-
Re11:读论文 EPM Legal Judgment Prediction via Event Extraction with Constraints
论文名称:Legal Judgment Prediction via Event Extraction with Constraints
论文ACL官方下载地址:https://aclanthology.org/2022.acl-long.48/
论文官方GitHub项目:WAPAY/EPM本文是2022年ACL论文,作者来自南大。
本文关注CAIL数据集上的法律判决预测legal judgment prediction问题,即以案例事件描述文本为输入,预测法条、罪名、刑期,是多任务multi-class分类任务。本文使用限制(在损失函数中加罚项)来利用三个子任务之间的关系
中间任务是抽取事件特征,用事件信息来辅助预测判决结果。

1. Background & Motivation
本文认为过去的LJP模型预测失误的原因在于错误定位影响判决结果的关键事件信息,以及没有利用LJP各子任务之间的跨任务一致性限制(也就是特定抽取出的法条只能对应特定的罪名和刑期),因此本文提出了一个基于事件和限制的预测模型EPM来解决这些问题。
法条由事件模式(event pattern)和判决(judgment)/惩罚(penalty)两部分组成。本文认为只要能抽取出案例中的事件信息,就能预测出正确的判决结果。
①抽取事件以辅助LJP任务(认为以前的模型错误预测事件导致预测失败)。
②在事件输出和子任务之间增加了constraint(不满足特定条件时增加penalty。限制特定事件角色必须出现、事件类型之间必须对应,特定法条会限制charge和terms of penalty的选择范围。这个具体限制关系的列表在代码中给出了)。2. 问题定义与模型介绍
2.1 定义分层级的事件
(跟传统的法律领域事件定义不太相同,是为了trigger types and argument roles能用于LJP任务而定义的)
基于法条定义法律事件,因为法条是分层级的,所以对应定义出的事件也是分层级的
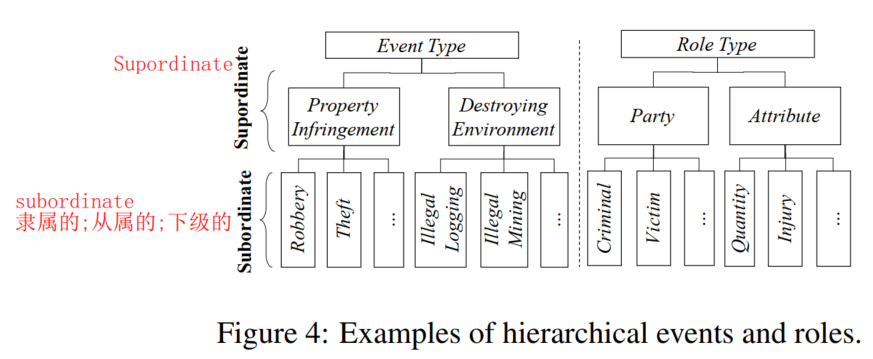
细粒度事件:

event trigger:指示一个事件的发生,与特定事件匹配(如事件Robbery对应的trigger type为Trigger-Rob)
event role:事件元素的类型(感觉可以类比为,role是类,argument是实例)token labeling任务范式:subordinate trigger(如果该token是trigger的一部分)或者subordinate role type(如果该token是argument的一部分)
2.2 EPM
我发誓这是今年我看过最魔性的模型,这也太能叠了!
联合训练:①抽取事件。②使用事件特征来实现多任务分类(用法条文本特征来做attention,考虑到事件输出constraint和多任务之间的constraint)。
baseline版本/EPM完整模型(用Switch分类器来切换:见后文实验部分介绍)
baseline版本:使用事实描述文本表征(context features)和法条表征(article embeddings)做attention,然后做3个分类任务
EPM版本:使用抽取出的事件的事件表征,和对应token的表征concat后得到的表征(event features),替换baseline中的context features
Token representation layer:使用预训练的Legal BERT模型实现事实描述文本表征
对事实描述文本表征进行max pooling,得到context feature(这个是在baseline里面用的,在EPM中将替换成后文会介绍的事件特征)
使用法条语义信息:用Token representation layer对法条进行character表征、使用max pooling得到每个法条的表征,然后用这个与context feature做attention:

Legal judgment prediction layer:对每个子任务实现一个线性分类器

hierarchical event extraction layer:①superordinate module:计算每个事实描述文本token的表征向量来与superordinate types/roles的correlation score ②subordinate module:基于层级信息计算subordinate type/role的分布概率
- 用可训练向量表示每个superordinate type/role的语义特征,用全连接层计算每个token与每个superordinate type/role的correlation score:
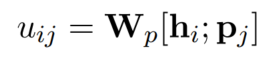
- 用softmax计算每个token的superordinate type/role feature(一个加权求和,软的表征)
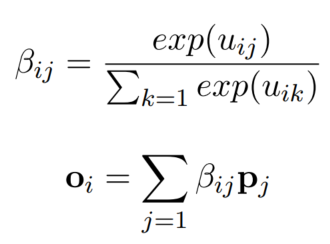
- 预测token属于subordinate type/role的概率:输入特征为concat token表征和superordinate type/role feature:
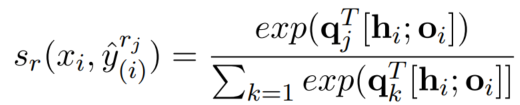
- 用CRF生成得分最高的types/roles序列:

