-
HDFS中DataNode的工作机制
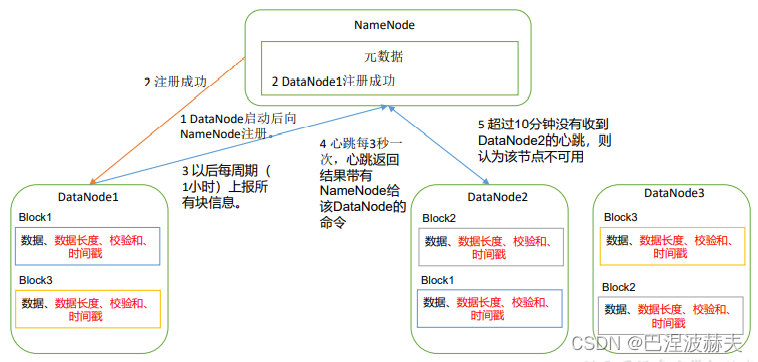
1 DataNode 工作机制
-
一个数据块在 DataNode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
-
DataNode 启动后向 NameNode 注册,通过后,周期性(1 小时)的向 NameNode上报所有的块信息。
-
心跳是每 3 秒一次,心跳返回结果带有 NameNode 给该 DataNode 的命令如复制块数据到另一台机器,或删除某个数据块。如果超过 10 分钟没有收到某个 DataNode 的心跳,则认为该节点不可用。
-
集群运行中可以安全加入和退出一些机器。
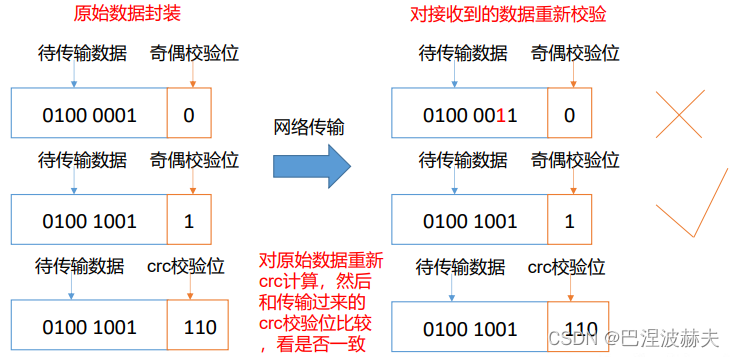
2 数据完整性检验
若 DataNode 节点上的数据出现损坏,显然会造成一些不必要的损失。如何保证 DataNode 节点的数据完整性十分有必要,检验流程如下:
- 当 DataNode 读取 Block 的时候,它会计算 CheckSum 。
- 如果计算后的 CheckSum,与 Block 创建时值不一样,说明 Block 已经损坏。
- Client 读取其他 DataNode 上的 Block。
- 常见的校验算法 crc(32),md5(128),sha1(160)
- DataNode 在其文件创建后周期验证 CheckSum。
3 掉线时限参数设置
- DataNode 进程死亡或者网络故障造成无法与NameNode通信;
- NameNode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长;
- HDFS默认的超时时长为10 min + 30 s;
- 如果定义超时时间为TimeOut,则超时时长的计算公式为:
TimeOut = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval
默认的dfs.namenode.heartbeat.recheck-interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。可在hdfs-site.xml配置文件中进行修改二者的值,值得注意的是,heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
<property> <name>dfs.namenode.heartbeat.recheck-intervalname> <value>300000value> property> <property> <name>dfs.heartbeat.intervalname> <value>3value> property>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4 DataNode多目录配置
DataNode 可以配置成多个目录,每个目录存储的数据不一样。即:数据不是副本
具体配置方法:
- 在 hdfs-site.xml 文件中添加如下内容
<property> <name>dfs.datanode.data.dirname> <value>file://${hadoop.tmp.dir}/dfs/data1,file://${hadoop.tmp.dir} /dfs/data2value> property>- 1
- 2
- 3
- 4
- 5
- 停止集群,删除三台节点的 data 和 logs 中所有数据。
[pbh@hadoop102 hadoop-3.1.3]$ rm -rf data/ logs/ [pbh@hadoop103 hadoop-3.1.3]$ rm -rf data/ logs/ [pbh@hadoop104 hadoop-3.1.3]$ rm -rf data/ logs/- 1
- 2
- 3
- 格式化集群并启动。
[pbh@hadoop102 hadoop-3.1.3]$ bin/hdfs namenode –format [pbh@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh- 1
- 2
- 查看结果
[pbh@hadoop102 dfs]$ ll 总用量 12 drwx------. 3 pbh pbh 4096 4 月 4 14:22 data1 drwx------. 3 pbh pbh 4096 4 月 4 14:22 data2 drwxrwxr-x. 3 pbh pbh 4096 12 月 11 08:03 name1 drwxrwxr-x. 3 pbh pbh 4096 12 月 11 08:03 name2- 1
- 2
- 3
- 4
- 5
- 6
-
-
相关阅读:
MySQL的内外连接
62. 不同路径-动态规划-双百代码
SpringBoot 整合 MyBatis-Plus
【第六篇】- Maven 仓库
第十九章《类的加载与反射》第3节:反射
java计算机毕业设计vue架构云餐厅美食订餐系统MyBatis+系统+LW文档+源码+调试部署
JUC并发编程——8锁现象(基于狂神说的学习笔记)
WebDAV之葫芦儿·派盘+读出通知
VS Code 常用快捷键
Autosar模块介绍:AutosarOS(1)
- 原文地址:https://blog.csdn.net/meng_xin_true/article/details/126039349