-
CTO说不建议我使用SELECT * ,这是为什么?

“不要使用SELECT *”几乎已经成为了使用MySQL的一条金科玉律,就连《阿里Java开发手册》也明确表示不得使用*作为查询的字段列表,更是让这条规则拥有了权威的加持。
 阿里Java开发手册
阿里Java开发手册
不过我在开发过程中直接使用SELECT *还是比较多的,原因有两个:
- 因为简单,开发效率非常高,而且如果后期频繁添加或修改字段,SQL语句也不需要改变;
- 我认为过早优化是个不好的习惯,除非在一开始就能确定你最终实际需要的字段是什么,并为之建立恰当的索引;否则,我选择遇到麻烦的时候再对SQL进行优化,当然前提是这个麻烦并不致命。
但是我们总得知道为什么不建议直接使用SELECT *,本文从4个方面给出理由。
1. 不必要的磁盘I/O
我们知道 MySQL 本质上是将用户记录存储在磁盘上,因此查询操作就是一种进行磁盘IO的行为(前提是要查询的记录没有缓存在内存中)。
查询的字段越多,说明要读取的内容也就越多,因此会增大磁盘 IO 开销。尤其是当某些字段是 TEXT、MEDIUMTEXT或者BLOB 等类型的时候,效果尤为明显。
那使用SELECT *会不会使MySQL占用更多的内存呢?
理论上不会,因为对于Server层而言,并非是在内存中存储完整的结果集之后一下子传给客户端,而是每从存储引擎获取到一行,就写到一个叫做net_buffer的内存空间中,这个内存的大小由系统变量net_buffer_length来控制,默认是16KB;当net_buffer写满之后再往本地网络栈的内存空间socket send buffer中写数据发送给客户端,发送成功(客户端读取完成)后清空net_buffer,然后继续读取下一行并写入。
也就是说,默认情况下,结果集占用的内存空间最大不过是net_buffer_length大小罢了,不会因为多几个字段就占用额外的内存空间。
2. 加重网络时延
承接上一点,虽然每次都是把socket send buffer中的数据发送给客户端,单次看来数据量不大,可架不住真的有人用*把TEXT、MEDIUMTEXT或者BLOB 类型的字段也查出来了,总数据量大了,这就直接导致网络传输的次数变多了。
如果MySQL和应用程序不在同一台机器,这种开销非常明显。即使MySQL服务器和客户端是在同一台机器上,使用的协议还是TCP,通信也是需要额外的时间。
3. 无法使用覆盖索引
为了说明这个问题,我们需要建一个表
CREATE TABLE `user_innodb` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`gender` tinyint(1) DEFAULT NULL,
`phone` varchar(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `IDX_NAME_PHONE` (`name`,`phone`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
我们创建了一个存储引擎为InnoDB的表user_innodb,并设置id为主键,另外为name和phone创建了联合索引,最后向表中随机初始化了500W+条数据。
InnoDB会自动为主键id创建一棵名为主键索引(又叫做聚簇索引)的B+树,这个B+树的最重要的特点就是叶子节点包含了完整的用户记录,大概长这个样子。
