类正确了。大于0.5预测为1,小于0.5预测为0。
为什么经过神经网络能分类这个问题,是因为经过隐藏层的处理之后,问题就变成线性问题。后阶段就处理逻辑回归问题了。
那我们就疑惑,我们输出0,0的时候隐藏层会输出什么:

我们通过权重的计算得到下面这个结果
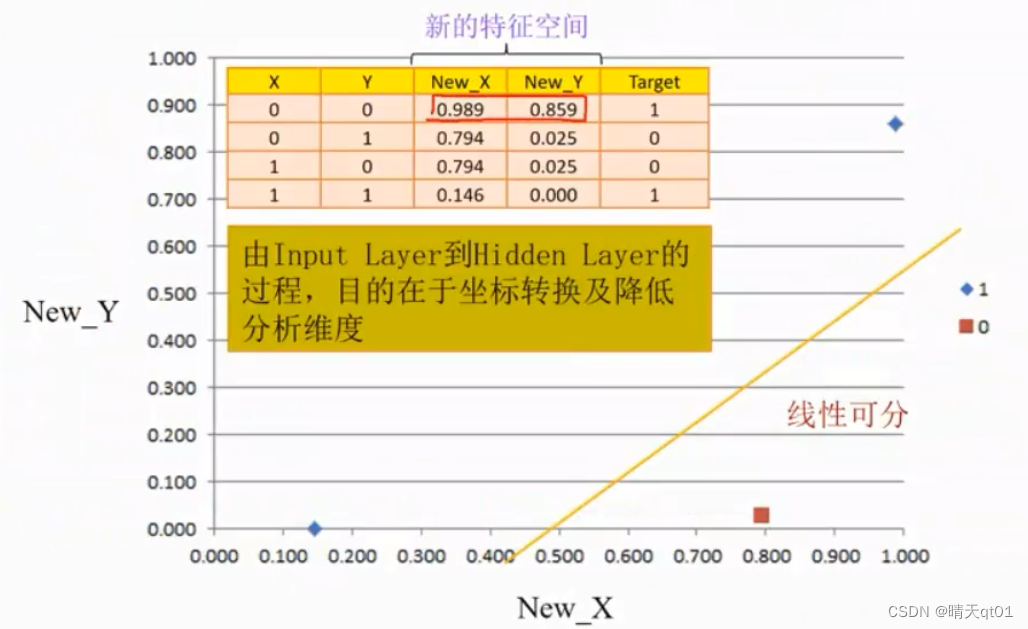
利用隐藏层的数据当成新的特征空间把它可视化出来,,发现有两个点变为同一个点,就可以用线进行分割。经过sigmoid激活函数果然就变成线性可分了
我们知道bp神经网络从输入层到隐藏层的过程其实就是在做坐标装换,把原始坐标装换为新坐标,如果输入层字段多,进行的就是坐标转化和降维的过程。

这是神经网络学习到的方程式。
然后我们看看支持向量机的分割边界

所以其实BP神经网络也是寻找一个最大分割的超平面。因为导出的方程式就是这个直线。Sigmoid也是可以用来做坐标装换
实际BP神经网络过程如下

常用非线性转化函数:
多项式转换(polynomial kernel)
高斯RBF转换(gaussian radial basis function)
这是另外一个神经网络架构
Sigmoid转换(sigmoid kernel)
所以我们说BP的非线性转化就是从神经网络里偷出来几个非线性方法。
不同的核心函数,会得到不同的非线性分类器。
支持向量机与神经网络之间的关系
我们可以发现,非线性SVM所找到的分类模型,与某些著名的神经网络所用的分类模型是一模一样的
SVM如果采用的是高斯核函数(gaussian radial basis function)找到的分类器和RBF神经网络相同
SVM采用S型核函数(sigmoid function),找到的分类器等同于BP神经网络
不同与BP神经网络会收敛到区域最佳解,SVM会找到全域最佳解,
总结:
我们之前说BP神经网络是一个集大成的模型,它把逻辑回归,线性回归,多元逻辑回归,整合到它的神经网络中。
SVM又将BP神经网络和RBF神经网络涵盖进来。变成它的子模型

根据核函数的不同支持向量机会的模型会与这些函数相同。
我们发现这些数学模型彼此的关联性是很密切的。
处理两类以上的分类问题。
标准的支持向量机只能处理两类的问题,两类以上的问题该如何处理。
一个二元的SVM分类模型,只能处理一个具有两种类别的数据,怎么解决六个类别的多元分类问题呢?
两种解决方法:
一对多:one against rest
我们把多类的数据,强迫分为两类,把一类标为+1.另一类标为-1,如此一来就能转换为一个二元分类的问题了。
比如glass的数据,数据有6类,就建立6个支持向量机分类器。
第一个SVM
属于类别1的资料为+1,其他类别为-1,这个SVM用来区别这两者
第二个SVM
属于类别2的标为+1,其他类别标为-1,这个SVM用来区别这两者
第三个SVM
属于类别3的标为+1….
以此类推。
换句话说,多分类的问题,有多少类数据,我们就会有多少个SVM
当有一笔新数据,会轮流丢到这些SVM中进行识别。
这样的做法很直观,而且运行时间与内存并不会消耗太多。
但是缺点是将“剩下类别”视为同一类,会导致这类数据非常的多导致+1和-1之间数据量差距过大,也就是类别不平衡问题。还得处理这个不平衡的问题。向量机如果都猜多数类,准确率就会很高,那就没有意义了。
一对一:one against one
相对一对多效果比较好,这个策略的想法,类似于高中的排列组合从T类别中任取两种类别,共会有C(T,2)=T(T-1)/2组合。
所以在这个策略底下,我们便会从多元类别的数据中,任意选择两个类别(2class)的数据,把数量多的判定为+1,少的为-1。训练出一个SVM。直到每个数据都训练完成为止。
因此,最后会有T(T-1)/2模型
测试数据进来的时候就要分别丢进这么多个数据中去,预测时间比较久。训练也会比较久,但是方式比较好,不会有类别不平衡的问题,
缺点:运行时间长,吃比较多的内存,而且会出现两个以上类别同票数的状况,导致+1,-1无法判断。。
我们的python的套件里是one-against-one来解决多元分类问题。
到时候实战的时候,会具体说明。
-
相关阅读:
rabbitmq之总览全局
Python PyQt 程序设置图标
挑战字节软件测试岗,原来这么轻松...
鸿鹄工程项目管理系统em Spring Cloud+Spring Boot+前后端分离构建工程项目管理系统
y149.第八章 Servless和Knative从入门到精通 -- Flow(十三)
开发实用篇——数据层解决方案
radio日志sim卡信号状态分析
Java语法笔记
C++ -- 深入理解多态
几何变换 - 图像的缩放、翻转、仿射变换、透视等
- 原文地址:https://blog.csdn.net/qq1021091799qq/article/details/126050481