- 使用预测出的types序列来生成事件特征:将每个抽取出的span的文本表征(token表征经max pooling得到)和subordinate type/role embedding进行concat,得到span的表征;再将所有span表征取max pooling,得到最终的事件特征
- 用事件特征替换前文baseline用的context feature
训练阶段损失函数:
3个子任务的损失函数为交叉熵。
事件抽取的损失函数和总的损失函数(这个没加事件输出限制的罚项):
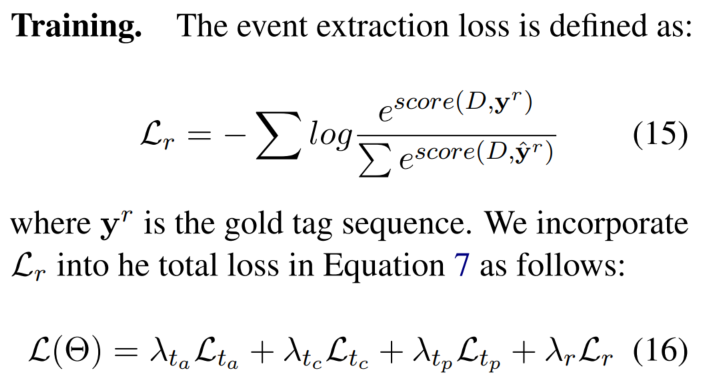
事件输出限制:如果特定trigger或role缺失,会增加penalty;特定trigger type必须出现特定角色


多任务之间的一致性限制:预测出的法条会限制charge和term penalty的选择范围(训练时,如果法条预测正确,在损失函数里加上mask 我跟学弟讨论了一下感觉作为单分类的话,理应训练时是无用的,但是在ablation study中article也会跟着受影响,所以训练阶段应该也会产生影响。另原论文中此处损失函数有两个连加号,但是别的损失函数公式都是单样本上的,所以怀疑是写错了这个情况是这样的。我问了作者,说是①做了label smoothing,所以mask始终会起效。②数据本身就有噪音,所以训练集真实标签不一定是对的,所以当y为1时mask不一定绝对是1。 测试时始终加上mask)
作者の回复:

代码呢也随后从one-hot改成了label smoothing。测试时加mask的方法,直接在预测分布时将不允许输出的类别的概率置0:

3. 实验
3.1 数据集
CAIL(big和small两个数据集)
新数据集LJP-E(手动标注了15种罪名上的案例的事件信息)3.2 baseline
①baseline:去掉事件抽取和constraint、把事件特征换成事实描述文本上下文特征的EPM模型。
③EPM模型先去掉事件部分(指①用的baseline模型)在原始数据集CAIL的训练集上进行预训练,然后再在标注事件信息的数据集LJP-E的训练集上进行微调。(问题:trick?感觉已经获得了fact description的信息,不公平)3.3 实验设置
超参设置:Legal-Bert的最长输入长度为512,用Adam作为优化器,学习率为 1 0 − 4 10^{-4} 10−4,batch size为32,warmup step为3000。模型最多训练20个epoch,保存每个子任务在验证集上Macro-F1最高的checkpoint(CAIL-big没有验证集,就直接用CAIL-small的验证集)。在LJP-E数据集上运行5个实验,报告平均结果。
在②中列出的总损失函数的四个λ是0.5, 0.5, 0.4, 0.2,事件输出限制罚项的超参 λ p \lambda_p λp是0.1
使用2个Tesla V100 GPUs运行实验。3.4 主实验结果
衡量模型使用的指标:Accuracy (Acc), Macro-Precision (MP), Macro-Recall (MR) and Macro-F1 (F1)
(实验结果表中的gold或@G指使用了真实事件标签(而非预测事件)来生成的结果)在LJP-E上的实验结果:

在CAIL上的实验结果:
由于LJP-E数据集只包含15种案例类型,因此先在CAIL训练集上训练了一个legal BERT,用[CLS] token的表征预测案例是否属于这15种之一(这个分类器叫Switch。batch size为32,训练20个epoch,用Adam做优化器,学习率为0.0001,在CAIL-big上的准确率为89.82%,CAIL-small为85.32%),如果是就用EPM来预测,如果不是就用微调前的EPM(③中讲的预训练的EPM)来预测。除直接使用EPM和各SOTA模型外:
- 在对比的SOTA模型上加EPM(如果Switch预测案例属于LJP-E的15种之一,就用fine-tuned EPM来分类;反之用原模型来分类)(我觉得这样直接加起来有些怪怪的)
- 修改TOPJUDGE模型(结果中的TOPJUDGE+Event):将CNN encoder换成LSTM,将原输入事实描述表征换成事件特征。效果会比直接TOPJUDGE+EPM更差,说明直接拿EPM当黑盒用效果会更好。


事件抽取的指标:

3.5 模型分析
3.5.1 Ablation Study
- 删除事件元素
- 删除事件输出限制(absolute constraint→CSTR1,event-based consistency constraint→CSTR2)
- 删除子任务之间的限制(article-charge constraint→DEP1,article-term constraint→DEP2)
- 删除Superordinate types,模型直接预测token的superordinate features
- 将event extraction视为auxiliary task(和LJP任务共享encoder)


4. 代码复现
我问作者:

作者回复:

I’m right here waiting for you!
- 用可训练向量表示每个superordinate type/role的语义特征,用全连接层计算每个token与每个superordinate type/role的correlation score:
-
相关阅读:
新电脑必装的7款软件,缺一不可
SU-03T语音模块使用简介
解耦电容选型定性与定量分析
函数栈详解
用户登录问题——登录态
LiveCharts2:简单灵活交互式且功能强大的.NET图表库
类和对象1:基础学习
利用SPI实现全自动化——LCD屏与RGB灯
斐波那契数列树形结构js
使用Django JWT实现身份验证
- 原文地址:https://blog.csdn.net/PolarisRisingWar/article/details/126029464