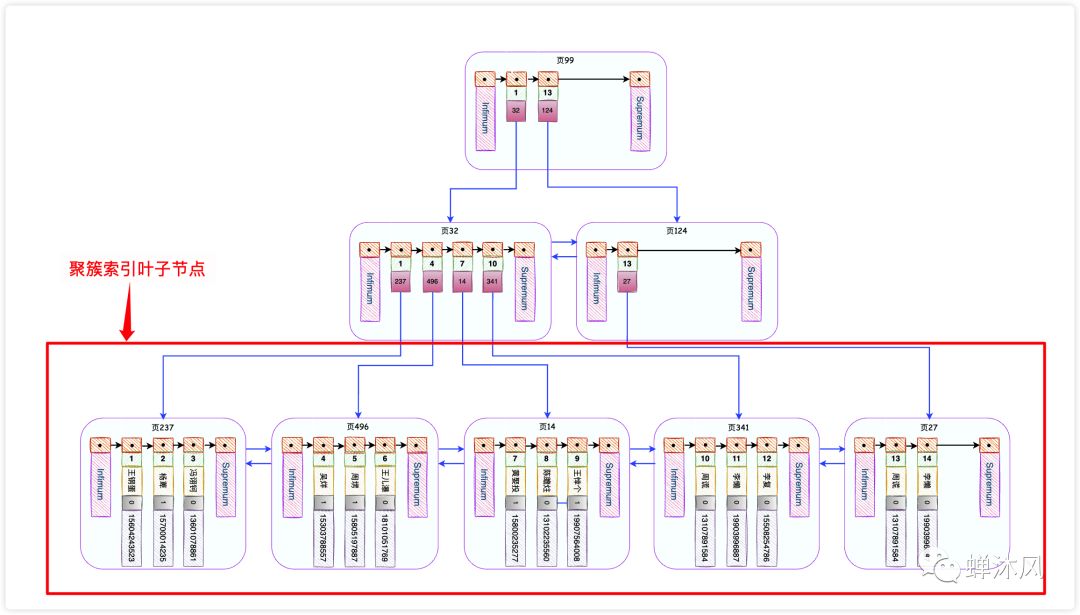 主键索引
主键索引
如果我们执行这个语句
SELECT * FROM user_innodb WHERE name = '蝉沐风';
使用EXPLAIN查看一下语句的执行计划:

发现这个SQL语句会使用到IDX_NAME_PHONE索引,这是一个二级索引。二级索引的叶子节点长这个样子:
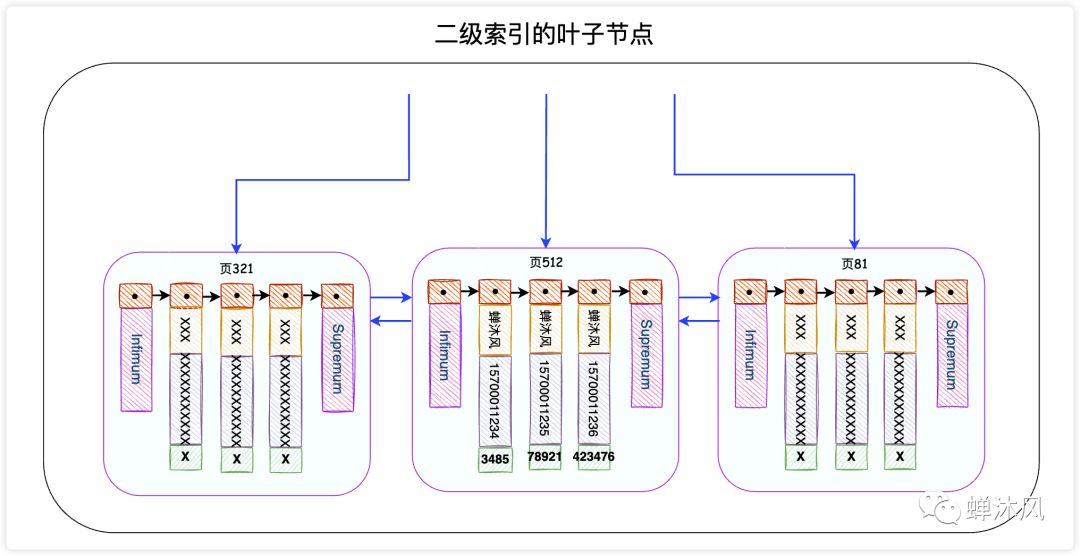
InnoDB存储引擎会根据搜索条件在该二级索引的叶子节点中找到name为蝉沐风的记录,但是二级索引中只记录了name、phone和主键id字段(谁让我们用的是SELECT *呢),因此InnoDB需要拿着主键id去主键索引中查找这一条完整的记录,这个过程叫做回表。
想一下,如果二级索引的叶子节点上有我们想要的所有数据,是不是就不需要回表了呢?是的,这就是覆盖索引。
举个例子,我们恰好只想搜索name、phone以及主键字段。
SELECT id, name, phone FROM user_innodb WHERE name = "蝉沐风";
使用EXPLAIN查看一下语句的执行计划:

可以看到Extra一列显示Using index,表示我们的查询列表以及搜索条件中只包含属于某个索引的列,也就是使用了覆盖索引,能够直接摒弃回表操作,大幅度提高查询效率。
4. 可能拖慢JOIN连接查询
我们创建两张表t1,t2进行连接操作来说明接下来的问题,并向t1表中插入了100条数据,向t2中插入了1000条数据。
CREATE TABLE `t1` (
`id` int NOT NULL,
`m` int DEFAULT NULL,
`n` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT;
CREATE TABLE `t2` (
`id` int NOT NULL,
`m` int DEFAULT NULL,
`n` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT;
如果我们执行下面这条语句
SELECT * FROM t1 STRAIGHT_JOIN t2 ON t1.m = t2.m;
这里我使用了STRAIGHT_JOIN强制令t1表作为驱动表,t2表作为被驱动表
对于连接查询而言,驱动表只会被访问一遍,而被驱动表却要被访问好多遍,具体的访问次数取决于驱动表中符合查询记录的记录条数。由于已经强制确定了驱动表和被驱动表,下面我们说一下两表连接的本质:
- t1作为驱动表,针对驱动表的过滤条件,执行对t1表的查询。因为没有过滤条件,也就是获取t1表的所有数据;
- 对上一步中获取到的结果集中的每一条记录,都分别到被驱动表中,根据连接过滤条件查找匹配记录
用伪代码表示的话整个过程是这样的:
// t1Res是针对驱动表t1过滤之后的结果集
for (t1Row : t1Res){
// t2是完整的被驱动表
for(t2Row : t2){
if (满足join条件 && 满足t2的过滤条件){
发送给客户端
}
}
}
这种方法最简单,但同时性能也是最差,这种方式叫做嵌套循环连接(Nested-LoopJoin,NLJ)。怎么加快连接速度呢?
其中一个办法就是创建索引,最好是在被驱动表(t2)连接条件涉及到的字段上创建索引,毕竟被驱动表需要被查询好多次,而且对被驱动表的访问本质上就是个单表查询而已(因为t1结果集定了,每次连接t2的查询条件也就定死了)。
既然使用了索引,为了避免重蹈无法使用覆盖索引的覆辙,我们也应该尽量不要直接SELECT *,而是将真正用到的字段作为查询列,并为其建立适当的索引。
但是如果我们不使用索引,MySQL就真的按照嵌套循环查询的方式进行连接查询吗?当然不是,毕竟这种嵌套循环查询实在是太慢了!
在MySQL8.0之前,MySQL提供了基于块的嵌套循环连接(Block Nested-Loop Join,BLJ)方法,MySQL8.0又推出了hash join方法,这两种方法都是为了解决一个问题而提出的,那就是尽量减少被驱动表的访问次数。
这两种方法都用到了一个叫做join buffer的固定大小的内存区域,其中存储着若干条驱动表结果集中的记录(这两种方法的区别就是存储的形式不同而已),如此一来,把被驱动表的记录加载到内存的时候,一次性和join buffer中多条驱动表中的记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的I/O代价,大大减少了重复从磁盘上加载被驱动表的代价。使用join buffer的过程如下图所示:
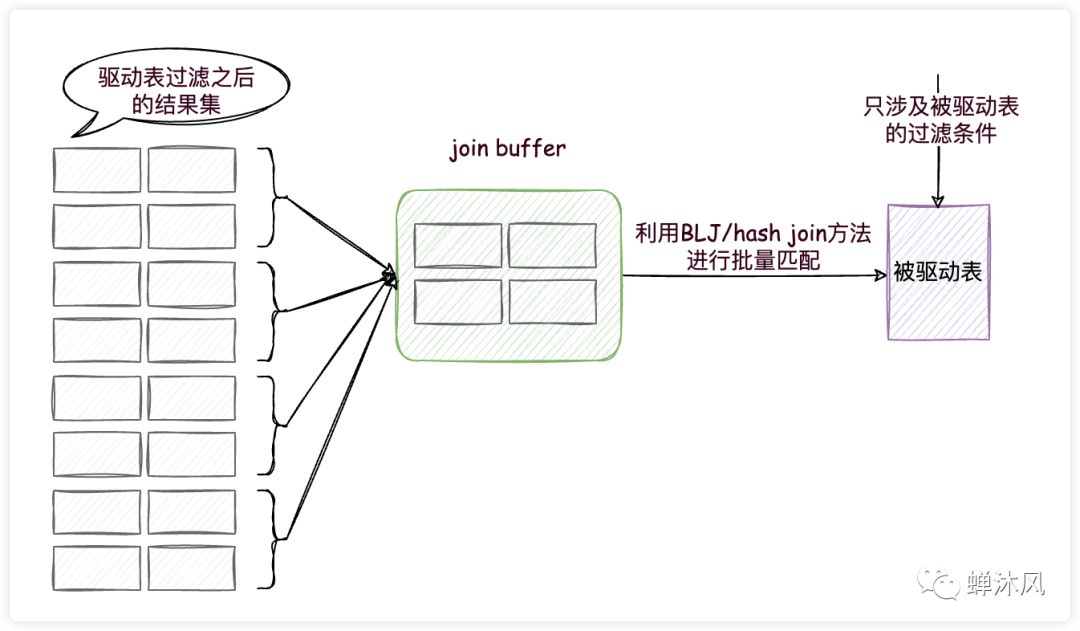 join buffer示意图
join buffer示意图
我们看一下上面的连接查询的执行计划,发现确实使用到了hash join(前提是没有为t2表的连接查询字段创建索引,否则就会使用索引,不会使用join buffer)。

最好的情况是join buffer足够大,能容纳驱动表结果集中的所有记录,这样只需要访问一次被驱动表就可以完成连接操作了。我们可以使用join_buffer_size这个系统变量进行配置,默认大小为256KB。如果还装不下,就得分批把驱动表的结果集放到join buffer中了,在内存中对比完成之后,清空join buffer再装入下一批结果集,直到连接完成为止。
重点来了!并不是驱动表记录的所有列都会被放到join buffer中,只有查询列表中的列和过滤条件中的列才会被放到join buffer中,所以再次提醒我们,最好不要把*作为查询列表,只需要把我们关心的列放到查询列表就好了,这样还可以在join buffer中放置更多的记录,减少分批的次数,也就自然减少了对被驱动表的访问次数。
-
相关阅读:
Redisson实现分布式锁的实战案例-锁单key-锁多key-看门狗
PCL (一)点云的格式
开发 AppWidget
Linux学习-HIS系统部署(1)
ES基本使用_2_整合SpringBoot
购物车的html
Java属性序列化自定义排序与字母表排序
Stirling-PDF 安装和使用教程
区块链系统Docker&Kuberntes一键部署
【vue】vue中如何使用http代理解决跨域问题_11
- 原文地址:https://blog.csdn.net/chenxuyuana/article/details/126028601

